Presentation given at WASSA 2018 (@ EMNLP2018) as part of the Implicit Emotion Shared Task (IEST).
You can read the paper here: https://arxiv.org/abs/1808.08672
And find the source code for the slides and paper (along with the solution to the task itself) here: https://github.com/jabalazs/implicit_emotion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
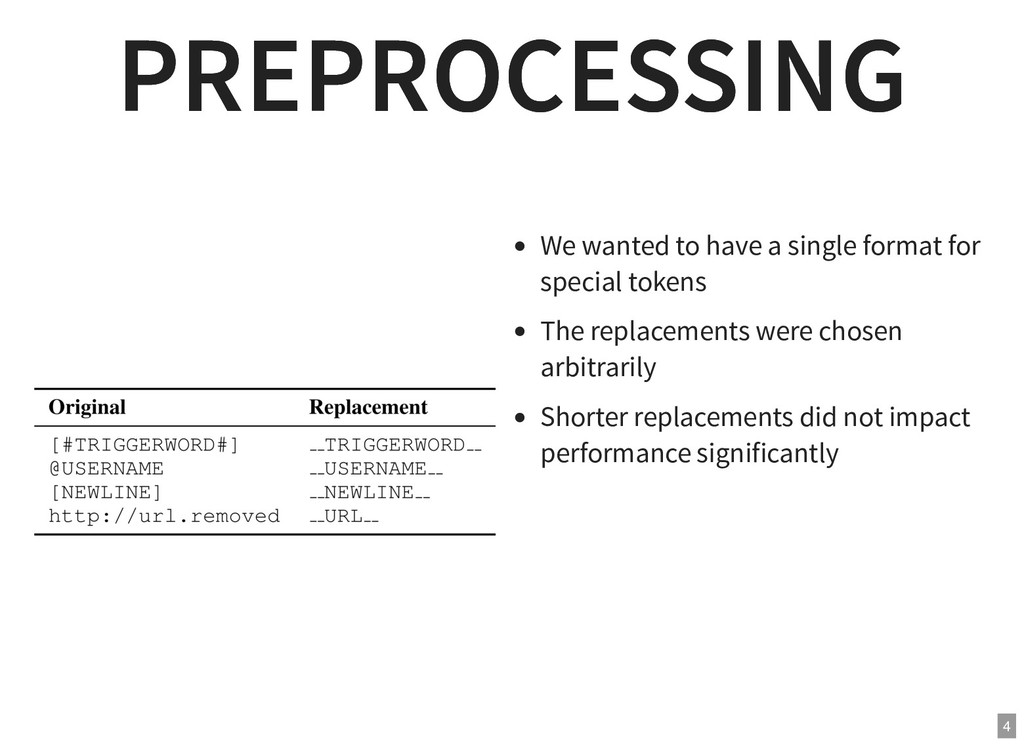{kind=link}
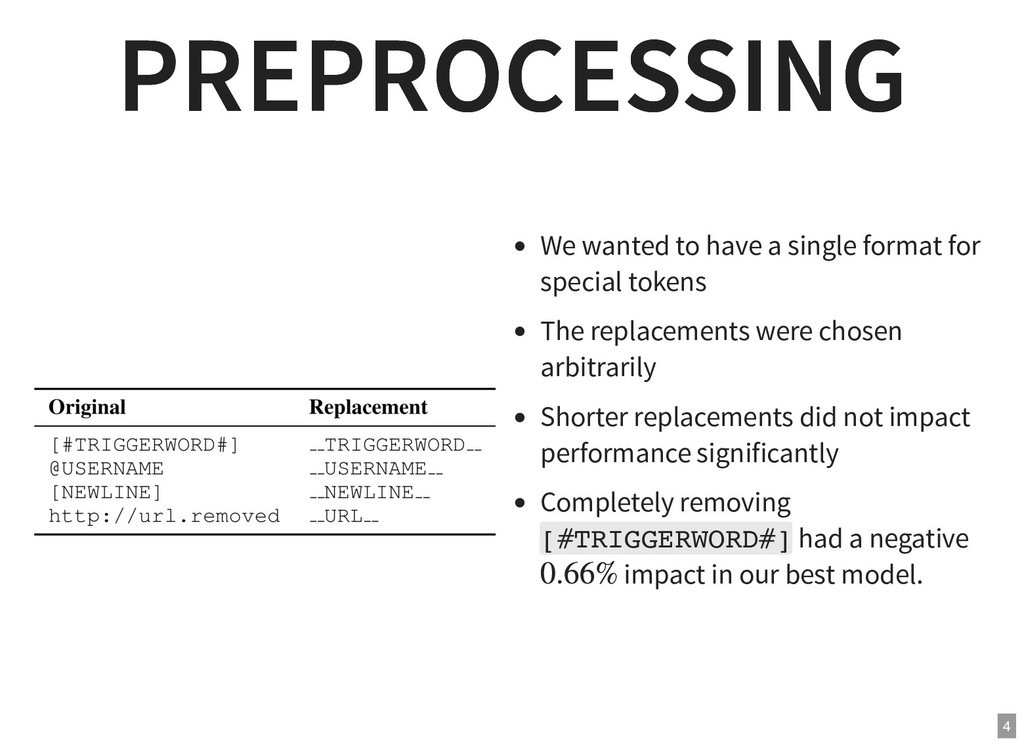{kind=link}
{kind=link}
