Given at NashJS in Nashville, GA on May 9, 2018
Given at WeRise in Atlanta, GA on Jun 21, 2018
Notes:
Slide 2:
Hi, my name is Jennifer Shehane - I live in Atlanta GA. I’ve been a developer at Cypress since it’s beginning as it’s first employee. I do a bunch of things at Cypress - I develop on the main project and it’s services, I do a lot of the design and also write a good deal of our documentation.
This is my contact info on Twitter & GitHub.
Slide 3:
Let me just review real quick what I’m going to be covering.
We’re going to have a quick overview of what browser automation is and the history of browser automation
Then I’ll explain the core of WebDriver’s architecture and approach to automating the browser.
We’ll go over some of the challenges that come with using WebDriver
And then finally dive into Cypress - how it’s architected and then hopefully have some time for a demo.
Slide 4:
So let’s start out with browser automation
Slide 5:
Let’s quickly define what automating a browser means and why someone would want to automate a browser.
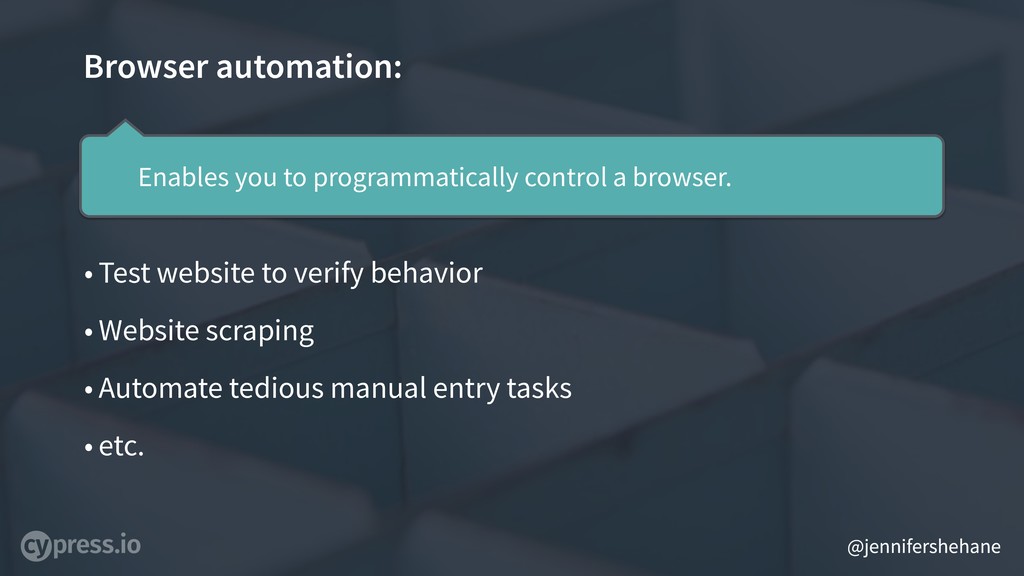
Browser automation simply enables you to programmatically control a browser.
You can utilize this to do things like test the behavior of your web application, scrape websites for content, automate manual entry tasks, automate taking screenshots of websites, verify that links work on your site and lots more. For the purpose of this presentation - we’re mostly focused on behavior testing, but the content of this presentation is applicable to all of these things.
