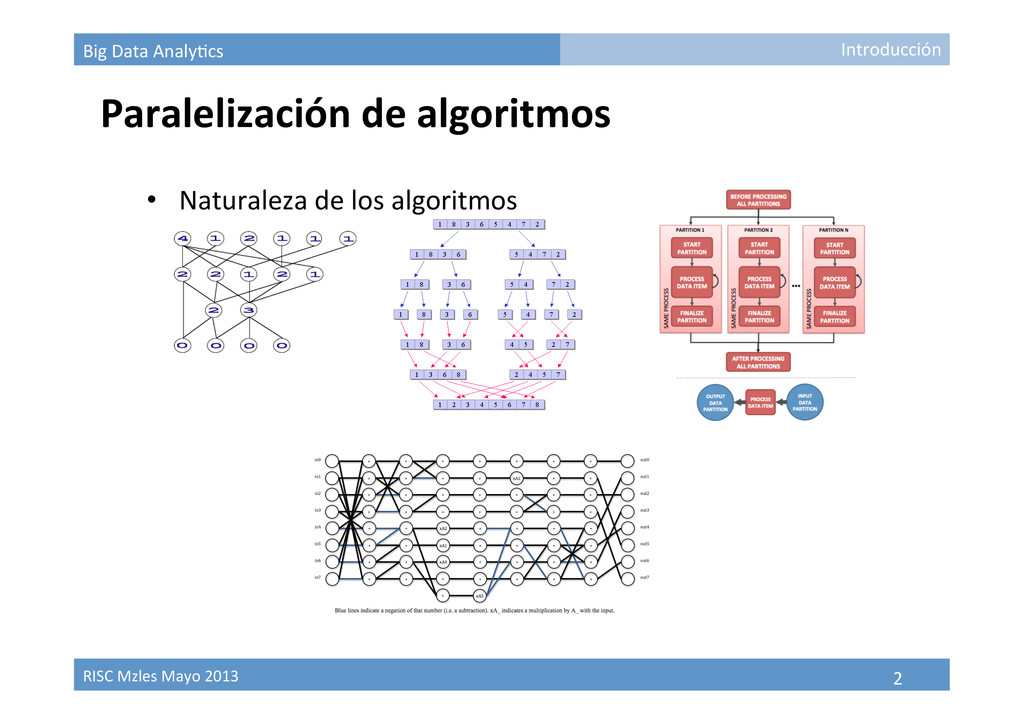
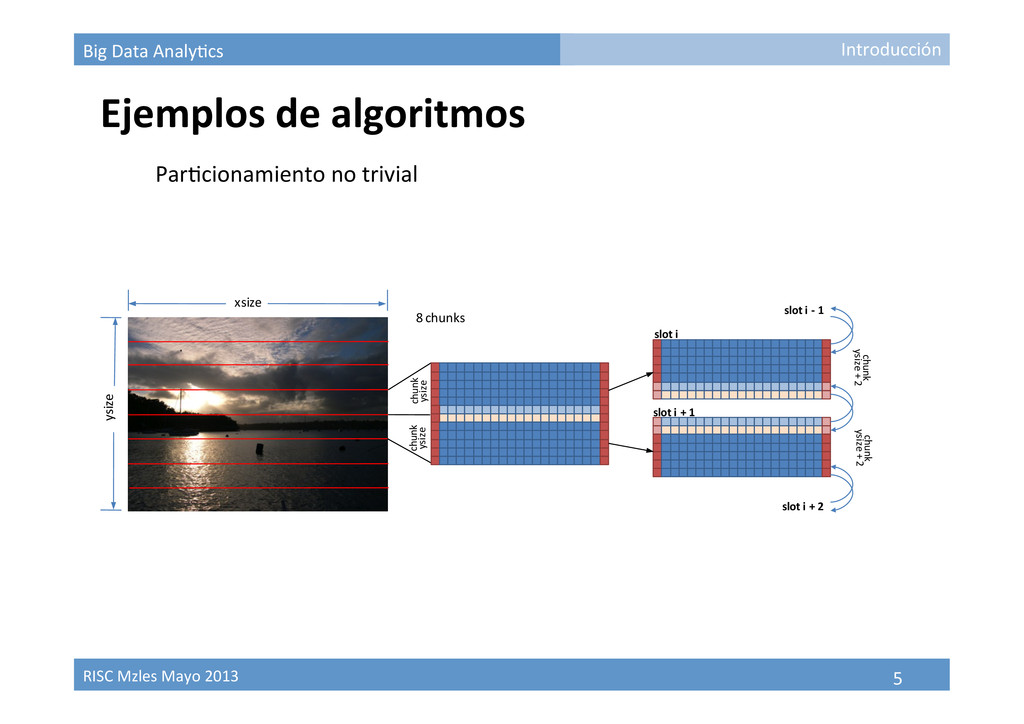
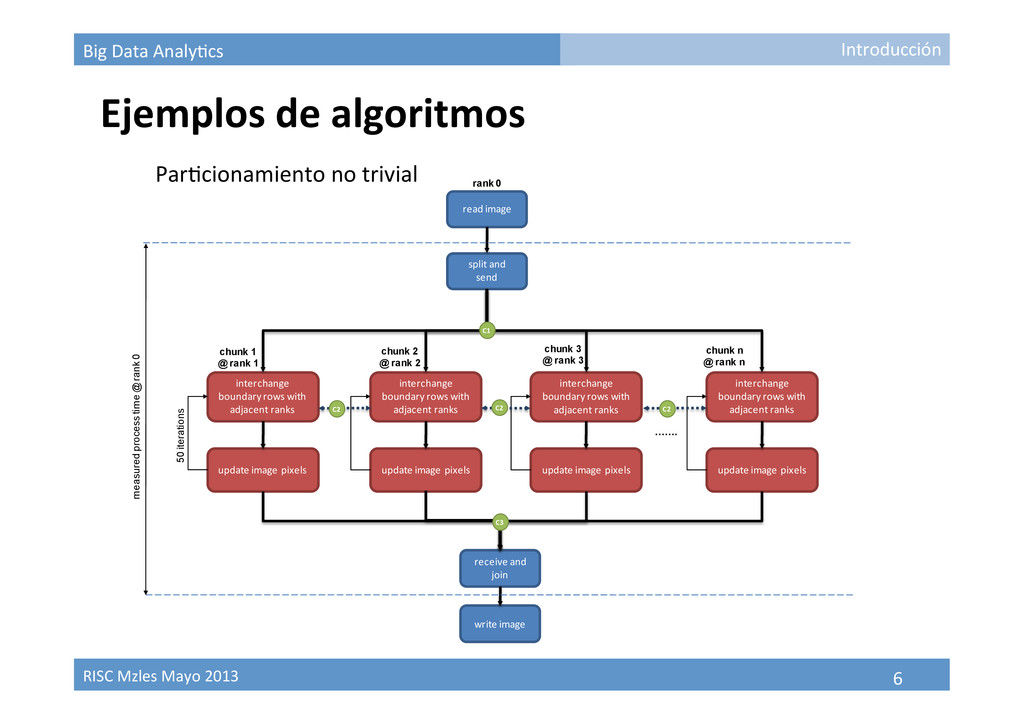
Paralelización de algoritmos • Recurso computacional disponible (GPUs, Cluster, Grids, Clouds, …) • Topología