State of the company o Future direction • Eric Follows o What we have been up to since we last met o Big wins we have had o Deep dive into customer examples (Princeton, DFCI, TU Dresden, IWM) o Look at customer challenges o Datakamer Event • Q&A and Discussion
data management, orchestration, multi-protocol access, and storage in a single system. This isn’t just a file system – it’s an end-to-end data fabric. Global data lifecycle management Mediaflux manages the entire data lifecycle, from ingestion through to long-term archive, both on-premises and in the cloud. Multi-protocol, scalable access Purpose built XODB supports common access methods (NFS, SMB, S3, SFTP, etc.), so any application or AI tool can read/write data seamlessly. One vendor-agnostic fabric Mediaflux works over any storage hardware: NetApp, Dell ECS, cloud blob stores, tape, you name it.
Transfer Compute-to-data Mediaflux can send analytics and processing jobs to where data lives. Rich metadata engine XODB database drives a powerful search. This world-class metadata catalog ensures you instantly know what data you have and how it’s connected. Ultra-fast WAN transfers Mediaflux’s Livewire module provides integrated WAN acceleration. It can move data globally at up to 95% of link speed.
of Mediaflux Global namespace Offers either a single unified file system and/or federated namespaces for geographically dispersed teams. Edge caching To meet low-latency needs, Edge nodes cache hot data close to users while keeping a copy centrally. Burst compute support For peak AI/compute spikes, Mediaflux Burst lets you extend compute to cloud or other data centers on demand, decoupling storage from compute resources. Real-Time Collaboration Mediaflux Real-Time ensures that no moment is lost—giving teams near instant access to growing files, seamless collaboration, and ultra-fast data transfers.
AI Integration XODB vector database Mediaflux XODB not only stores file metadata, but also manages vectors between data objects. By understanding spatial/temporal Mediaflux can place or replicate data to facilitate AI models. RAG and generative AI Mediaflux is architected for the next-generation AI stack. XODB supports vector embedding representations, therefore it can serve as a backend for AI agents. Seamless search and hierarchy Mediaflux can present virtual hierarchies of data based on search results or metadata filters. The net result is that your AI applications gain an “all- knowing” index of the enterprise data.
an analogue to a digital domain. Old library functions were about preserving books, films, tape recordings, curation, sorting etc. Princeton is working on a 100-year data management plan. Think about how many technology refreshes there will be over a 100-years? How will a Nobel prize winning researcher find their 2024 data in 2040?