Slide 6:
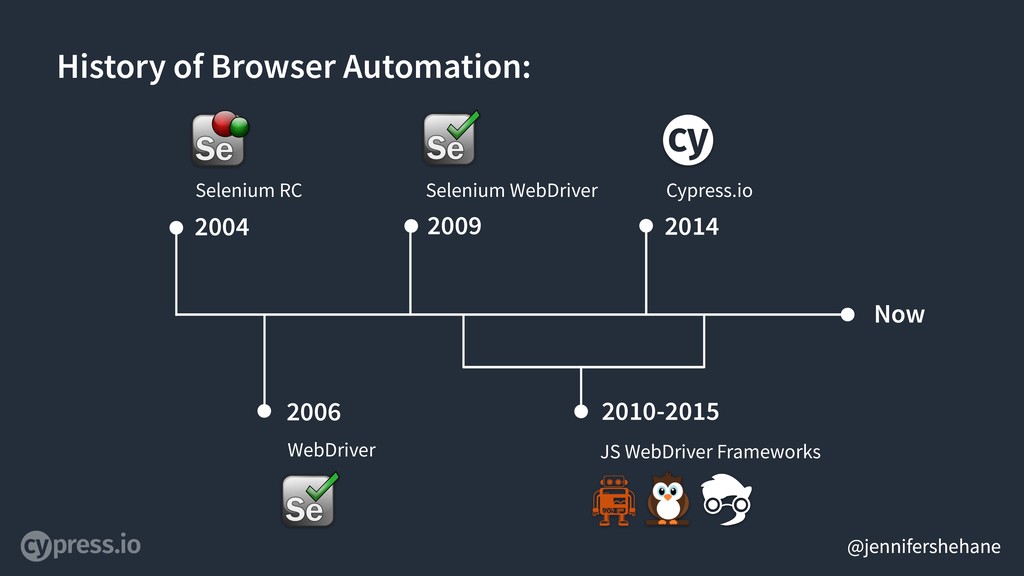
So if we look back at the history of browser automation - The earliest approach to that really took off was called Selenium Remote Control in 2004. Jason Huggins was testing an internal application at ThoughtWorks when he wrote it. He developed a Javascript library that could drive interactions with the page.
Then in 2006, Simon Stewart, an engineer at Google, started work on a project he called WebDriver. Google had been using Selenium, but there were limitations of the product - mainly that it ran in a sandboxed JavaScript environment. So the WebDriver project began with the aim to solve the Selenium’ pain-points.
Jump to 2008/2009 and this is when Selenium and WebDriver merged, Selenium RC has been basically retired.
Almost immediately after Selenium WebDriver was a product, client libraries began popping up as a way to allow programmers to run Selenium commands from a program of their own design. There’s a different client library for each supported language - like ruby and python, and multiple frameworks in the JavaScript language alone.
In 2014, the first commit to Cypress was made. Brian Mann, the creator of Cypress, was frustrated with many of the challenges that he saw while writing tests with the existing tools, so he started from scratch on a new testing tool. We’ll talk about some of those challenges later in this talk.
Now - in May 2018 - Cypress has had its public release, the main project is open source and we will be coming out of our official “beta” very soon. I’m not going to really go over the architecture of the Selenium RC project - although it’s pretty interesting, I’m just focusing on what it most commonly used in the testing world today - which is all based on WebDriver - this one from 2006.
Slide 7:
Right so, WebDriver.
Slide 8:
WebDriver provides a RESTful way to remotely instruct the behavior of web browsers. WebDriver is in the “Proposed Recommendation” stage of the W3C spec as of April, like, literally 2 weeks ago, so it’s still a work in progress.
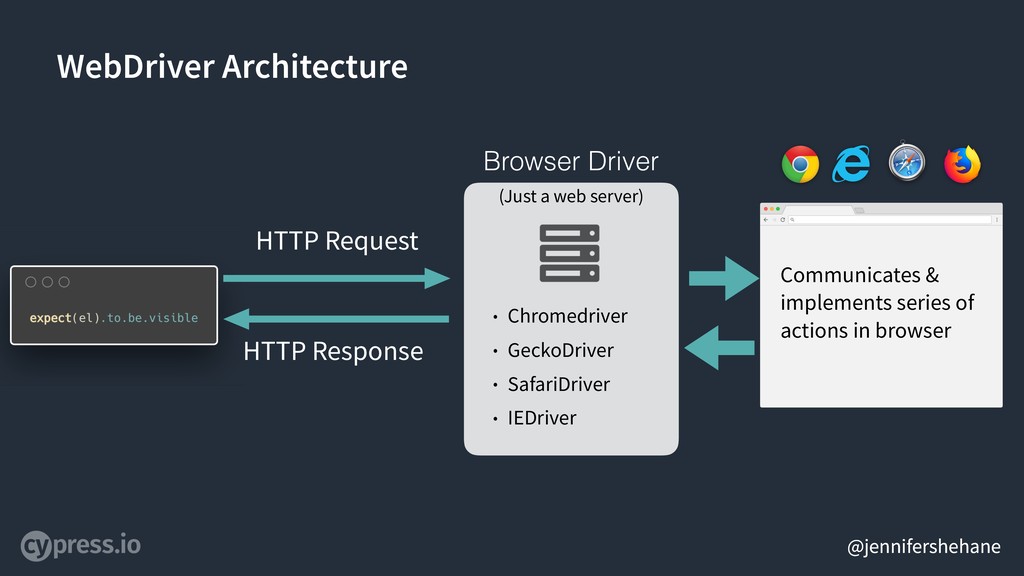
So, let’s imagine we have some test code - take this as psuedo-code if you will - that we want to test that a DOM element is visible on the screen of a browser.