interconexión unidades de cómputo • Estrategias para explotar recursos computacionales Por paralelización intrínseca del algoritmo Por barrido de parámetros Por par9ción de datos Introducción
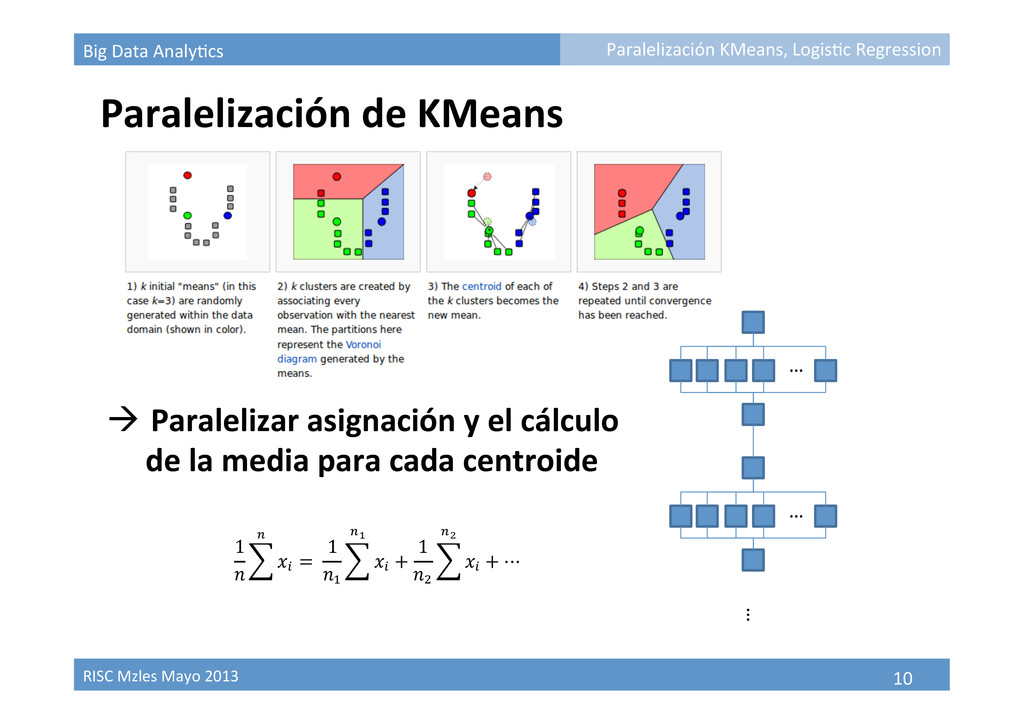
