the cloud tend to span across multiple processes and computers • Applications are broken into specialized parts • Each part has duplicate copies, either for resiliency or scale • A traditional operating system can’t reason about or manage them
of computation on the cloud computer are containers (eg Docker) • Containers are grouped into pods, similar to a group of threads forming a process • Inter-process communication is largely over TCP/IP network connections • Contention and coordination between containers is managed externally ◦ Eg, we use ZooKeeper for service discovery and routing
invented to prevent a producer writing to a buffer faster than a consumer could read • Producer/consumer problems arise in many places in cloud apps ◦ Processing webhooks ◦ Writing to a 3rd party API faster than it can receive ◦ Job queues “consuming” the available worker pool • In many cases we don’t have shared state between producer and consumer that can be used to store a shared semaphore • Sometimes have other feedback mechanisms such as HTTP 429 (“too many requests”) • When there is no feedback loop we can use a producer-side semaphore (circuit breaker)
of available job workers • If all workers are busy, we can have starvation of waiting jobs • Notably, payment jobs are used to complete purchases • A large flash sale could exhaust workers for all shops • We use a semaphore to limit number of payment jobs running per pod
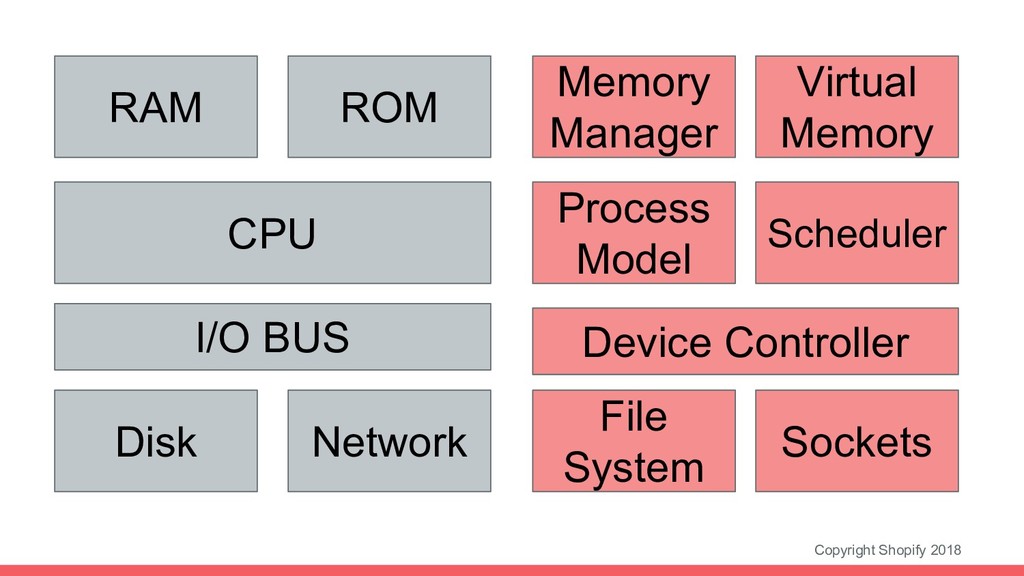
need memory allocation just like normal processes • Kubernetes scheduler is a cross between a memory manager and a process scheduler • Scheduler allocates containers to physical computers (nodes) based on memory and CPU requirements (also potentially disk and other resources) • Containers can be swapped and evicted just like memory blocks and processes on a local computer
key differences between allocating CPU and memory? How can we handle exceeded limits in each case? How do we make maximum use of the underlying resource?
are ephemeral and disposable ◦ Eviction means killing the container • Any valuable state needs to be stored externally • Apps like Redis and memcached act like “RAM” of the cloud computer • Two main uses for shared memory: caches and queues • Cache memory is not allocated to a container, it is typically MRU • Queue memory is segmented by priority
is performed by background jobs • Dedicated group of containers constantly running jobs • We use resque which is a job scheduler built on redis • FIFO with multiple queues based on priority • Big jobs must be preemptible ◦ We built a custom framework for Shopify core: BackgroundQueue::Iteration
apps receive millions of HTTP requests/minute at all times • We need to spread these requests out to handle the load ◦ Much like an OS process scheduler allocating CPU time for processes • We use a mixture of commonly used algorithms ◦ Exponentially Weighted Moving Average (EWMA) - most recently least loaded ◦ Round Robin (RR) ◦ Power of 2 Choices (P2C) - Pick two at random, select least loaded
between fast processors and slow I/O • Spools allow many things to write to one consumer in an orderly way • Kafka is a messaging system used heavily at Shopify, for similar reasons • Producers can deliver messages to a local Kafka client quickly • Kafka then sends them to a server, where they are spooled by topic • Consumers can consume from the spool/topic at their own pace
Independent Disks (RAID) is a way of configuring disk drives • Distributed databases use a similar strategy to store multiple copies • ElasticSearch is one example that we use. It stores documents in multiple nodes, somewhat like block-level striping in RAID-5 • When one node (disk) fails, nothing is lost, but the entire cluster (drive) has slower performance while it rebalances
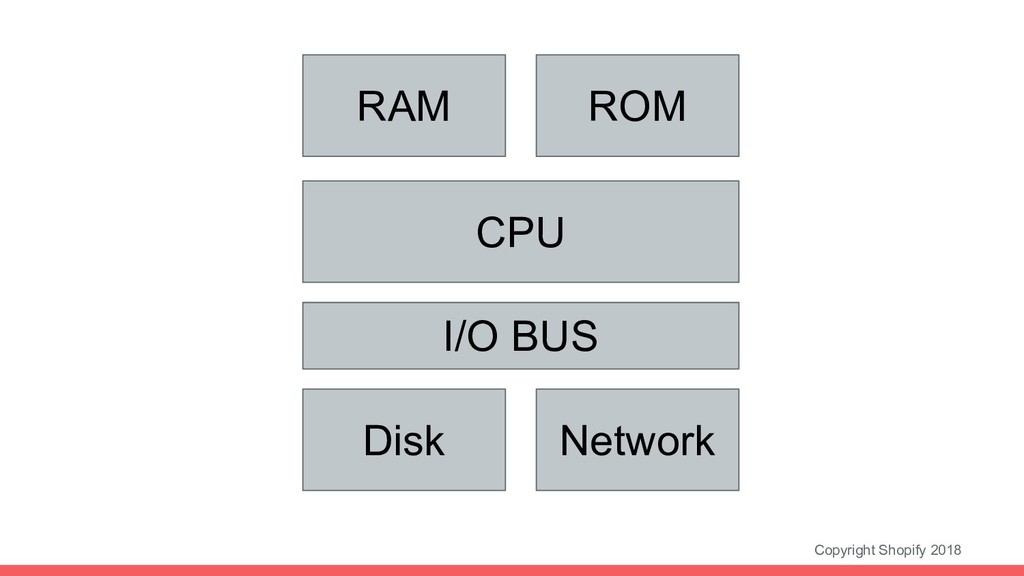
of abstractions to make life easier for application programs (and their developers) • Modern web apps run across hundreds or thousands of hosts (the “cloud computer”), where OS-level abstractions can’t help us • Many of these OS abstractions are applicable in surprising ways for apps running on the “cloud computer” • This is NOT a straight-forward mapping, but frameworks such as kubernetes help simplify some of the problems that emerge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}