I was invited to the kubernetes-batch-sig bi-weekly meeting to give an overview of Dask and how we leverage Kubernetes in Dask.
This talk starts with an overview of Dask, followed by a history of deploying Dask on Kubernetes. Then it dives into the Dask Kubernetes Operator and how it is being leveraged by the community.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
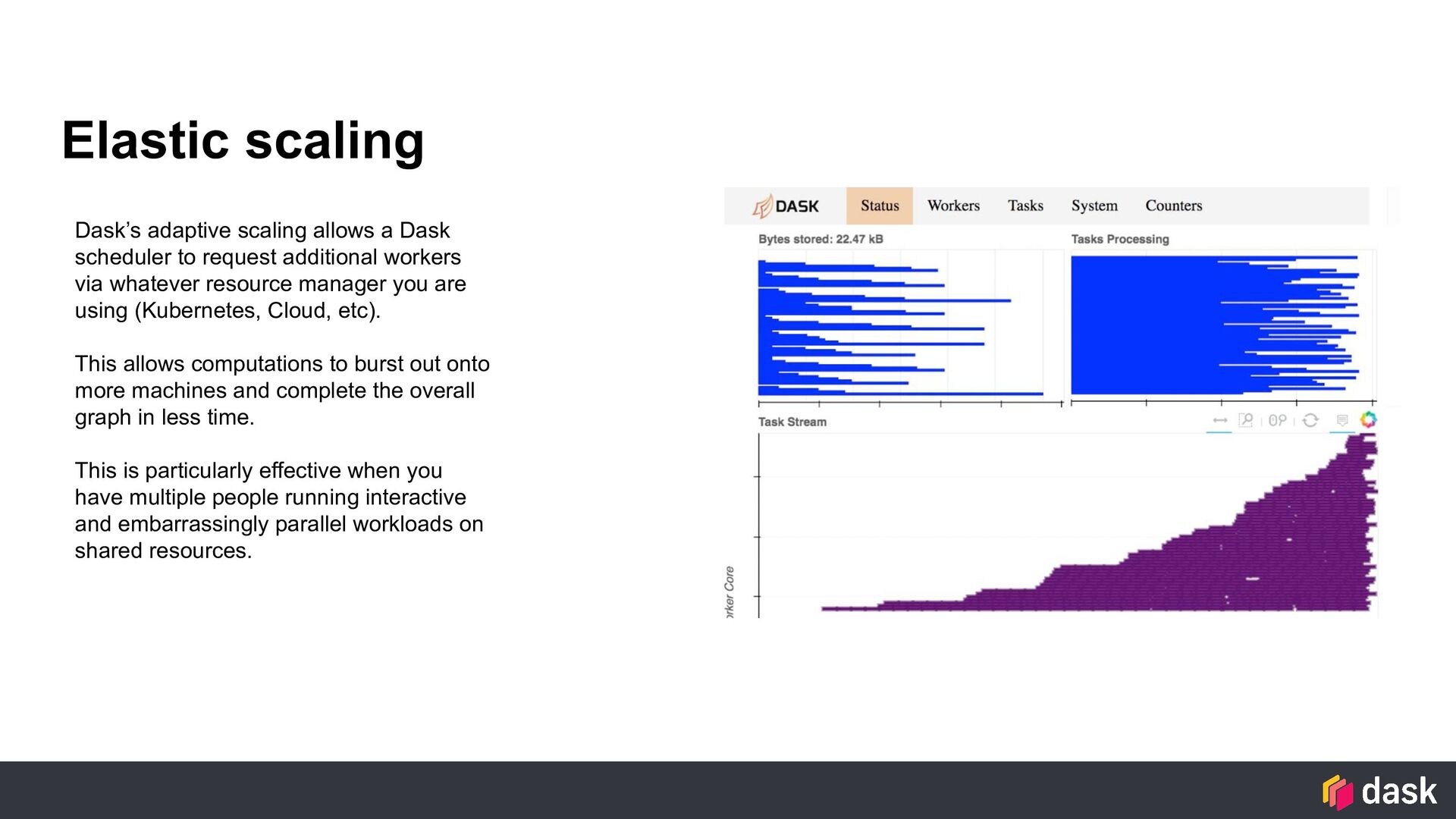{kind=link}
