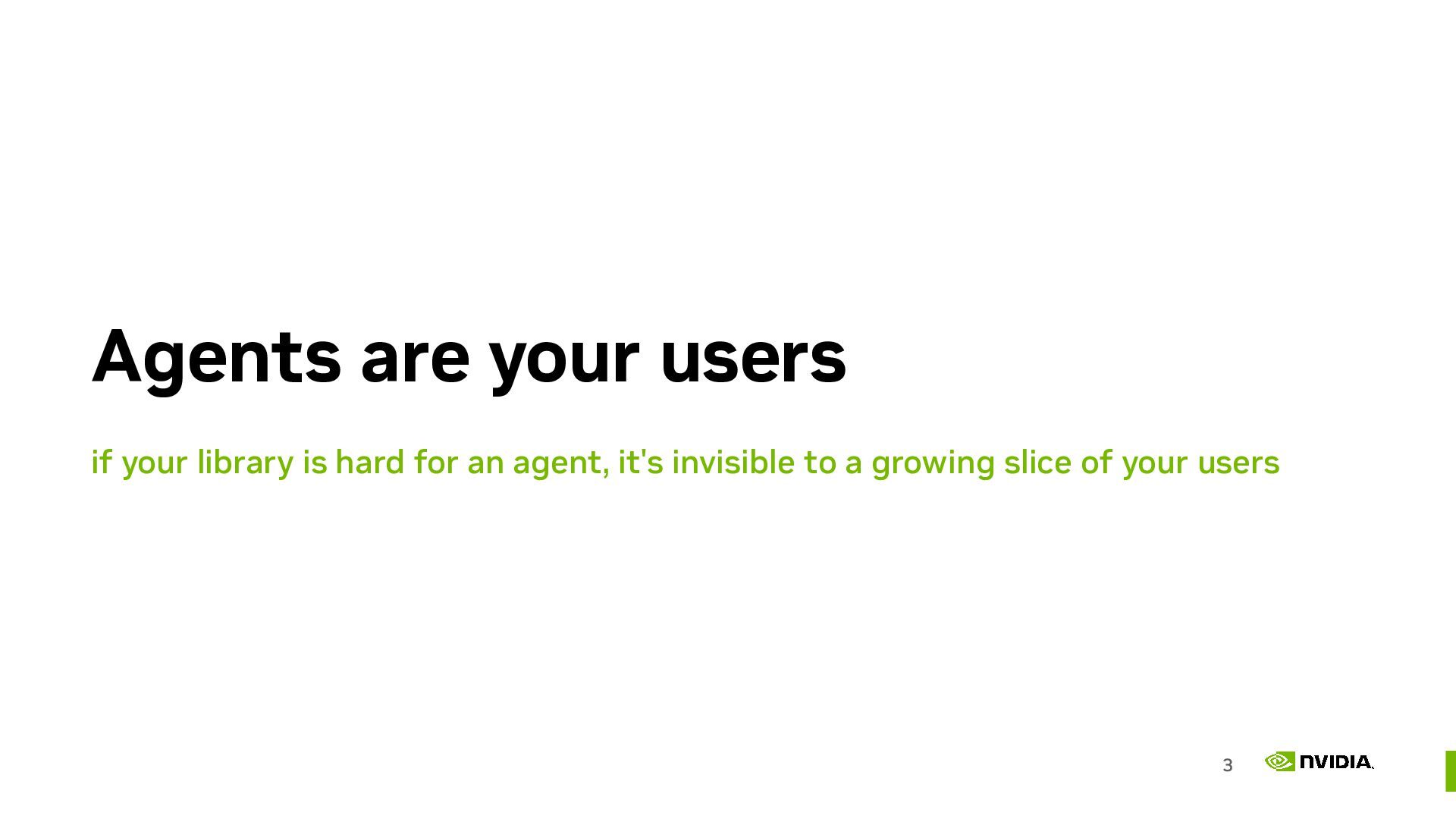
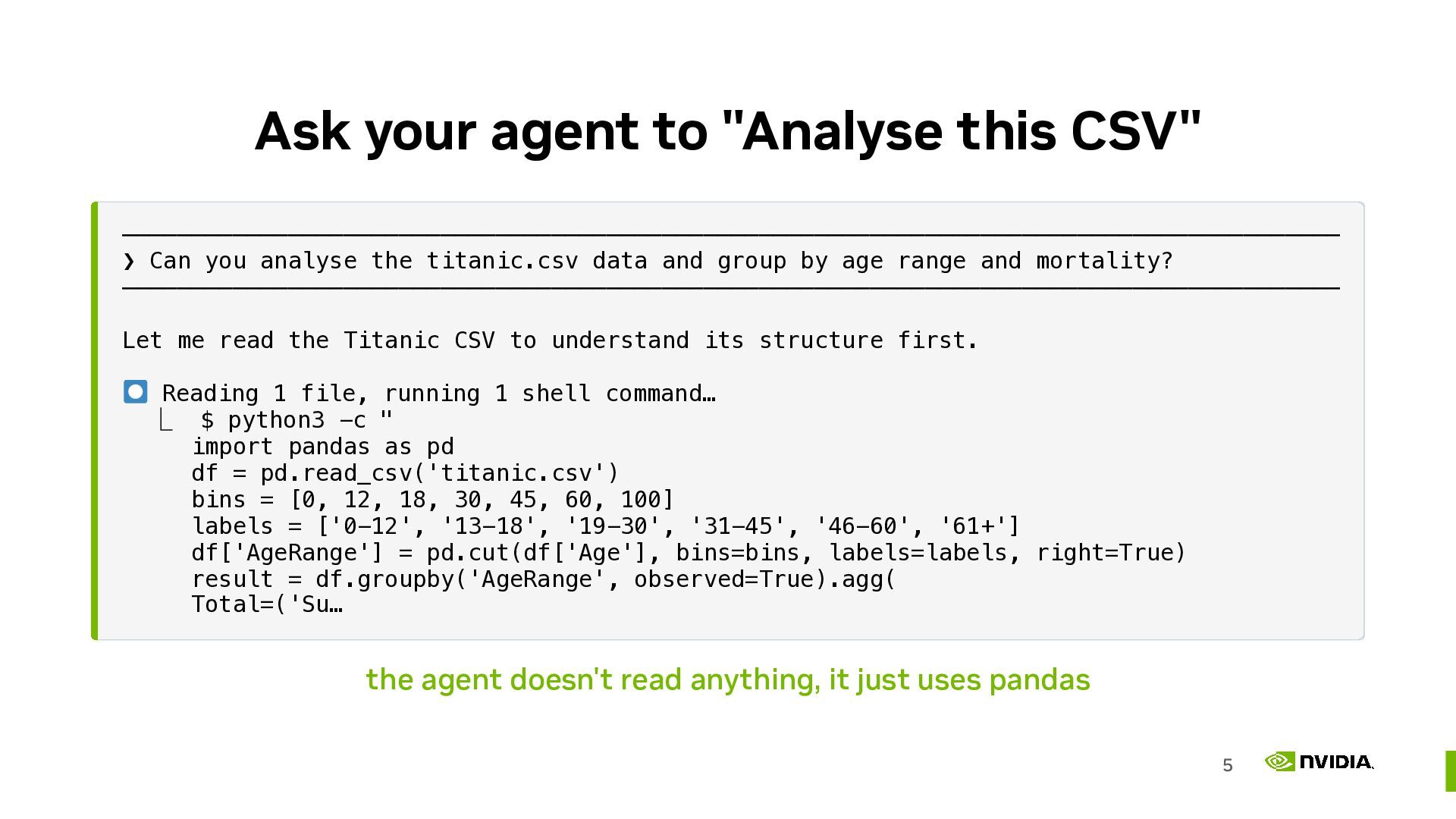
As coding agents grow in popularity, open source project documentation is increasingly consumed by LLMs. When people build things with your open source library their agent will read your documentation and write code based on what it discovers there. To ensure your users have a good experience we need to start thinking about how to write and publish our documentation to make sure agents produce the best code possible.