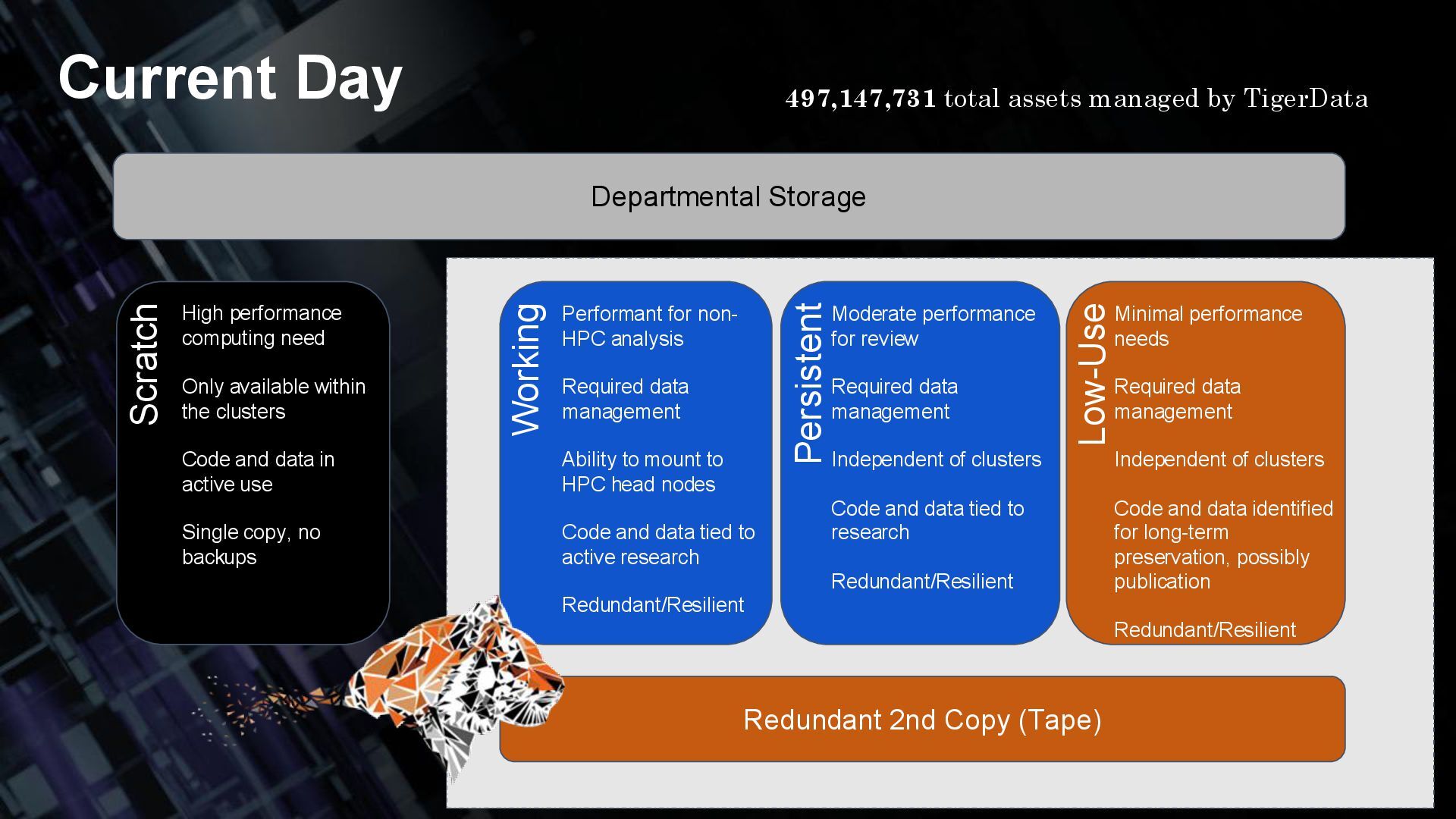
(Tape) Scratch Working Persistent Low-Use High performance computing need Only available within the clusters Code and data in active use Single copy, no backups Performant for non- HPC analysis Required data management Ability to mount to HPC head nodes Code and data tied to active research Redundant/Resilient Moderate performance for review Required data management Independent of clusters Code and data tied to research Redundant/Resilient Minimal performance needs Required data management Independent of clusters Code and data identified for long-term preservation, possibly publication Redundant/Resilient Current Day 497,147,731 total assets managed by TigerData
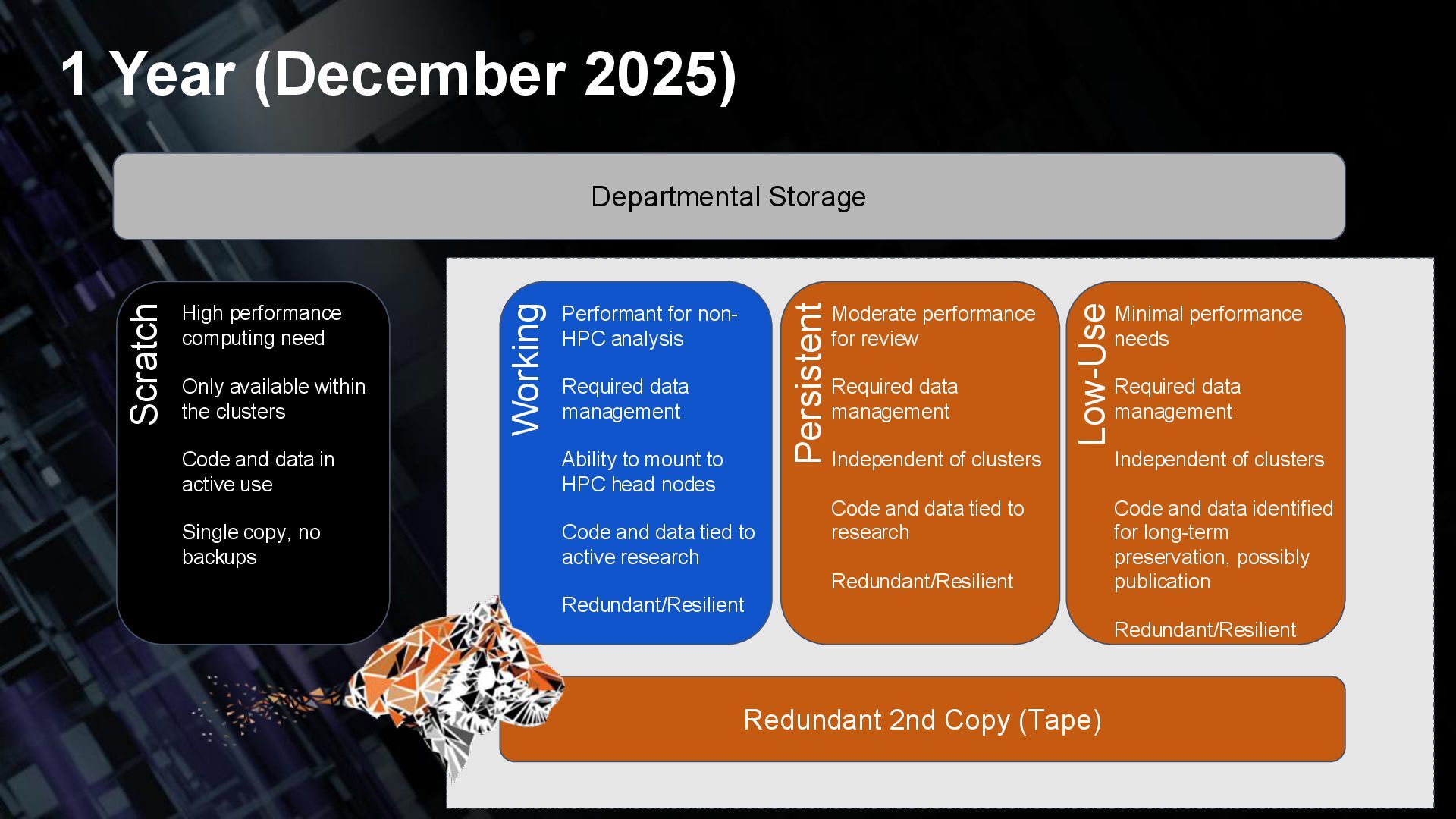
(Tape) Scratch Working Persistent Low-Use High performance computing need Only available within the clusters Code and data in active use Single copy, no backups Performant for non- HPC analysis Required data management Ability to mount to HPC head nodes Code and data tied to active research Redundant/Resilient Moderate performance for review Required data management Independent of clusters Code and data tied to research Redundant/Resilient Minimal performance needs Required data management Independent of clusters Code and data identified for long-term preservation, possibly publication Redundant/Resilient 1 Year (December 2025)
