Tera-scheduling Esteban Eduardo Mocskos Departamento de Computaci´ on Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires Consejo Nacional de Investigaciones Cient´ ıficas y T´ ecnicas 2 of April, 2013 Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 1 / 28
local scene: 1 BIA: Plataforma de Bionform´ atica Argentina (Bioinformatics Platform) 2 CSC: Centro de Simulaci´ on Computacional para Aplicaciones Tecnol´ ogicas (Center for Computational Simulation in Technological Applications) - CONICET 3 SNCAD: Sistema Nacional de C´ omputo de Alto Desempe˜ no (National System for Large Computing Equipment) Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 2 / 28
R&D in Latin America Strategic research clusters established Fully functioning network focusing on activities to support and promote coordination of the HPC and Supercomputing research between Europe and Latin America Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 3 / 28
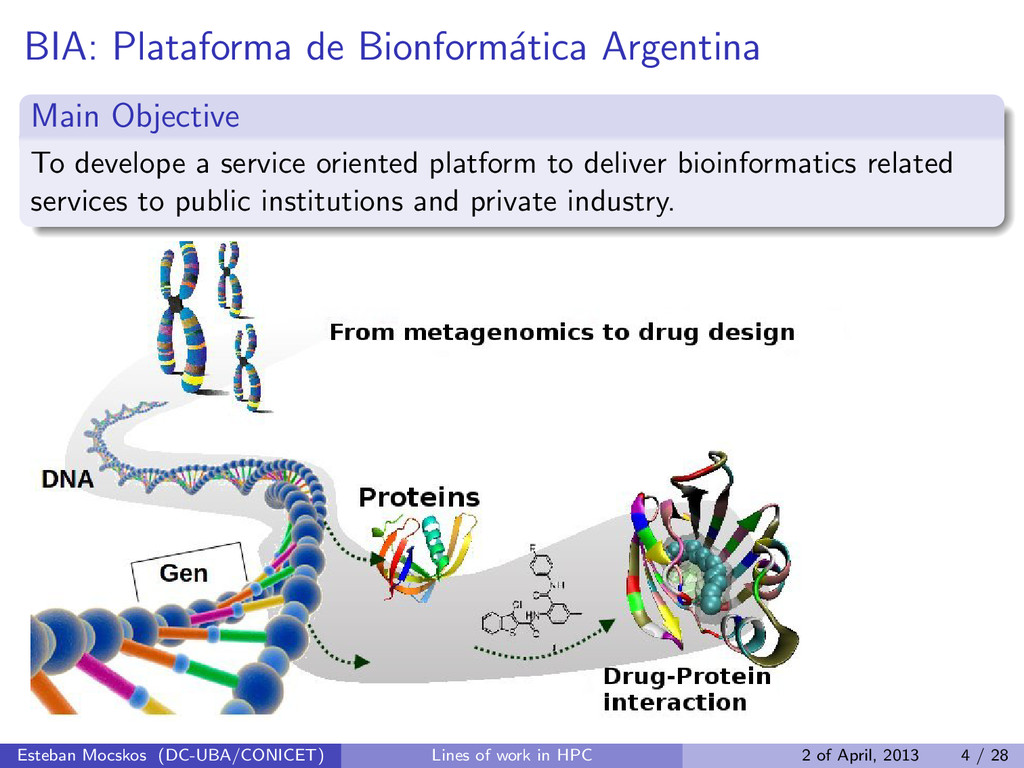
a service oriented platform to deliver bioinformatics related services to public institutions and private industry. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 4 / 28
in Computational Biology and Bioinformatics field. Cover identified necessities in Bioinformatics in public and private sectors. Increase the specialized human resources in the area: Undergraduate and postgraduate courses. Creation of Master in Bioinformatics Support the new orientation of Biology at UBA. Currently, searching and hiring staff, and buying equipment. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 5 / 28