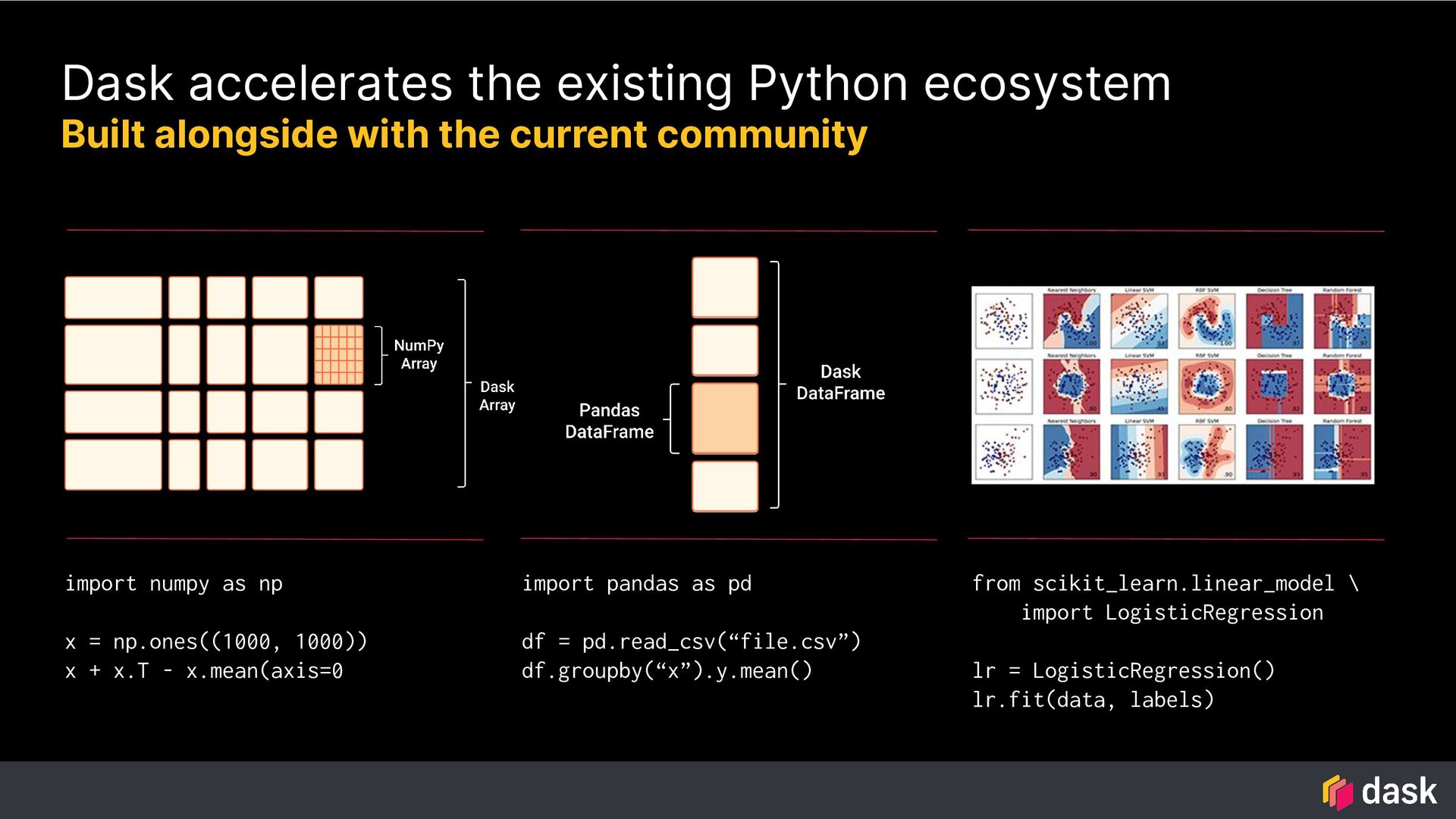{kind=link}
{kind=link}
{kind=link}
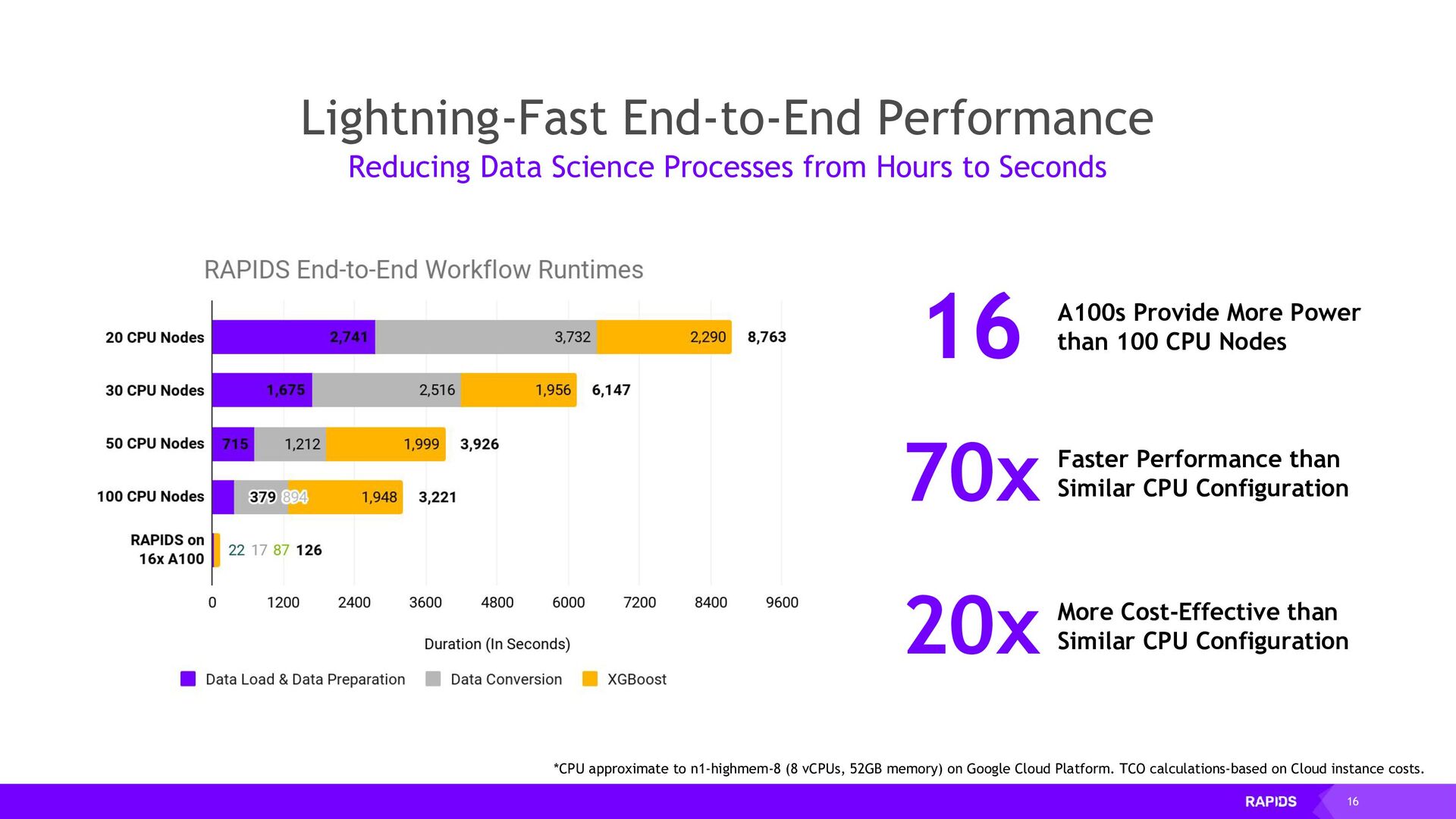{kind=link}
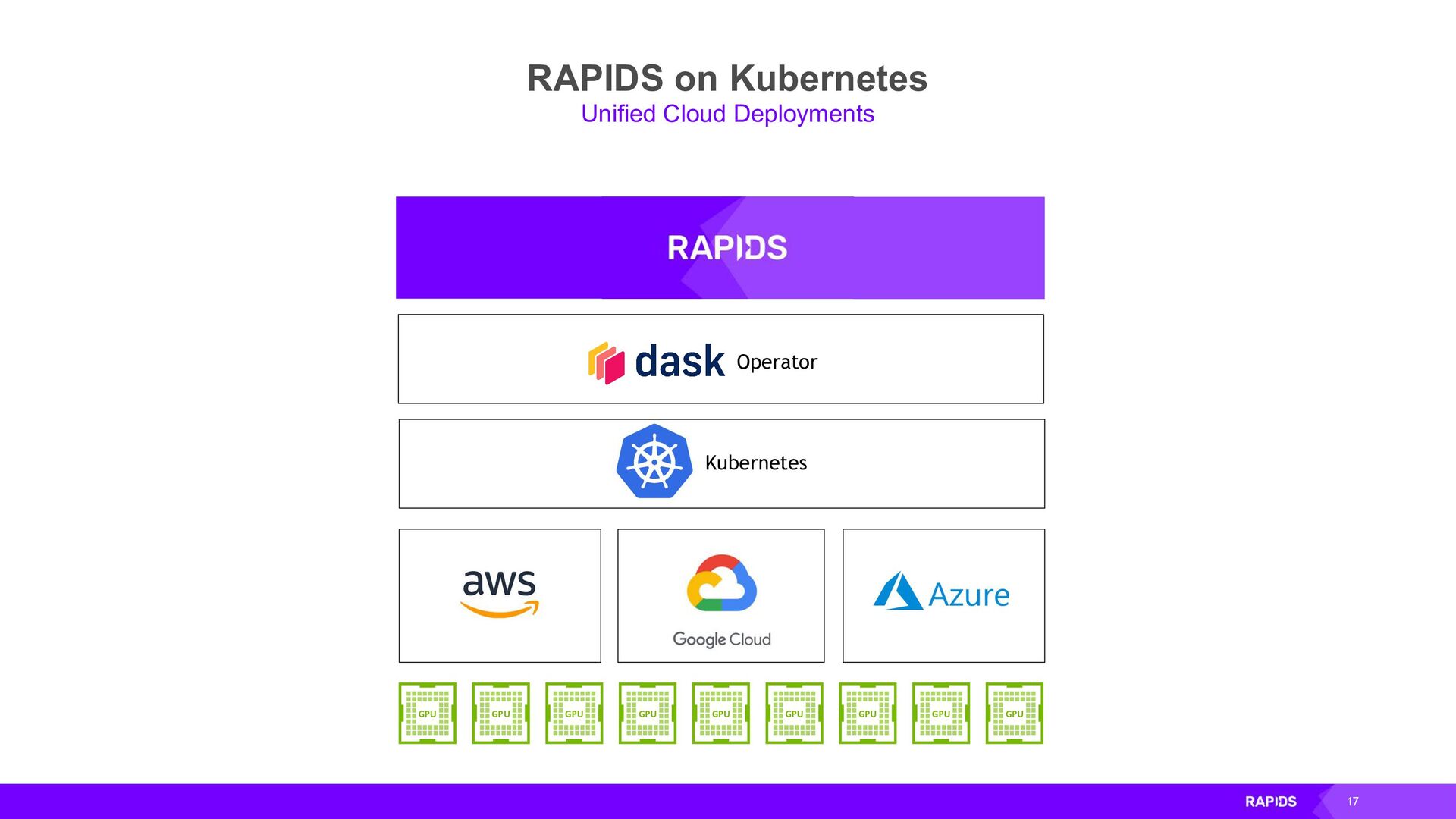{kind=link}
