Once upon a time, an application query triggered a crashing bug. After automated failure recovery, the application resented the query, and MySQL crashed again. This was the beginning of a cascading failure that led to a full datastore unavailability and some partial data loss.
MySQL stability means that we can easily forget to implement operation best practices like cascading failure prevention and testing of unlikely recovery scenarios. It happened to us and this talk is about how we recovered and what we learned from this situation.
Come to this talk for a full post-mortem of a cascading outage caused by a crashing Bug. This talk will not only share the incident operational details, but will also include what we could have done differently to reduce its impacts (including avoiding data loss), and what we changed in our infrastructure to avoid this from happening again (including cascading failure prevention).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
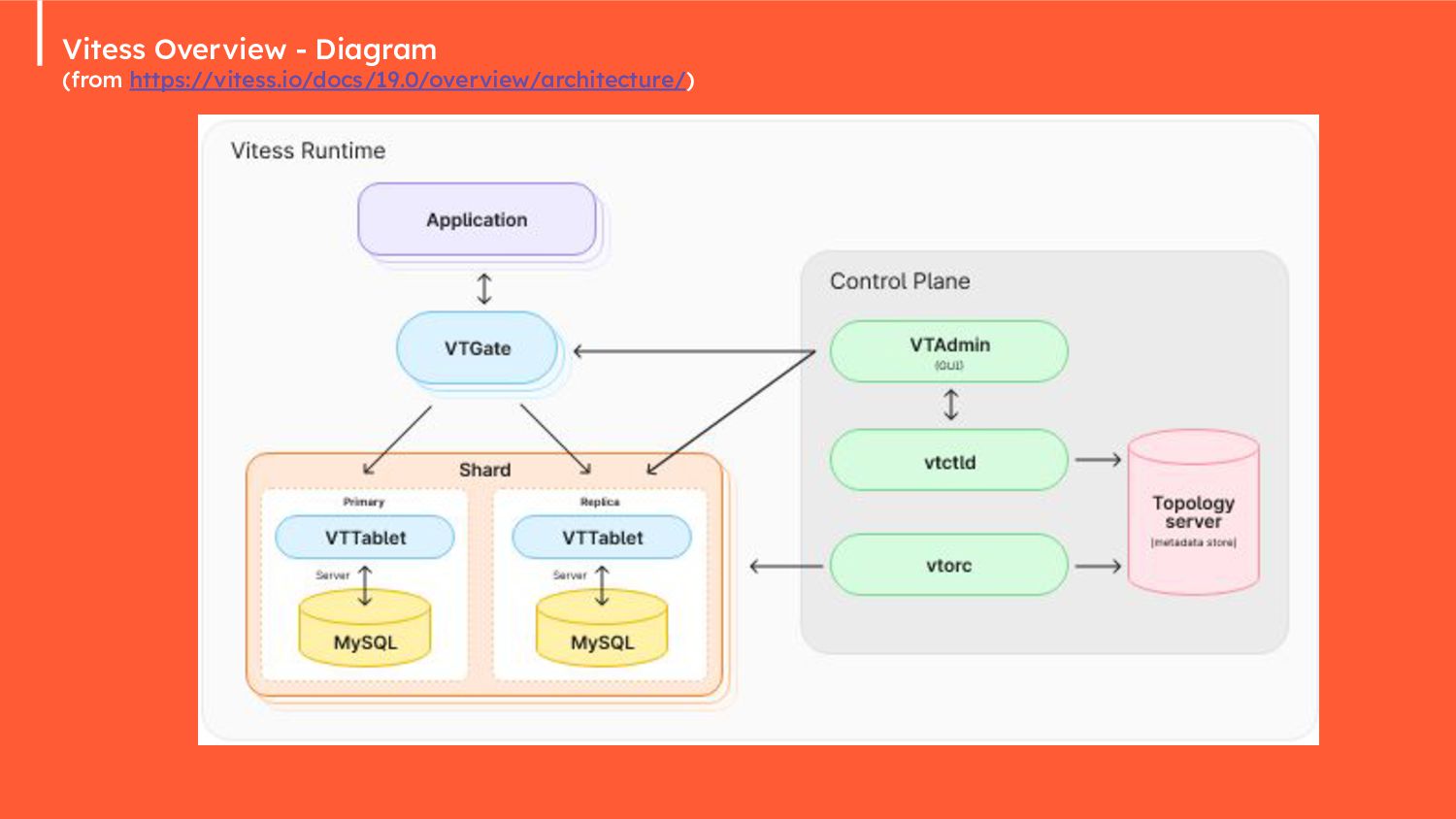{kind=link}
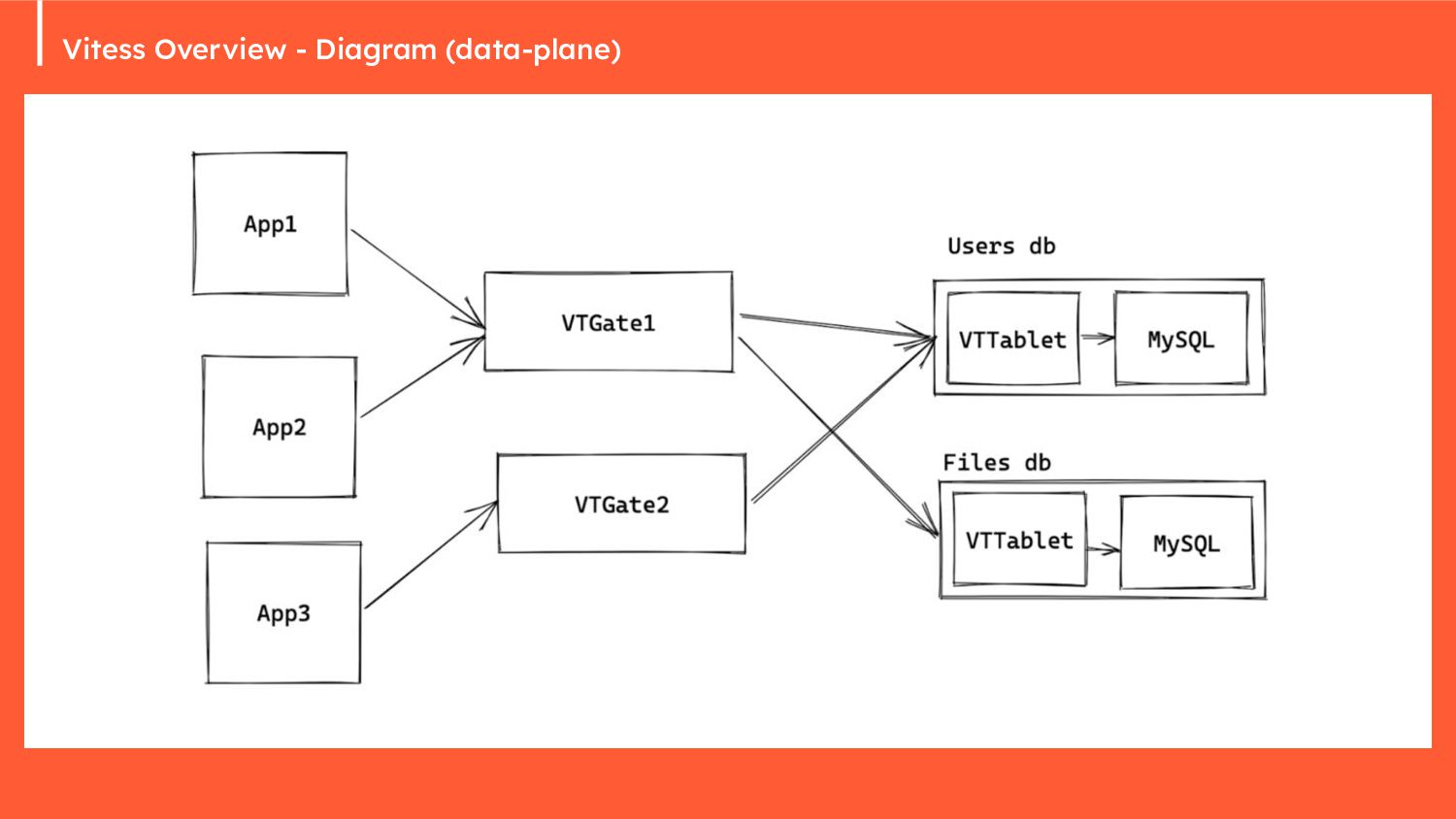{kind=link}
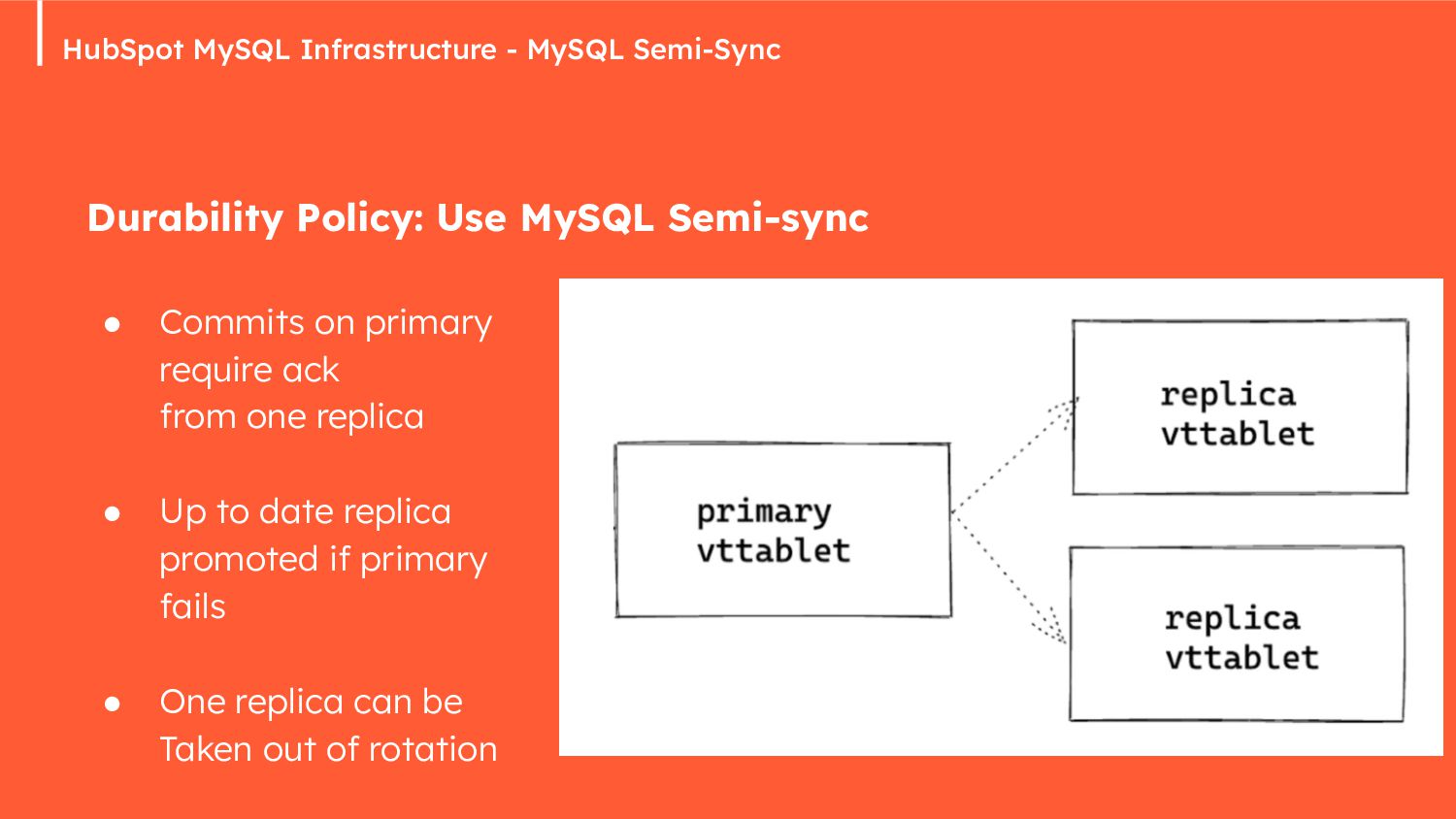{kind=link}
{kind=link}
{kind=link}