To develop computational formulations oriented to the solution of technological problems in Argentinean industries. To train young Engineers and Scientists in the usage of Computational Mechanics methods. To perform original research. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 6 / 28
wave propagation in complex mediums. Technological Application for mechanical waves: sonar and sismic prospection. Technological Application for electromagnetic waves: radar. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 7 / 28
compute servers, with 2 system boards, each with 4 AMD 16-core-processor. Every server will have 512GB of RAM. In addition, there will be 2 servers with 16 nVidia Tesla GPU each. In total 4600 AMD CPU cores. 18 TB of DDR3 RAM. 32 nVidia Tesla GPU. About 48TFLOPS of GPU+CPU (Top500 RPeak) 40Gbps Infiniband 4xQDR connection for each server. Separate 10Gb Ethernet connection for resource administration and monitoring. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 8 / 28
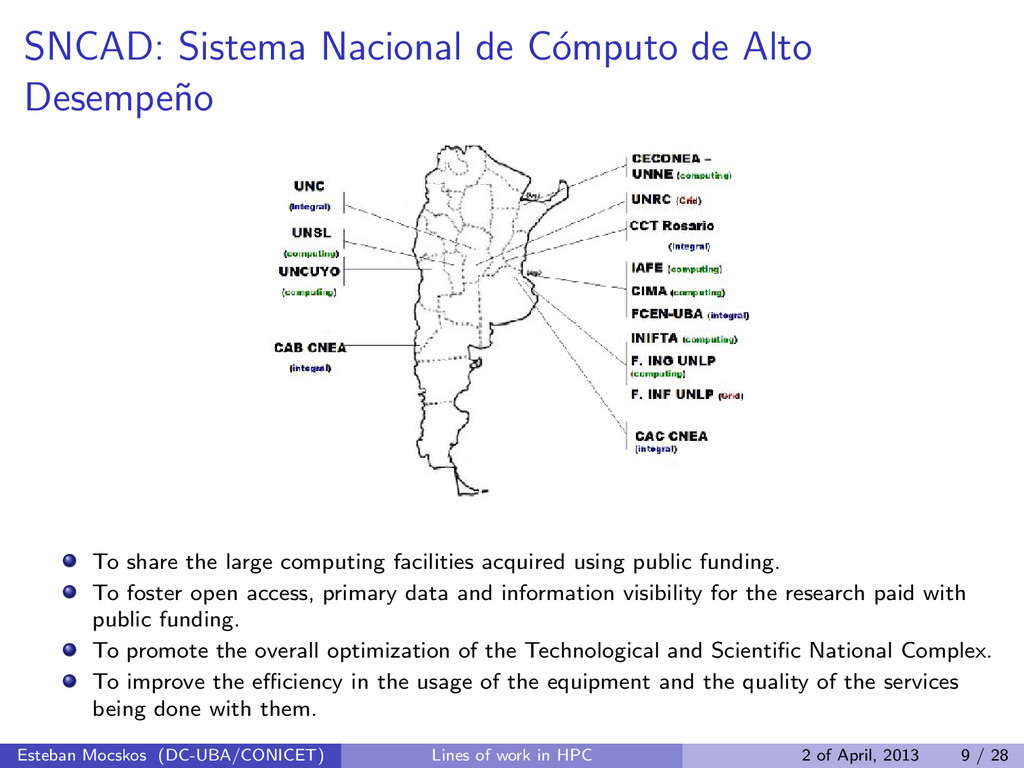
To share the large computing facilities acquired using public funding. To foster open access, primary data and information visibility for the research paid with public funding. To promote the overall optimization of the Technological and Scientific National Complex. To improve the efficiency in the usage of the equipment and the quality of the services being done with them. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 9 / 28
be available to be interconnected. The scheduling process needs up-to-date information about resources in the system. Any centralized point of failure must be avoided. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 10 / 28