{kind=link}
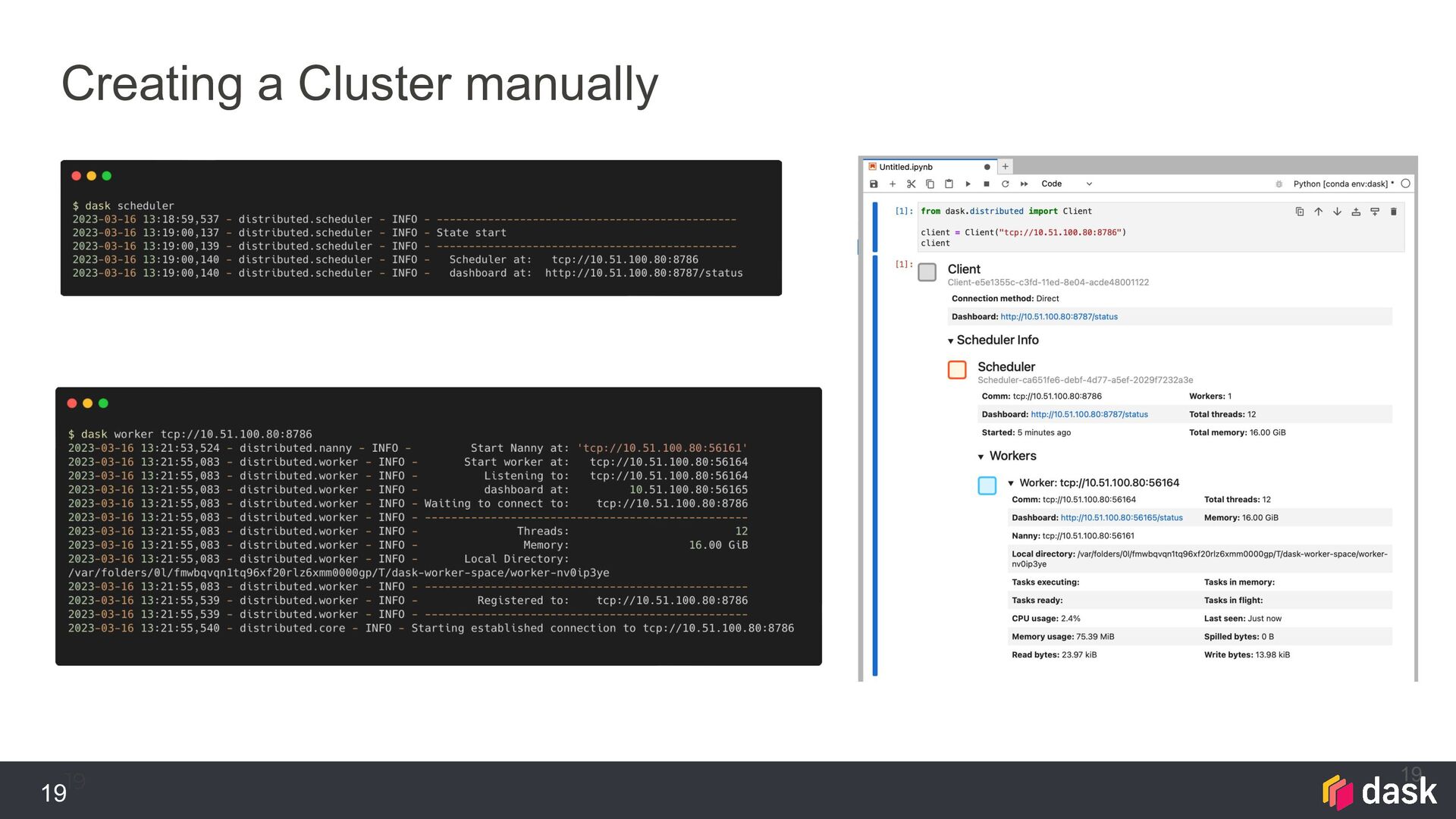{kind=link}
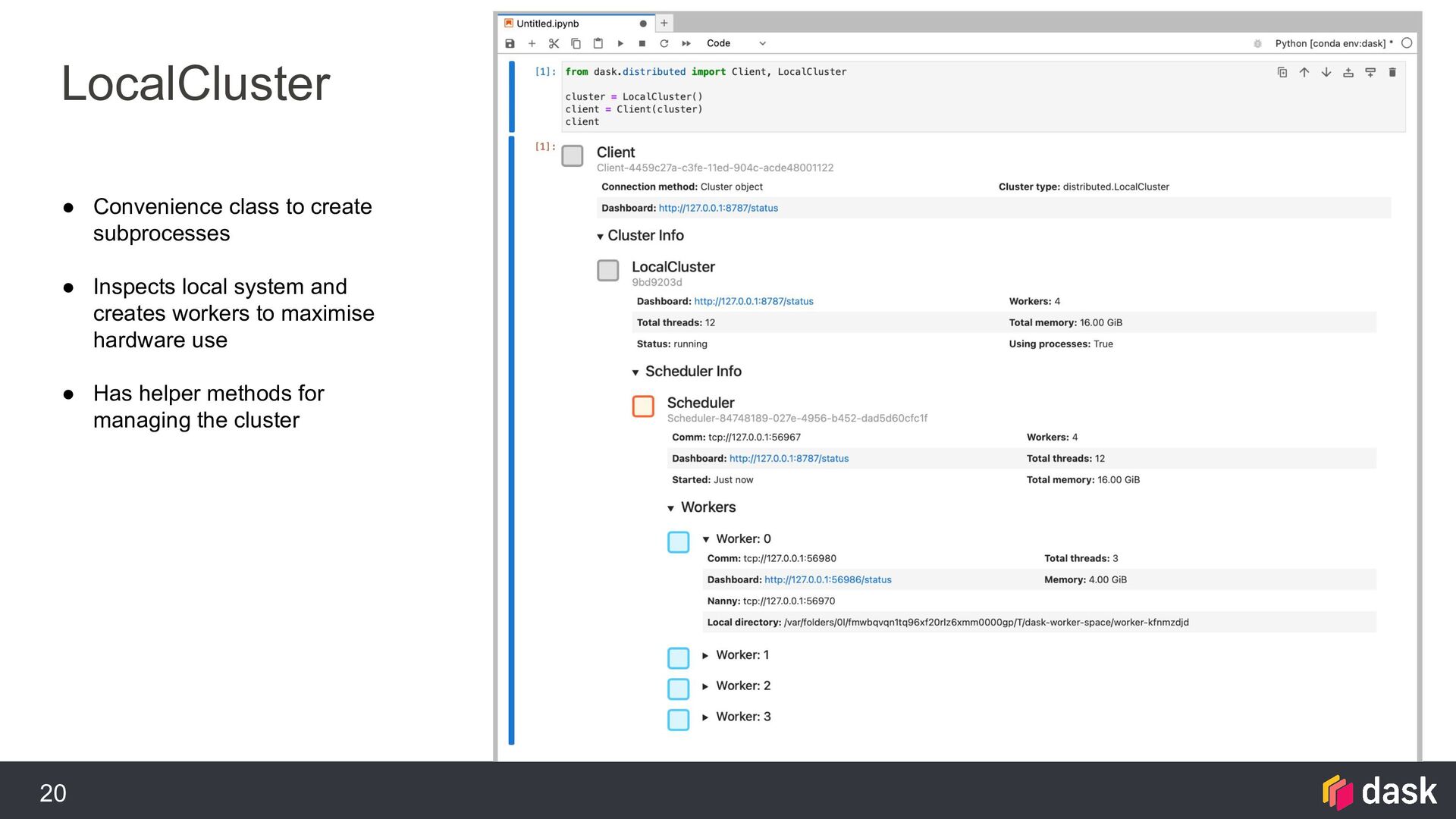{kind=link}
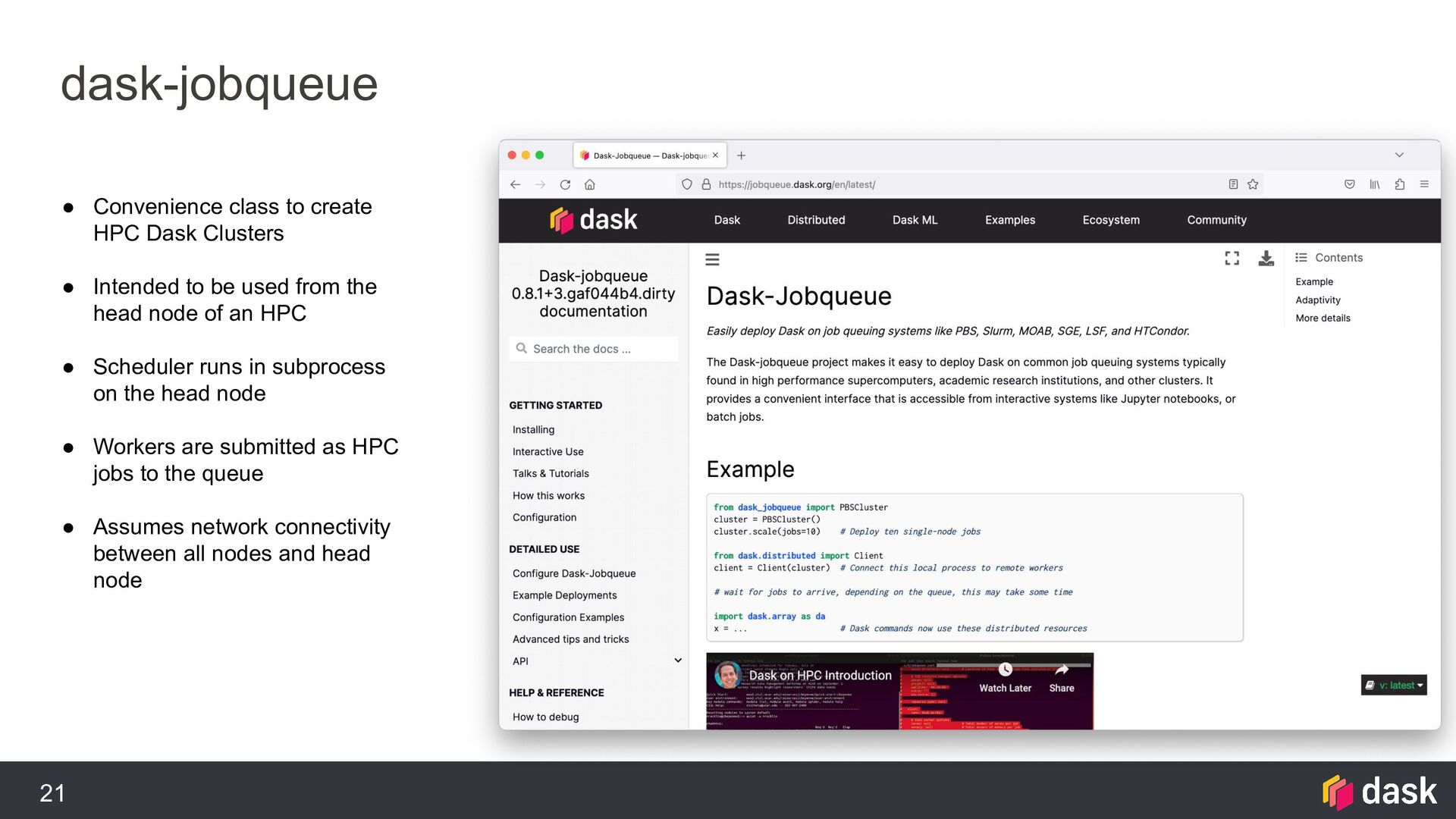