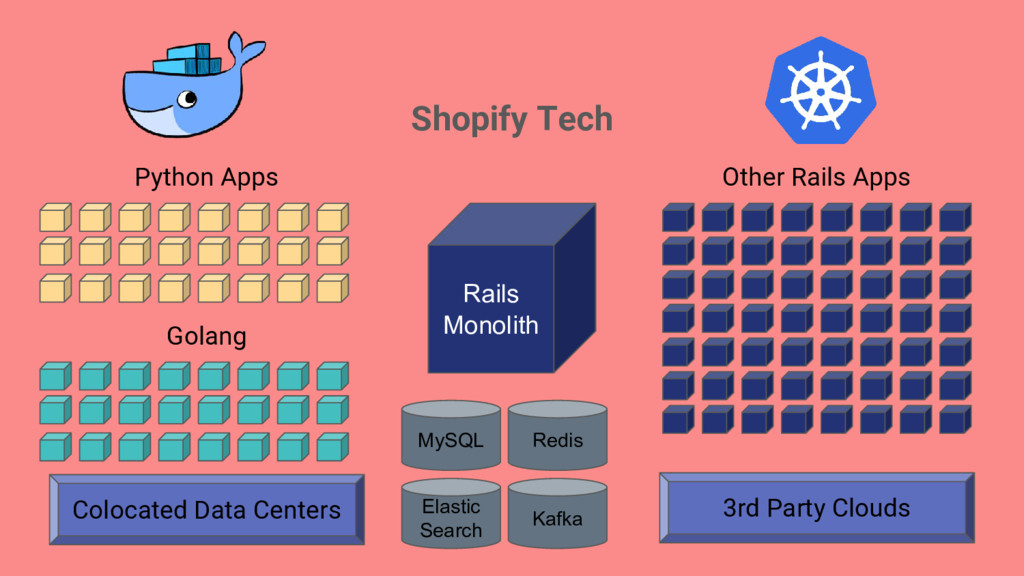
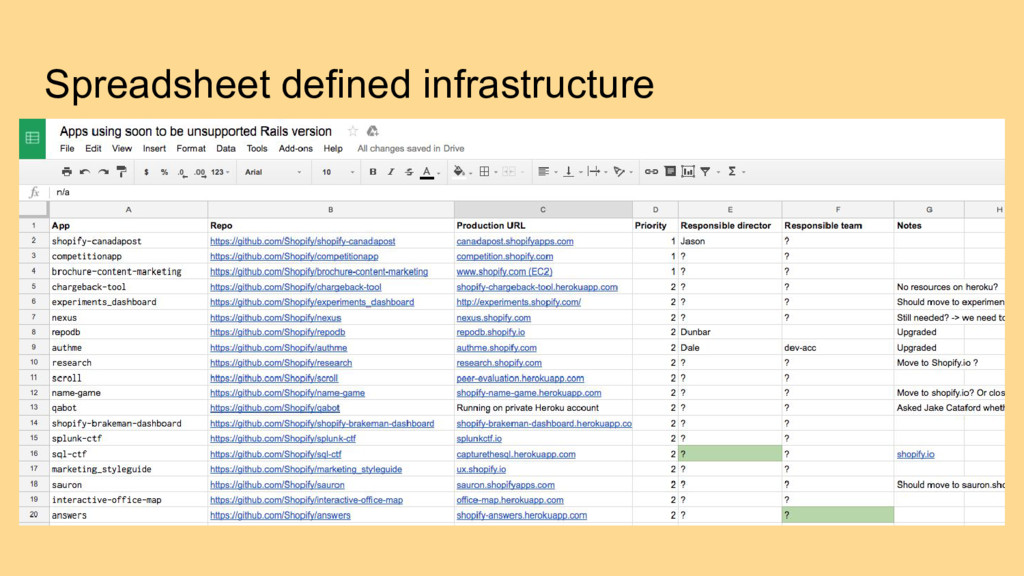
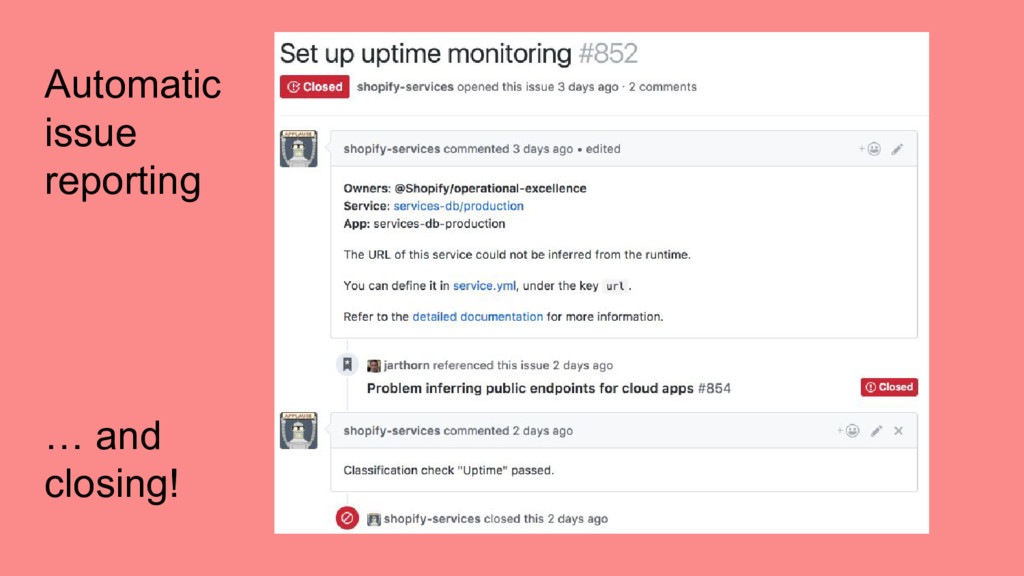
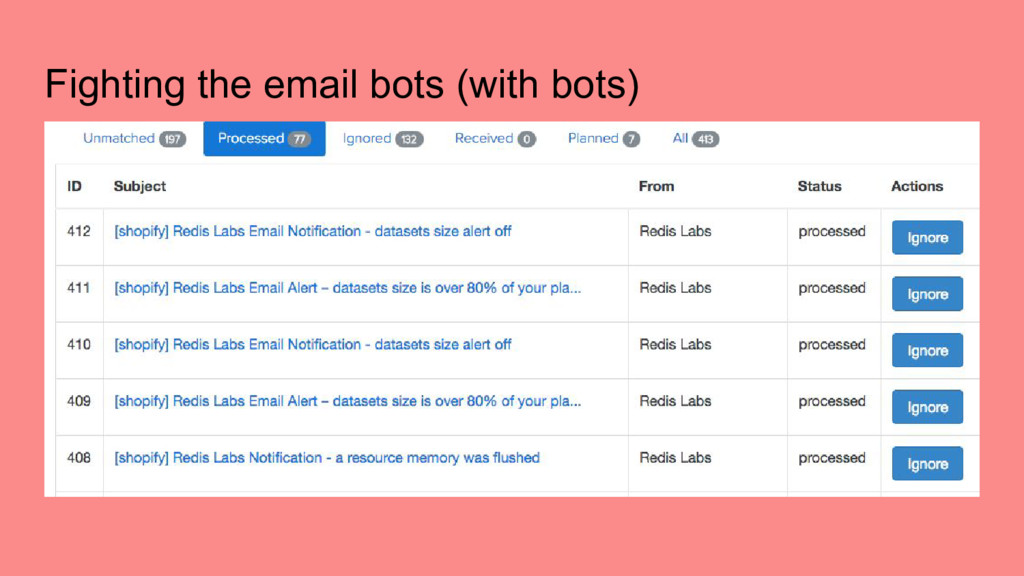
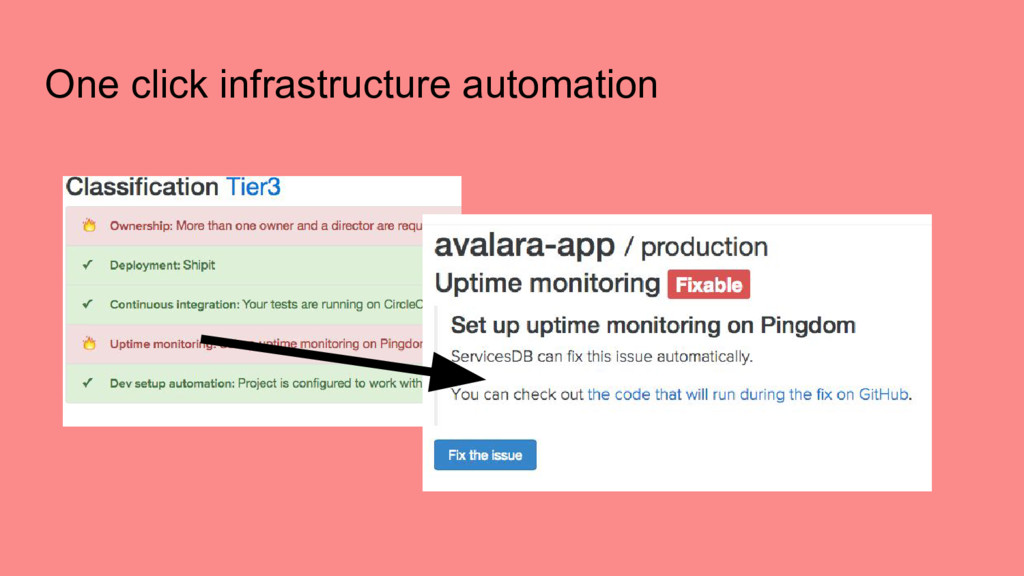
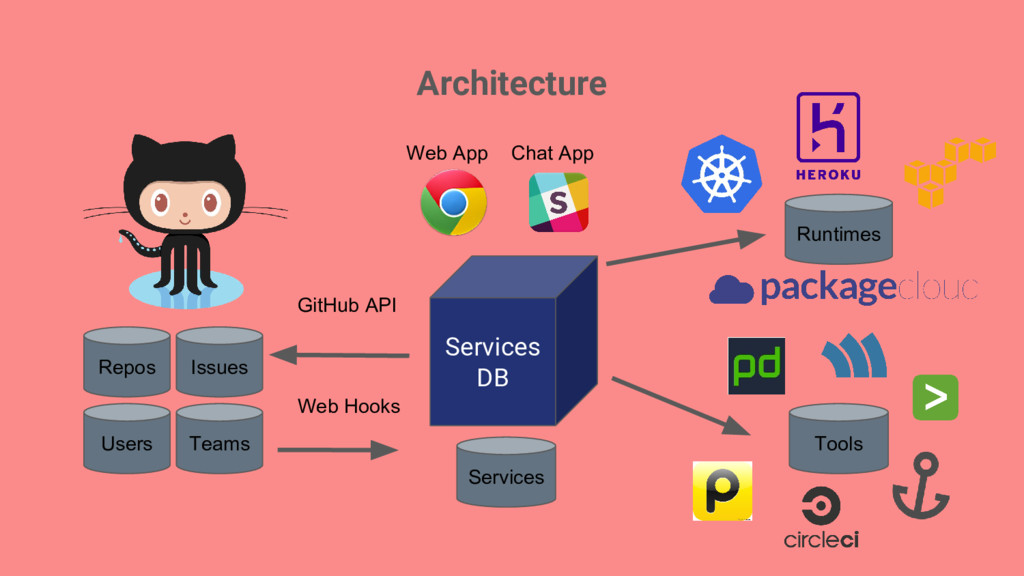