Using the WebDriver protocol, we would communicate to any one of a number of browser drivers, so Chromedriver for Chrome, GeckoDriver for Firefox. This is basically just a web server.
The W3C spec defines a set of HTTP requests that should be used to communicate to these drivers.
The Browser Driver is then responsible for communicating and implementing the series of actions in the appropriate browser. How these direct calls are made, and the features they support depends completely on the browser you are using - and what the browser driver decides.
Again, using the WebDriver protocol, the browser driver is responsible to then send a defined HTTP response back. This is basically what the entirety of the W3C WebDriver spec covers - this communication loop.
Slide 9:
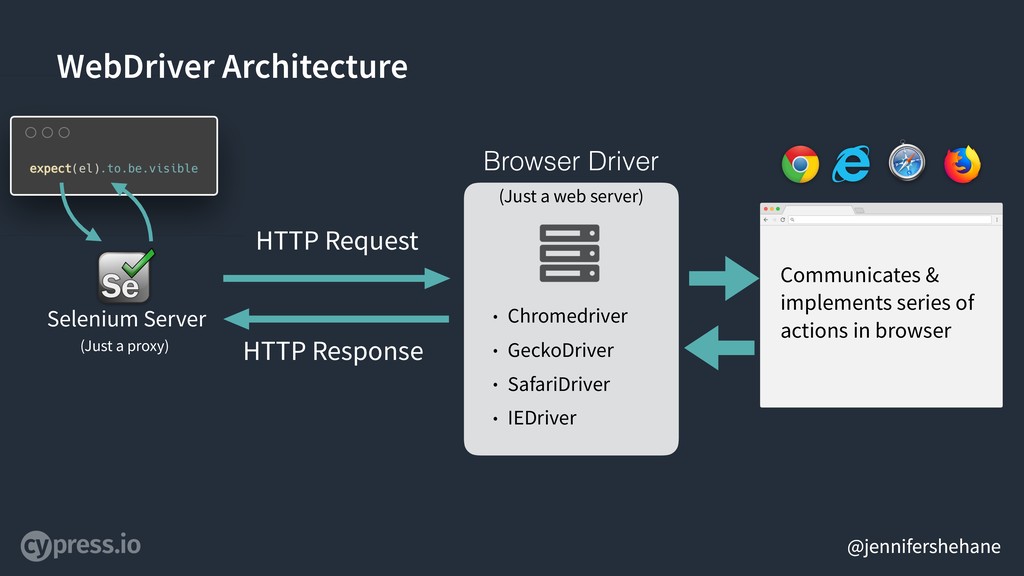
If you wanted to also include Selenium in this diagram, Selenium Server would basically sit here - as a proxy between your code and the browser driver.
Slide 10:
The WebDriver protocol is organized into commands. Each HTTP request with a method and url represents a single command with there being about 54 defined endpoints.
This is also available for extension - usually for vendor specific needs. So if chrome wanted to like add a command to load it’s browser in ‘mobile emulation’ mode, it could make it’s own command to do this.
So, however a client side library - like Selenium - chose to create an API to interact with these remote commands would be totally up to them.
Slide 11:
So let’s walk through an actual example with WebDriver’s implementation.