{kind=link}
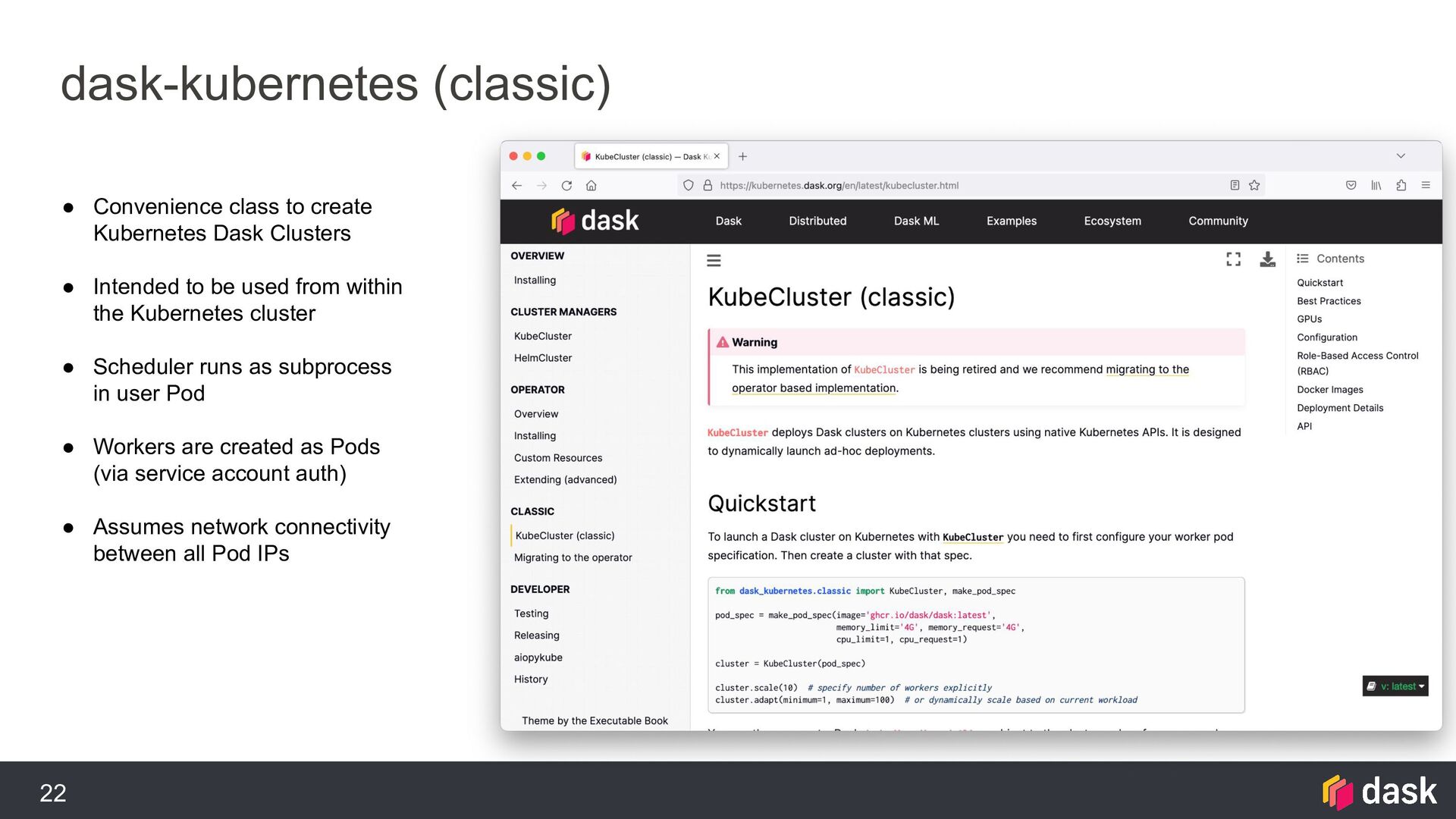{kind=link}
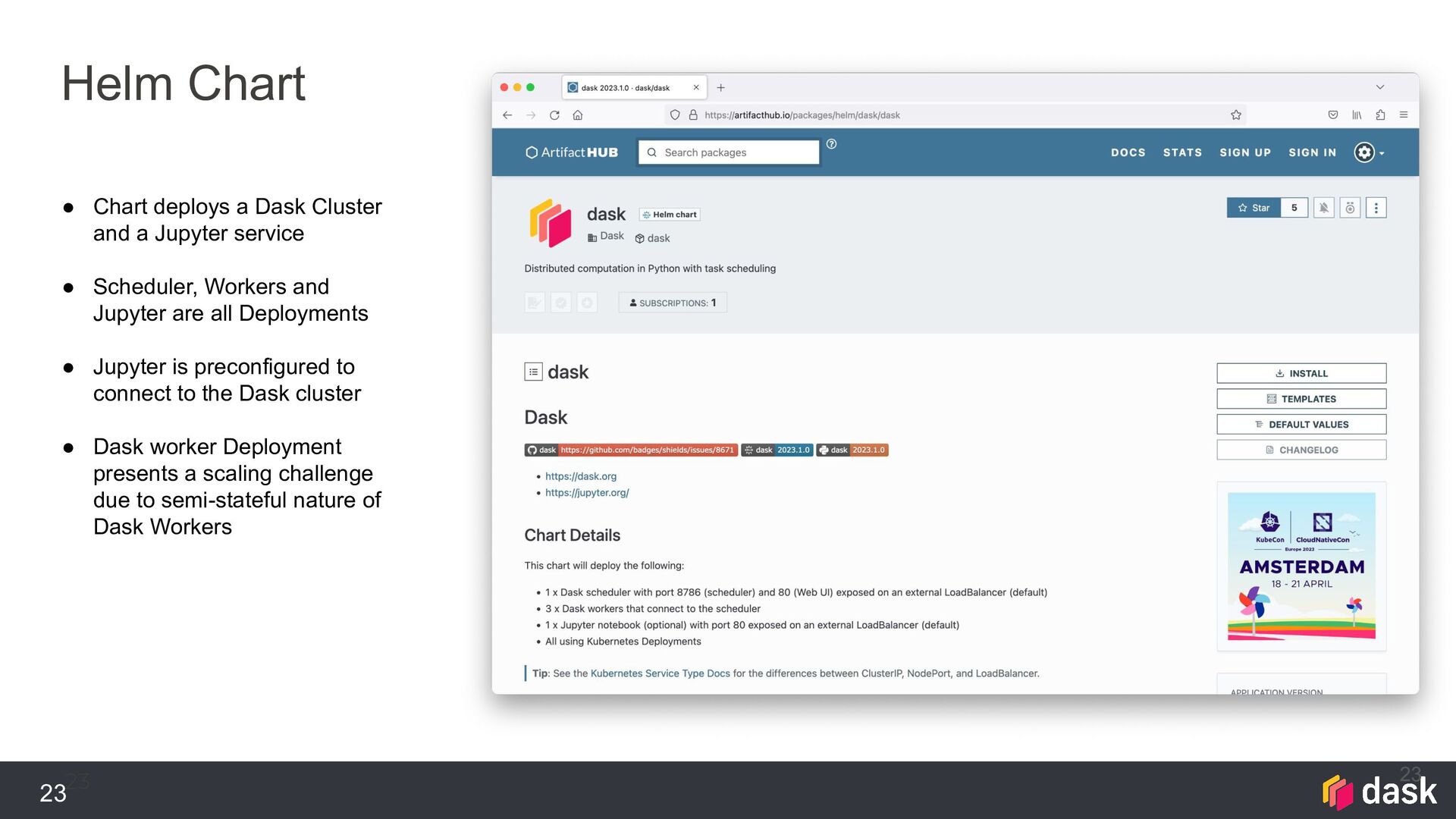{kind=link}
