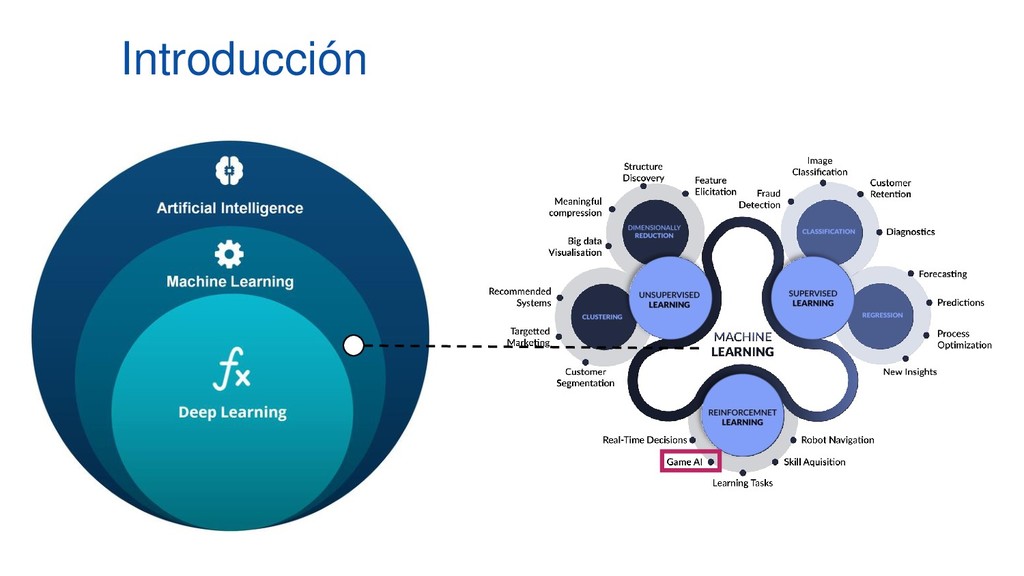
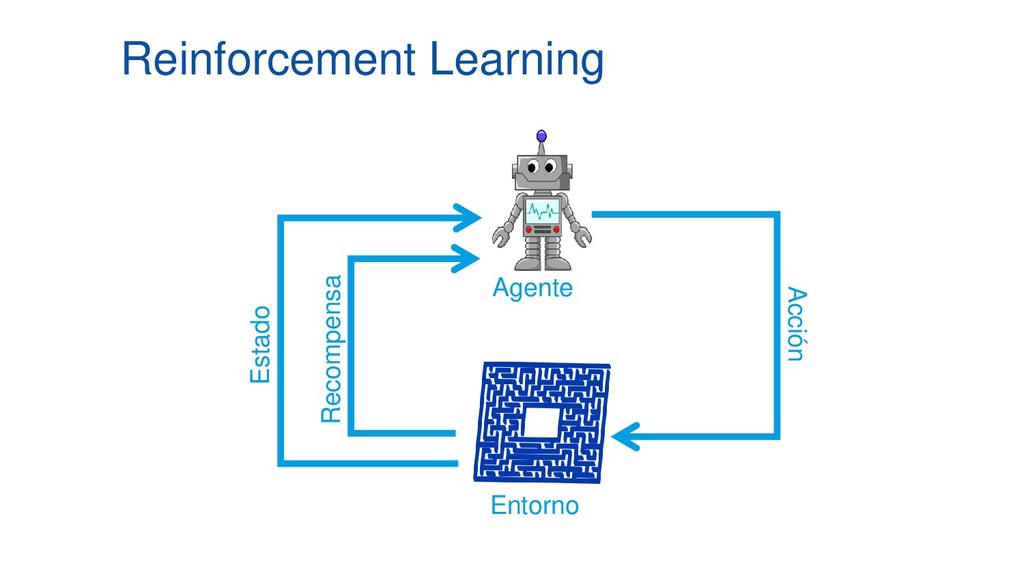
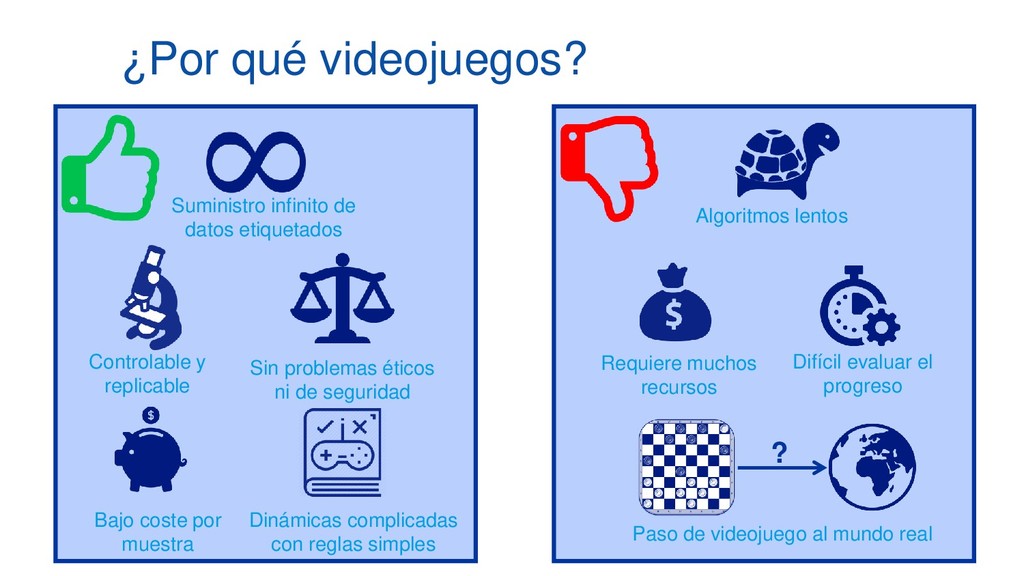
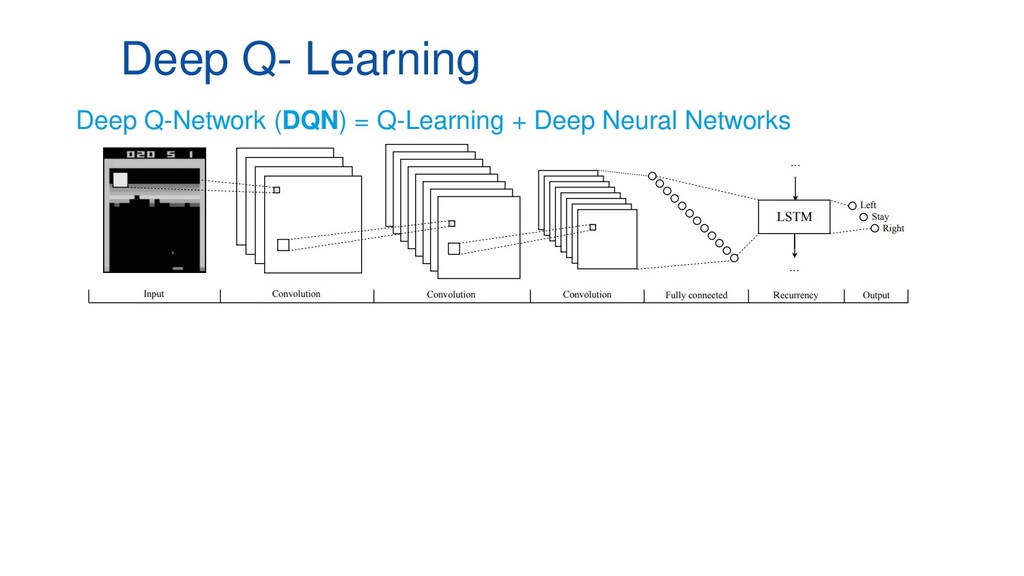
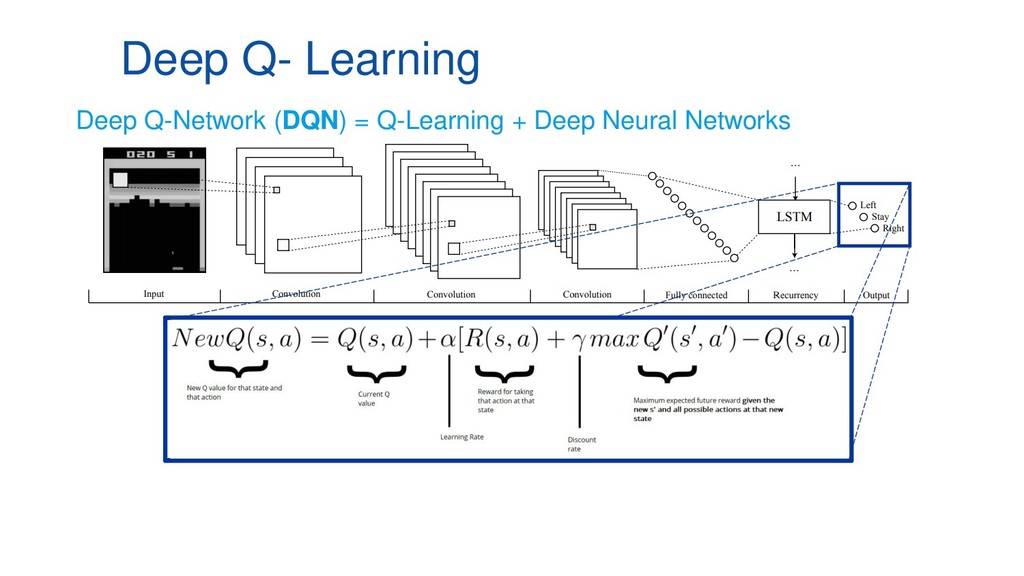
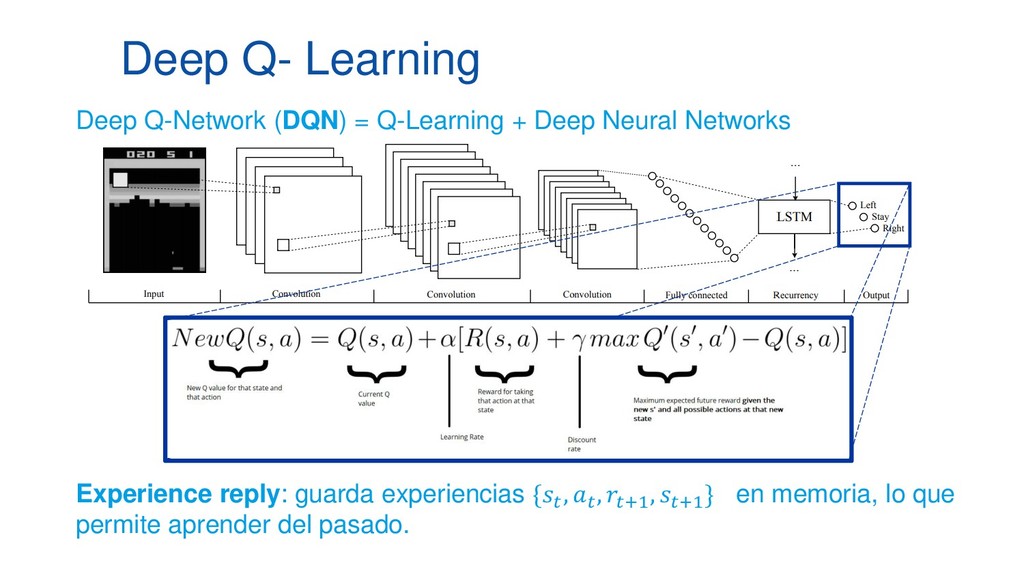