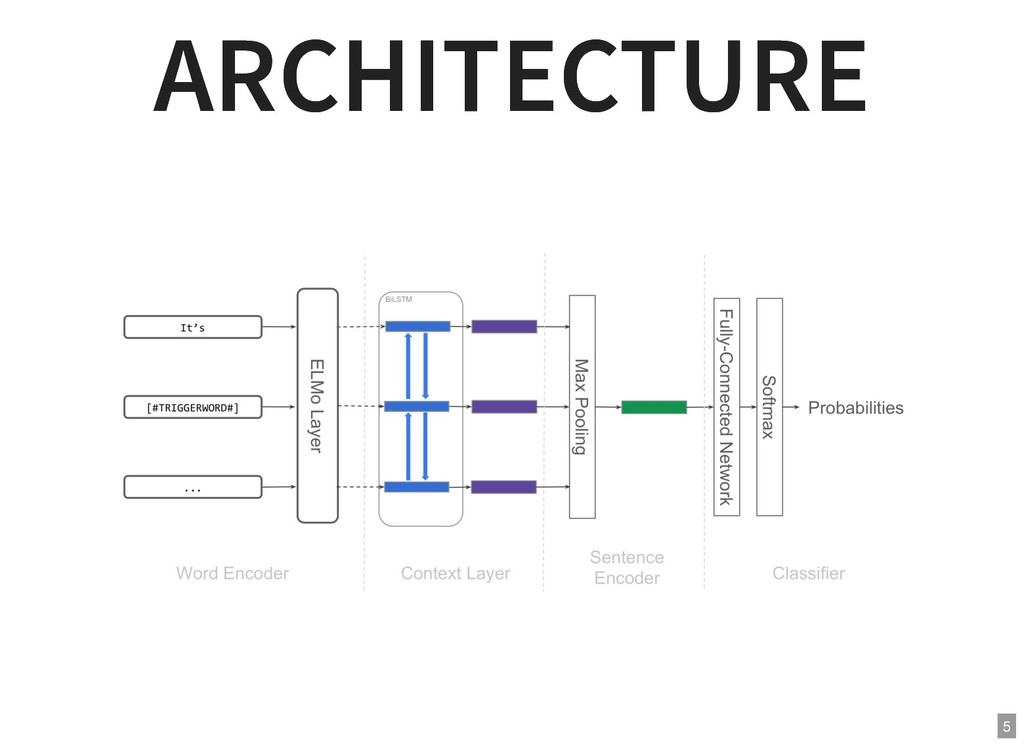{kind=link}
{kind=link}
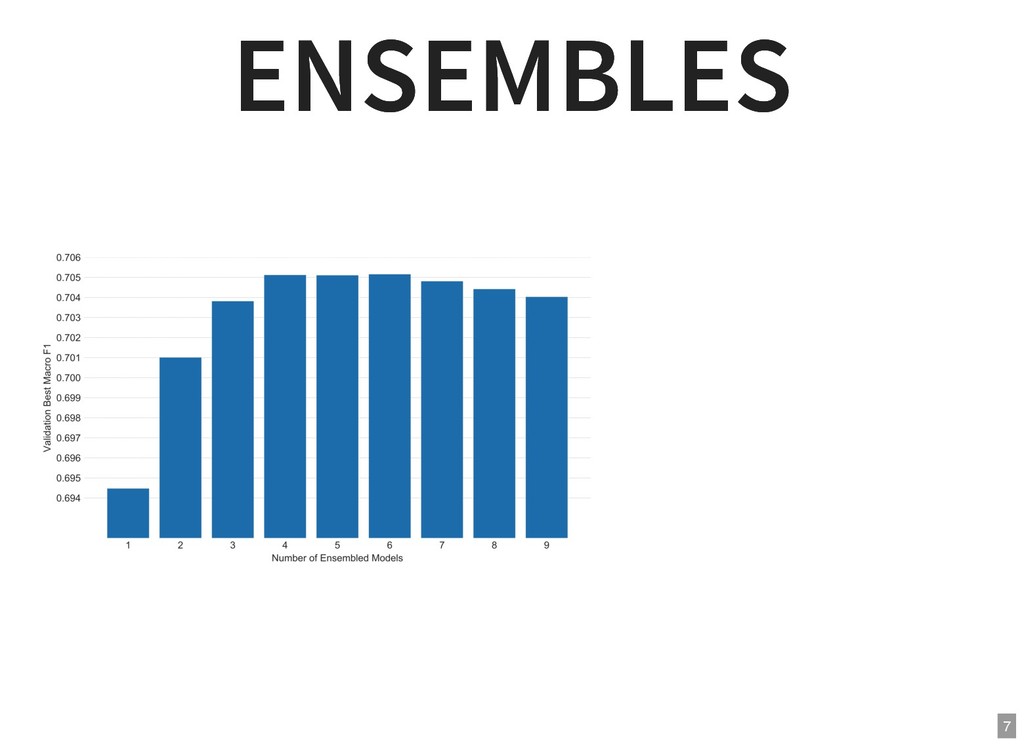{kind=link}
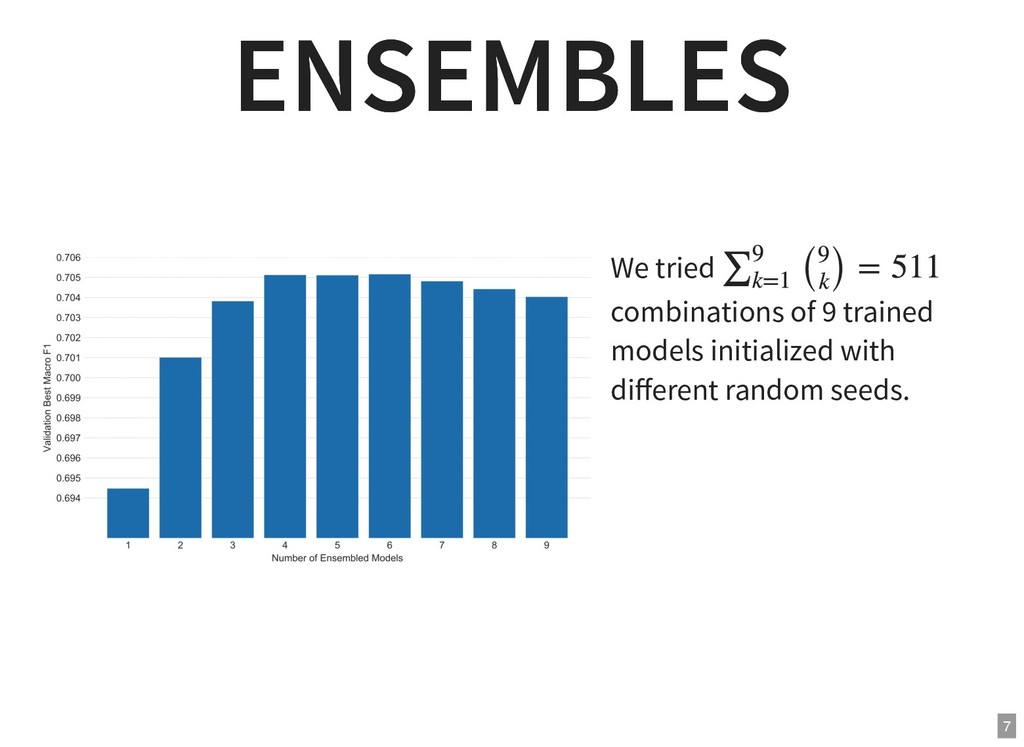{kind=link}
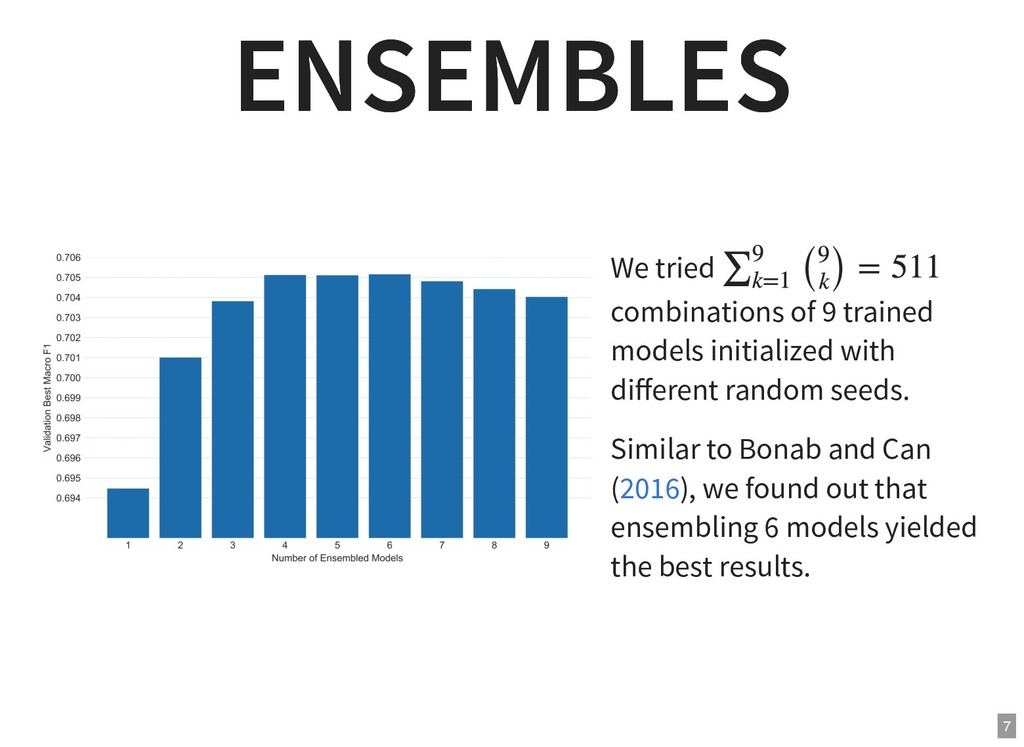{kind=link}
{kind=link}