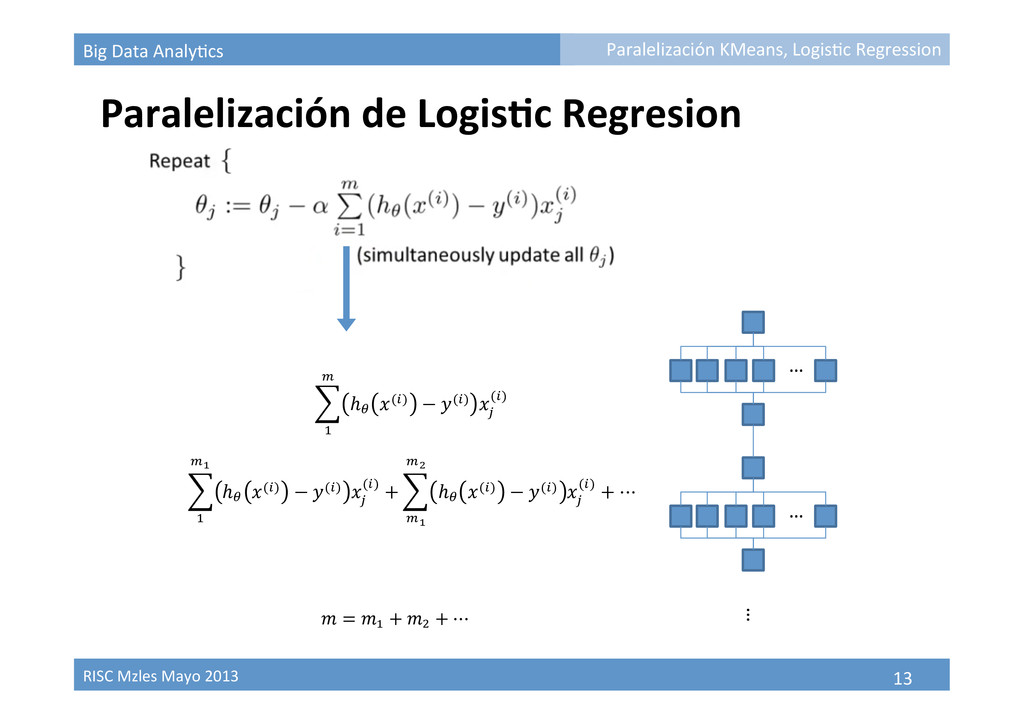
Paralelización de KMeans à Paralelizar asignación y el cálculo de la media para cada centroide … … … Paralelización KMeans, Logis9c Regression 1 ! !! ! =! 1 !! !! !! + 1 !! !! !! + ⋯!!