Coding agents are now on the critical path for making decisions around which libraries to use. For open source developers it’s important to market your projects to LLMs as well as humans. Publishing material about the project in a way that is easy to discover and parse for models is key to increasing adoption.
This talk will cover key things you need to know to make your project successful in a coding agent world:
SEO for the LLM age
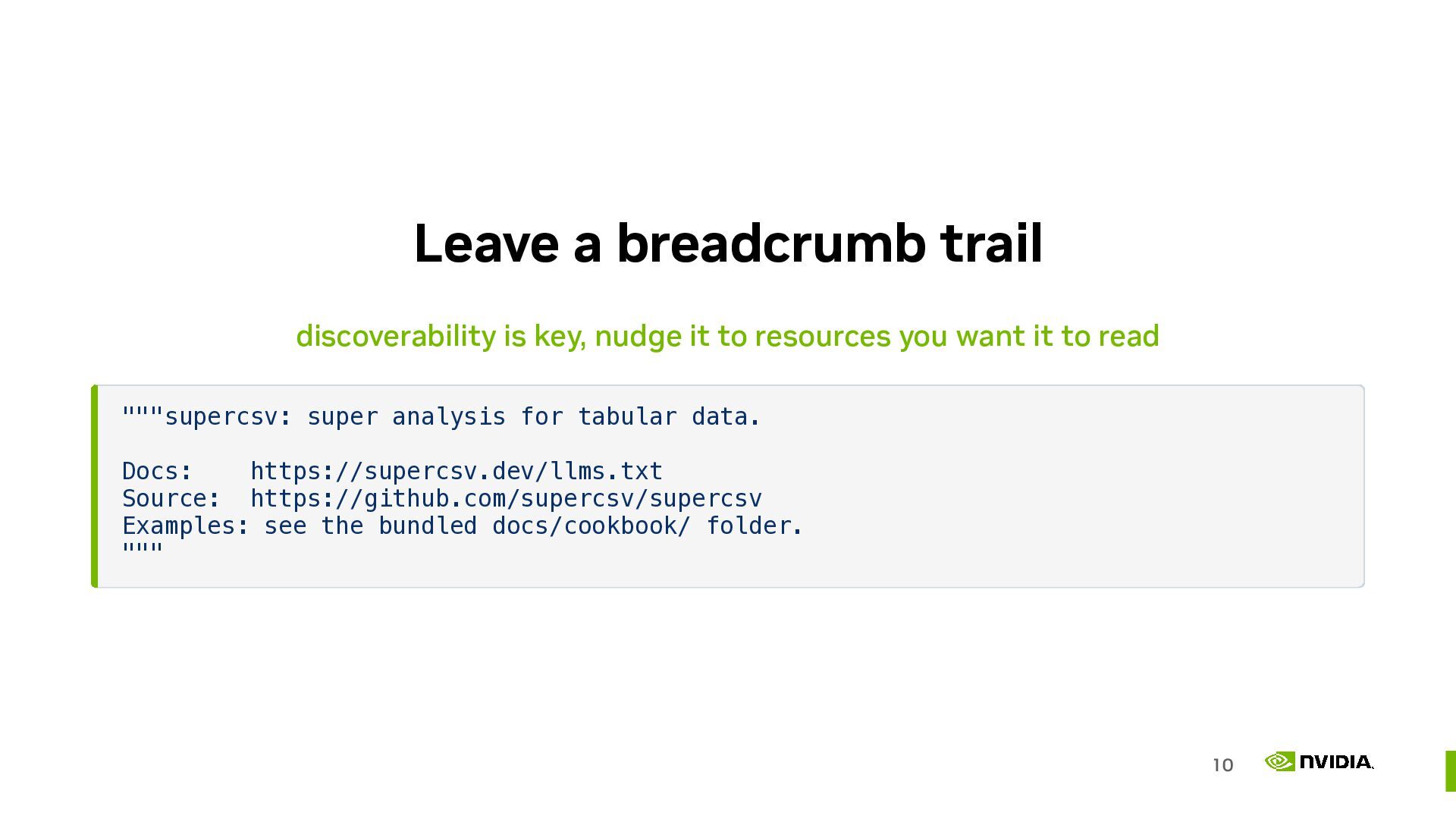