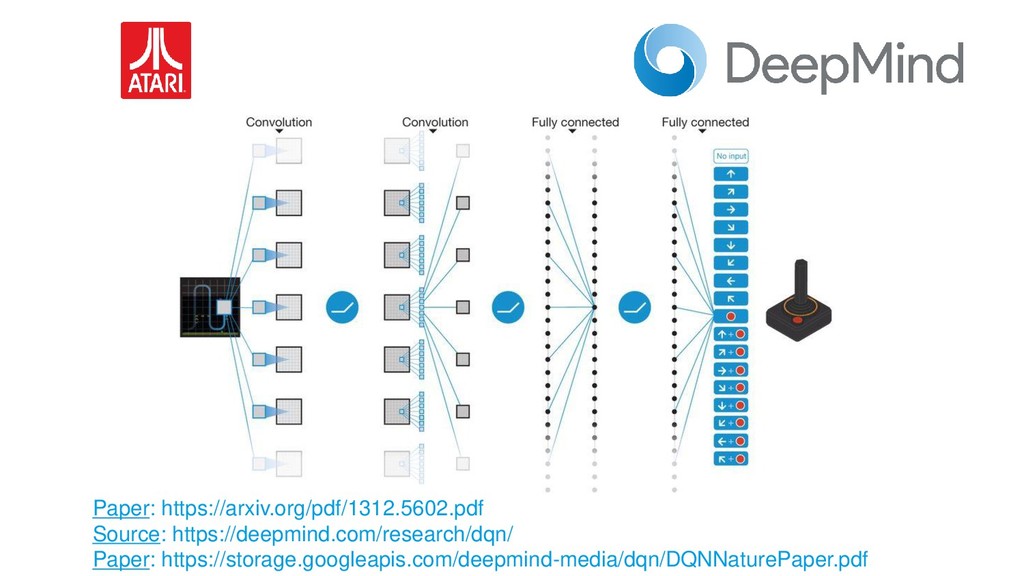
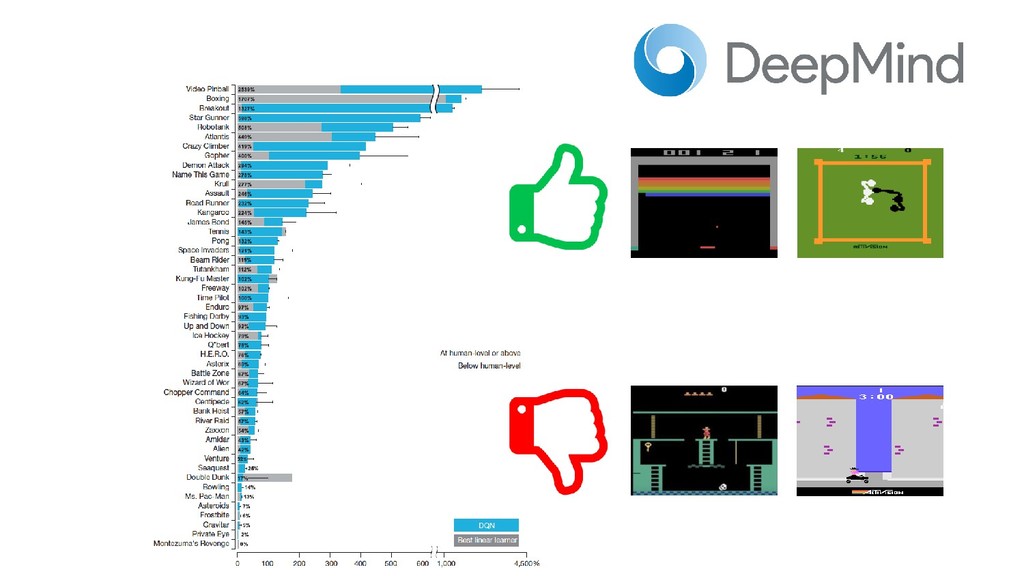
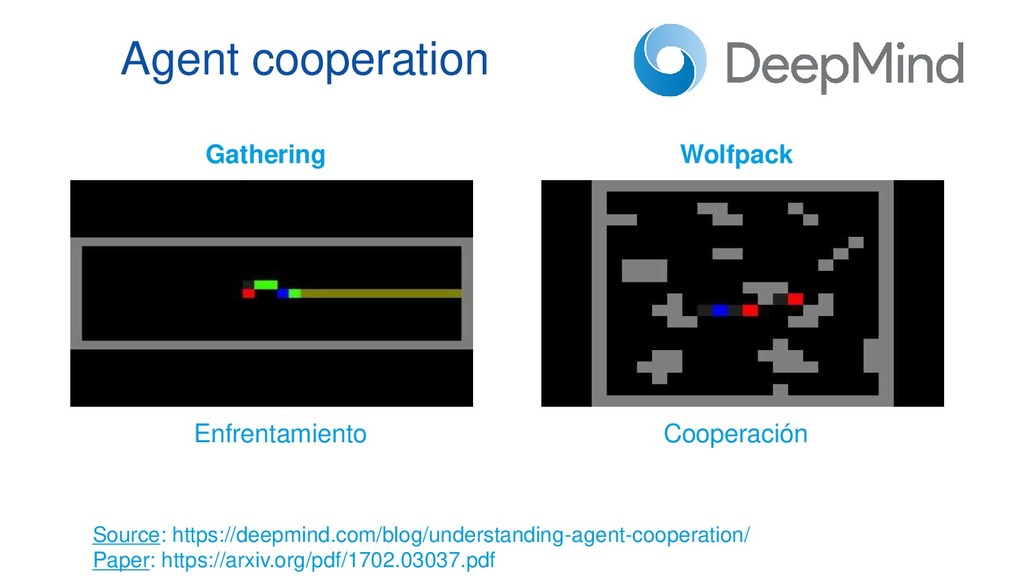
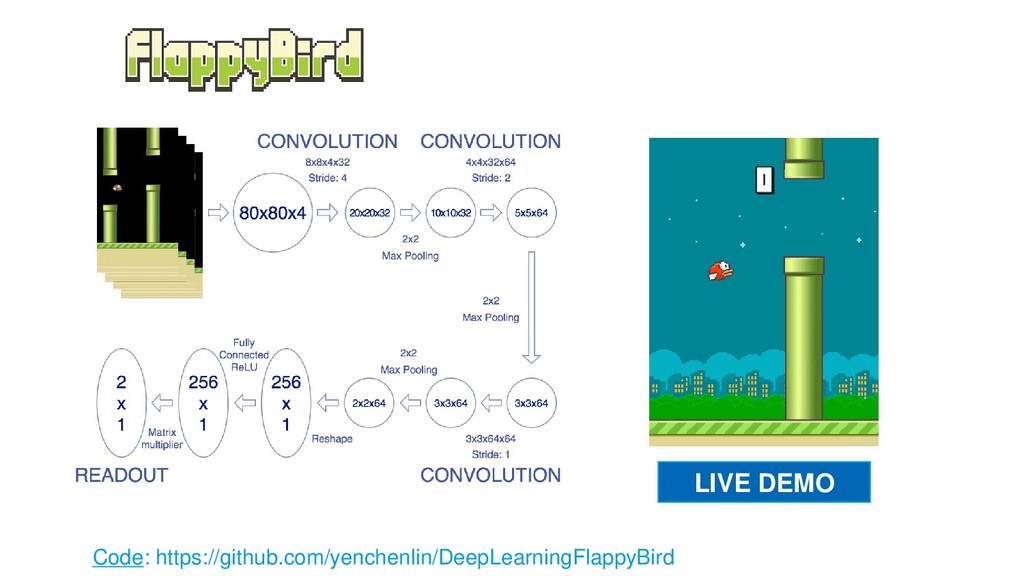
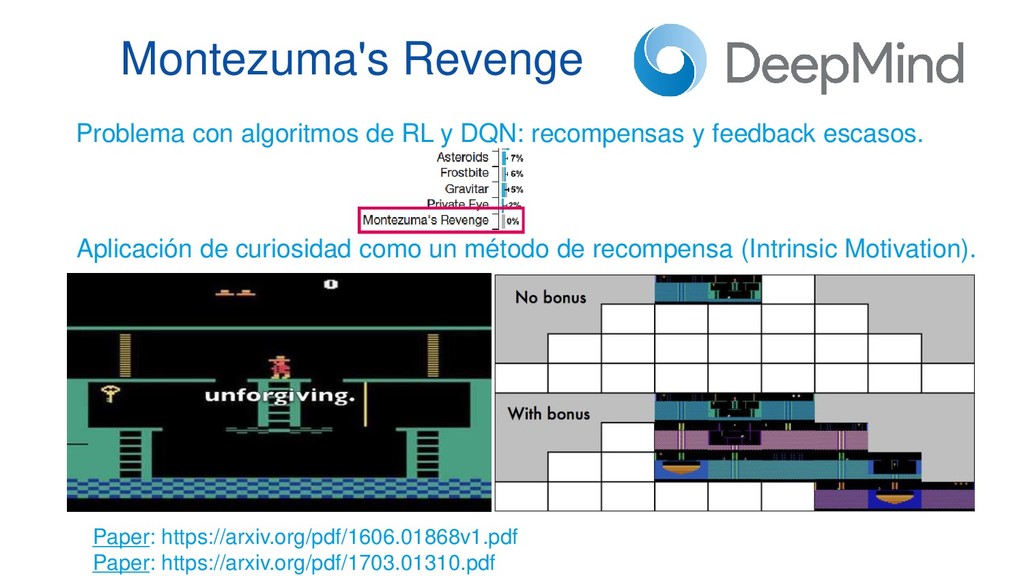
En pleno auge de la Inteligencia Artificial cada vez es mayor la necesidad de disponer de entornos controlados, replicables y disponer de una cantidad infinita de datos etiquetados, lo que ha aumentado el empleo de algoritmos de Deep Learning y Reinforcement Learning al mundo de los videojuegos como entornos de prueba antes de aplicarlos en diversos campos como medicina, ciberseguridad o banca electrónica. Esta ponencia contará con multitud de demos en directo en las que mostraremos el funcionamiento de varios algoritmos de Deep Q-Learning en distintos escenarios, desde los clásicos juegos de ATARI hasta juegos de mundo abierto como Minecraft.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}