increasing the speed). It will become more and more difficult to feed these cores. A change in the underlying architecture and (probably) computing model will eventually come. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 10 / 28
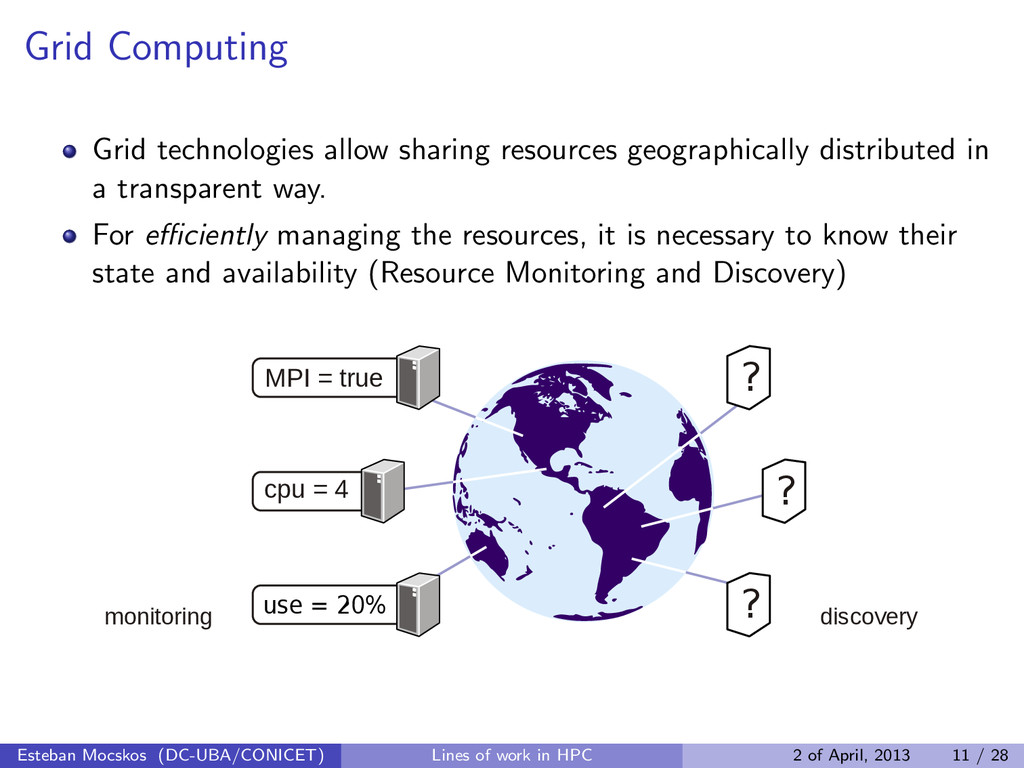
a transparent way. For efficiently managing the resources, it is necessary to know their state and availability (Resource Monitoring and Discovery) MPI = true monitoring discovery ? ? cpu = 4 ? use = 20% Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 11 / 28
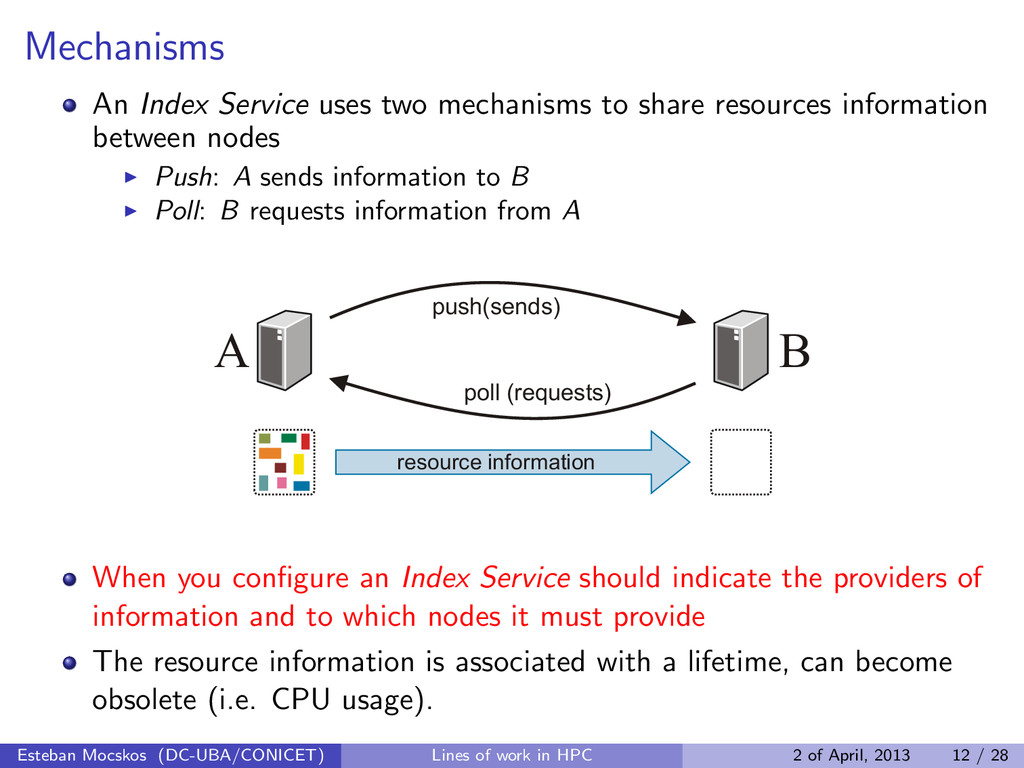
information between nodes Push: A sends information to B Poll: B requests information from A resource information poll (requests) push(sends) A B When you configure an Index Service should indicate the providers of information and to which nodes it must provide The resource information is associated with a lifetime, can become obsolete (i.e. CPU usage). Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 12 / 28
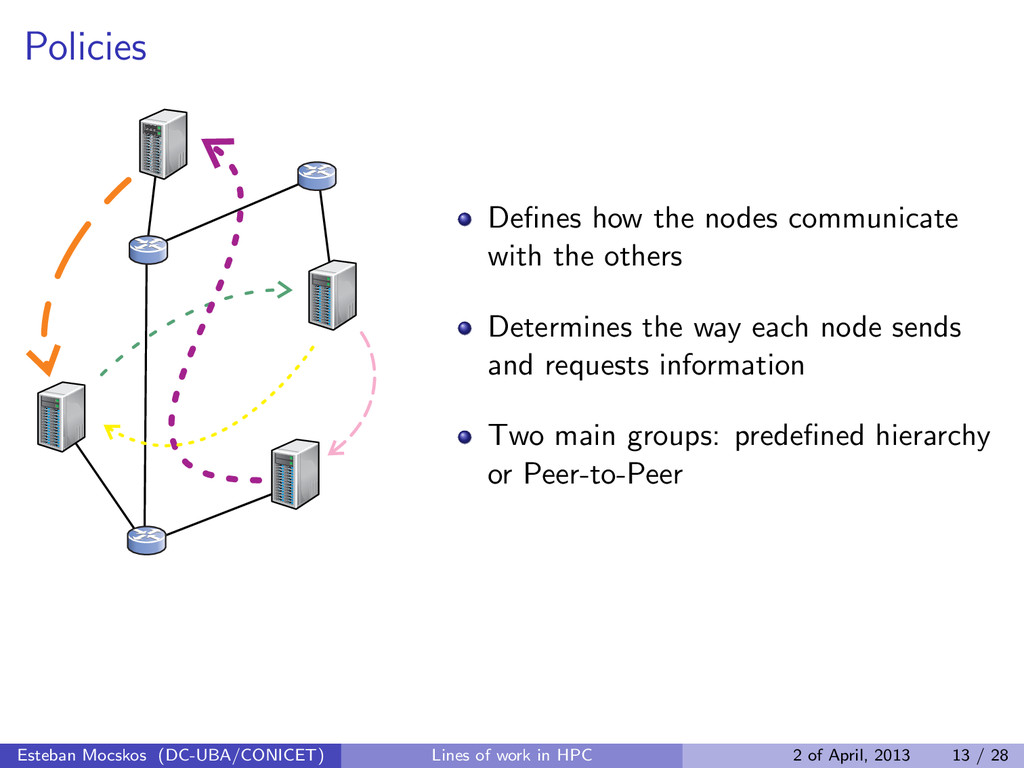
the way each node sends and requests information Two main groups: predefined hierarchy or Peer-to-Peer Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 13 / 28
take into account the associated lifetime of the information: LIR: captures the amount of information that a particular host has from all the entire grid in a single moment. For the host k, LIRk is: LIRk = N h=1 f (ageh, expirationh) · resourceCounth totalResourceCount N - number of hosts in the system expirationh - the expiration time of the resources of host