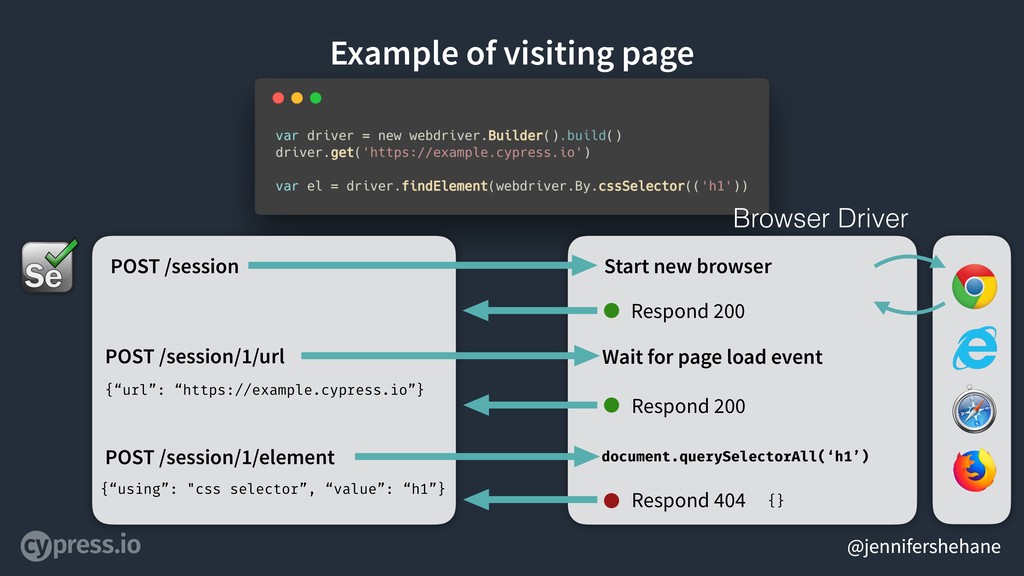
Let’s say, we want to visit a page in our browser and find the h1 element. Very simple.
The Selenium WebDriver would begin by issuing a POST to get a session in the browser.
The browser driver should then, start a new browser - whichever one we had specified in our config (which I’m not really showing) and respond with 200. Remember - the browser driver is going to continue to execute the actions in the browser for the rest of our test. The next command would POST the url we wanted to visit.
The Browser Driver would visit the url and wait for the page’s load event to fire and if that fires within a specific allowed timeout - it responds with 200.
The final command initializes a POST to the element endpoint with the data needed to find our h1 element.
This results in a very simple document.querySelectorAll for our element.
IF our element is found, this POST request will respond with the serialized element that was found. This diagram represents an ideal workflow - so, no errors.
Slide 12:
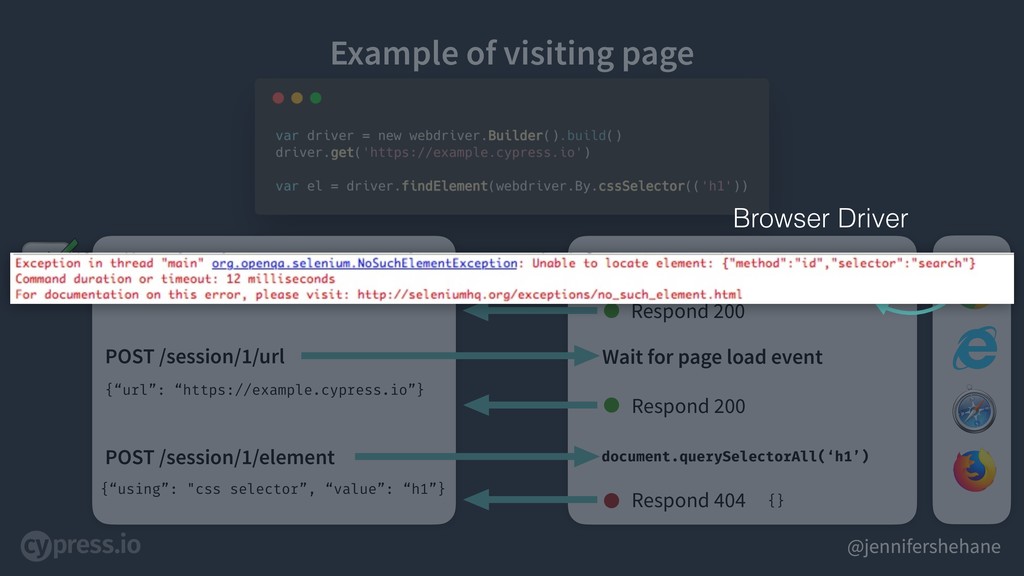
But what happens if our document.querySelectorAll does not find our element when it queried - say, our loading view wasn’t done loading or a request in our application was still waiting for a response.
If this happens, our browser driver responds with a 404 error
Slide 13: ‘Unable to locate element’ This is how the majority of the failures are handled in the WebDriver spec - with this kind of error response.
