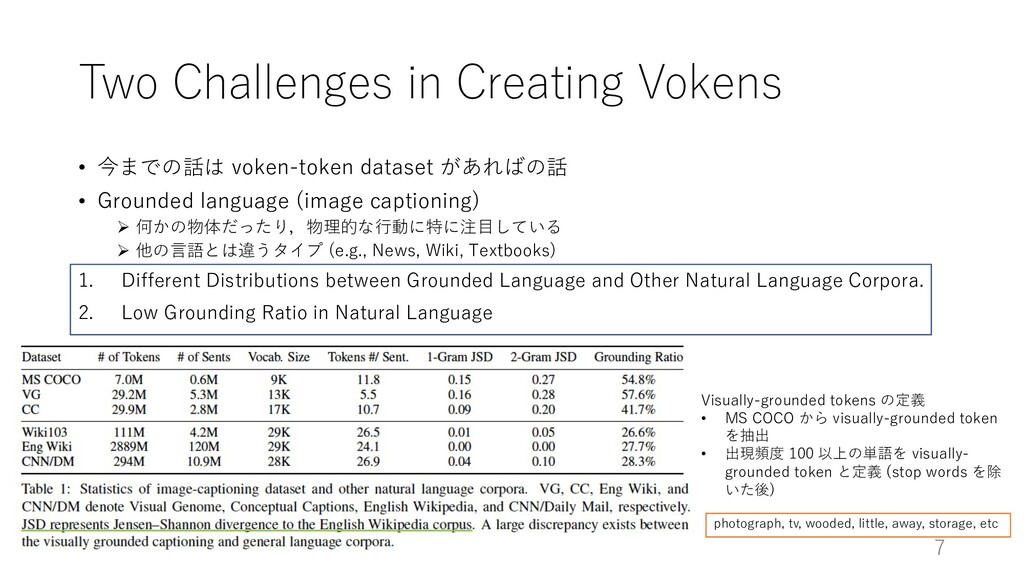
は未だ存在しない • Token-voken dataset を作る際の⼆つの課題点 1. Visually-grounded language とその他のタイプの⾔語のデータセット間の違い n visually-grounded language→⽐較的,簡潔で有益な情報が欲しい; データ数⼩さい n トークン数,⽂⻑,能動態 2. ほとんどの単語が視覚的に表現可能でない (not visually-grounded) n Concrete nouns (dog, cat, horse) → visually-grounded n “up”, “by”, “into” → 抽象的,not visually-grounded n English Wikipedia で約 28 % の単語が visually-grounded n Grounding ratio の低さ 3
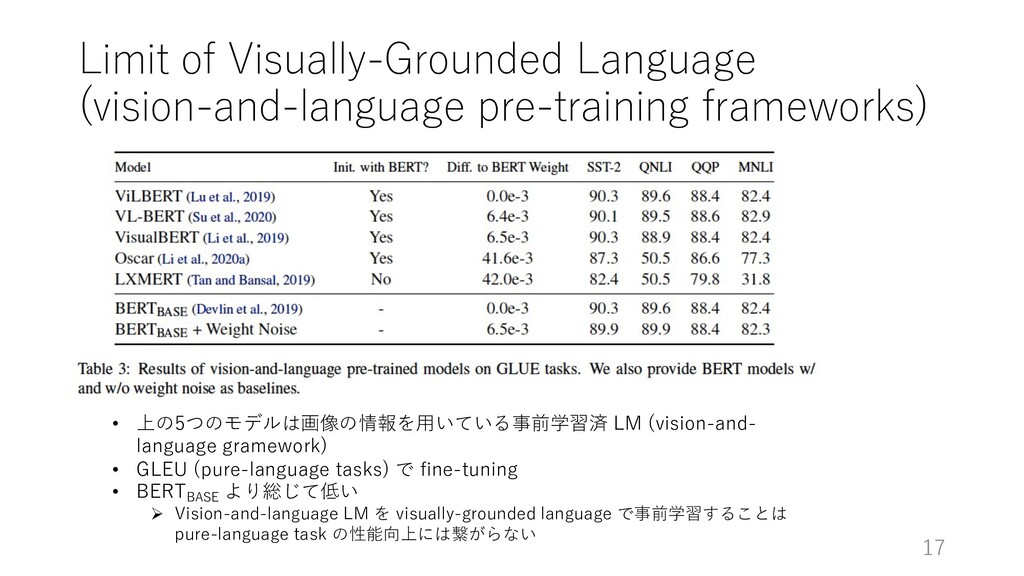
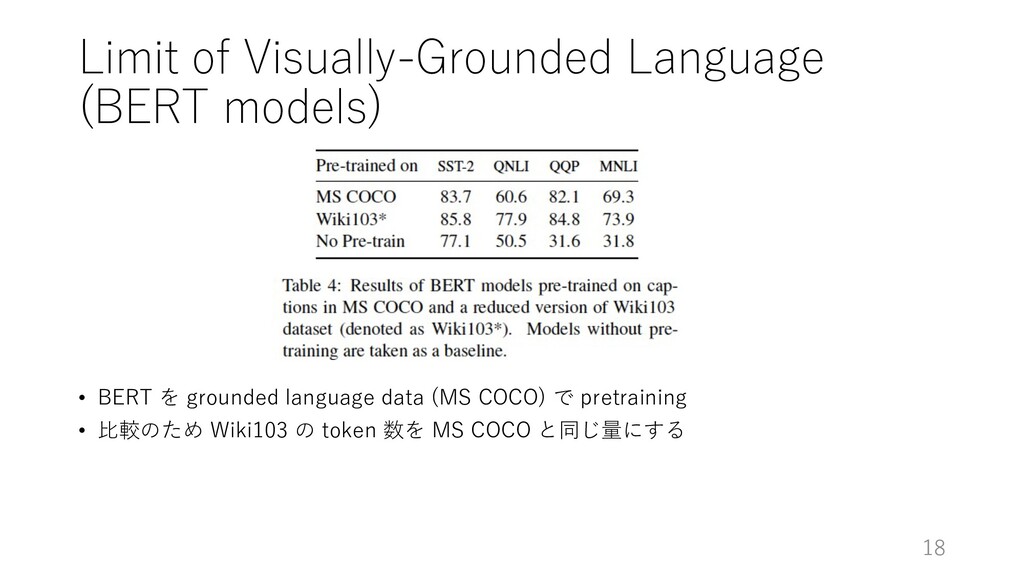
Ø Using the fixed sequence length of 128 Ø BERTBASE model: 12 layers, 768 hidden dimensions, training on English Wikipedia (200K steps) Ø Reduced BERT model: 6 layers, training on Wiki103 (160K steps) n フルの English Wikipedia dataset には適合しなかった Ø batch size: 256, learning rate: 2e-4, λ: 1.0 (visual と textual LM のロスの割合を調整するパラメータ) • Fine-tuning Ø dev での結果を報告 Ø batch size: 32, learning rate: 1e-4, training (3 epochs) 15
• 曖昧性解消 (e.g., “down” in example 2) u Token の意味を捉えていない voken もある (e.g., “writing” in example 1) u アライメントがシフトしている (e.g., “my love” というフレーズでの意味が “love” の代わりに “my” にアライメントされている in example 2) Ø Token-image のデータセットが確⽴されていないせいか?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}