of rapid delivery 2013: Capistrano deploy by dedicated ops team 2014: 3rd party CI, struggling with scalability and production fidelity 2015: Building out new generation deploy pipeline
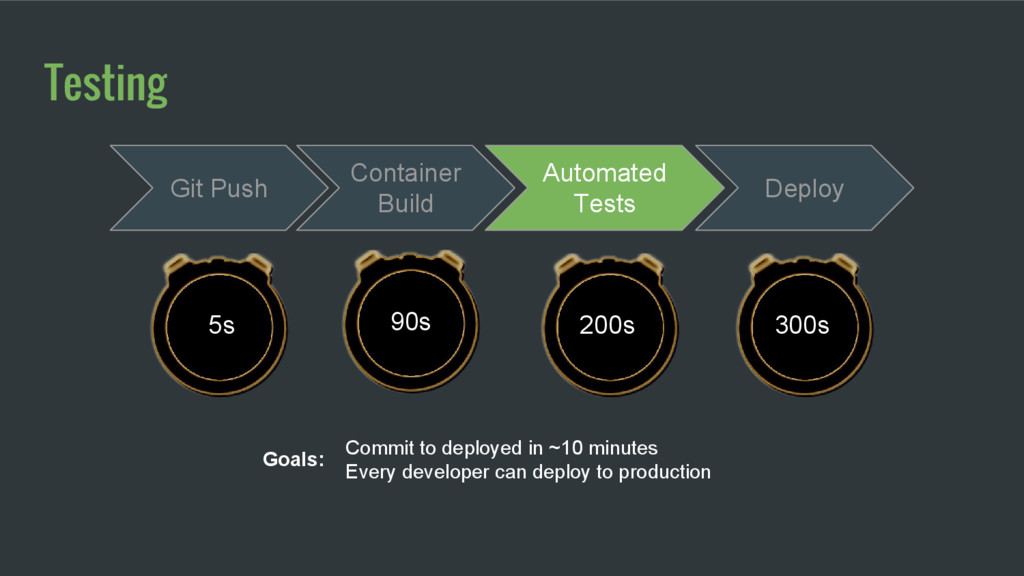
developers Faster time to a fix for customers Continuous uptime requires many small changes which magnifies wait times But the #1 reason: keeping the batch size small
master on a busy day Commit every 3 minutes assuming 8 hour work day 3 minute deploy required for smallest batch size Builds have to keep getting faster to keep batch size down