Slide 14:
Most JS Developers, if they’ve done any testing in the last 5 years or so have maybe not used Selenium WebDriver directly but come across or used a Framework that claimed to improve the experience of writing tests. There’s been a lot to choose from - some that have already come and gone.
So, as nice as these API may be - they will always be susceptible to the challenges that WebDriver has - so keep this in mind as we move on…
Slide 15:
these challenges.
Slide 16:
The first main pitfall of WebDriver wasn’t as evident at the time it was first written in 2006.
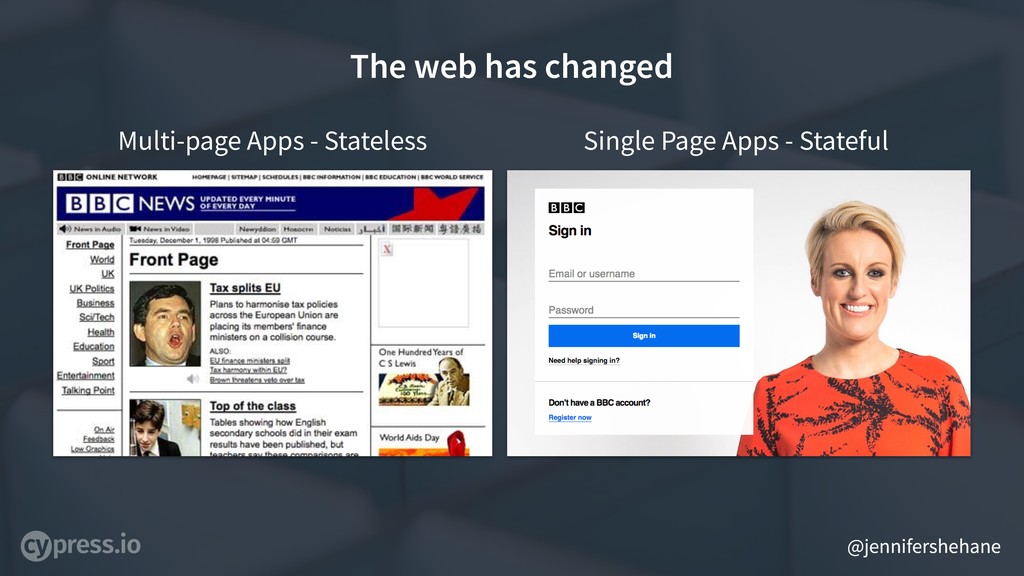
12 years ago during WebDriver’s initial creation - the web was mostly multi-page applications, oftentimes a stateless web, where sites were static, not saving or changing state on the client side within the web application as it was used.
Since then, we’ve largely moved to building single page applications - a stateful web, that delivers preserved state across complex web applications.
Slide 17:
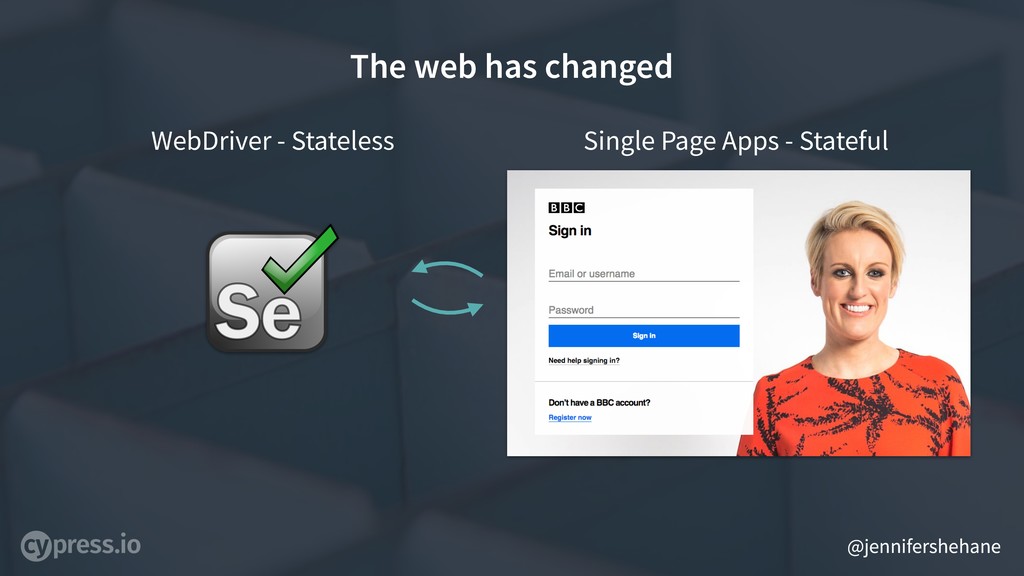
But the system that the core of WebDriver is built from - a REST system - is stateless. A stateless system cannot deterministically communicate, model, or respond to a stateful system. Testing has to be 100% deterministic, there can’t be variability in what it observed, but the stateless WebDriver observing a stateful web prevents tests from being 100% deterministic. This is the definition of flake.
