Writing code for GPUs has come a long way over the last few years and it is now easier than ever to get started. You can even do it in Python! This talk will cover setting up your Python environment for GPU development. How coding for GPUs differs from CPUs, and the kind of problems GPUs excel at solving. We will dive into some real examples using Numba and also touch on a suite of Python Data Science tools called RAPIDS.
Session takeaways
* You don't need to learn C++ to develop on GPUs
* GPUs are useful for more than just machine learning
* hardware accelerators like GPUs are going to be more important than ever in order to scale our current workloads
{kind=link}
{kind=link}
{kind=link}
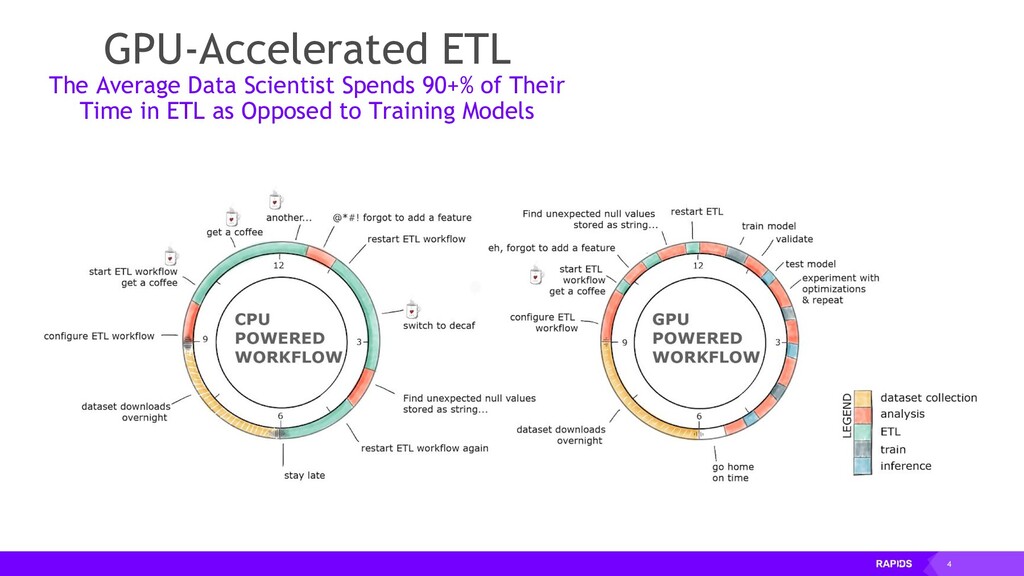{kind=link}
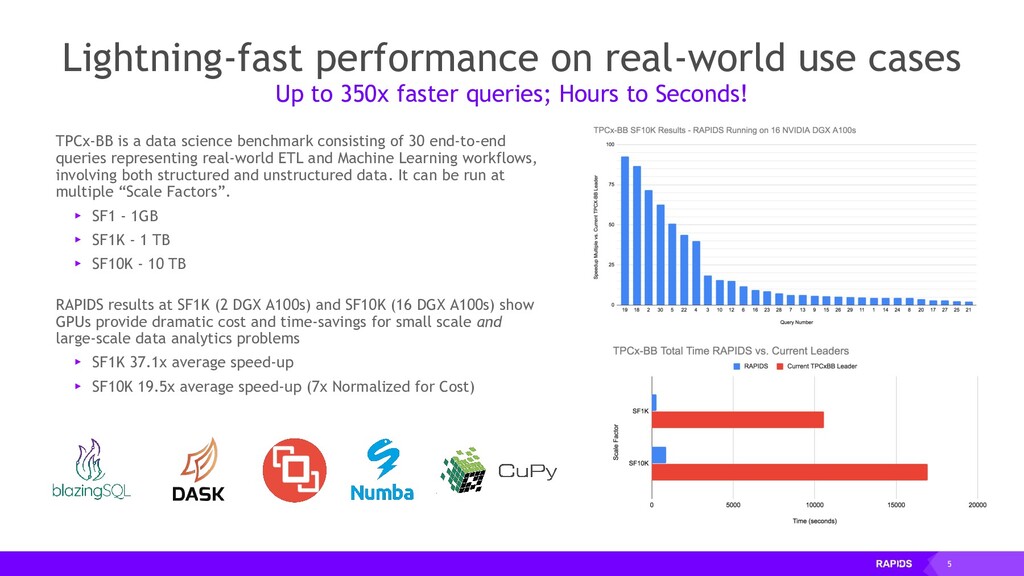{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
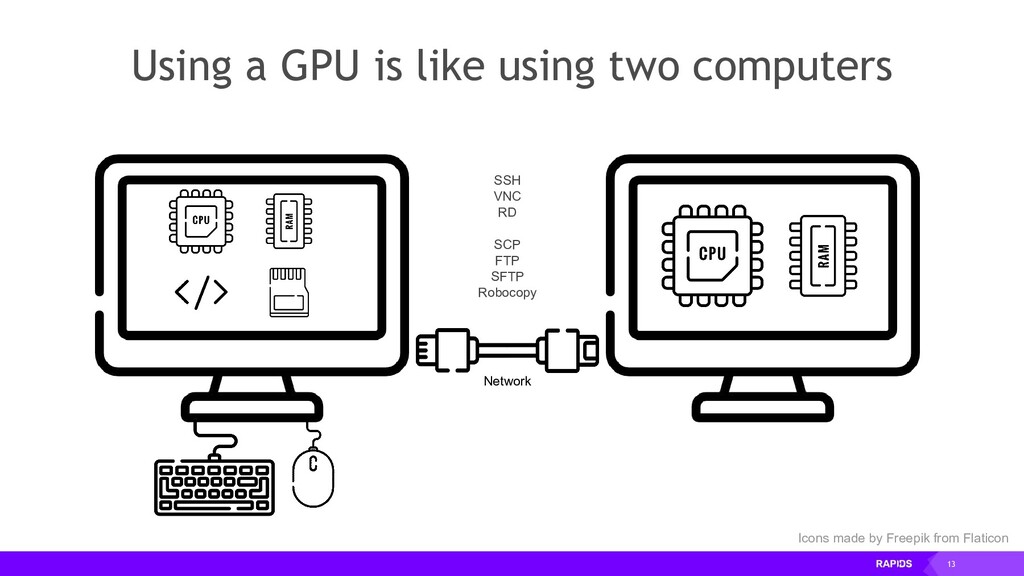{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}