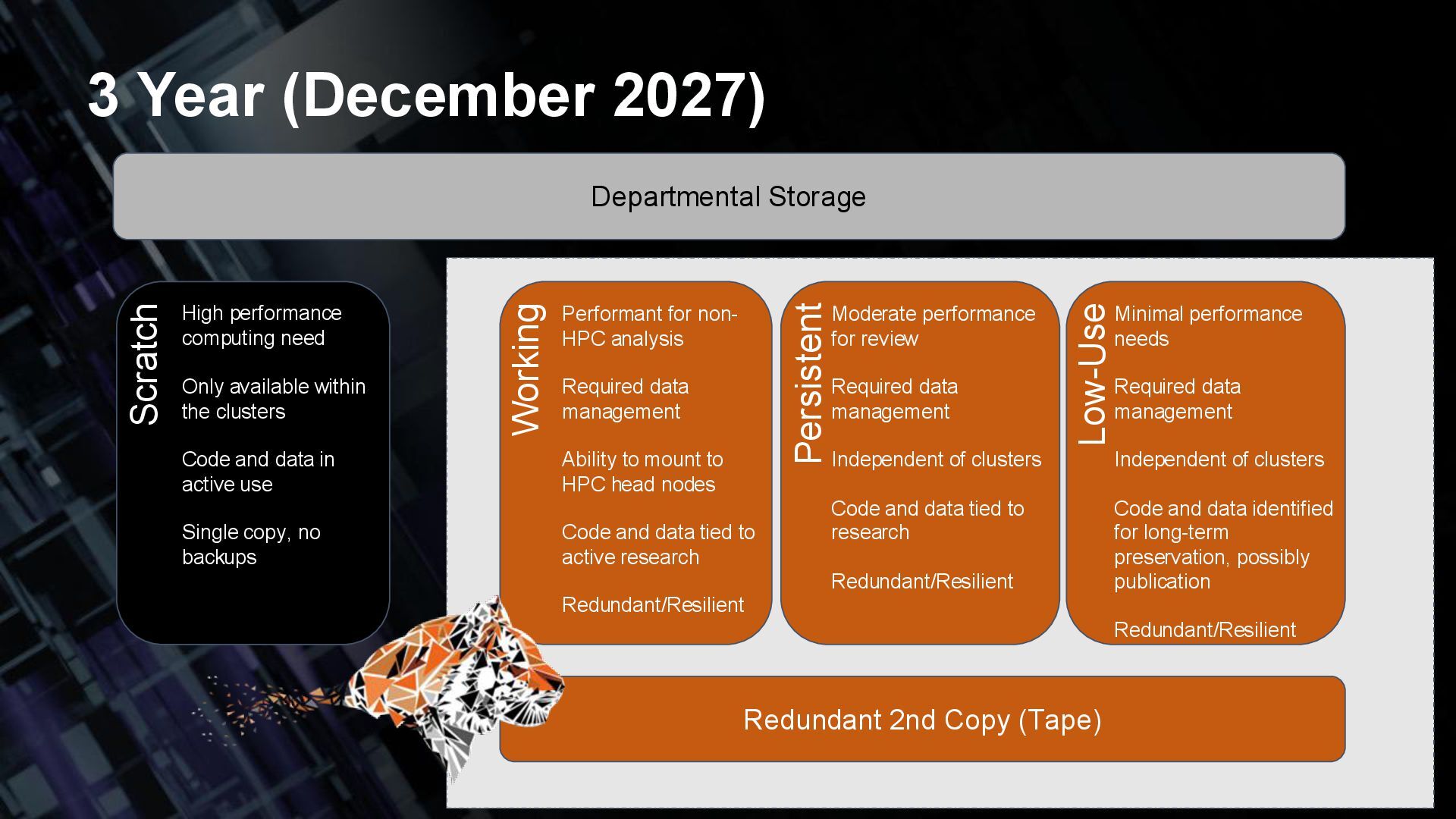
(Tape) Scratch Working Persistent Low-Use High performance computing need Only available within the clusters Code and data in active use Single copy, no backups Performant for non- HPC analysis Required data management Ability to mount to HPC head nodes Code and data tied to active research Redundant/Resilient Moderate performance for review Required data management Independent of clusters Code and data tied to research Redundant/Resilient Minimal performance needs Required data management Independent of clusters Code and data identified for long-term preservation, possibly publication Redundant/Resilient 3 Year (December 2027)
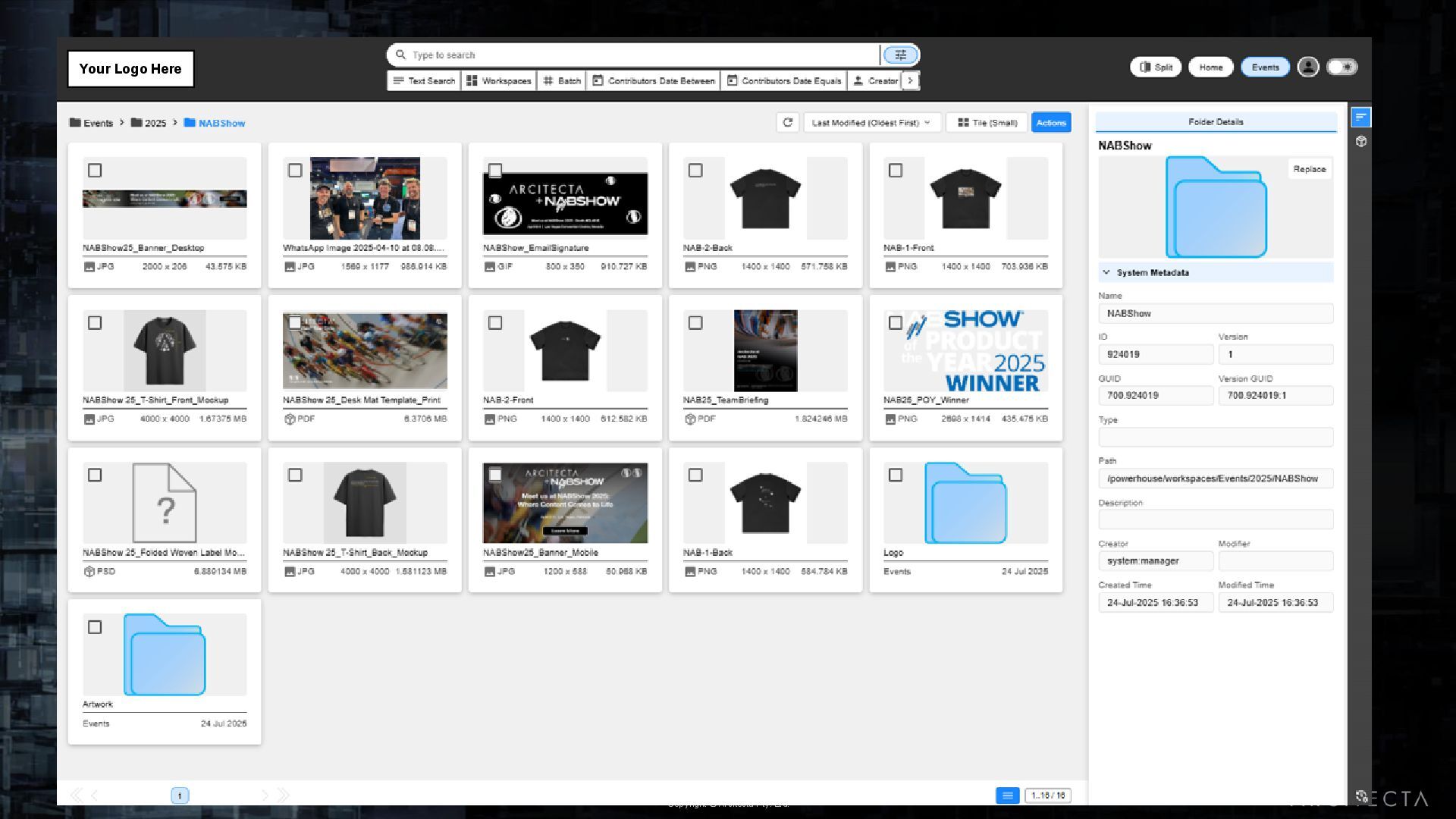
Ecosystem o Spectra Logic o Wasabi • Mediaflux is the tool used to manage and share data within DFCI and with outside organizations • Spectra Cube with BlackPearl • Wasabi cloud storage
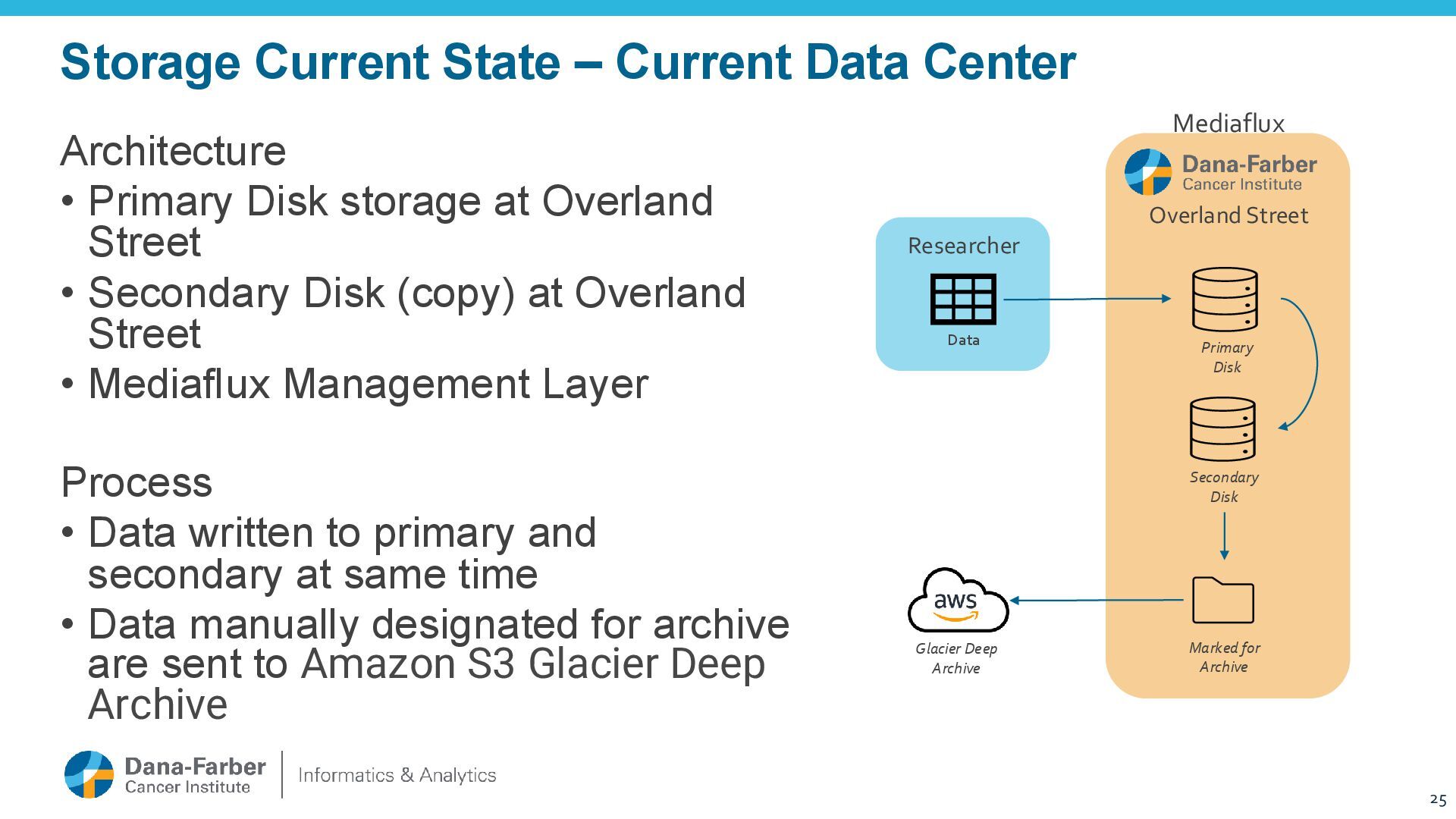
Architecture • Primary Disk storage at Overland Street • Secondary Disk (copy) at Overland Street • Mediaflux Management Layer Process • Data written to primary and secondary at same time • Data manually designated for archive are sent to Amazon S3 Glacier Deep Archive 25 Data Secondary Disk Primary Disk Marked for Archive Glacier Deep Archive Mediaflux