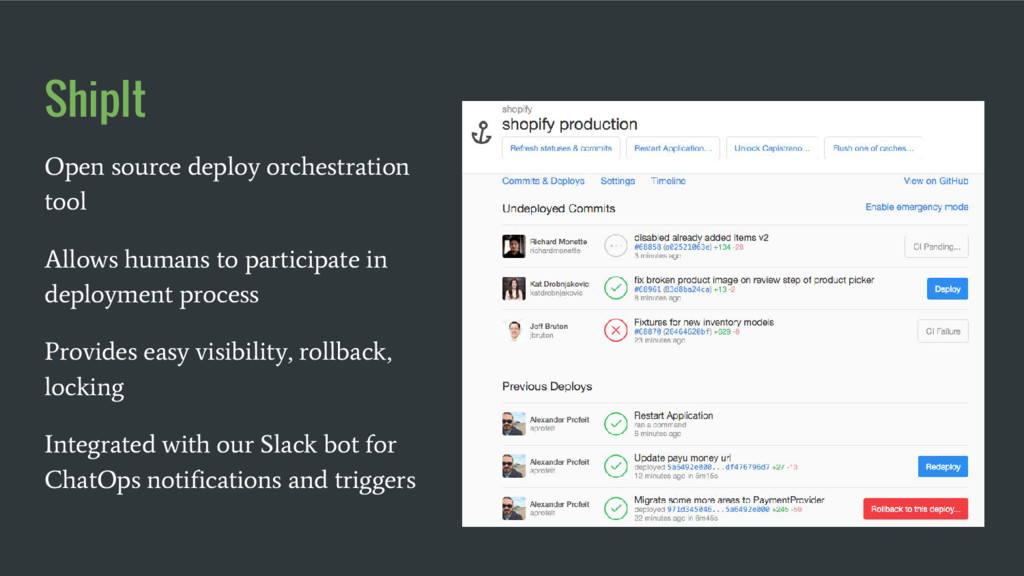
a given batch Faster time to find root cause when deploy causes problems Forces optimization of release process Higher chance of clean rollback #1 reason: making developers feel invested in deploy process
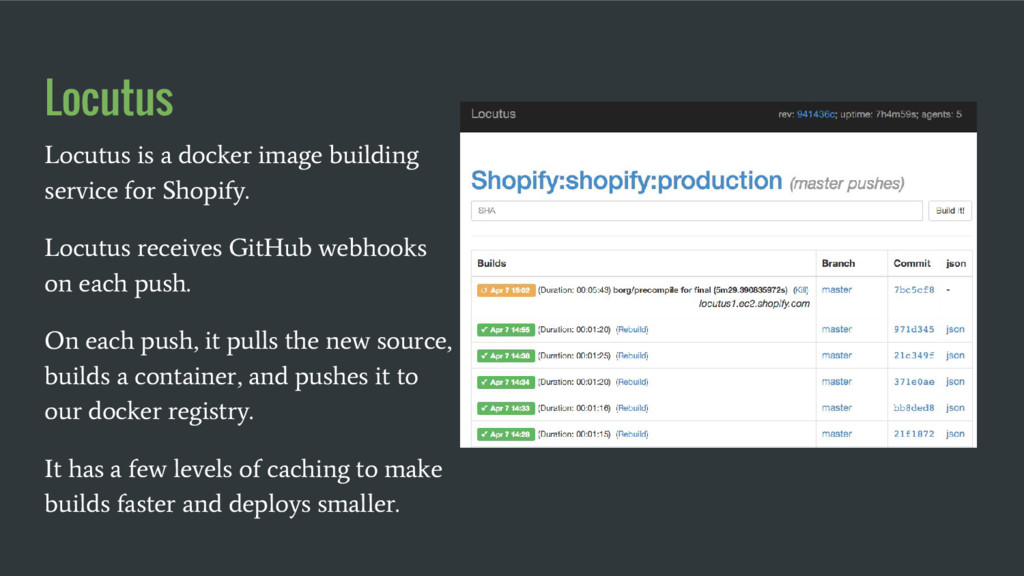
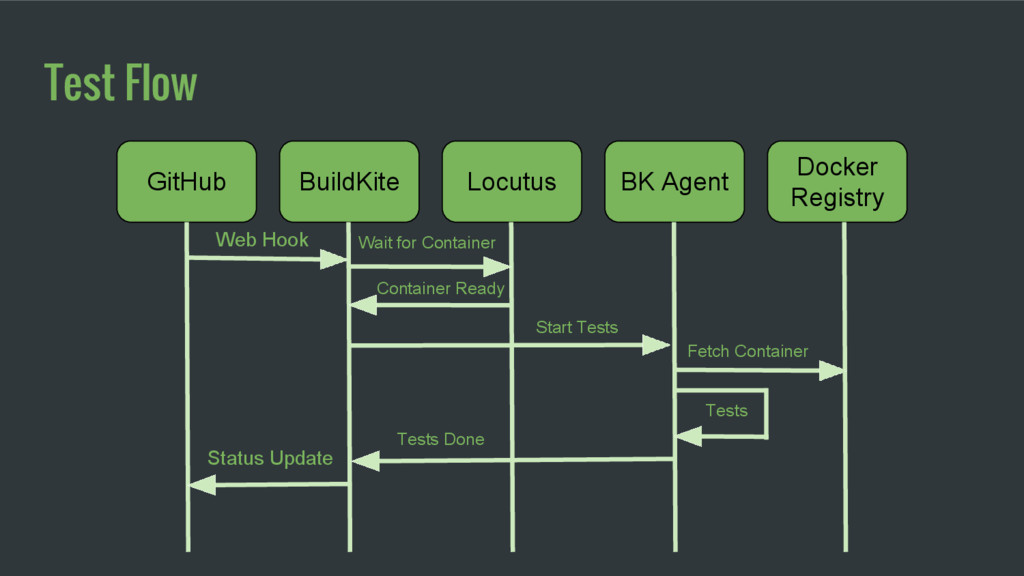
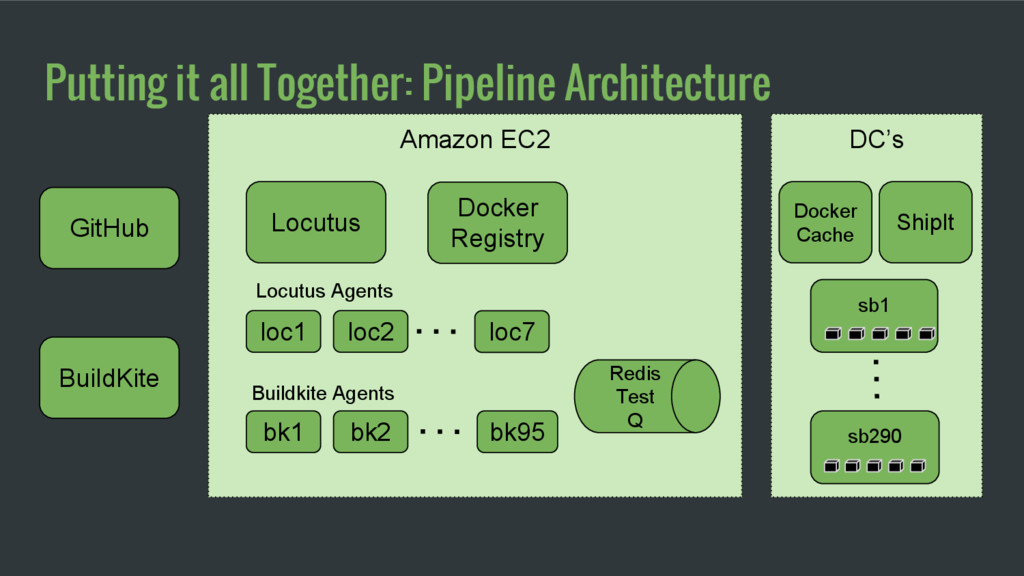
Locutus receives GitHub webhooks on each push. On each push, it pulls the new source, builds a container, and pushes it to our docker registry. It has a few levels of caching to make builds faster and deploys smaller.