h in host k ageh - the time passed since the information was obtained by k node resourceCounth - the amount of resources in host h totalResourceCount - is the total amount of resources in the whole grid Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 14 / 28
take into account the associated lifetime of the information: LIR: captures the amount of information that a particular host has from all the entire grid in a single moment. For the host k, LIRk is: LIRk = N h=1 f (ageh, expirationh) · resourceCounth totalResourceCount N - number of hosts in the system expirationh - the expiration time of the resources of host h in host k ageh - the time passed since the information was obtained by k node resourceCounth - the amount of resources in host h totalResourceCount - is the total amount of resources in the whole grid GIR: captures the amount of information that the whole grid knows, is the mean value of every node’s LIR. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 14 / 28
the behavior of different information distribution policies SimGrid2 is used as simulation engine Graphical interface for the design of the underlying network Allows automatically generating networks and measures the main properties Displays the simulation execution Coded in C++, QT and Python (multiplatform) Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 15 / 28
using many different information propagation policies. As a case study, we analysed the clique network topology. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 16 / 28
using many different information propagation policies. As a case study, we analysed the clique network topology. Tested the following policies: Random Hierarchical Super-Peer Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 16 / 28
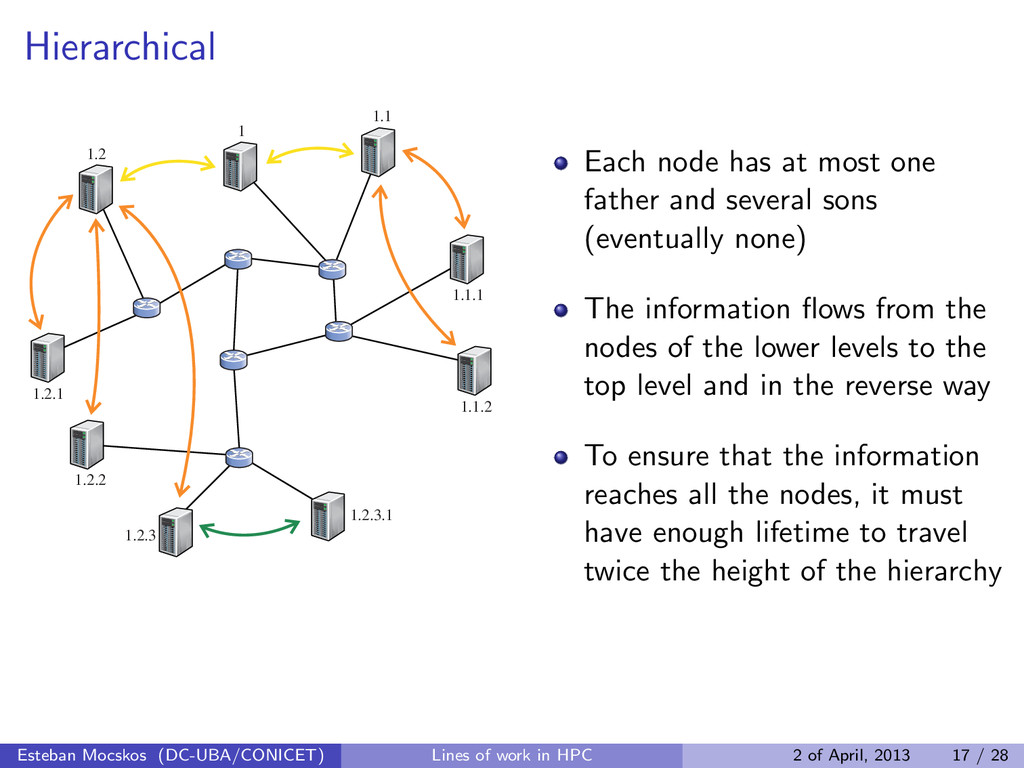
Each node has at most one father and several sons (eventually none) The information flows from the nodes of the lower levels to the top level and in the reverse way To ensure that the information reaches all the nodes, it must have enough lifetime to travel twice the height of the hierarchy Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 17 / 28
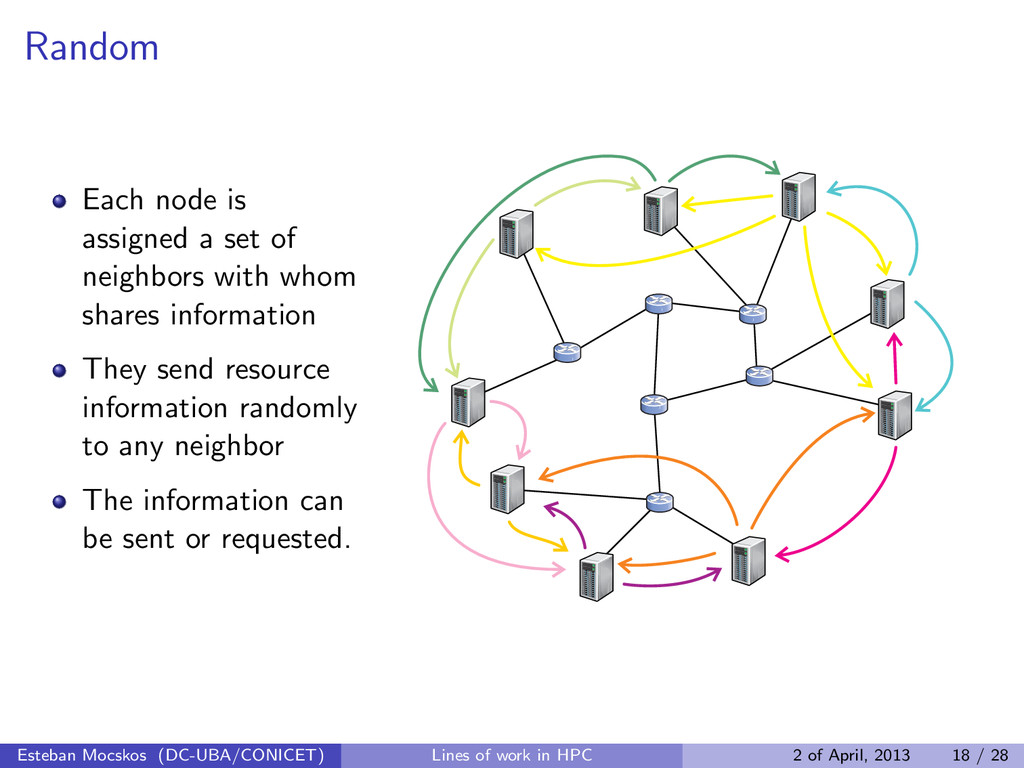
whom shares information They send resource information randomly to any neighbor The information can be sent or requested. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 18 / 28
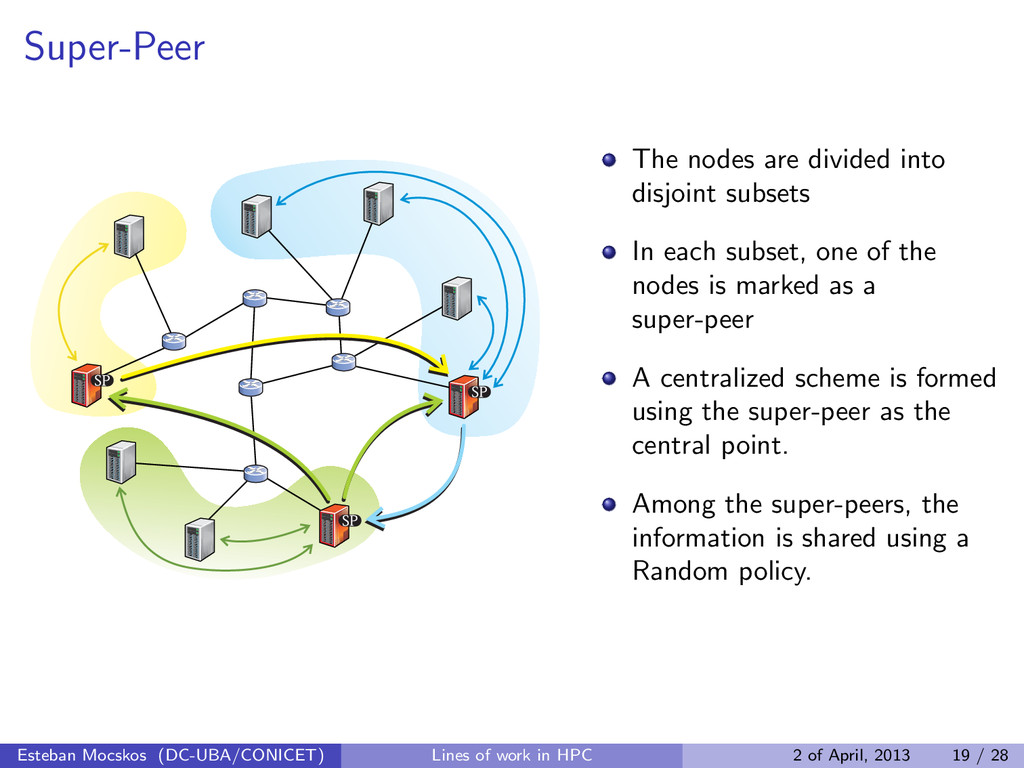
subset, one of the nodes is marked as a super-peer A centralized scheme is formed using the super-peer as the central point. Among the super-peers, the information is shared using a Random policy. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 19 / 28
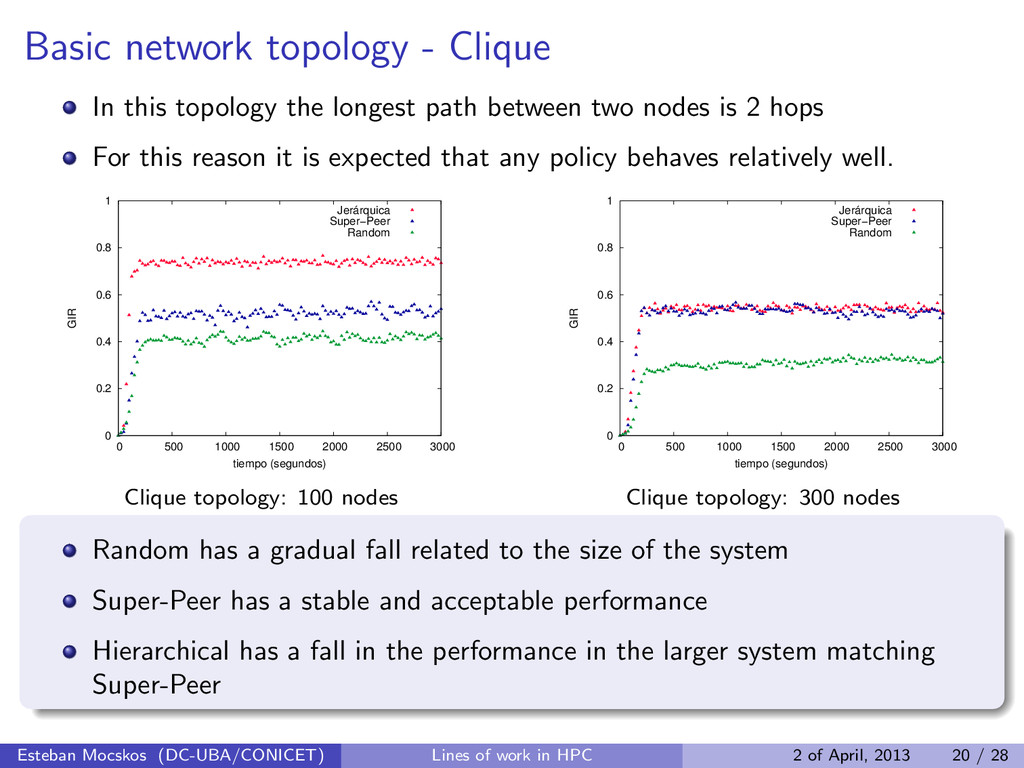
path between two nodes is 2 hops For this reason it is expected that any policy behaves relatively well. 0 0.2 0.4 0.6 0.8 1 0 500 1000 1500 2000 2500 3000 GIR tiempo (segundos) Jerárquica Super−Peer Random Clique topology: 100 nodes 0 0.2 0.4 0.6 0.8 1 0 500 1000 1500 2000 2500 3000 GIR tiempo (segundos) Jerárquica Super−Peer Random Clique topology: 300 nodes Random has a gradual fall related to the size of the system Super-Peer has a stable and acceptable performance Hierarchical has a fall in the performance in the larger system matching Super-Peer Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 20 / 28