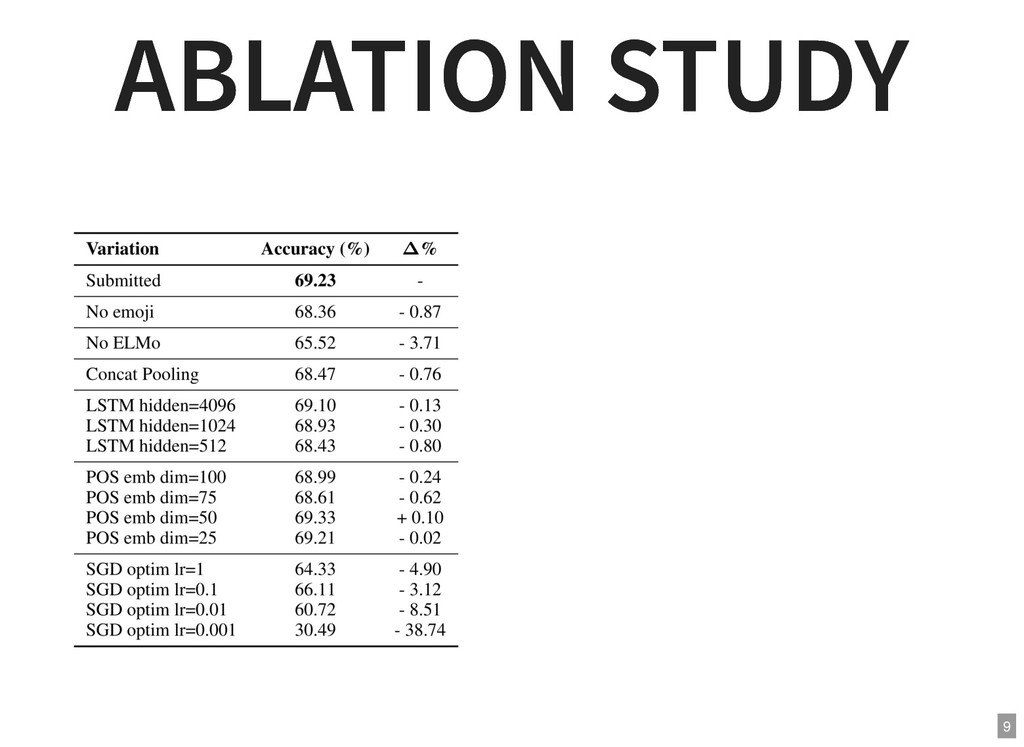{kind=link}
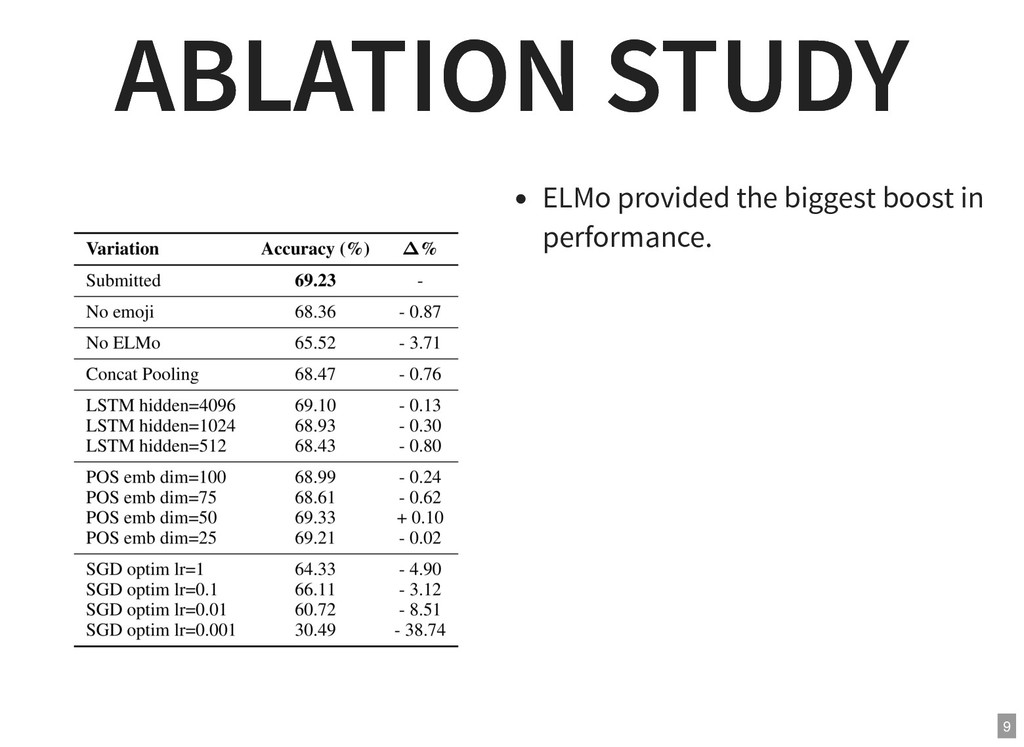{kind=link}
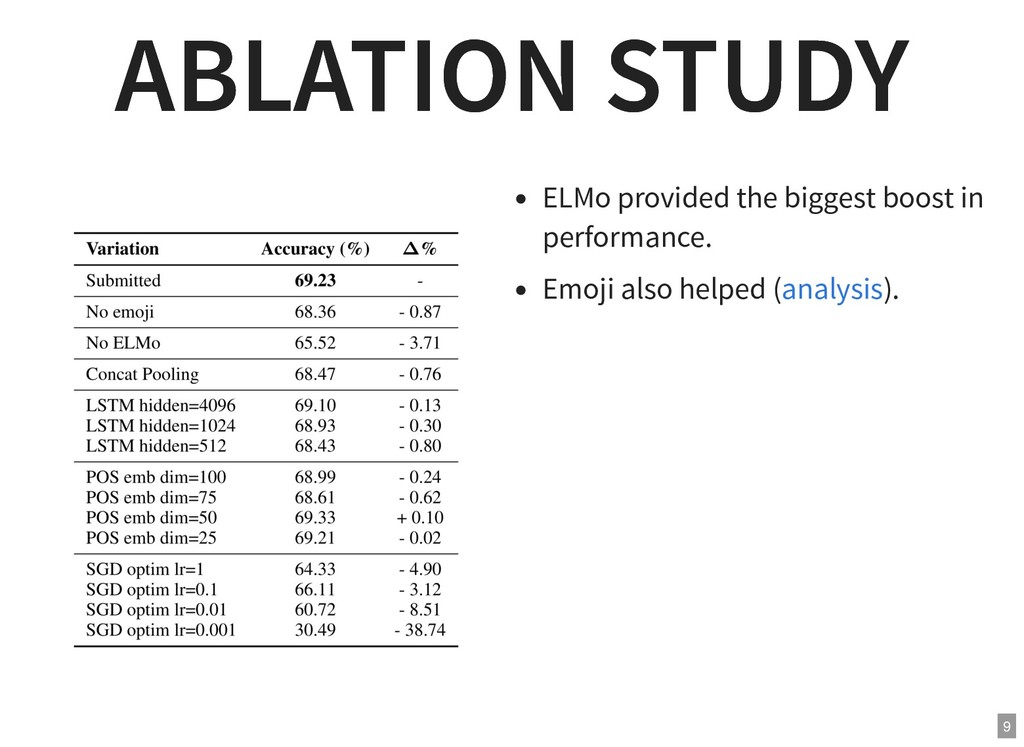{kind=link}
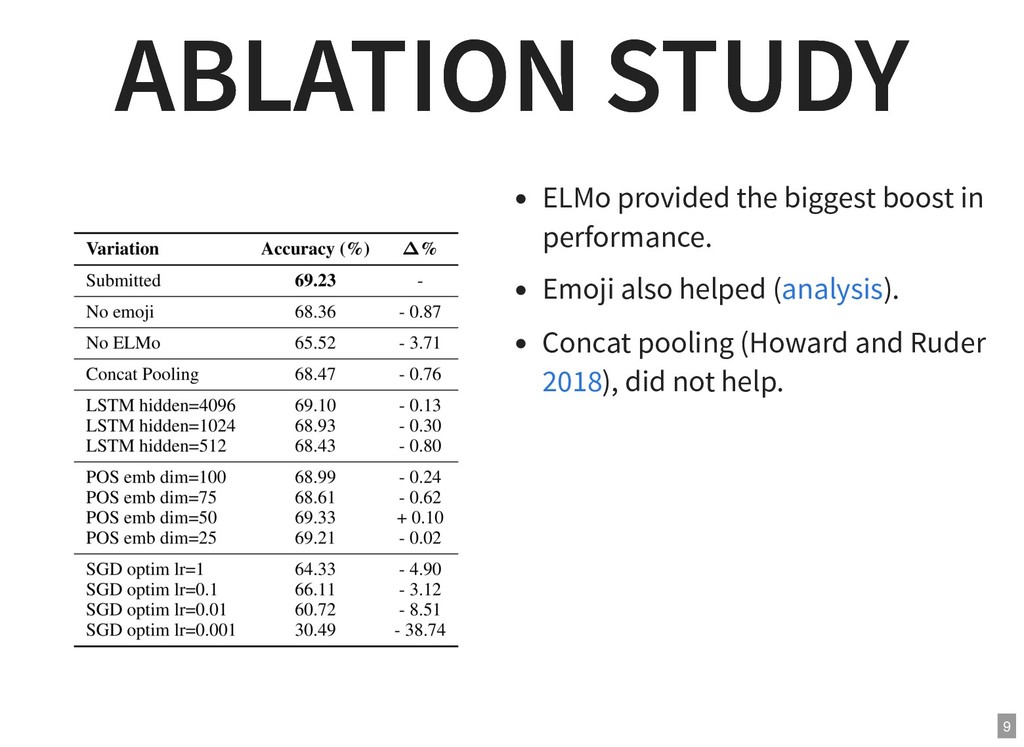{kind=link}
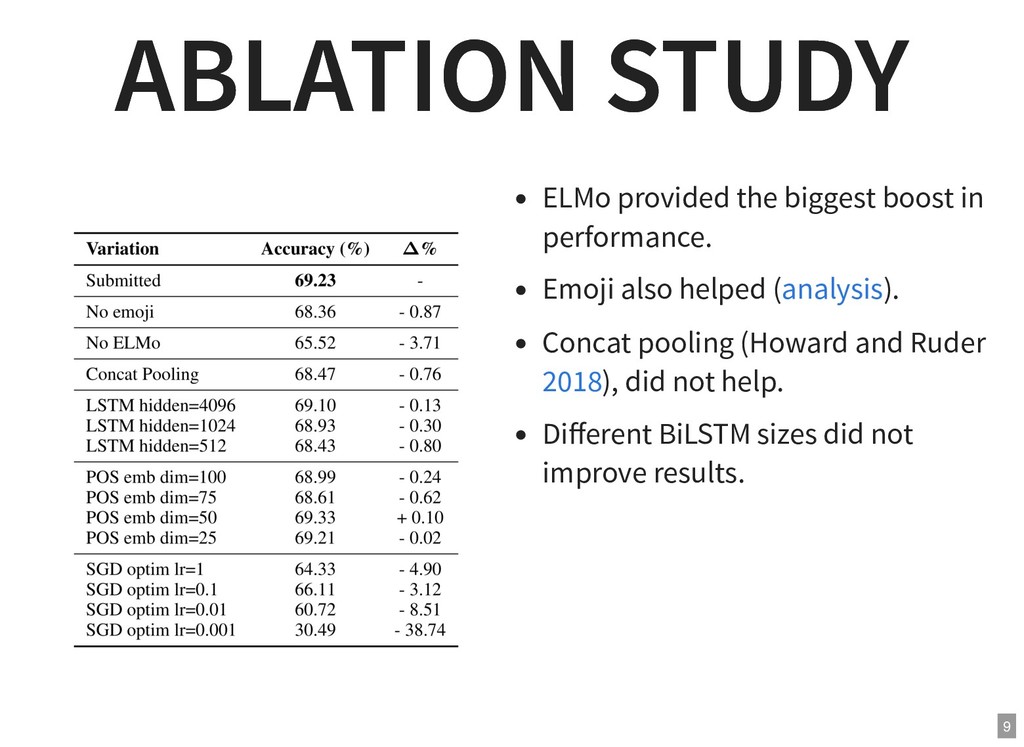{kind=link}