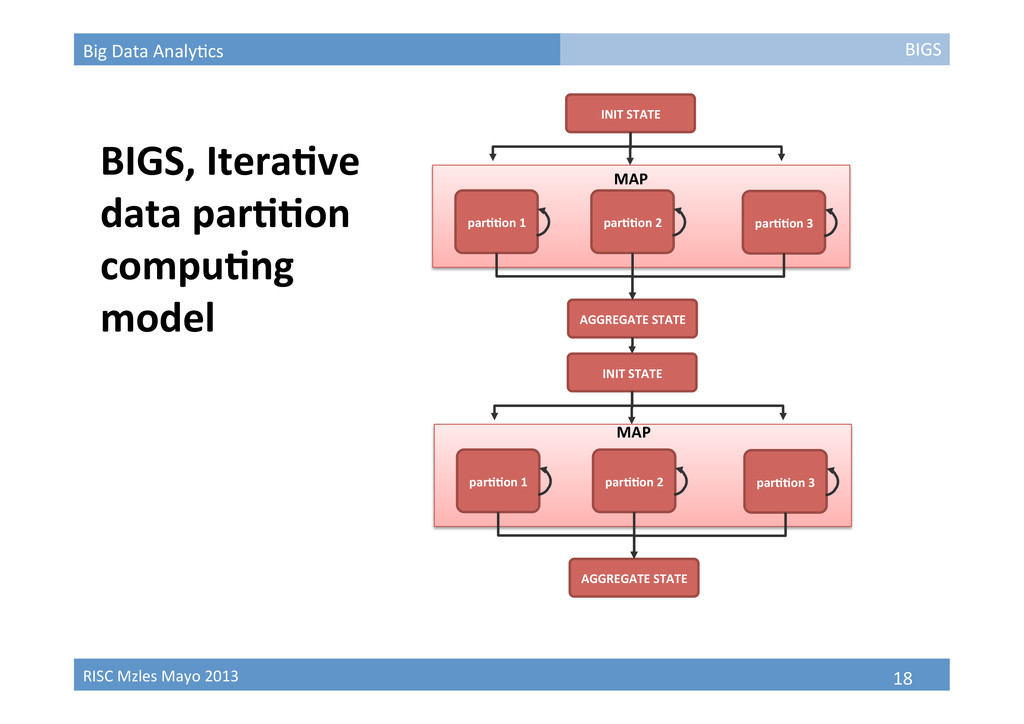
INIT STATE AGGREGATE STATE parBBon 1 parBBon 2 parBBon 3 BIGS, IteraBve data parBBon compuBng model BIGS MAP INIT STATE AGGREGATE STATE parBBon 1 parBBon 2 parBBon 3 MAP
Bases de datos NoSQL • Expresividad SQL vs. Escalabilidad • Tablas: filas de keys + lista no fija de columnas/valores • Operaciones simples: Scan por key Acceso directo por key Transacciones