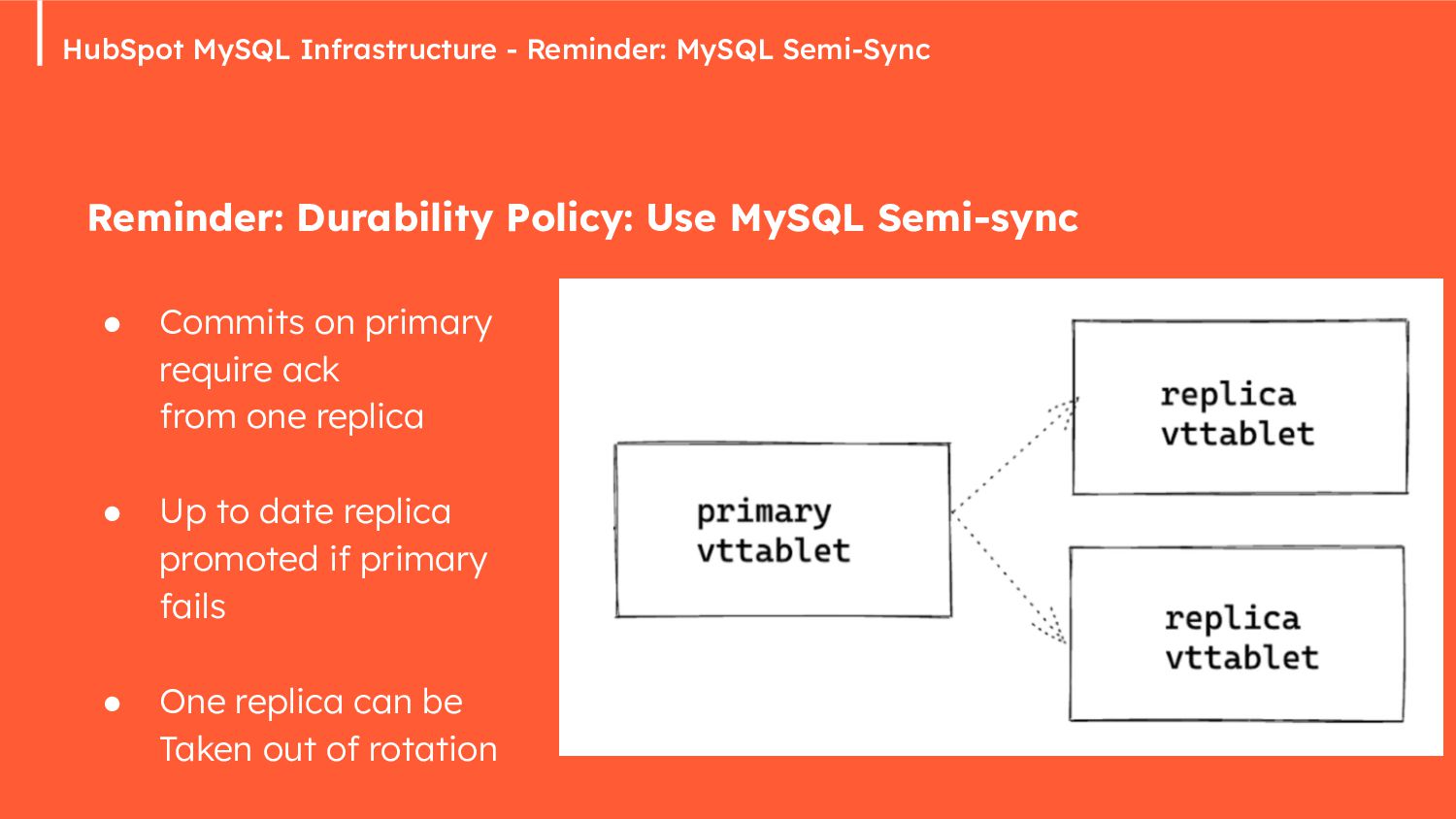{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
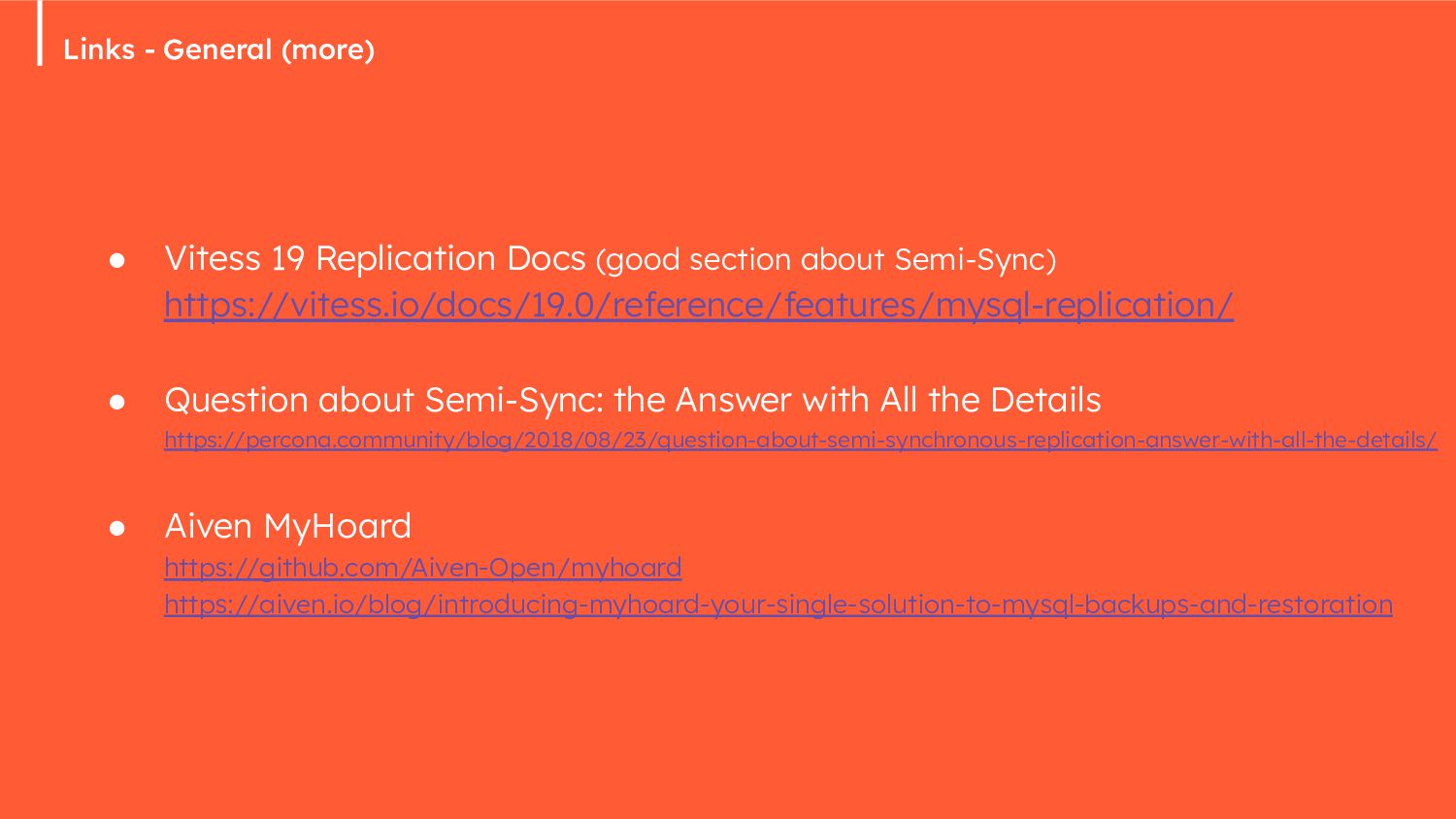{kind=link}
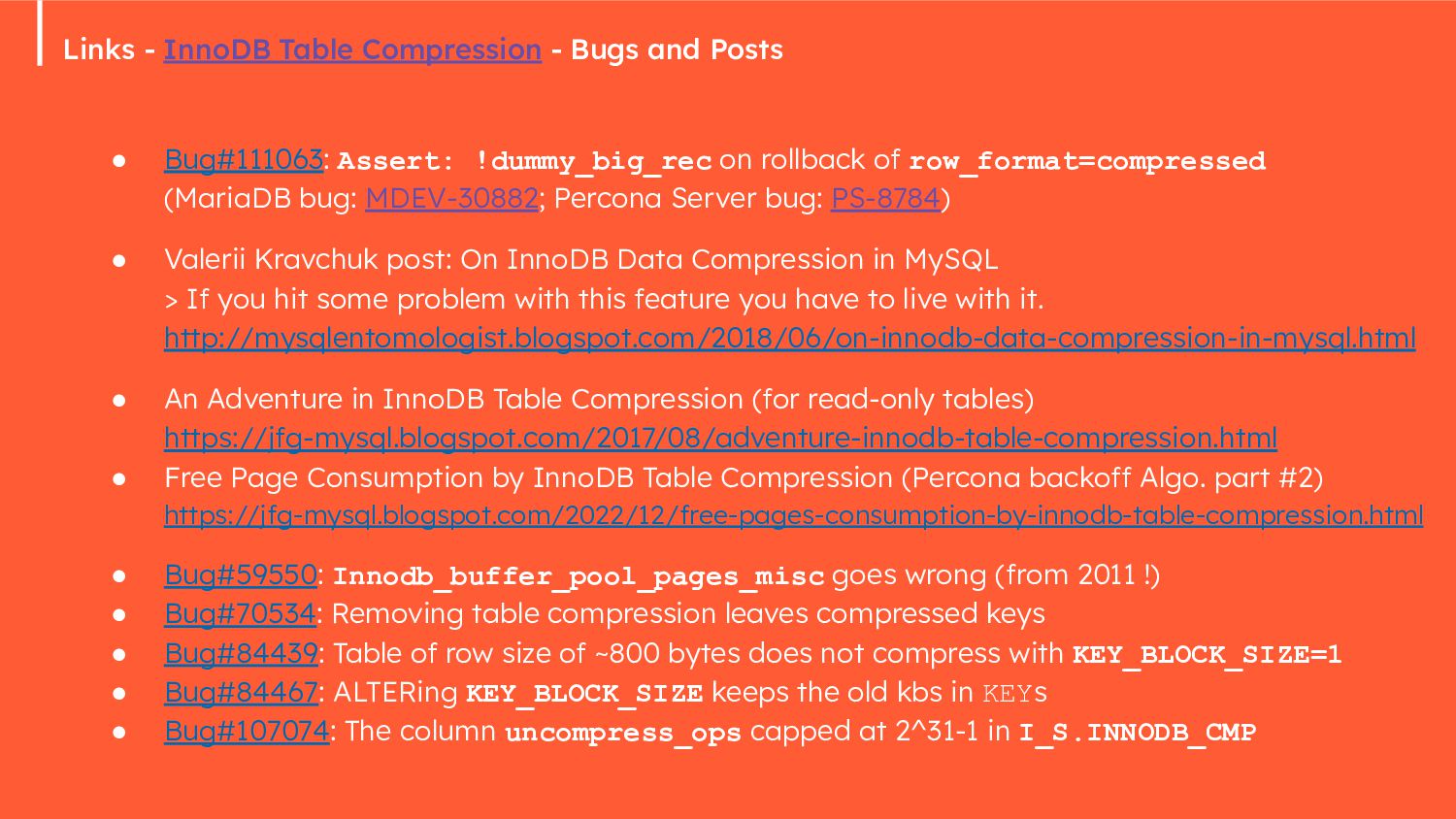{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}