services/apps at Shopify • Measurement: Be able to measure how well we are doing on operational infrastructure for a given service • Automation: Provide tools to make it easier to build out and maintain service infrastructure ➢ Create a tool to track everything in one place, get out of spreadsheet hell
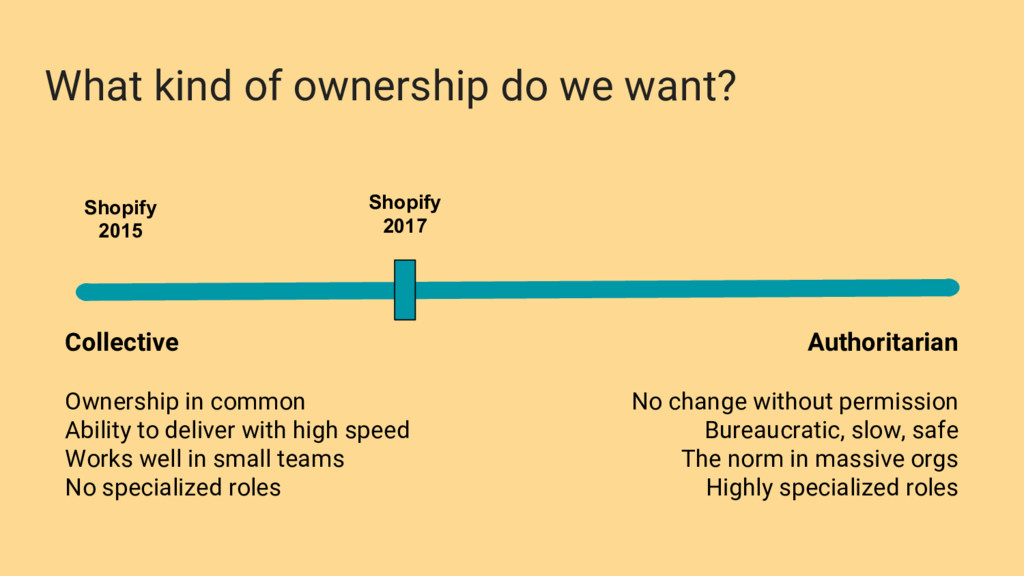
common Ability to deliver with high speed Works well in small teams No specialized roles