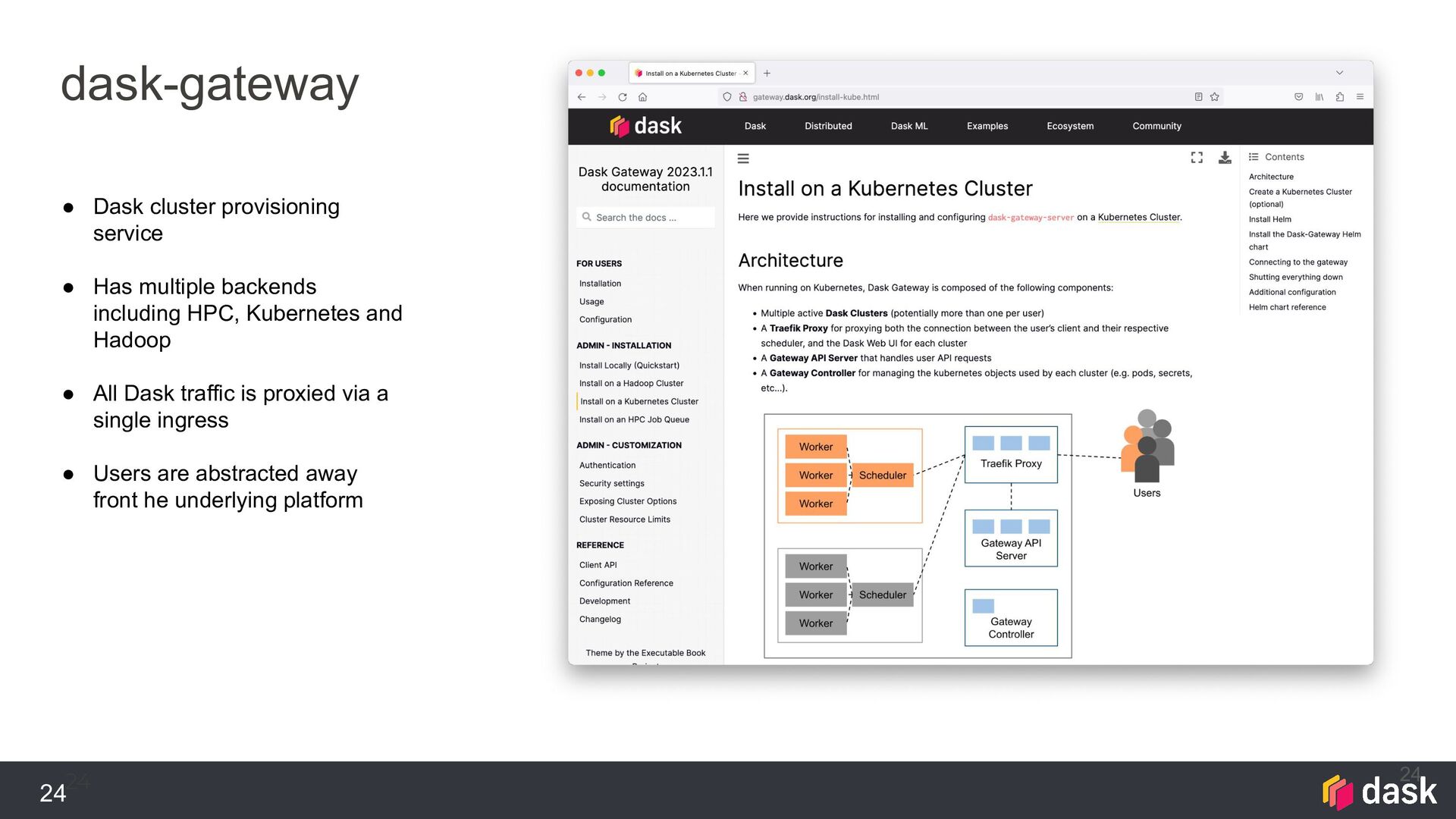{kind=link}
{kind=link}
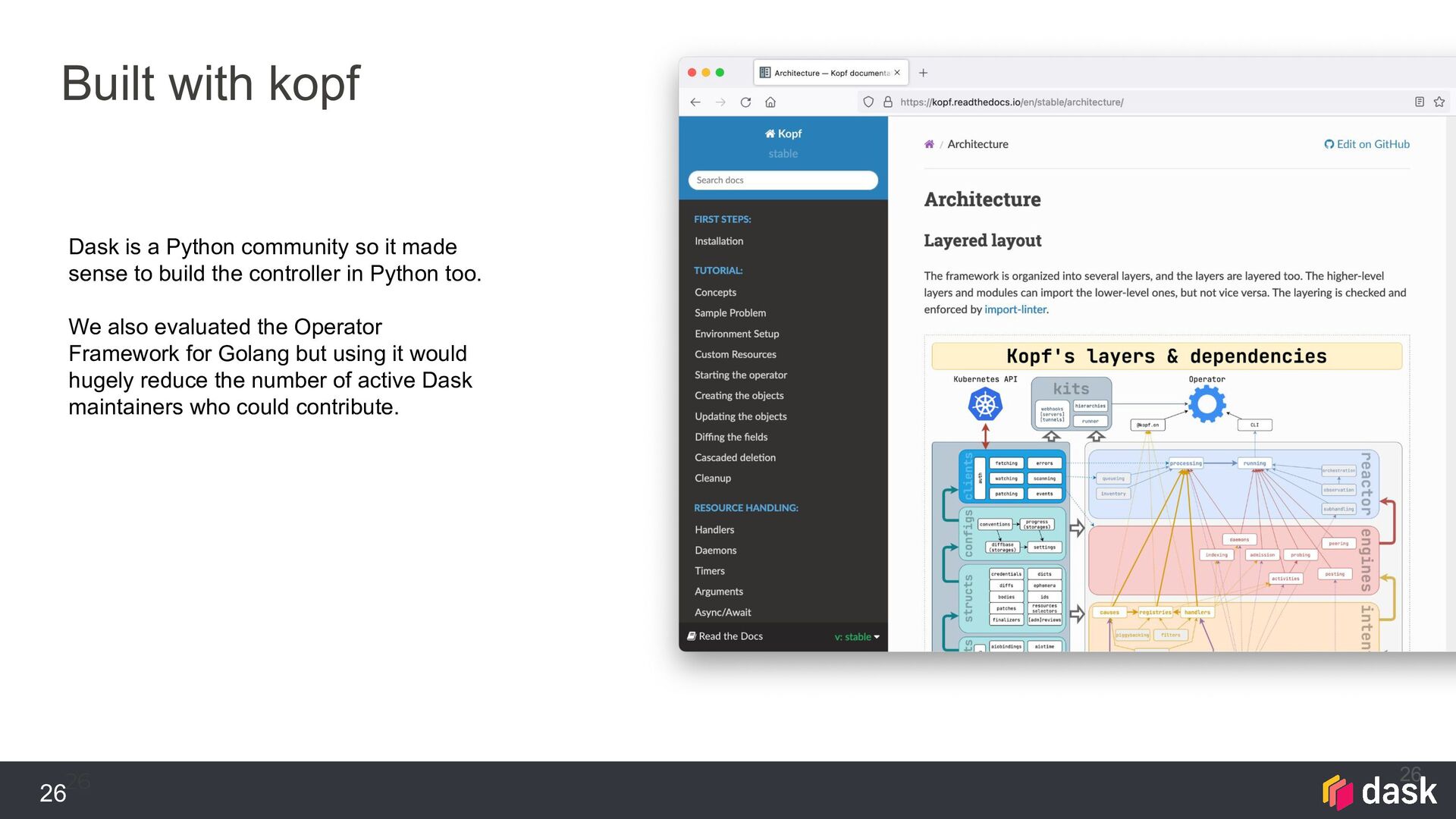{kind=link}
{kind=link}
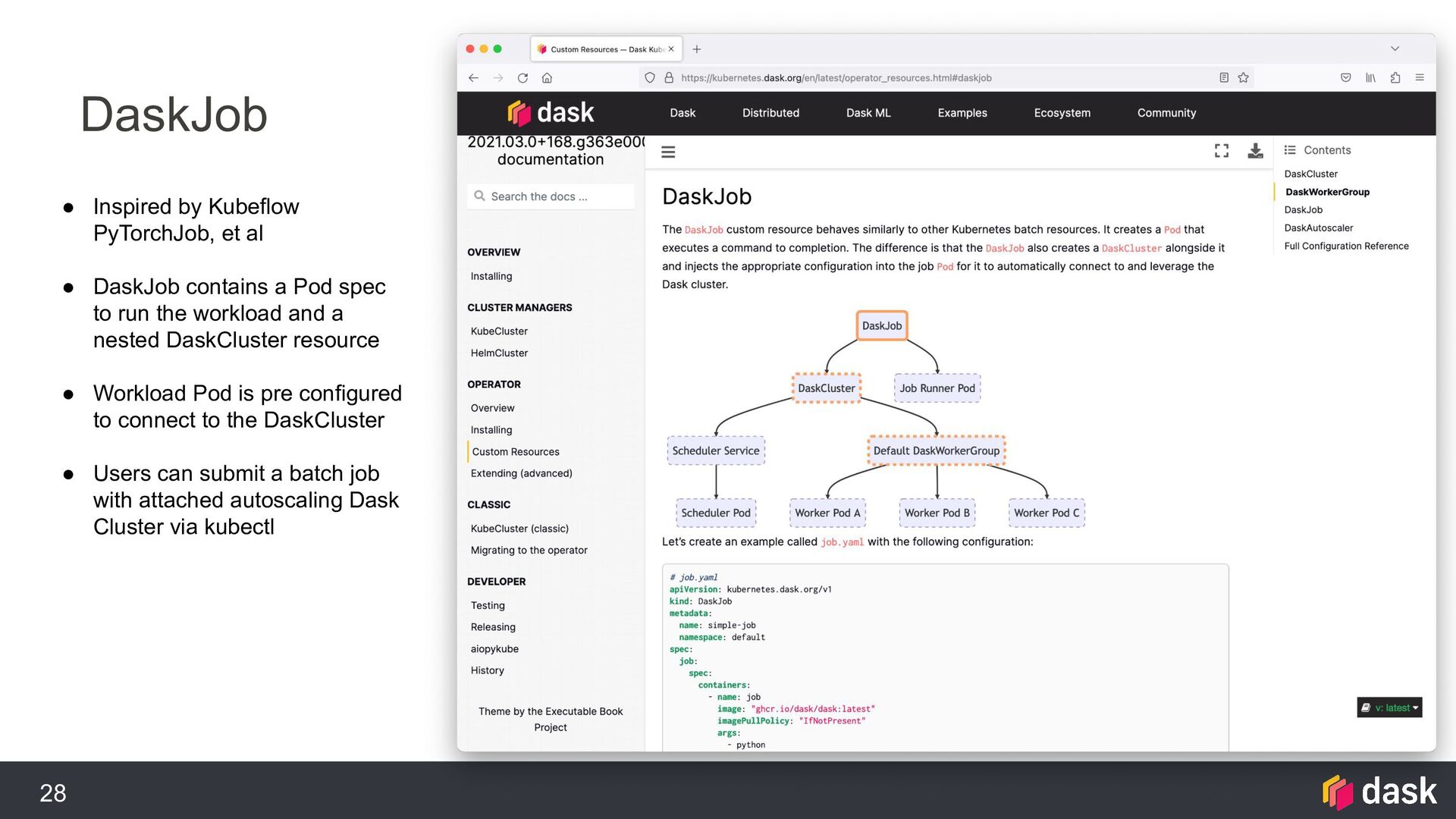{kind=link}