mínimas (check&put) No joins, no SQL language • Big table, Hbase, DynamoDB, Azure, Cassandra, etc.
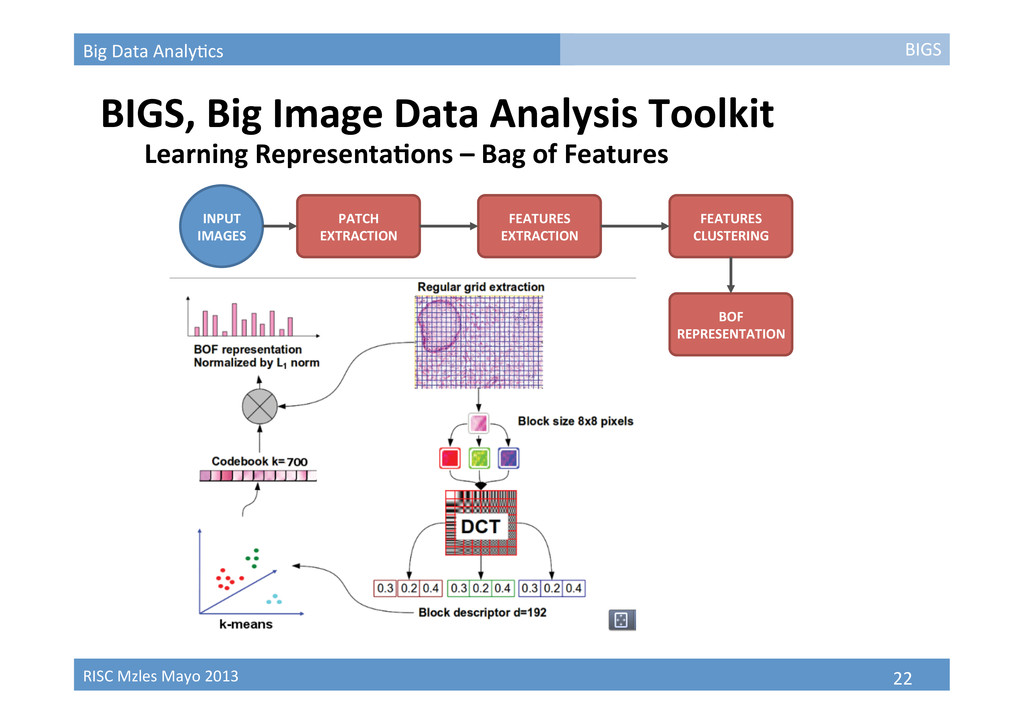
BIGS, Big Image Data Analysis Toolkit PATCH EXTRACTION INPUT IMAGES FEATURES EXTRACTION FEATURES CLUSTERING BOF REPRESENTATION BIGS Learning RepresentaBons – Bag of Features
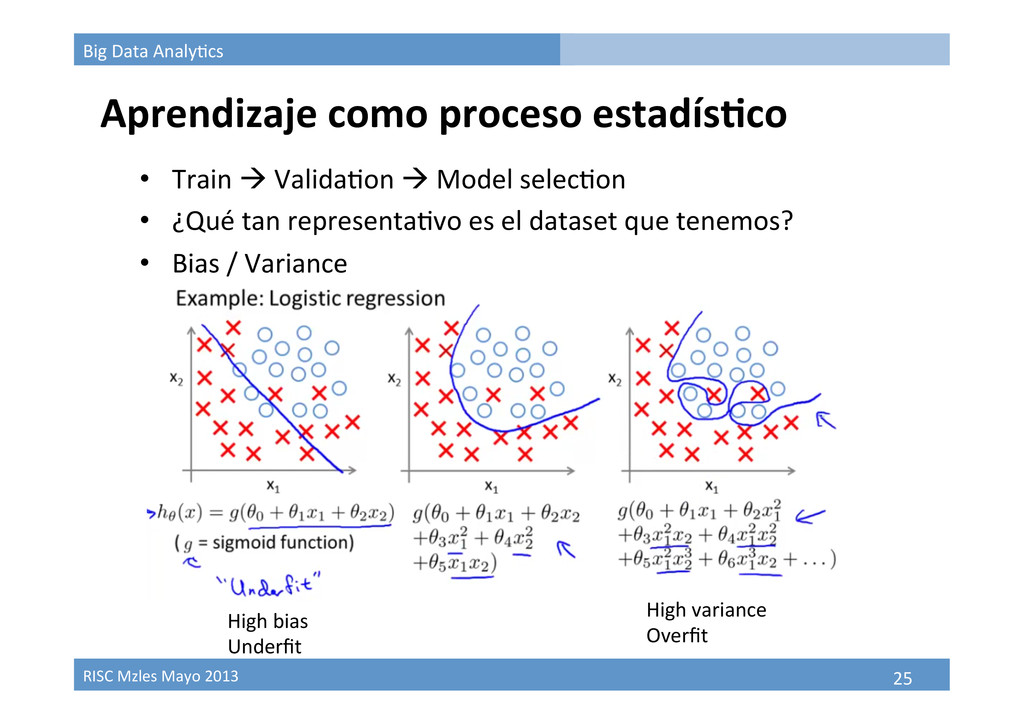
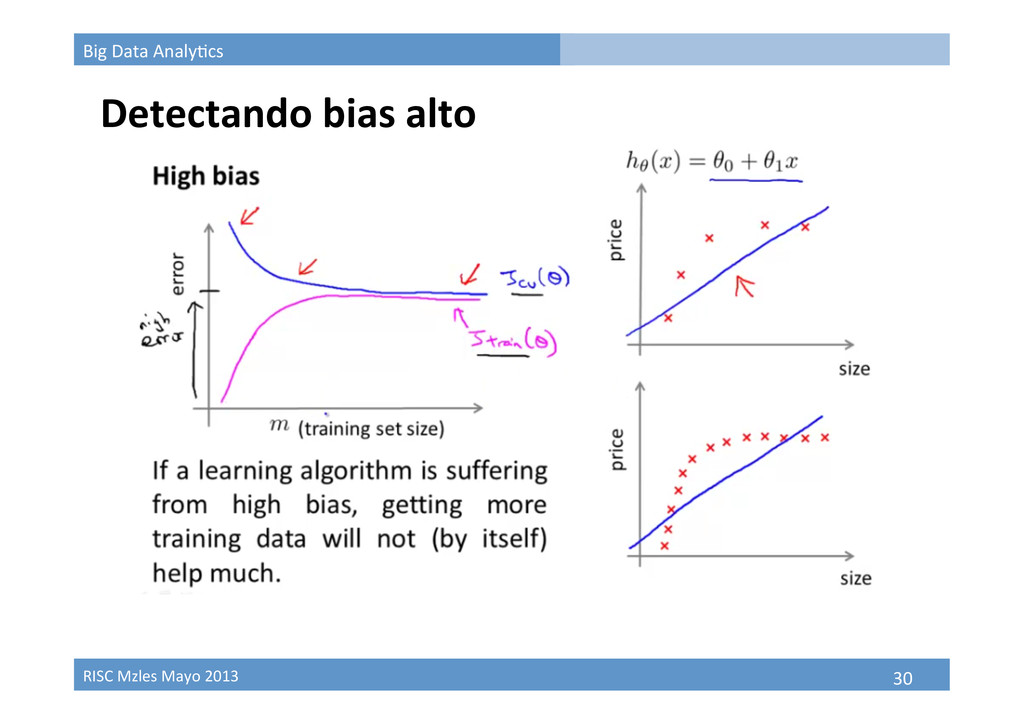