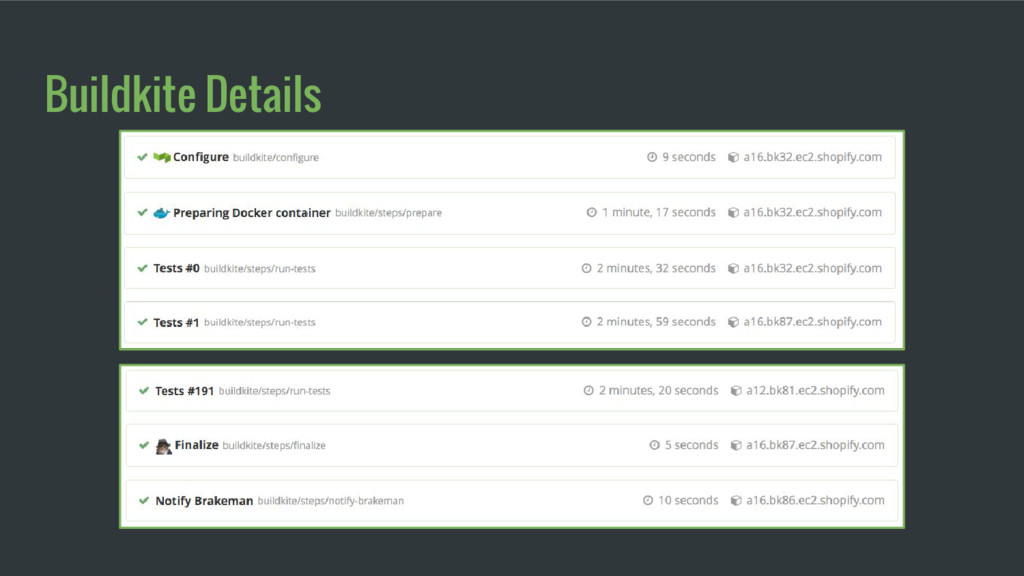
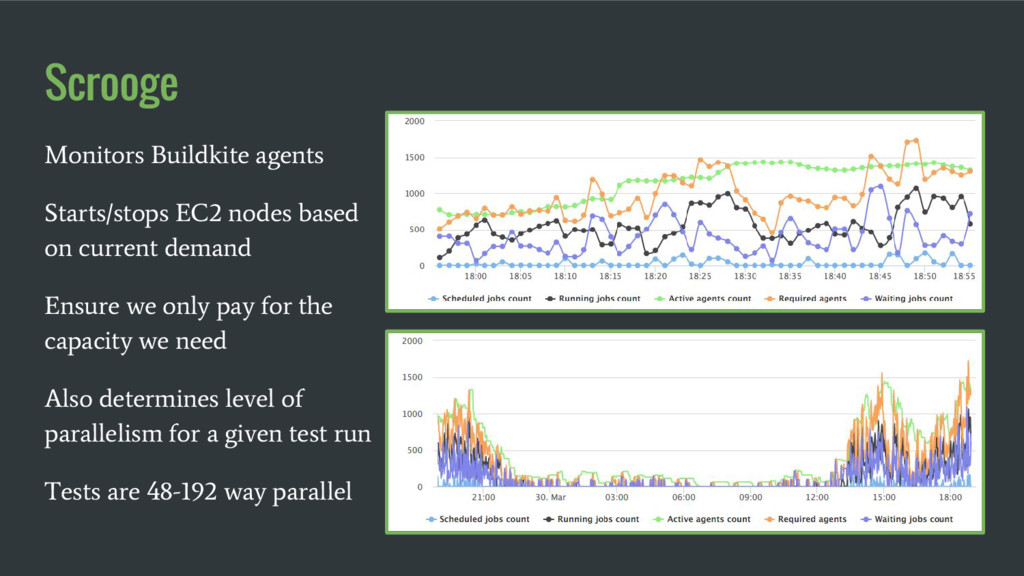
in parallel on our own EC2 boxes Agents pull tests from Redis queue Ruby tests + Browser tests run with Selenium/Chrome 102 C4.8xlarge VMs 1472 Peak agents 45k Tests/Build
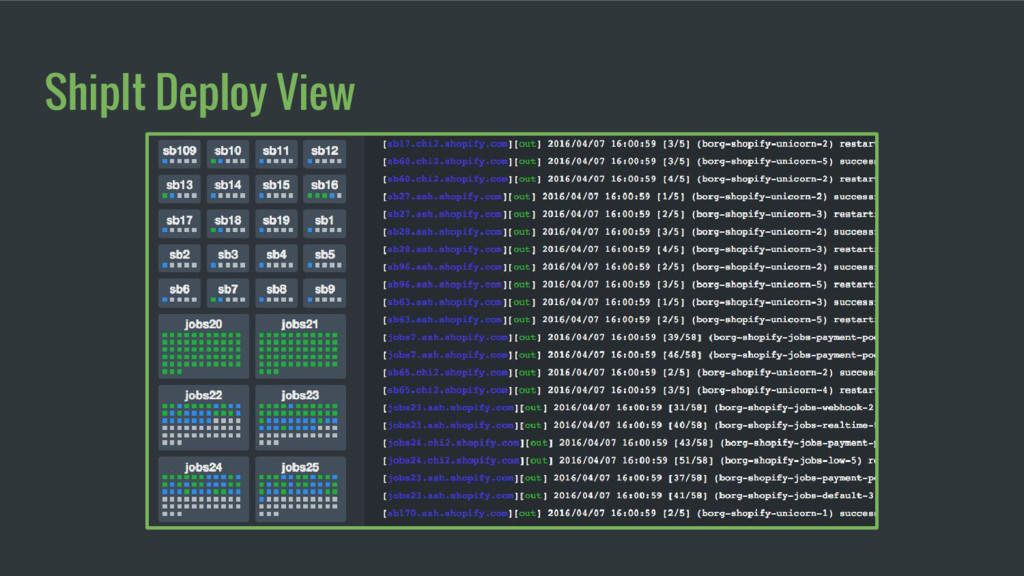
which container to run Containers restarted using sv-rollout / runit Each node fetches its container from docker registry through local DC caching proxy Containers start on each node ready to run 40 Peak deploys/day 289 Machines deployed 1500+ Production Containers