Slide 18:
To quickly demonstrate what I mean - let me share an example in JavaScript. This example we are just using a setInterval to count - so this is meant to represent some piece of application code you may have in your browser with the count being the state you’re maintaining in your application.
Below this, we are logging the value found within the count every 100ms (so imagine this is the latency that a RESTful system like WebDriver would have - hopping back and forth to check the count.)
When you run this code and try to get a predictable result to test this value - it ends up being impossible. So here is the output of the code ran - you can see none of the values are predictably the same. This is an example of a stateless system - trying to observe a stateful system from the outside.
Now, this example is very simplified - a more realistic example in an application would be say - having this count being displayed in a DOM element and trying to observe that the counter is working as designed.
Since WebDriver is designed to observe from the outside of your application with a series of hops between each piece, you cannot react or directly listen to to changes that may have happened while that request was going to or responding from the browser.
Slide 19:
Another challenge in WebDriver is debugging - it is not a very intuitive process.
When there are problems in WebDriver, WebDriver responds with an HTTP error response that can be seen after running all of the tests have run. You would then have to figure out what that error message means. At this point, our application is gone, the browser is closed - we just have this error message. This is usually the point where you begin adding commands to save screenshots all over your test cases and checking through static images after they’ve run to determine the problem. It’s a bit like driving in the dark. As developers, we’re used to debugging problems in our dev tools, while our application is up and running, with access to the application’s objects. This process in WebDriver can leave a lot of devs feeling like tearing their hair out.
Slide 20:
Setting up an entire testing suite using WebDriver can also be a challenge
You need to install selenium server or another framework of your choosing.
You need to install the browser drivers you want to test in so, chromedriver, geckodriver, etc.
You will also want to install a runner to run and structure your tests like Mocha or Jest.
You’ll likely want an assertion library to use a normalized structure for how to assert the state of things in your web application like Chai, or Should
And if you want to do any stubbing or mocking of functions or api calls or manipulating timers in your application - you’ll want to install a library like Sinon to handle that.
This setup process is tedious and often is major blocker for getting teams started quickly in testing - since there are so many pieces involved.
Slide 21:
Let's talk about Cypress' architecture now.
Slide 22:
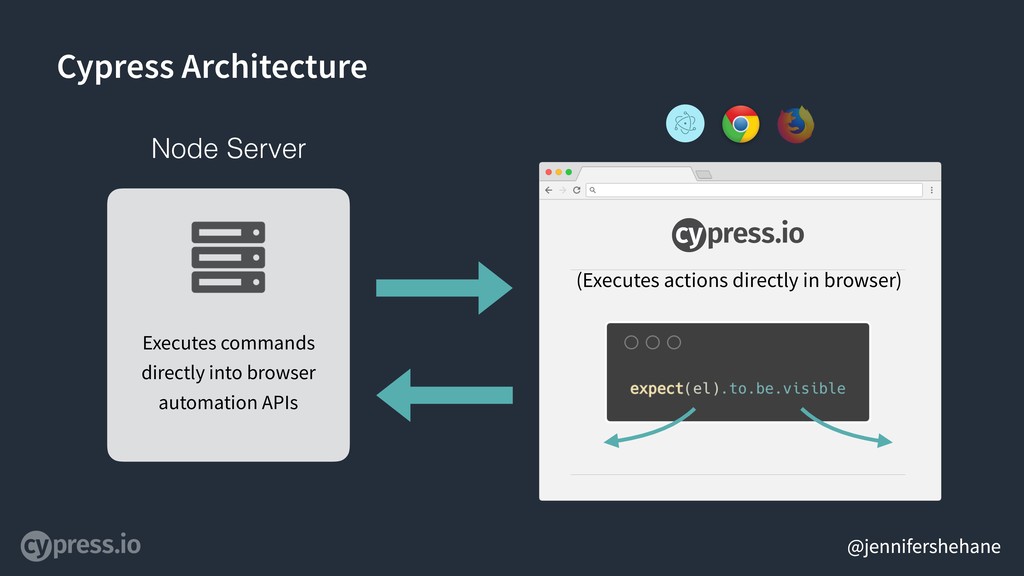
The biggest difference between Cypress and WebDriver is that while WebDriver is a RESTful command interface,
Cypress actually executes all of your test code within the same context and run loop as the browser. This means that Cypress has access to everything in the browser - all native objects, even your code. It doesn’t serialize anything over the wire, instead it has direct access to your application.
