»Don‘t be evil« ist das Motto der Suchmaschine Google, die als Monopolist die Informationen im Internet verteilt. Wie viel Macht hat Google dabei und warum? Was sind die Risiken? Wenn Google alle Informationen kontrolliert, wer kontrolliert dann eigentlich Google?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
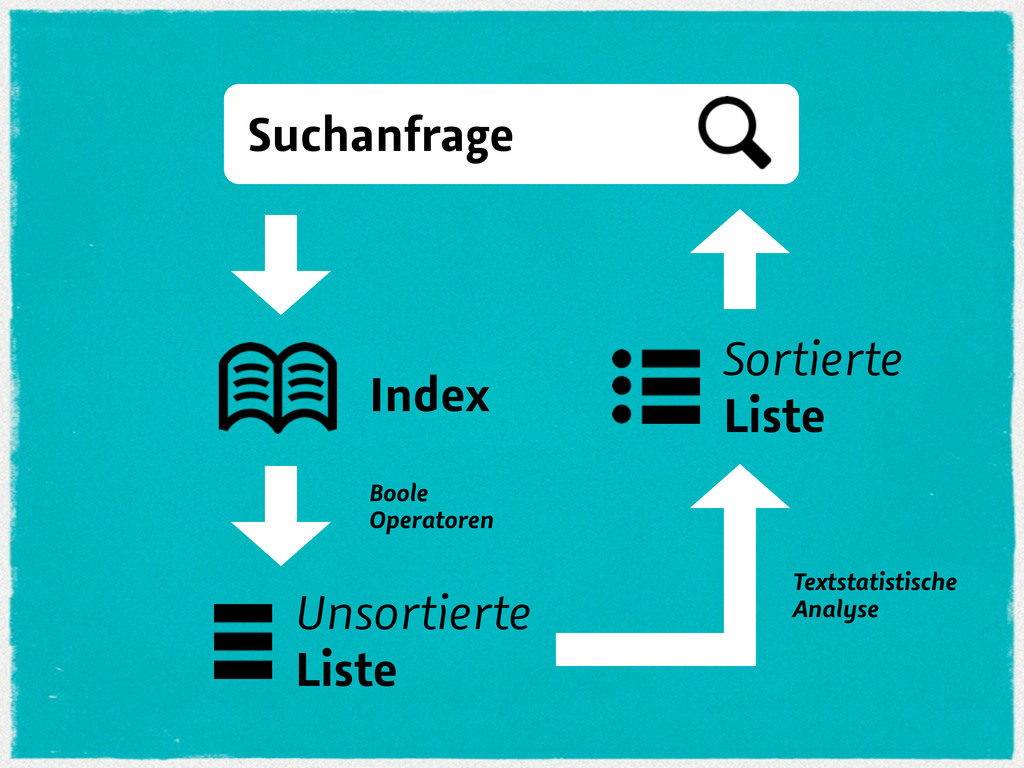
![Van Couvering, 2007: »[...] wurde die Di"erenzierungskraft der textstatistischen Verfahren](https://files.speakerdeck.com/presentations/49c72690cde20130823c4eed7ec0da39/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
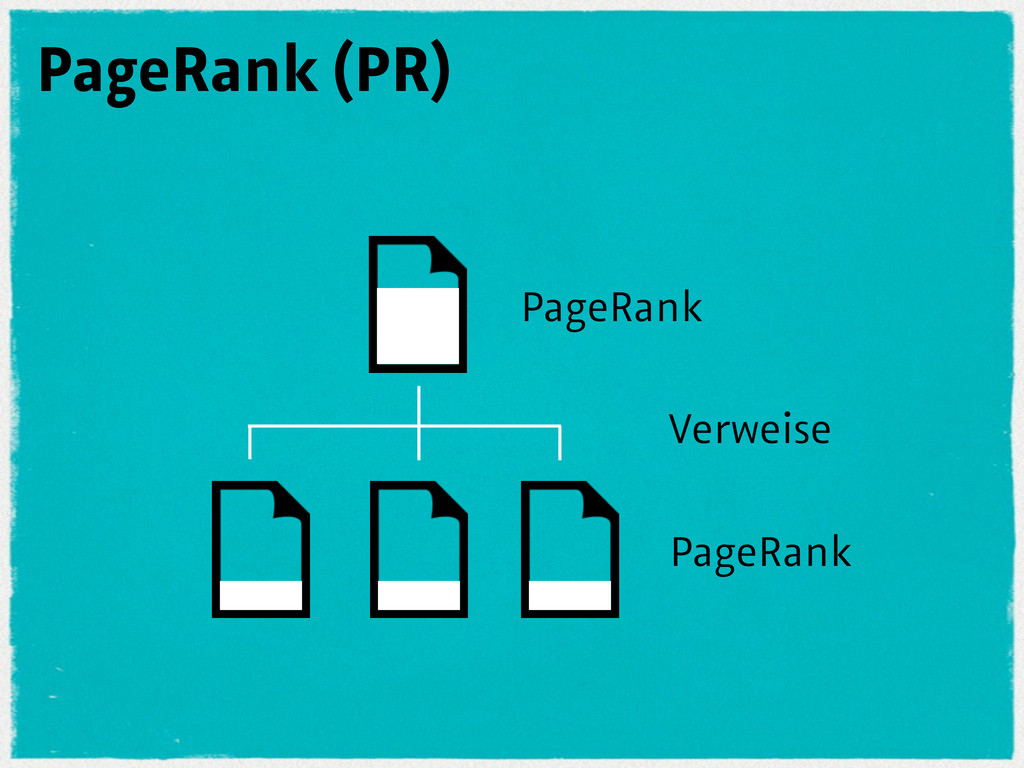{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• shareholder democracy [Finkelstein, 2008] • Gut verlinkte Seiten haben](https://files.speakerdeck.com/presentations/49c72690cde20130823c4eed7ec0da39/slide_74.jpg){kind=link}
{kind=link}
![• Matthäus-E#ekt [Merton, 1986] • Cumulative Advantage [Price, 1976] •](https://files.speakerdeck.com/presentations/49c72690cde20130823c4eed7ec0da39/slide_76.jpg){kind=link}
![• Bei Chakrabarti / Frieze / Vera [2006] wird Google](https://files.speakerdeck.com/presentations/49c72690cde20130823c4eed7ec0da39/slide_77.jpg){kind=link}
![• Pasquale [2006]: Das Problem, dass PR ein relativer Wert](https://files.speakerdeck.com/presentations/49c72690cde20130823c4eed7ec0da39/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}