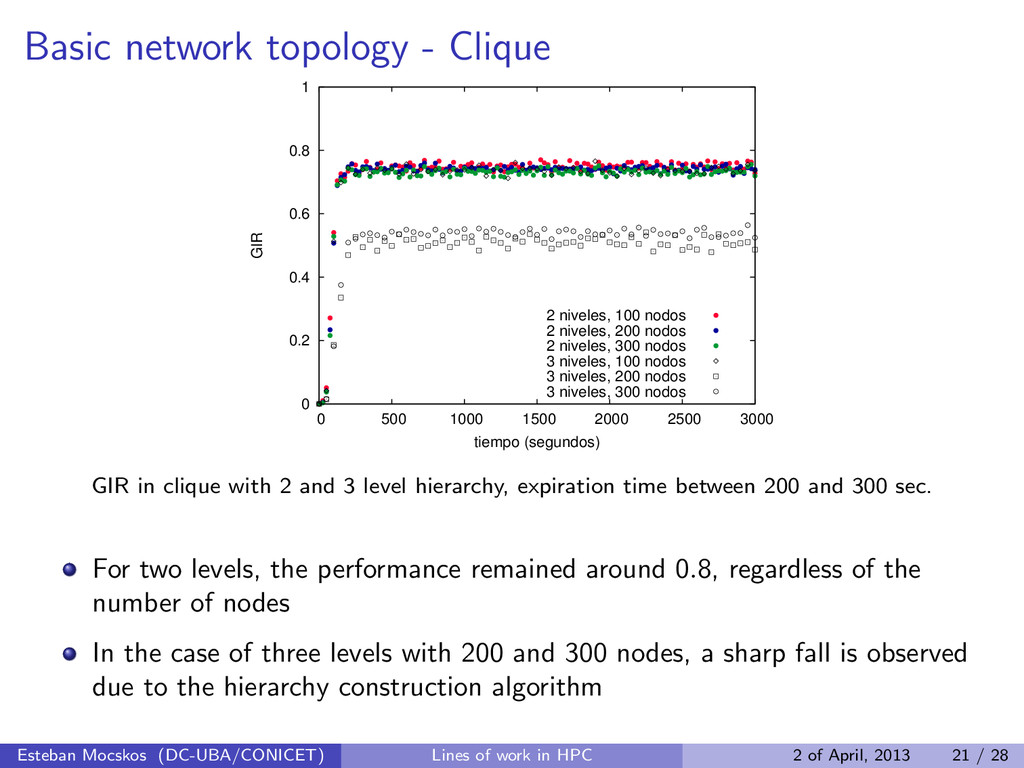
1 0 500 1000 1500 2000 2500 3000 GIR tiempo (segundos) 2 niveles, 100 nodos 2 niveles, 200 nodos 2 niveles, 300 nodos 3 niveles, 100 nodos 3 niveles, 200 nodos 3 niveles, 300 nodos GIR in clique with 2 and 3 level hierarchy, expiration time between 200 and 300 sec. For two levels, the performance remained around 0.8, regardless of the number of nodes In the case of three levels with 200 and 300 nodes, a sharp fall is observed due to the hierarchy construction algorithm Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 21 / 28
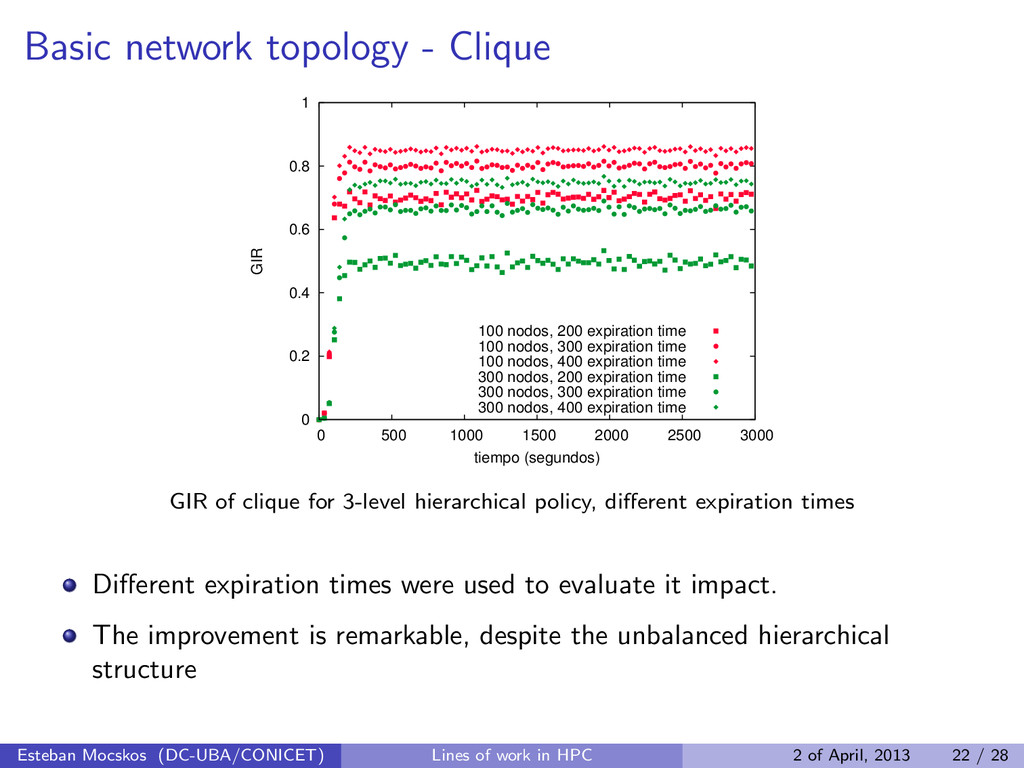
1 0 500 1000 1500 2000 2500 3000 GIR tiempo (segundos) 100 nodos, 200 expiration time 100 nodos, 300 expiration time 100 nodos, 400 expiration time 300 nodos, 200 expiration time 300 nodos, 300 expiration time 300 nodos, 400 expiration time GIR of clique for 3-level hierarchical policy, different expiration times Different expiration times were used to evaluate it impact. The improvement is remarkable, despite the unbalanced hierarchical structure Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 22 / 28
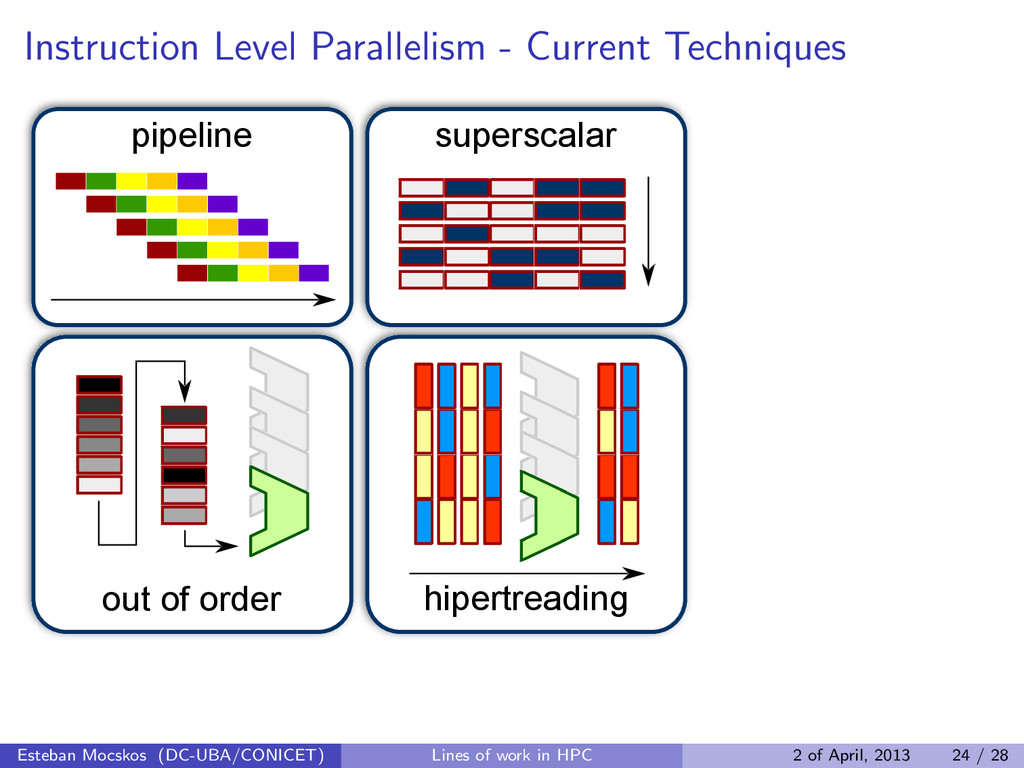
But... we can not increase the clock frequency We need to run more instructions in parallel Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 23 / 28
core. This is the only way to have more powerful processors because the frequency is fixed for the non-gamers. It is very difficult to efficiently use these processors. There is (or will be) a need for a new computing model, to take advantage of the increasing amount of cores in each chip Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 23 / 28