This can also communicate to a Node Server to do things like clearing cookies, clearing the cache, starting the browser, making http requests, etc - because you can’t implement everything necessary for testing in just JavaScript within the browser.
We should note here - Cypress does not currently have connections to all of the browser automation APIs. It currently can only run within Chromium and we’re working on Firefox.
Slide 23:
So how does Cypress solve the issue of stateful versus stateless - since it runs inside the browser in the same context
- Cypress can listen and respond to your application’s events in real time
- Cypress observes web traffic in realtime so it knows exactly when XHR’s are sent and received
- You can import app code directly in test code to do things like load components and do component testing
- You can call methods and access objects directly from your tests as they run.
- Cypress also observes the application under test and allow you to travel back in time through each test command.
- You also get readable, actionable error messages at the moment a test fails
- Something else you can’t do in WebDriver - you can listen and debug uncaught errors coming from app code
Slide 24:
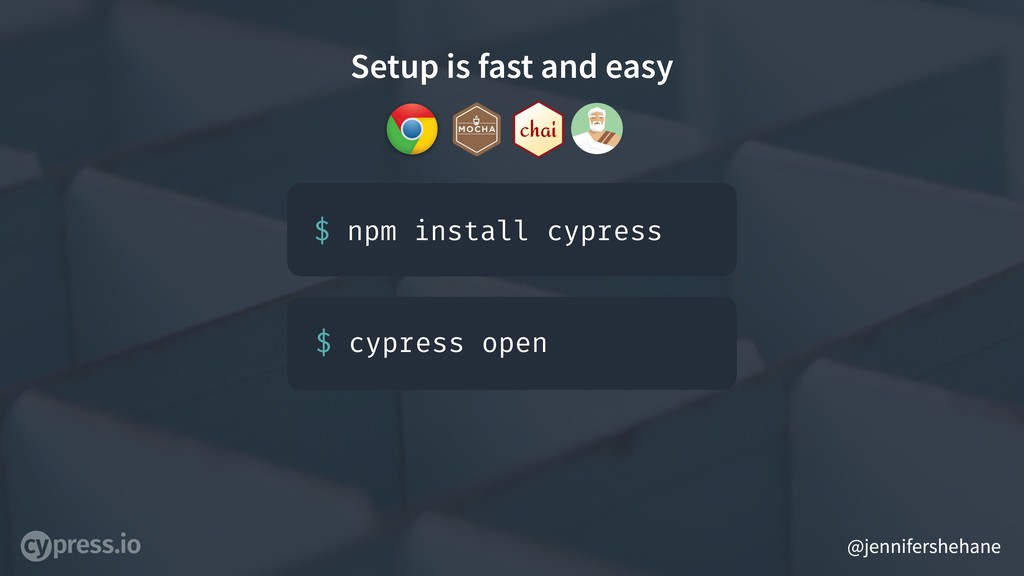
Having an easy setup in Cypress was one of our main focus points of the project.
You just npm install cypress.
Cypress is bundled with Mocha, Chai, and Sinon so that there’s no extra installation necessary to write assertions and spy, stub, or mock.
Then you just run cypress open to open the Cypress Test Runner - which I’m going to go ahead and give a quick demo of to show how quickly you can get it running and how debugging works within Cypress.
Slide 25:
Thank you - just wanted to put up my information here and mention that we are hiring Senior JavaScript Developers before I dive into a demo of Cypress.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@jennifershehane document.querySelectorAll(‘h1’) {elements: [h1]} Example of visiting page POST /session/1/element](https://files.speakerdeck.com/presentations/a068cfd93b3148ce87dd18b87e395407/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}