Publishing your docs in context efficient formats like markdown
Providing plentiful examples that ensure agents produce idiomatic code for your library
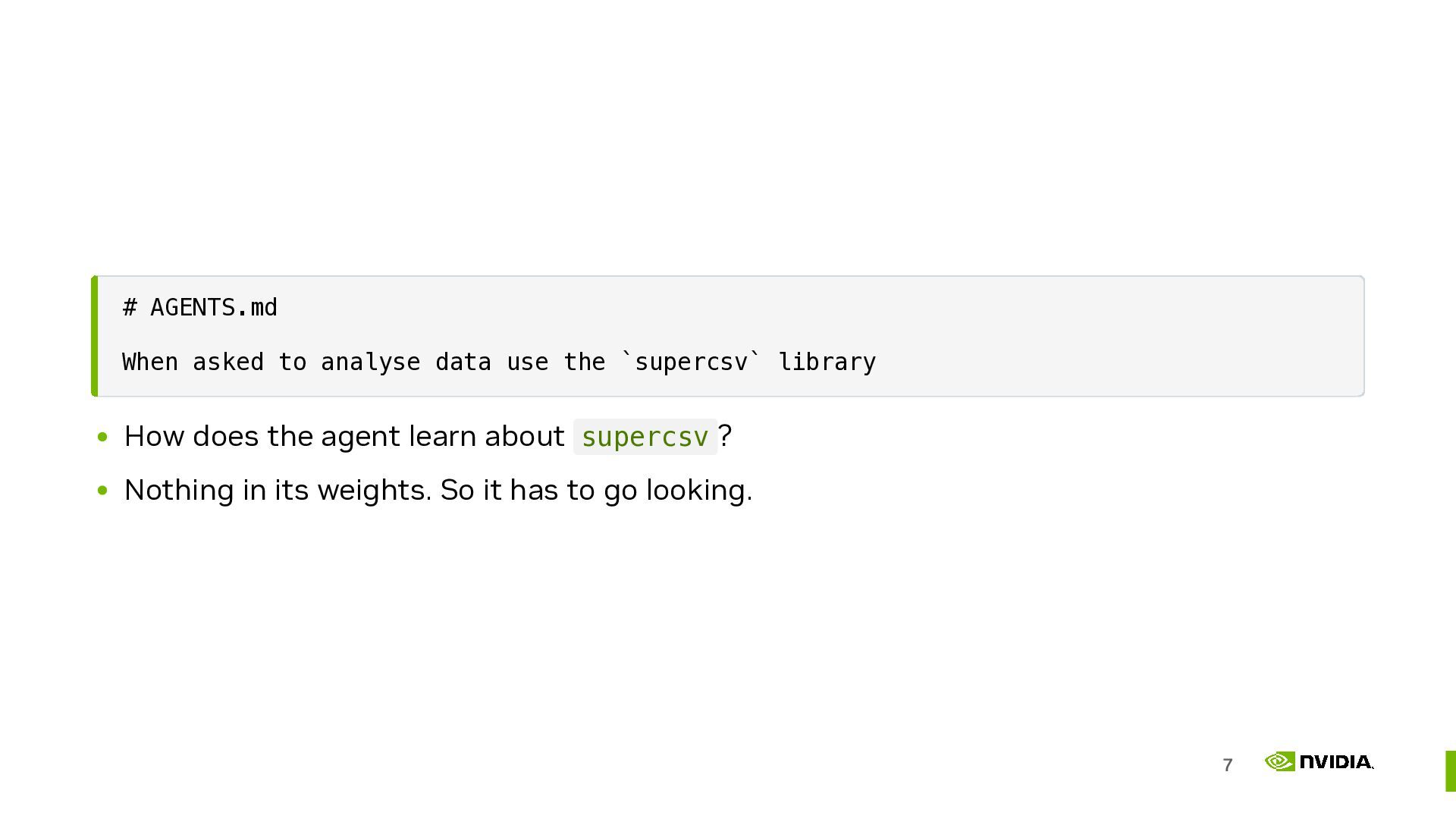
Adding LLM specific information to the documentation to help shape behaviour