Authoritarian No change without permission Bureaucratic, slow, safe The norm in massive orgs Highly specialized roles Shopify 2015 Shopify 2017
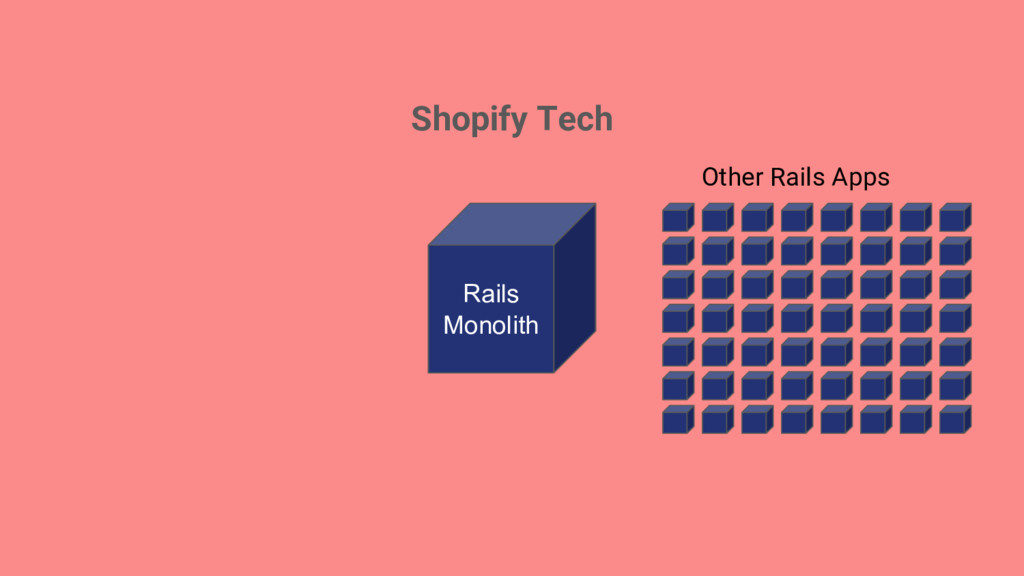
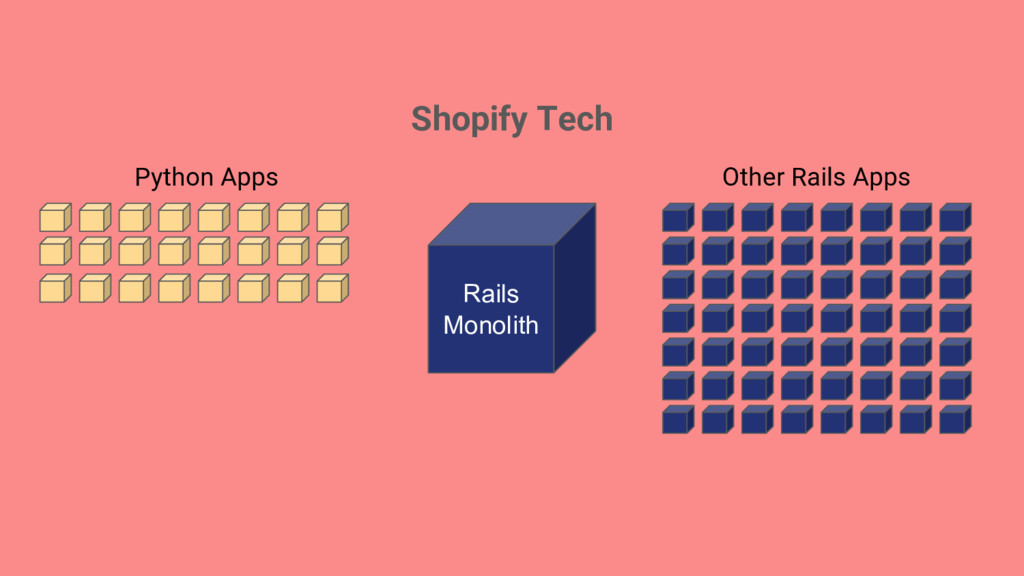