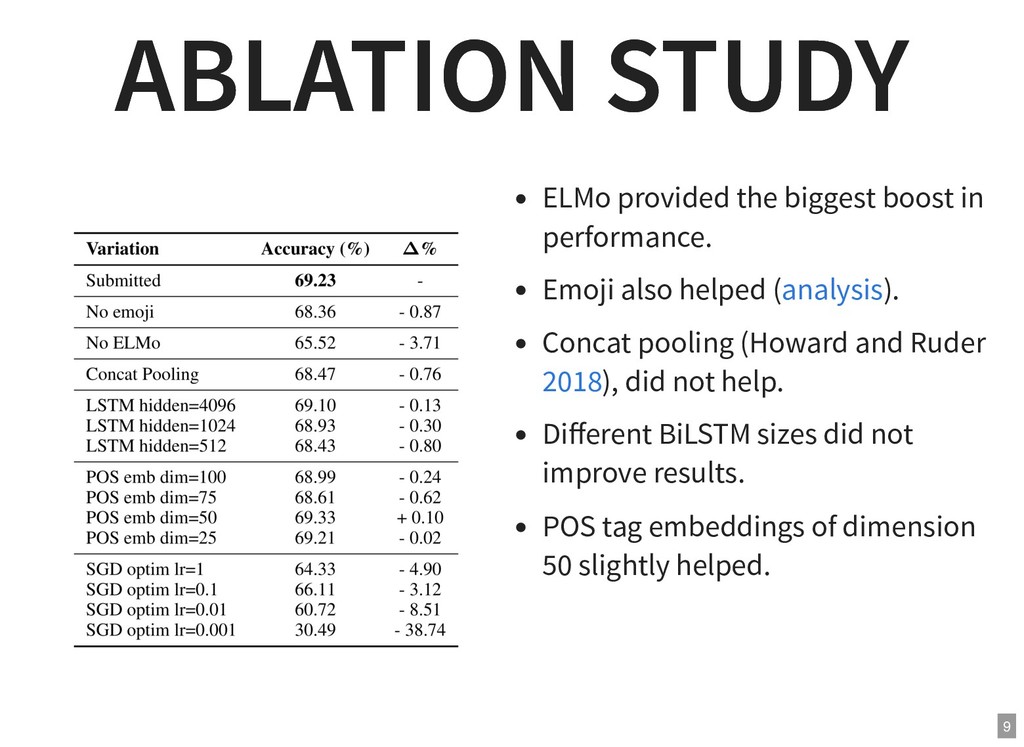{kind=link}
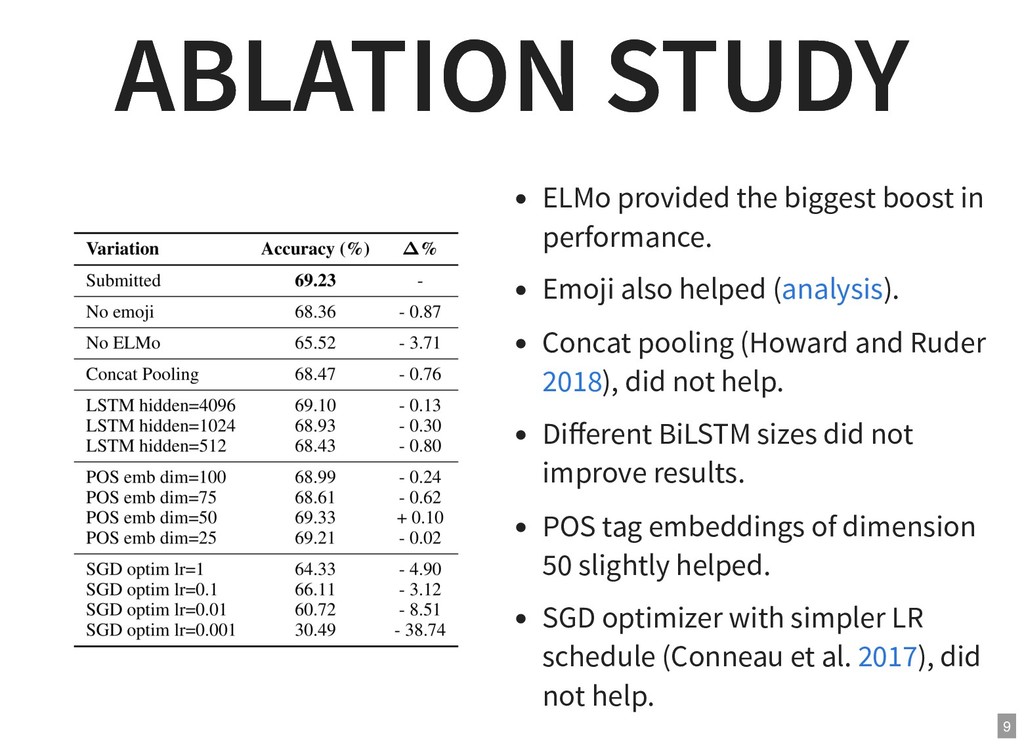{kind=link}
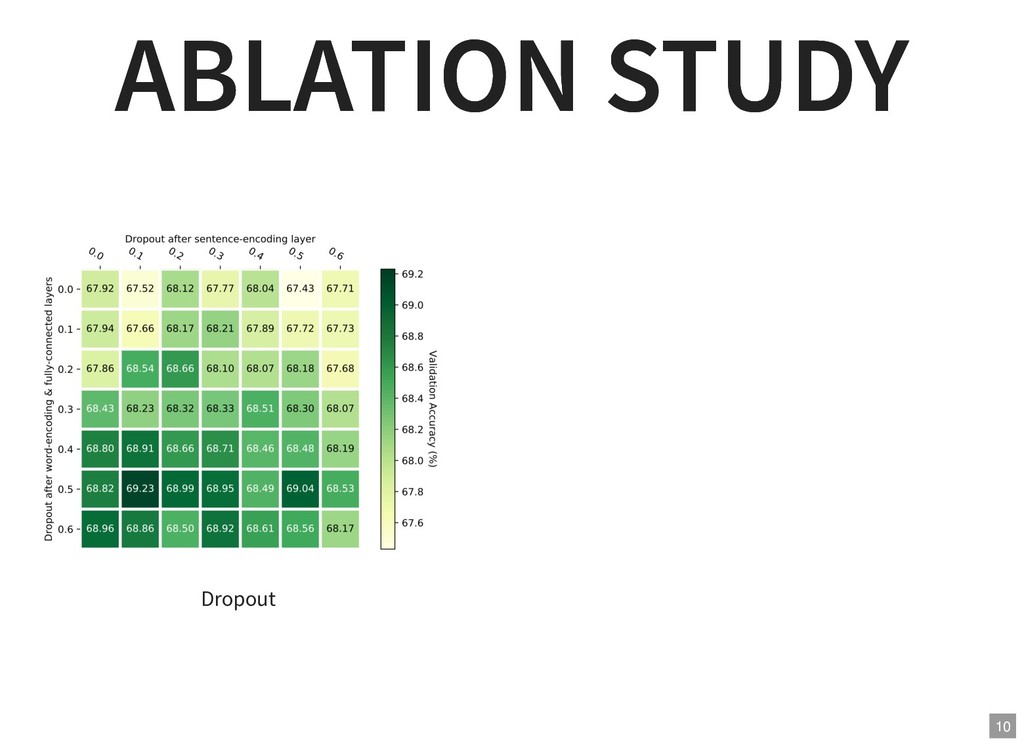{kind=link}
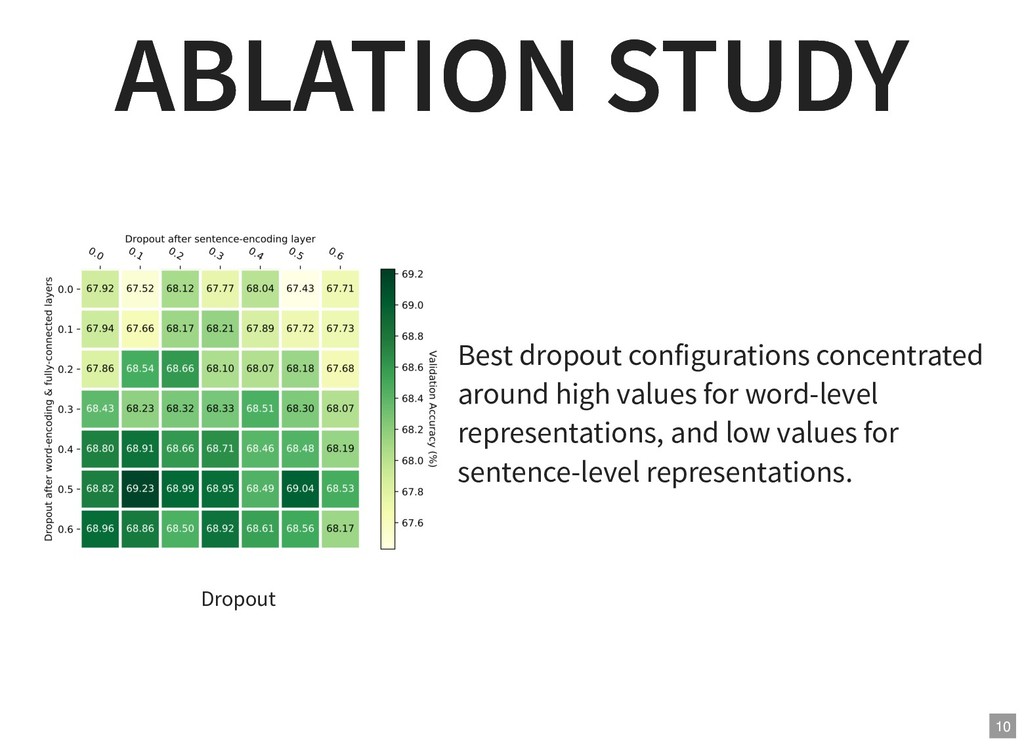{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