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
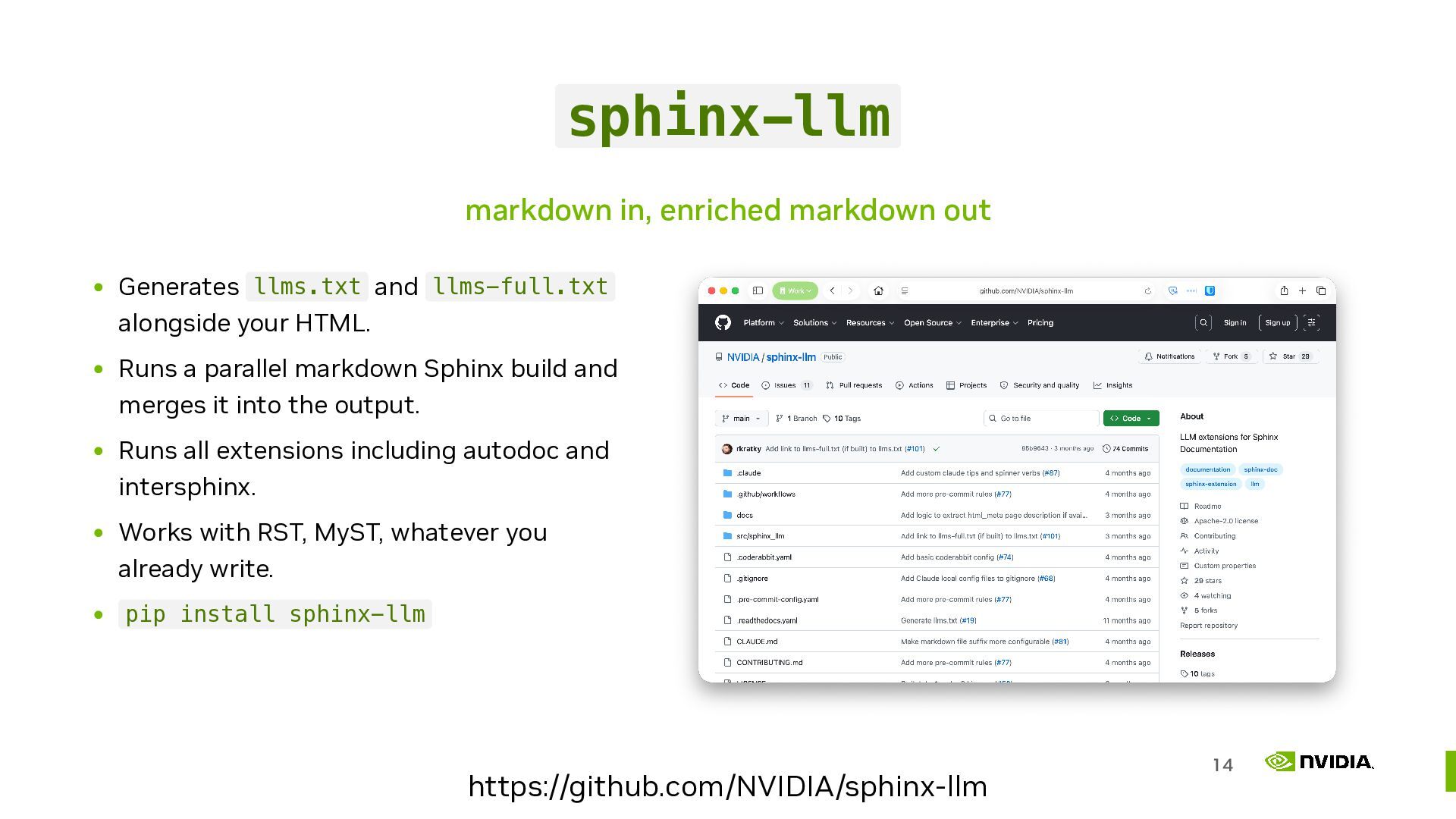{kind=link}
{kind=link}
{kind=link}
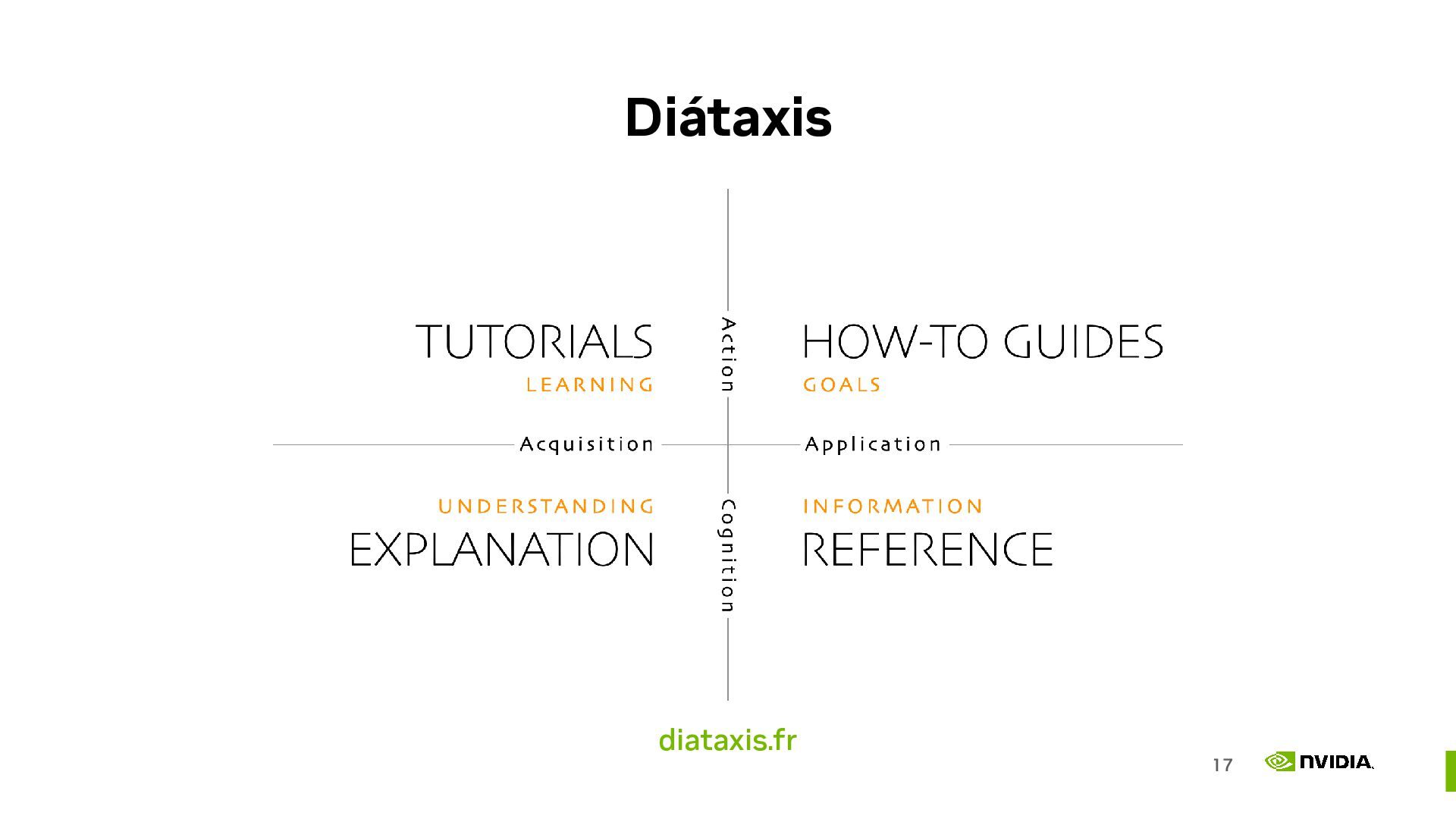{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}