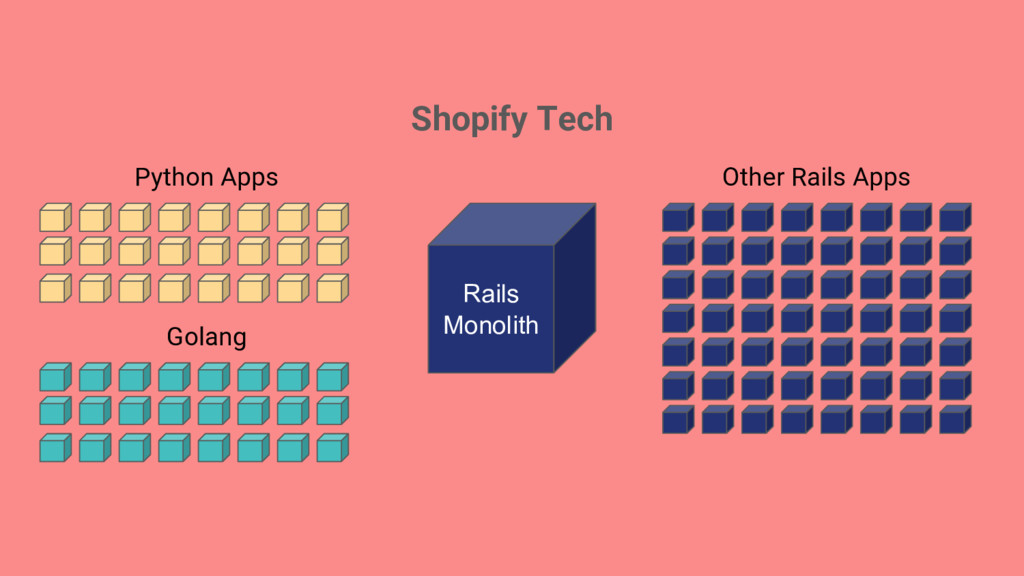
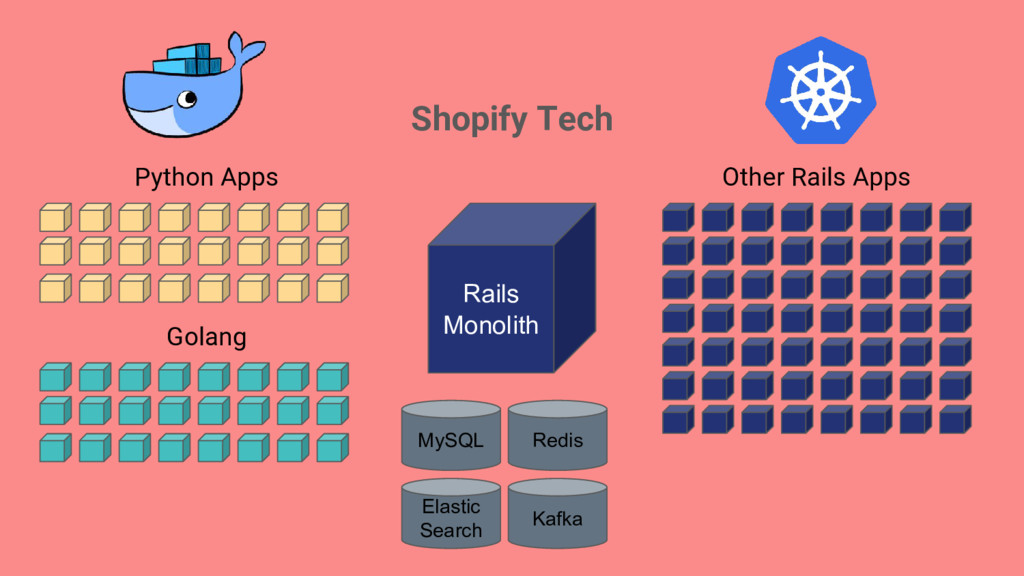
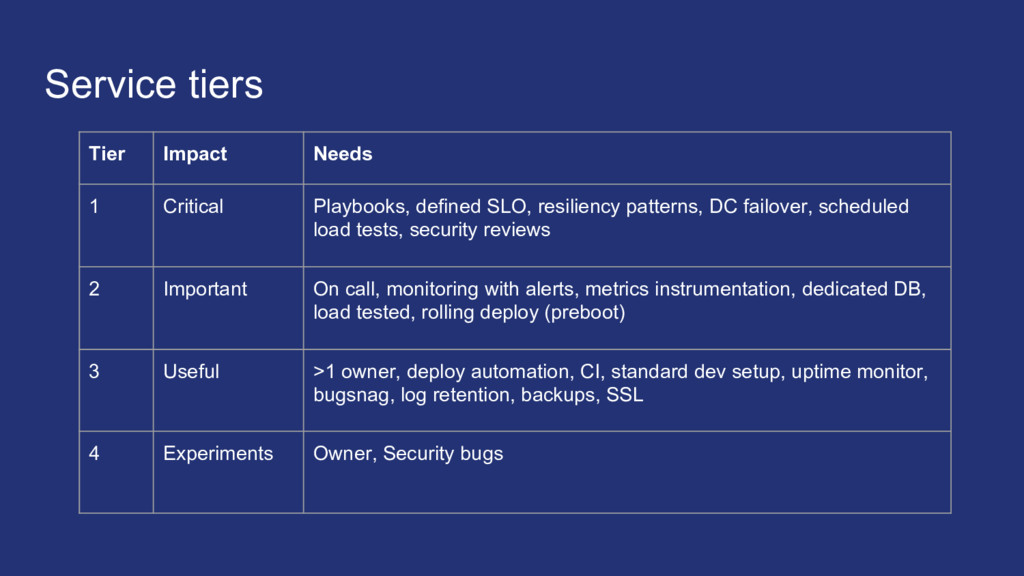
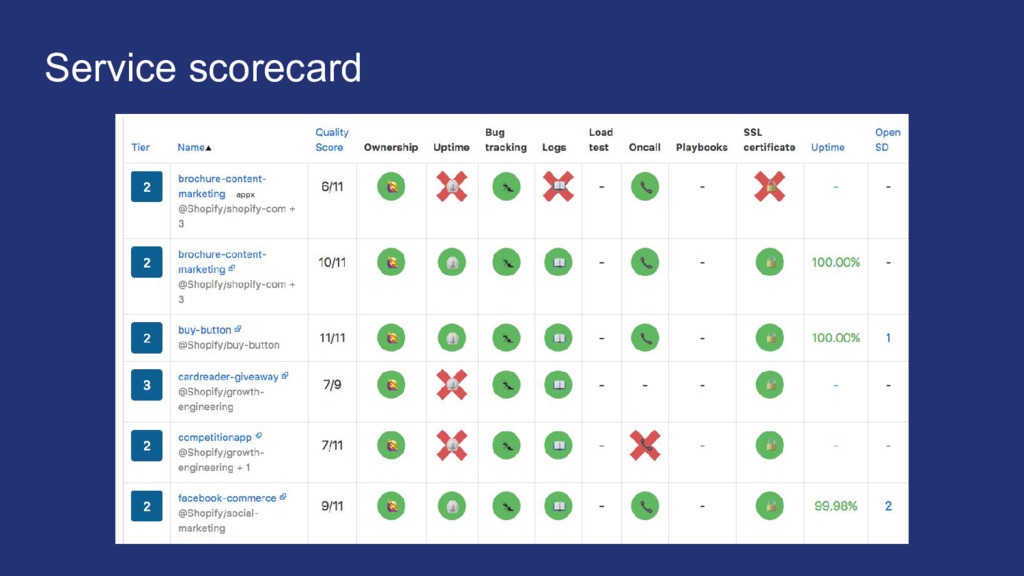
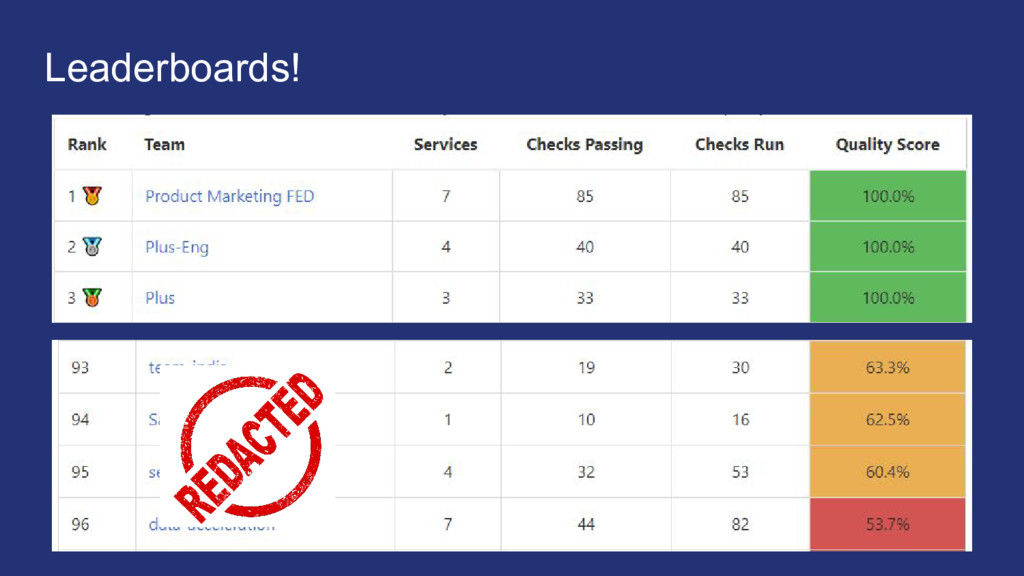