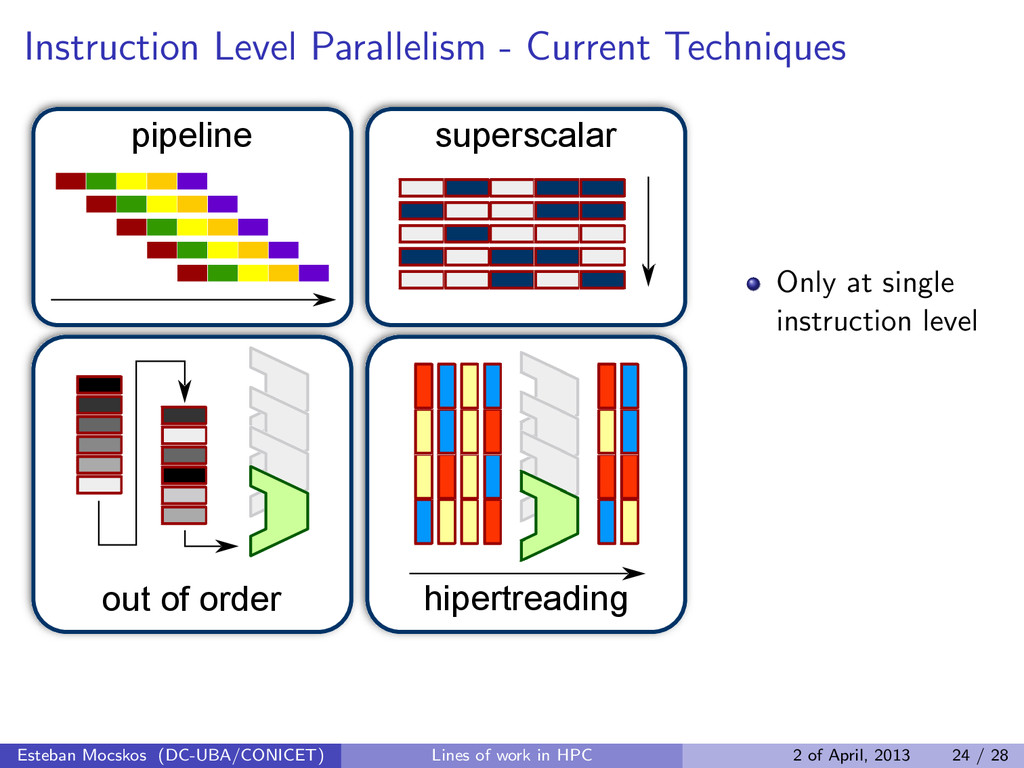
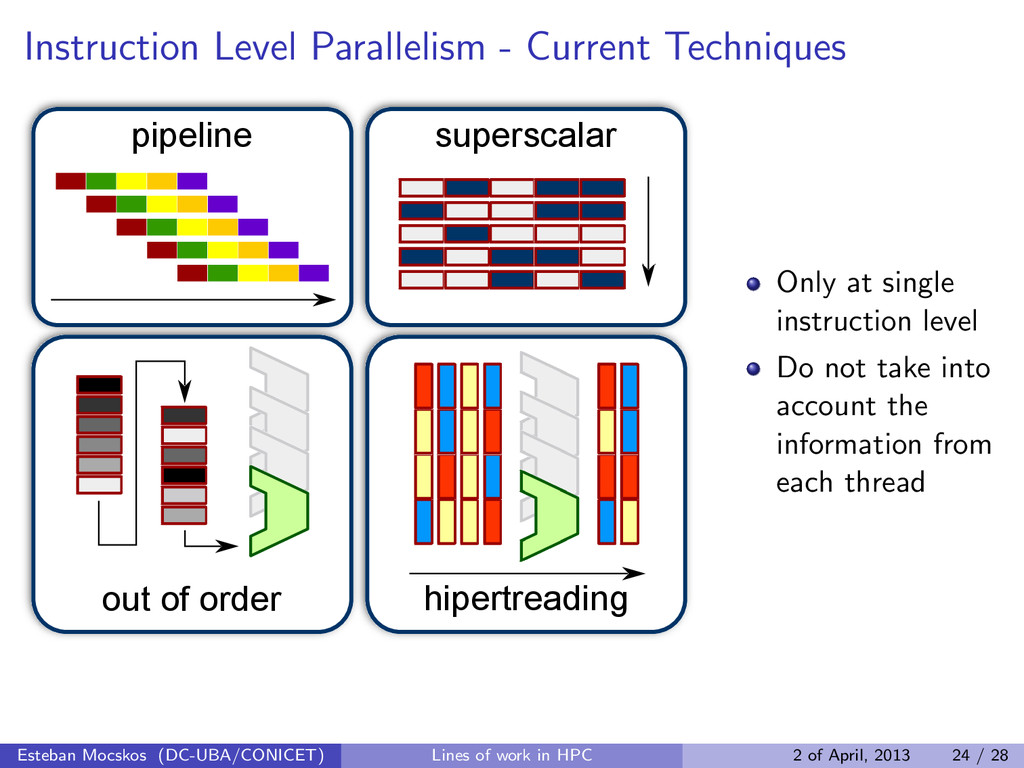
hipertreading superscalar Only at single instruction level Do not take into account the information from each thread Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 24 / 28
Microthread 2 Processor 2 Microthread 3 Processor 3 My program Processor 0 new new new new end end end end mth queue One main thread and several short-lived threads collaborating (called microthread). Add new instructions to the ISA for launching microthreads. The microthreads run in a different core with a copy of the main thread context. Each microthread run until it terminates. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 25 / 28
Microthread 2 Processor 2 Microthread 3 Processor 3 My program Processor 0 new new new new end end end end mth queue One main thread and several short-lived threads collaborating (called microthread). Add new instructions to the ISA for launching microthreads. The microthreads run in a different core with a copy of the main thread context. Each microthread run until it terminates. We need to do all of this very very very VERY fast Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 25 / 28
to a launch a (micro)thread fast. Objectives Less overhead allows us to further exploit parallelism. It must be well supported in software. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 26 / 28