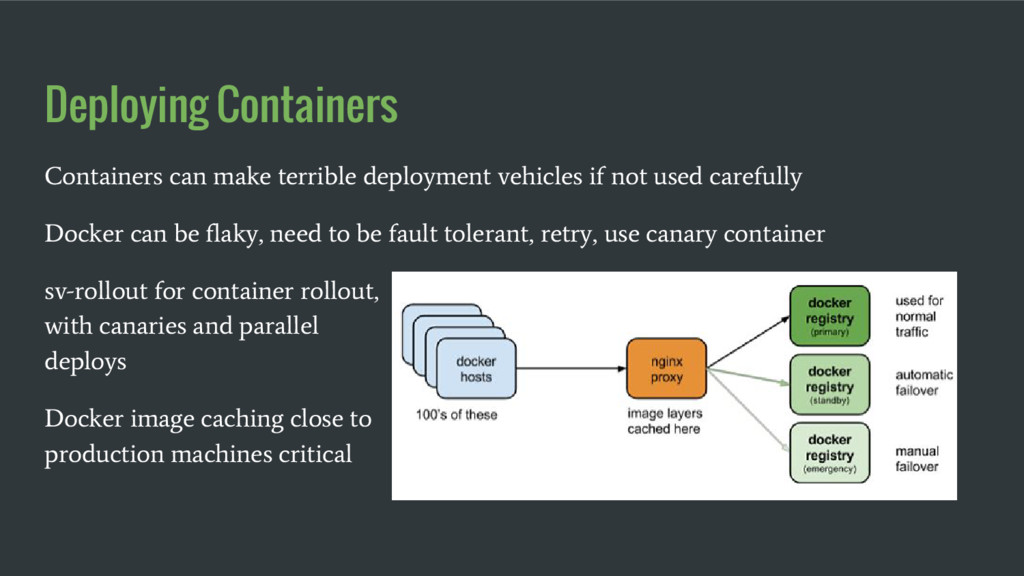
used carefully Docker can be flaky, need to be fault tolerant, retry, use canary container sv-rollout for container rollout, with canaries and parallel deploys Docker image caching close to production machines critical
a team scales up The Shopify deploy pipeline is heavily optimized for speed to keep deploy batches small Tests tend to scale well with a lot of parallelism and hardware thrown at it Fast container build and deployment is a major challenge and requires careful optimization
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}