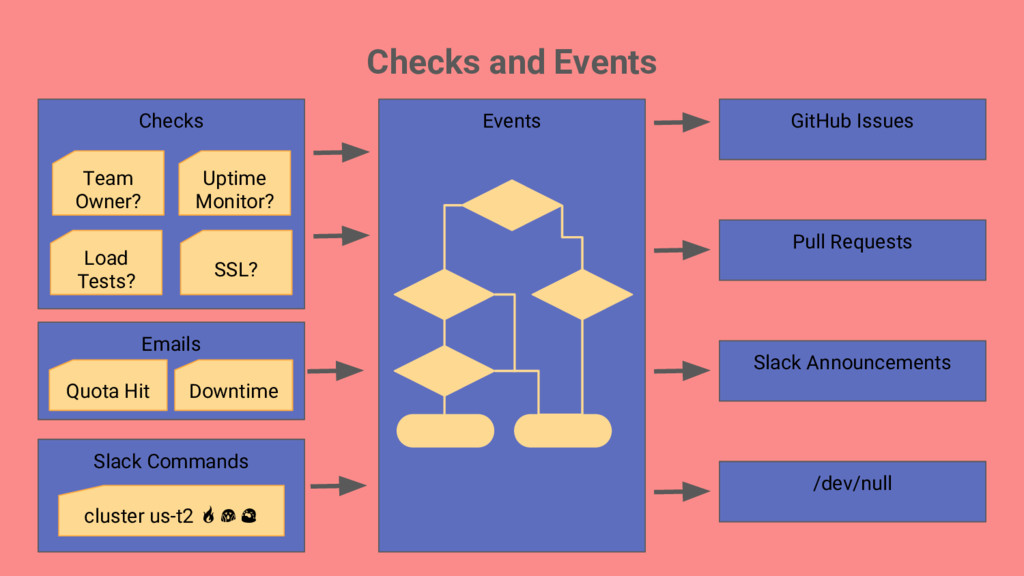
things getting better or worse? My team has a lot of applications, where should we focus efforts on improving infrastructure? Classifying services to make sure we put an appropriate level of work into surrounding infrastructure