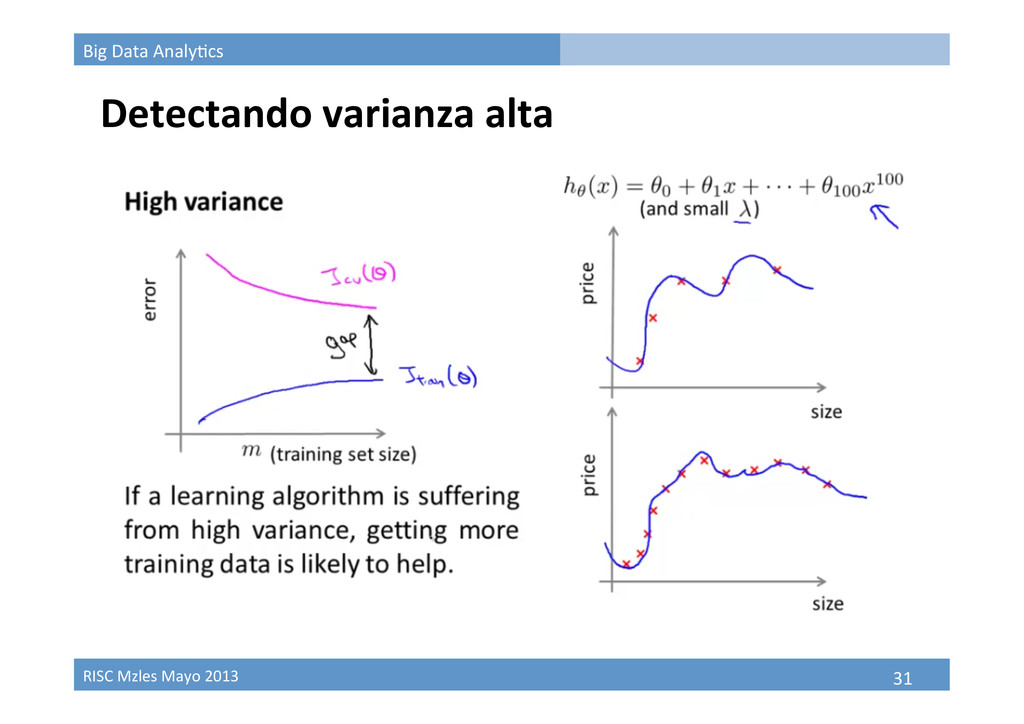
Aprendizaje como proceso estadísBco • Train à Valida9on à Model selec9on • ¿Qué tan representa9vo es el dataset que tenemos? • Bias / Variance High bias Underfit High variance Overfit
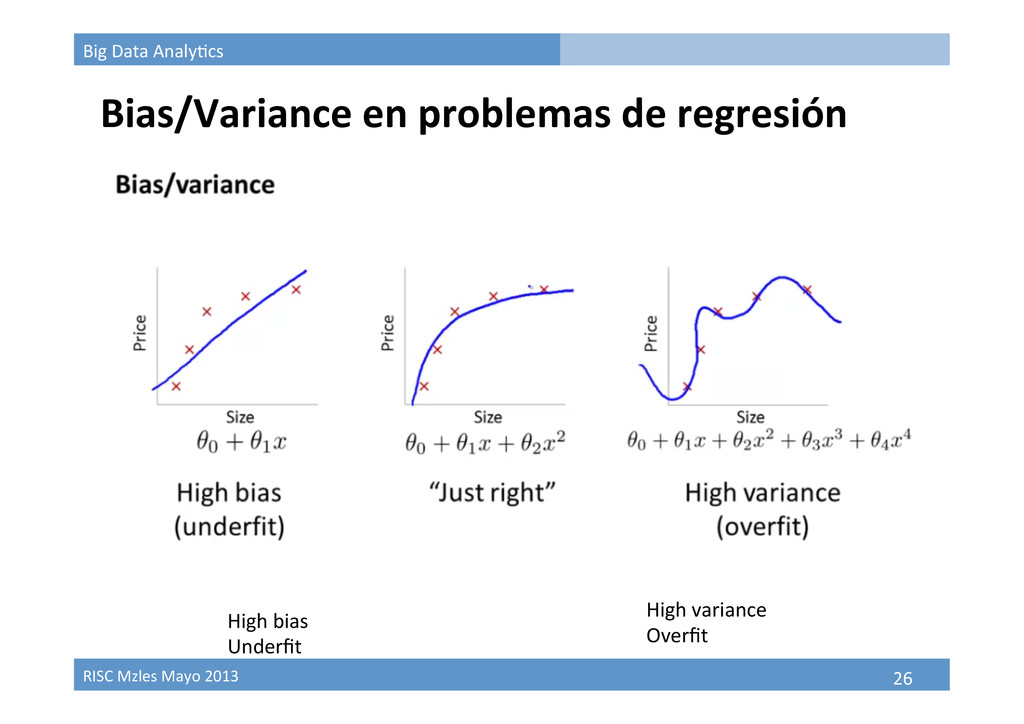
Bias/Variance en problemas de regresión • Train à Valida9on à Model selec9on • ¿Qué tan representa9vo es el dataset que