to a launch a (micro)thread fast. New Primitives - Launch and stop threads: mthRun, mthEnd - Synchronization: waitForThreads How is it done? We decompose a program in several parts (eventually will be a compiler task, maybe user assisted). Each part can be scheduled for running in a separate core The cores have a mechanism for duplicating the registers from the master core to the others Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 26 / 28
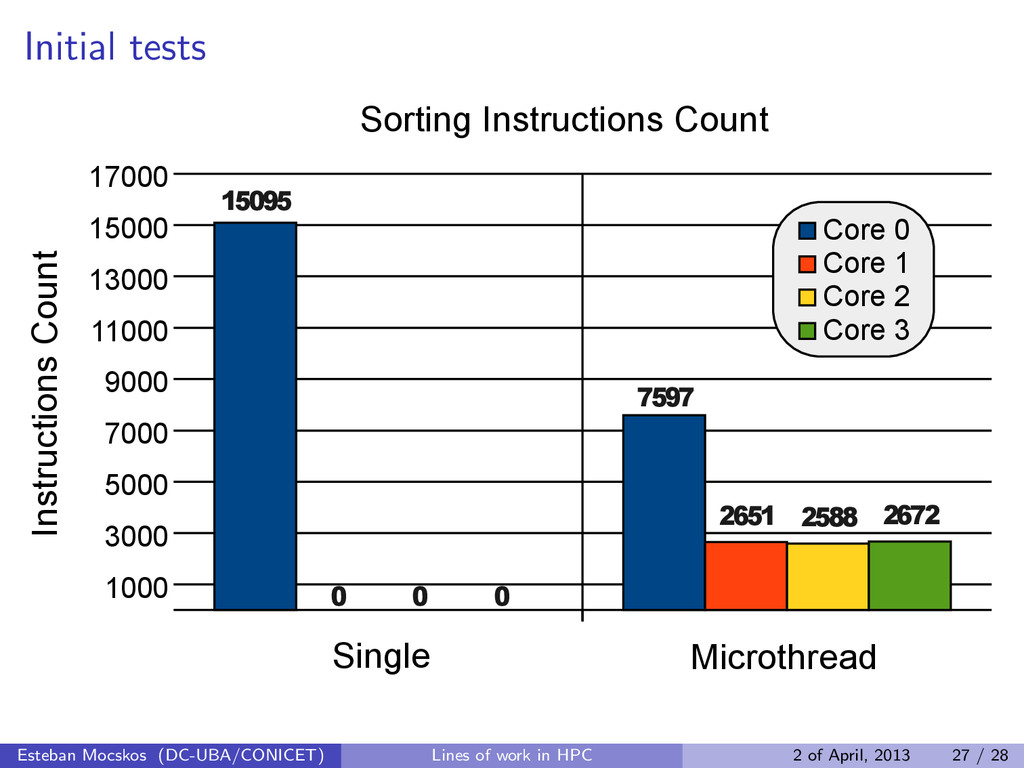
no sense in a conventional parallel mechanism (due to overhead) Serial solution - implement a heap sort (about 15000 instructions until finished) Parallel solution - divide the array in four parts - run a heap sort in a microthread for each part - merge the four arrays (about 7000 instructions until finished) Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 27 / 28
Grids. Planning a new architecture to support the increasing number of cores to come Important We have some resources, we are willing to share them. Think in students exchange, research short stays. There are opportunities all around, we have to be smart to use them. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 28 / 28
Grids. Planning a new architecture to support the increasing number of cores to come Briefly: Trying to be a step ahead and understand the dynamics of the systems to come in the small and large scale. Important We have some resources, we are willing to share them. Think in students exchange, research short stays. There are opportunities all around, we have to be smart to use them. Esteban Mocskos (DC-UBA/CONICET) Lines of work in HPC 2 of April, 2013 28 / 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}