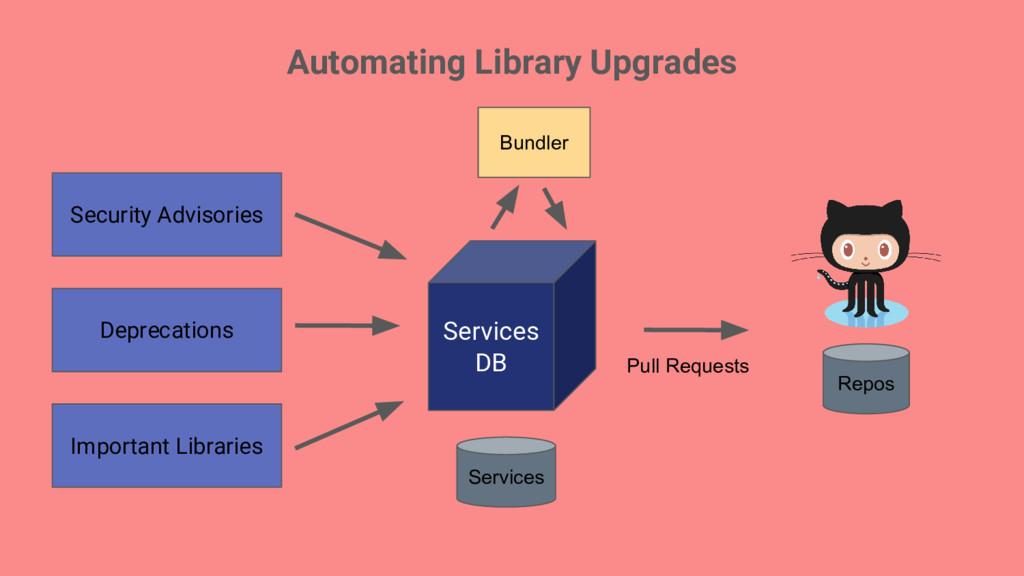
of each running service and what that implies. Think of infra investment in terms of trade-offs. More is not always better, and aim for just enough investment to get quality goals. Measure progress. Be aware of manual steps involved in creating and maintaining services. Automation is the only way to stay ahead of the growth curve.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}