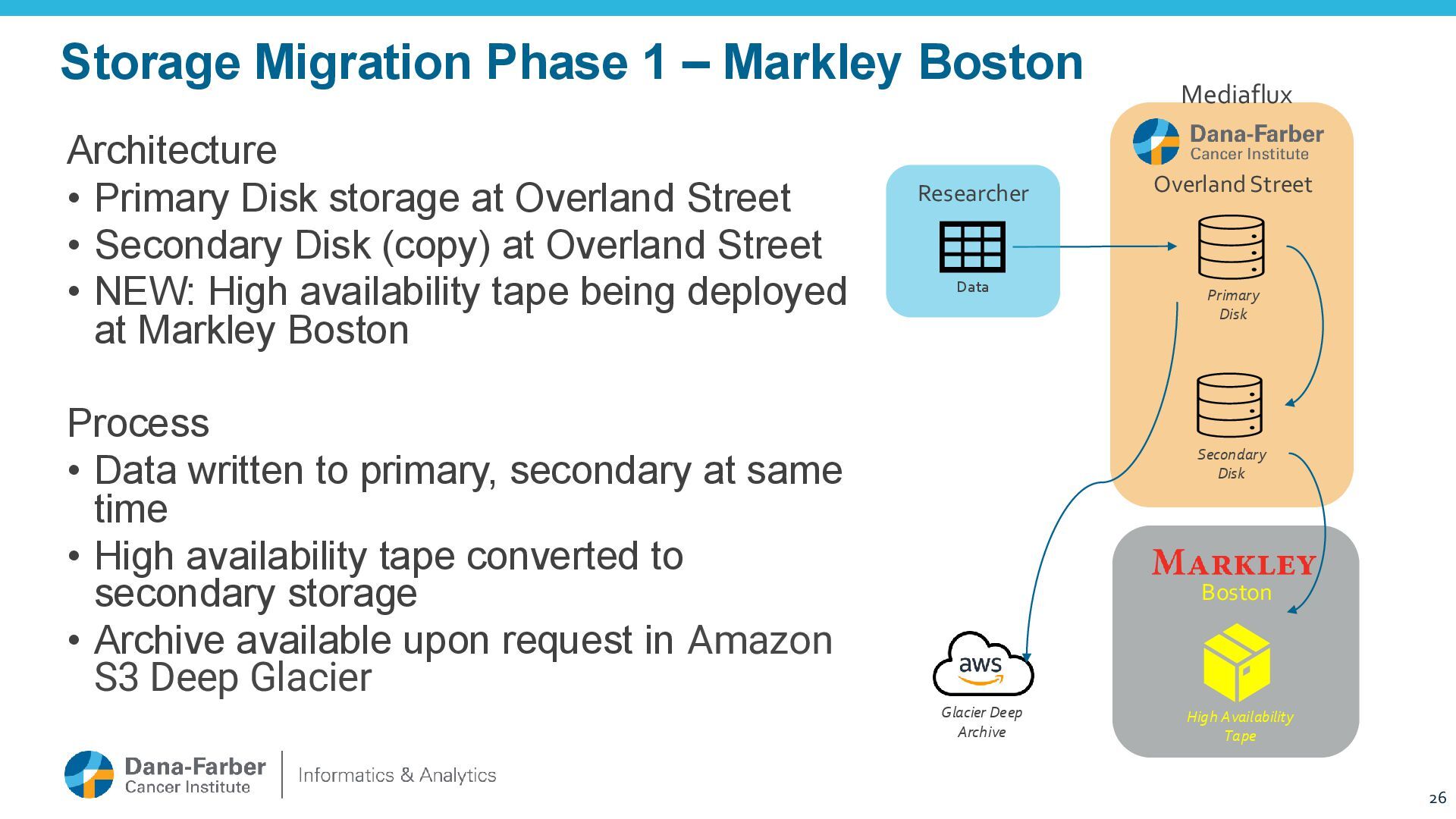
Disk storage at Overland Street • Secondary Disk (copy) at Overland Street • NEW: High availability tape being deployed at Markley Boston Process • Data written to primary, secondary at same time • High availability tape converted to secondary storage • Archive available upon request in Amazon S3 Deep Glacier 26 Overland Street Primary Disk Glacier Deep Archive Boston High Availability Tape Secondary Disk Researcher Data Mediaflux
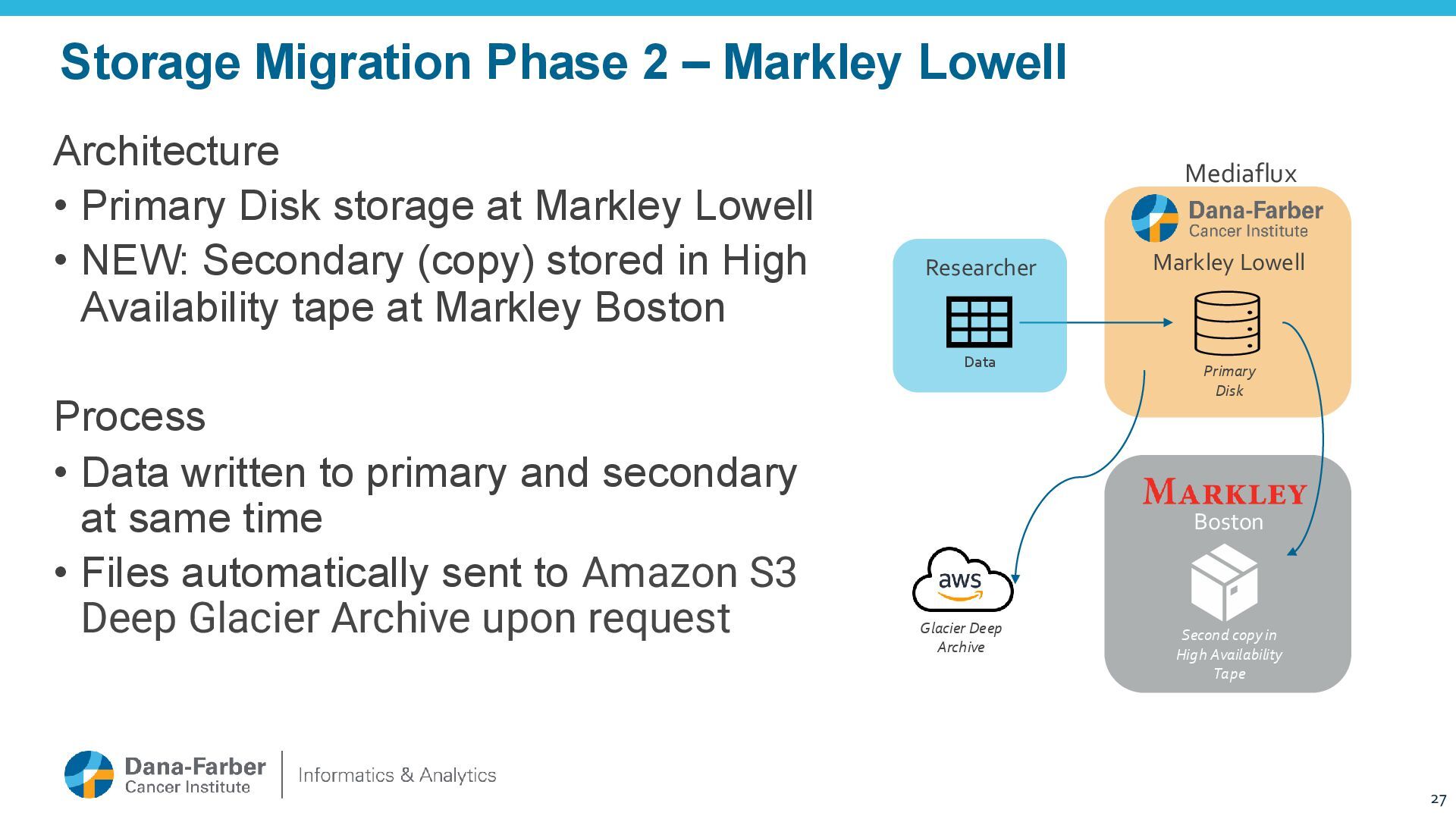
Primary Disk Glacier Deep Archive Boston Second copy in High Availability Tape Architecture • Primary Disk storage at Markley Lowell • NEW: Secondary (copy) stored in High Availability tape at Markley Boston Process • Data written to primary and secondary at same time • Files automatically sent to Amazon S3 Deep Glacier Archive upon request Researcher Data Mediaflux
Future Storage (size) needs • Determine what other storage devices/services they are utilizing with the goal of consolidating most/all data into RCSM • Work with them to create more efficient workflows for moving data • Work with vendors to evaluate best options for future storage hardware balancing price and support • Work with peer institutions to collaborate on future solutions for all aspects of Research computing 28