tenemos? • Bias / Variance High bias Underfit High variance Overfit
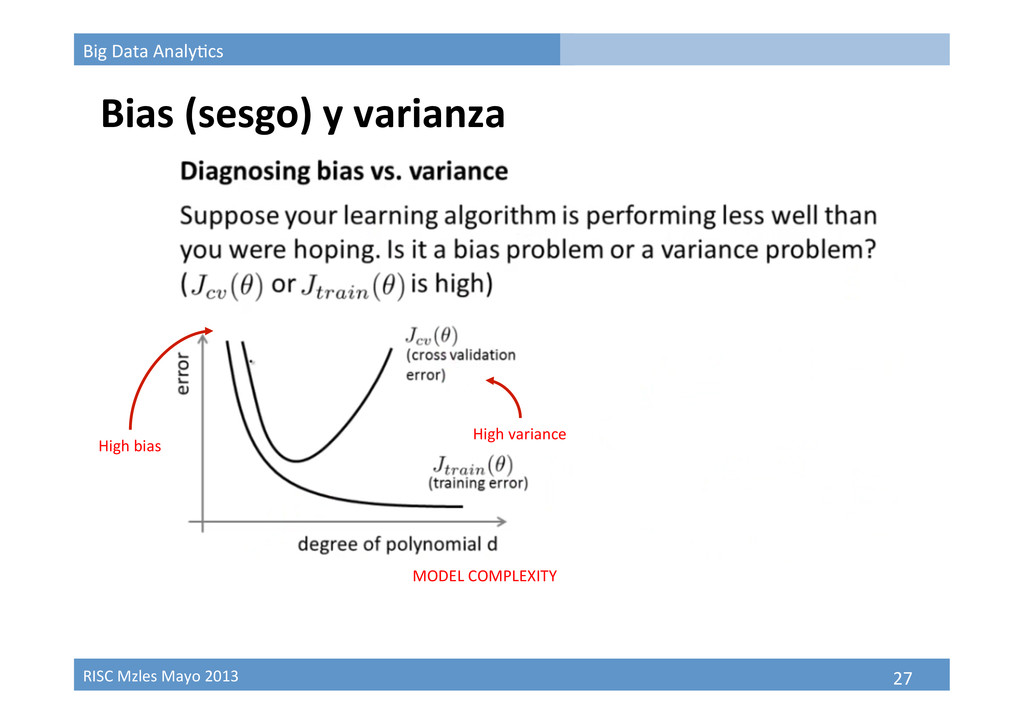
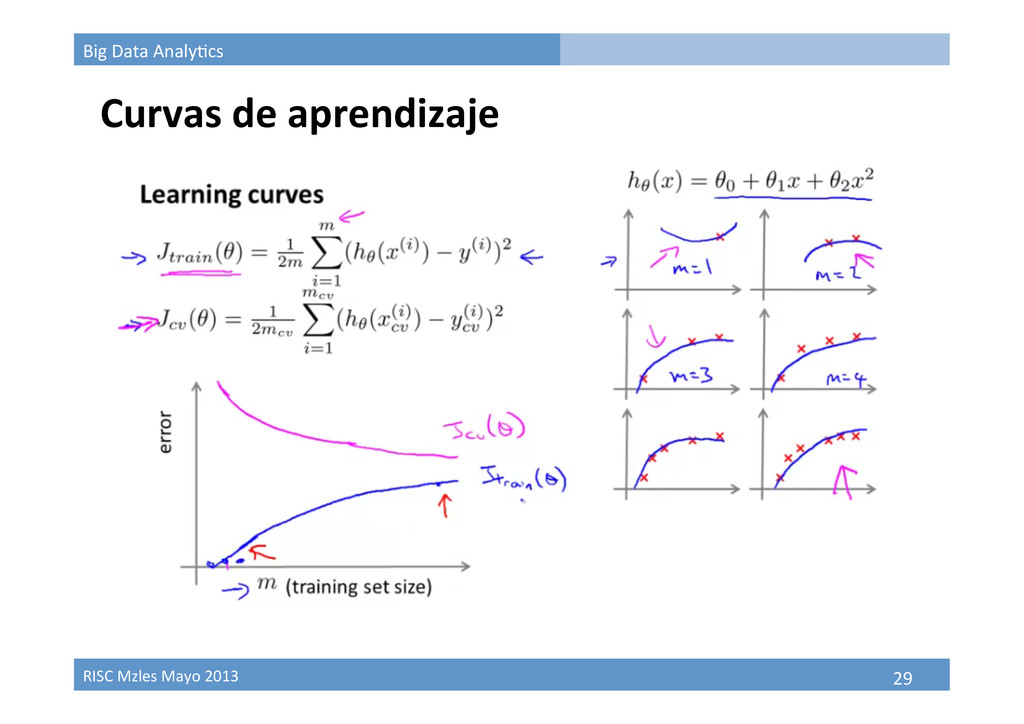
Resampling (remuestreo) Técnicas de resampling • K-‐fold cross valida9on Good for model selec9on Less bias more variance • Bootstrapping When the theore9cal distribu9on of a sta9s9c of interest is complicated or unknown. The bootstrapping procedure is distribu9on-‐independent When the sample size is insufficient for straighxorward sta9s9cal inference. When power calcula9ons have to be performed, and a small pilot sample is available.
[email protected] Universidad Nacional de Colombia, Grupo de InvesBgación MindLab www.unal.edu.co hfps://sites.google.com/a/unal.edu.co/mindlab/ www.3igs.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}