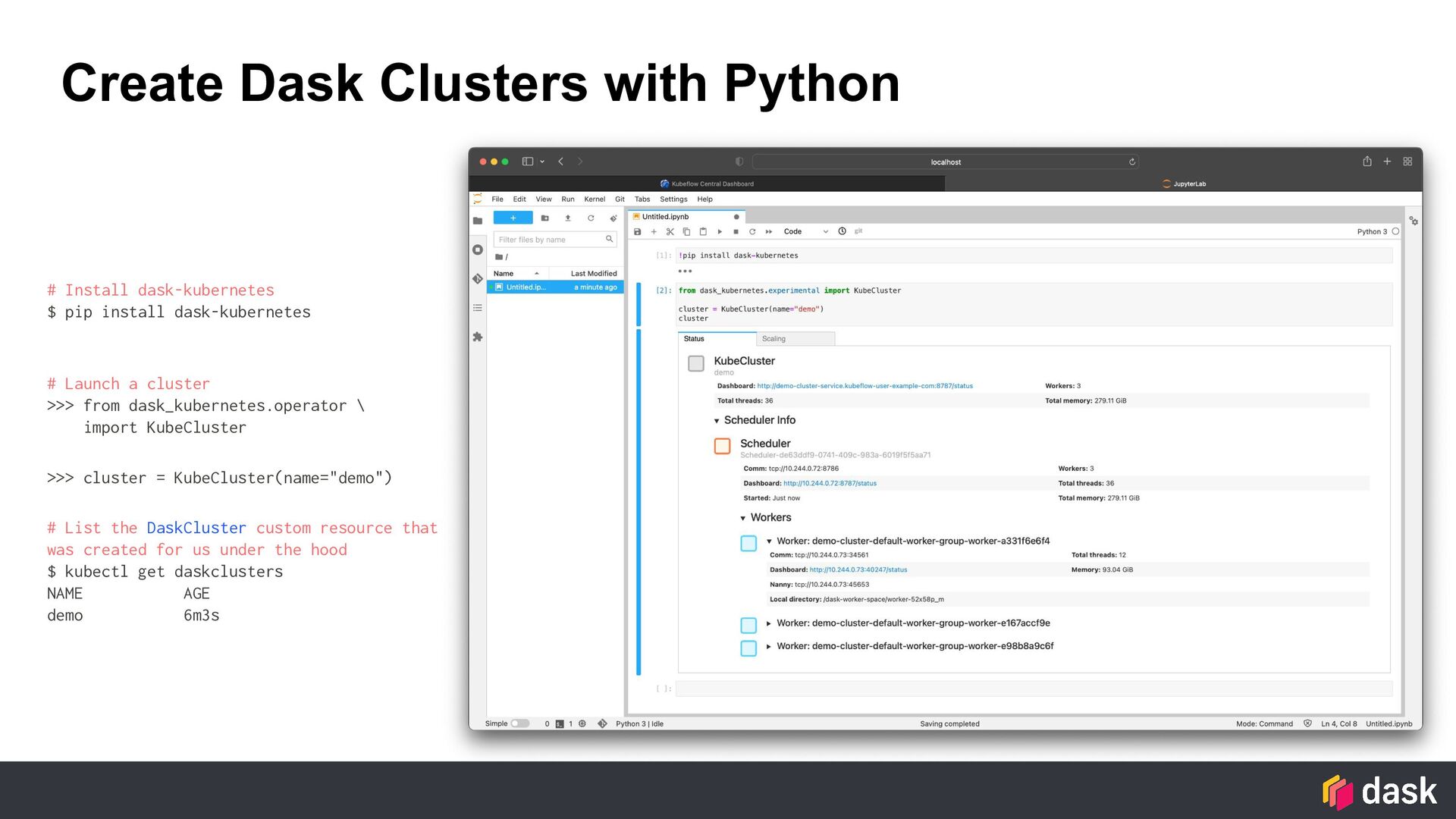{kind=link}
{kind=link}
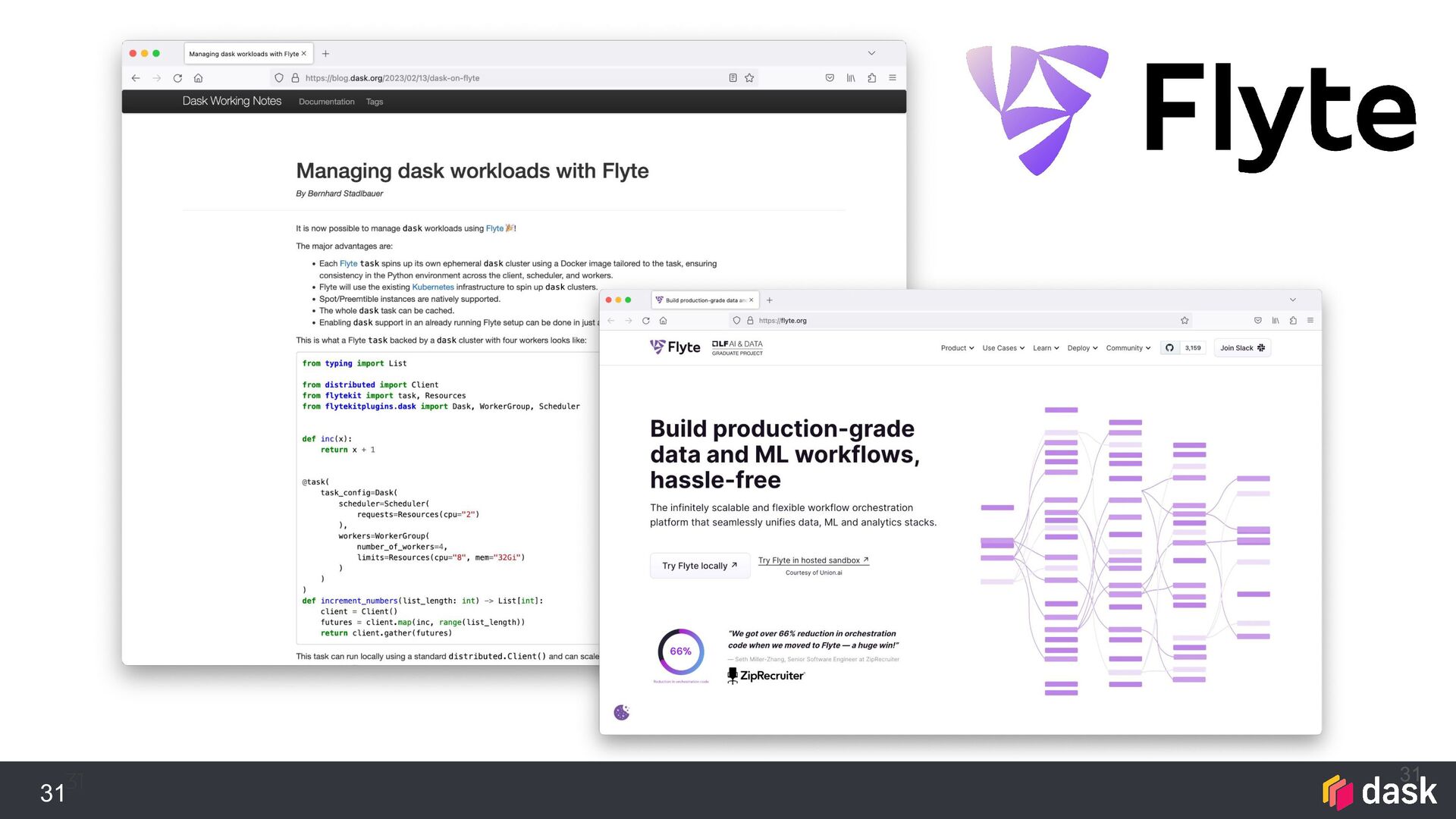{kind=link}
{kind=link}
{kind=link}