Technology Insight · Document the Data – Creating Reports Using Docs Tooling
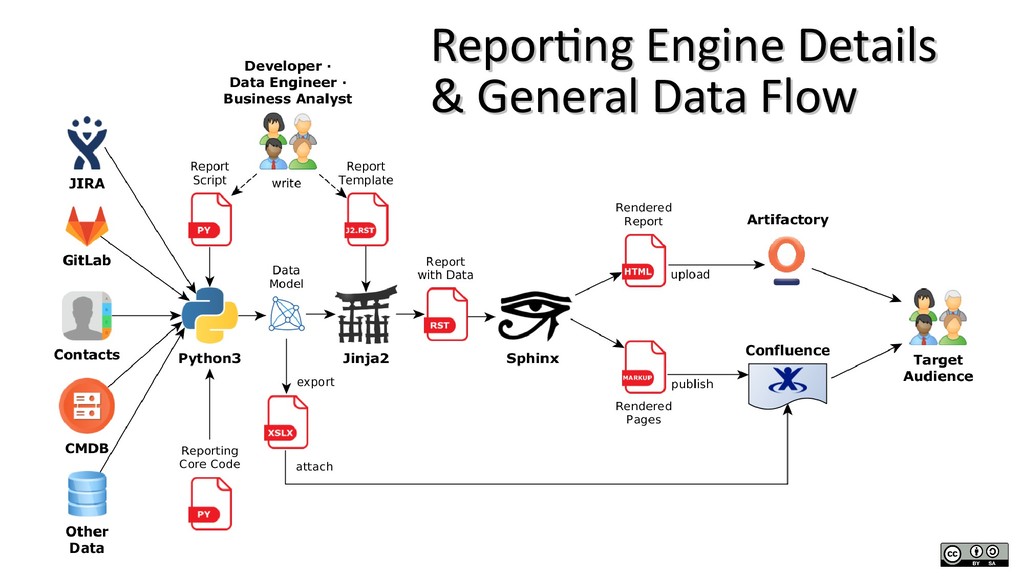
As a developer, use your existing skill set regarding programming and documentation to generate technical or business reports from distributed data sources.
https://www.meetup.com/PyData-Suedwest/events/250368244/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}