data growth into petabytes • Fragmented, siloed storage systems • Physical and digital assets • GLAM sector is a neglected area for technology innovation
Wasabi • Centralized visibility across all storage tiers • East to use interface with Mediaflux DAMS • Automated, seamless tiered archiving (disk → cloud) • Integration with Wasabi AIR for vector embedding
NFSA with a modern way to manage and ingest content • Simplifying complexity • Reducing costs • Easy to use and intuitive • Providing AI ready data and vector embeddings that can be searched across along with metadata
data growth into petabytes • Fragmented, siloed storage systems • Hard-to-find archived data; slow retrieval • Inefficient, manual archiving workflows • Limited collaboration across research teams
with Mediaflux + GRAU DATA XtreemStore • Centralized visibility across all storage tiers • Metadata-driven indexing for easy discovery • Automated, seamless tiered archiving (disk → tape) • High scalability and performance for research workloads
workflows: Automated archiving saves time • Seamless access: Even tape-stored data stays searchable • Better collaboration: Central repository boosts data sharing • Lower costs: Cold data moved to low-cost storage tiers • Future-ready: Scalable, adaptable infrastructure
data management from a bottleneck into a competitive advantage by: • Simplifying complexity • Reducing costs • Boosting collaboration and performance • Enabling research at scale
Diverse asset types: images, video, documents • Need for scalability: petabytes of storage • Distributed operations across sites • Security and compliance requirements • Ease of use for both archivists and casual users
for ingestion, cataloging, distribution • Automated metadata extraction for discovery • Multi-site deployment with redundancy • Military-grade security and compliance • User-centric design with intuitive interfaces • Future-proof scalability and modular architecture
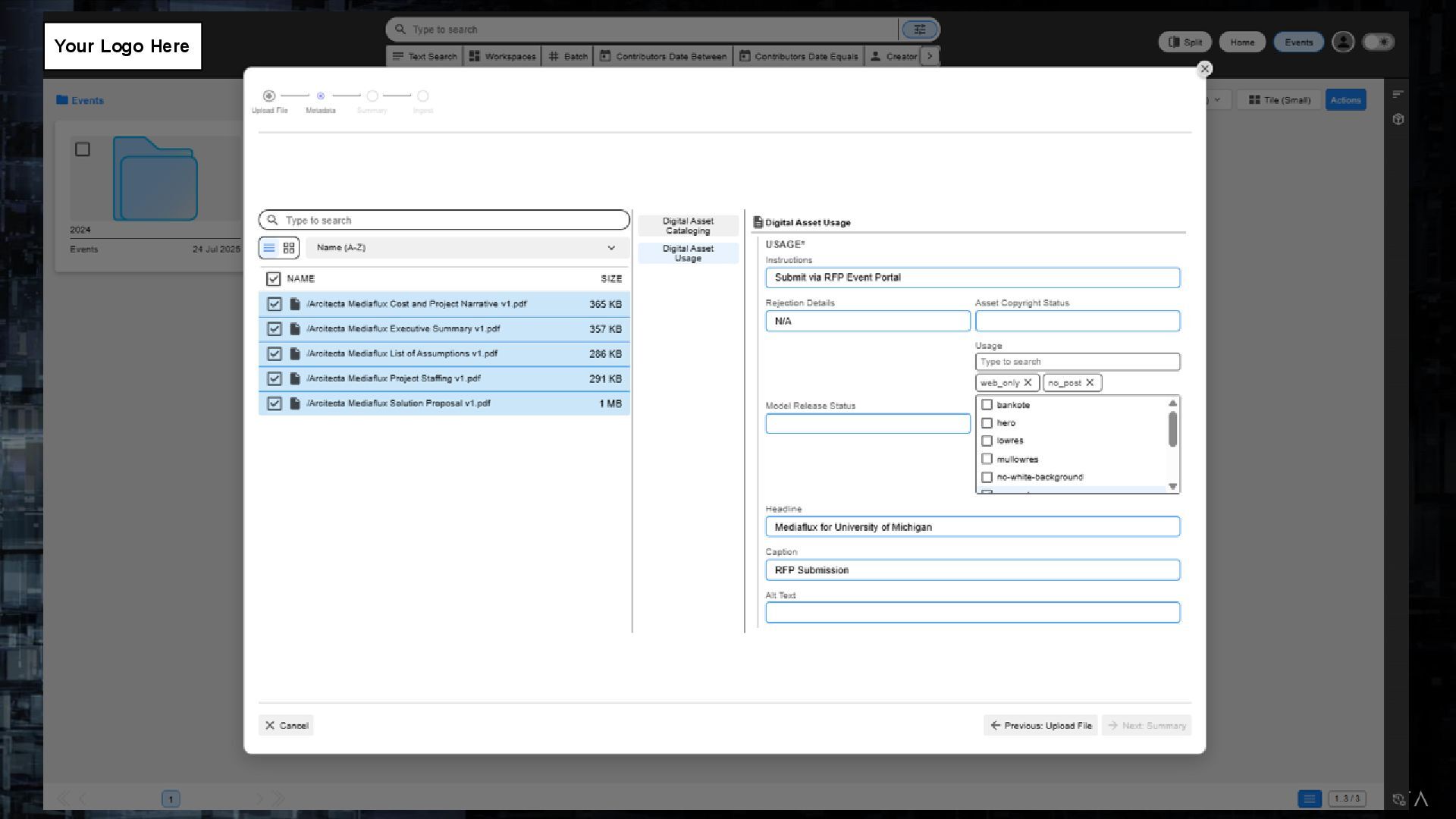
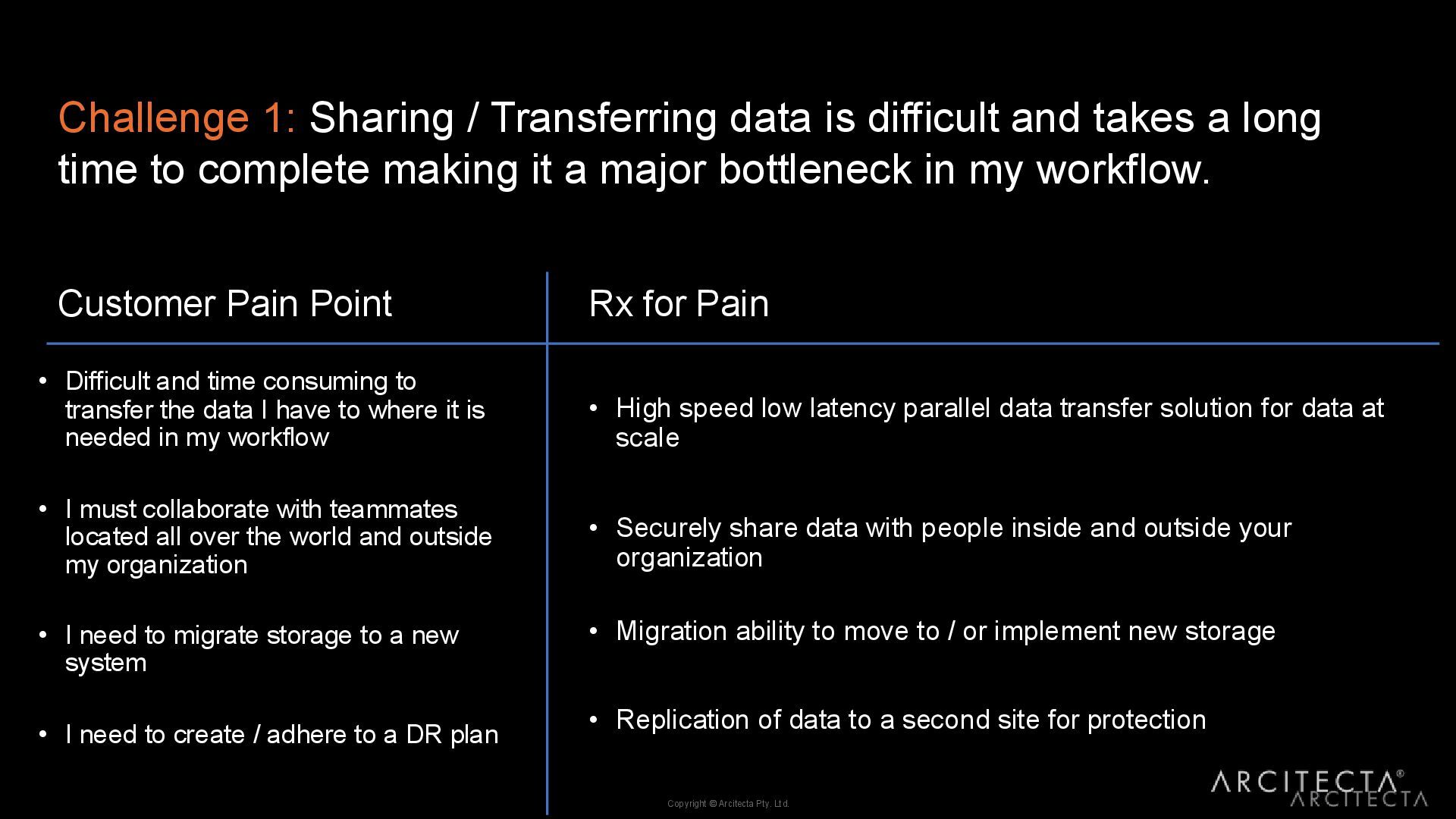
parallel data transfer solution for data at scale • Securely share data with people inside and outside your organization • Migration ability to move to / or implement new storage • Replication of data to a second site for protection • Difficult and time consuming to transfer the data I have to where it is needed in my workflow • I must collaborate with teammates located all over the world and outside my organization • I need to migrate storage to a new system • I need to create / adhere to a DR plan Customer Pain Point Rx for Pain Challenge 1: Sharing / Transferring data is difficult and takes a long time to complete making it a major bottleneck in my workflow.
single view (and access point) into what data I have and what is generating it / I need insights of my data • Find, mine, understand, utilize your data • Centralize and consolidate all your data into a single view. One pane of glass into all your data • Ability to utilize existing hardware and software already being used • I don’t know or understand what data I have and who or what is generating data • I have orphaned (siloed) storage and files that need to be centralized • I need a solution that fits into my existing workflow and can integrate with current technology I have Customer Pain Point Rx for Pain
keep pace with new equipment generating vast amounts of data • Being in the data path • Remove Vendor Lock-In • Data is being generated too fast for existing storage solution to manage = large amounts of unstructured data that needs management • I need my users and applications to maintain access to data regardless of where or what its stored on • Don’t want to be tied to a single vendor Customer Pain Point Rx for Pain Challenge 3: Data is being generated at an increasing pace and I need to store it and leave it accessible to users and applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}