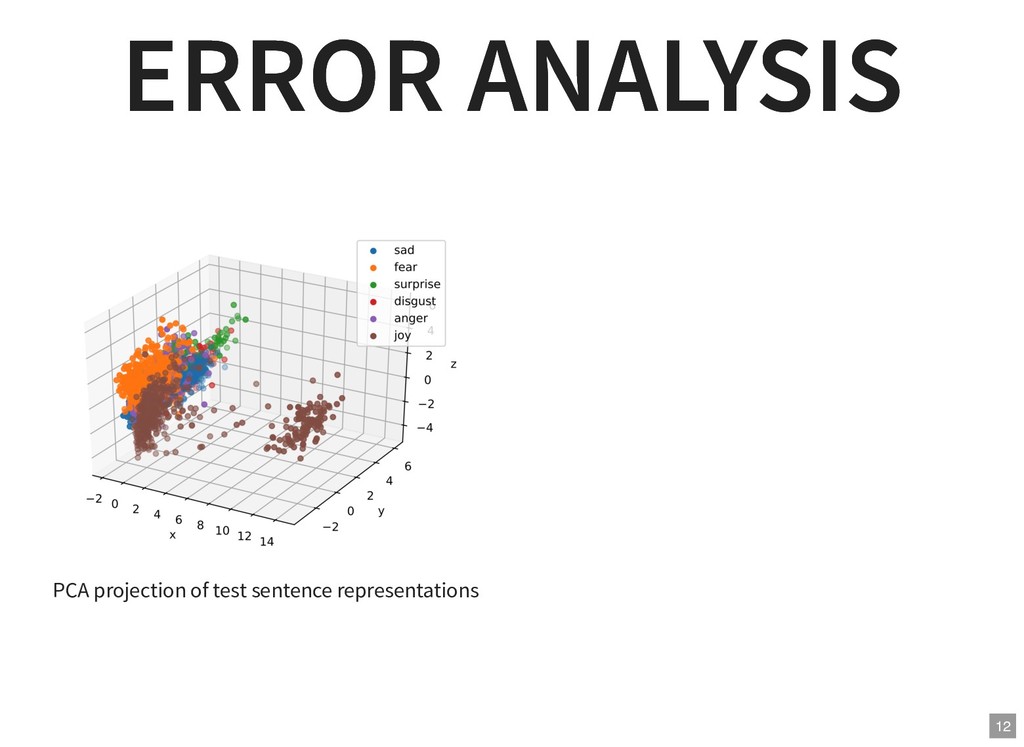{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CONCLUSIONS CONCLUSIONS We showed that: The “un[#TRIGGERWORD#]” artifact had significant](https://files.speakerdeck.com/presentations/c57fbed84c884cd69307e51bc65f4df9/slide_45.jpg){kind=link}
![CONCLUSIONS CONCLUSIONS We showed that: The “un[#TRIGGERWORD#]” artifact had significant](https://files.speakerdeck.com/presentations/c57fbed84c884cd69307e51bc65f4df9/slide_46.jpg){kind=link}
![CONCLUSIONS CONCLUSIONS We showed that: The “un[#TRIGGERWORD#]” artifact had significant](https://files.speakerdeck.com/presentations/c57fbed84c884cd69307e51bc65f4df9/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}