Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Multi-task Learning for Multilingual Neural Mac...
Search
Hiroto Tamura
July 06, 2021
Research
64
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Multi-task Learning for Multilingual Neural Machine Translation
2021/06/24 論文紹介
EMNLP2020 (
https://aclanthology.org/2020.emnlp-main.75/
)
Hiroto Tamura
July 06, 2021
More Decks by Hiroto Tamura
See All by Hiroto Tamura
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
jinlafan
0
140
Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
jinlafan
0
96
Bilingual Subword Segmentation for Neural Machine Translation
jinlafan
0
130
TMU Japanese-English Multimodal Machine Translation System for WAT 2020
jinlafan
0
140
Other Decks in Research
See All in Research
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
350
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
420
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
480
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
Harness Engineering and Al Agent
kzinmr
3
1.8k
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
570
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
100
Featured
See All Featured
Odyssey Design
rkendrick25
PRO
2
730
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Making Projects Easy
brettharned
120
6.7k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Building Adaptive Systems
keathley
44
3.1k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Building an army of robots
kneath
306
46k
Accessibility Awareness
sabderemane
1
160
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Rails Girls Zürich Keynote
gr2m
96
14k
Transcript
EMNLP 2020 ⽥村弘⼈, 6/21 1
Introduction 現在の multilingual MT は複数⾔語対の対訳データで訓練 • 単⾔語データの multilingual MT への活⽤はあまり研究されていない
• 逆翻訳するには多くの⾔語対で訓練必要→multilingual MT では⼤変 ⾃⼰教師有りの事前学習⼿法 • Catastrophic forgetting • Pre-training + fine-tuning の2段階 • 新しい⾔語や単⾔語データを⼊れる際の柔軟性が低い (from scratch) 提案⼿法 • Multilingual MT において単⾔語データを活⽤する新たなマルチタスク学習法 (MTL) を提案 • masked language modeling (MLM) + denoising auto-encoding (DAE) + MT • 新たなスケジューリング⼿法 (データとノイズ) を提案 • dynamic temperature-based sampling, dynamic noising ratio • High-resource, low-resource どちらでも性能向上 • NLU タスクに転移学習しても SOTA モデル (XLM-Roberta) 以上の性能 2
Multi-task learning • Task 1: Machine Translation (MT) • 対訳データで訓練
• Task 2: Masked Language Modeling (MLM) • Encoder の表現を⾼めるため (特に low-resource) • ソース側の単⾔語データで訓練 • Encoder の後ろに線形レイヤを追加 • 𝑅! % (たぶん 15%)のユニット (word or subword) をマスク • Task 3: Denoising Auto-encoding (DAE) • ターゲット側の単⾔語データで訓練 3 Text Infilling 各スパンを blanking token で置き換える • スパンの⻑さはポアソン分布 (𝜆 = 3.5) から抽出 • ⽂⻑の 𝑅! % (たぶん 35%) のトークンをマスク Word Drop & Blank 各トークンをランダムに削除 or blanking tokenで置換 Word Swapping 3 position 以内で各トークンをシャッフル 80 %: [MASK] に置換 10 %: ランダムな token に置換 10 %: そのまま MT と DAE にはターゲット⾔語を⽰す⾔語タグ [LID] を ⽂の末尾に追加 • Joint Training 最終的なロス 𝐶(*): stochastic noising function
Task Scheduling: Sampling • Temperature-based Sampling [Arivazhagan et al., 2019]
• データセットが⾔語によって不均衡→low-resource の性能に悪影響 • それぞれの⽂ペアを ,! ∑" ," # $ の確率に従ってサンプリング. • Low-resource では性能向上.high-resource な⾔語では性能の低下. Ø High-resource なデータで⼗分に訓練される前に収束している? [Bapna and Firat, 2019] • Dynamic Data Sampling • 最初は high-resource,徐々に low-resource な⾔語をサンプリング 4 𝑙: ⾔語ペア 𝐷" : 𝑙 の対訳コーパス 𝑇: サンプリング温度 (ハイパラ) 𝑘: 現在のエポック数 𝑇# : 初期サンプリング温度 (𝑇# = 1) 𝑇$ : 最⼤サンプリング温度 (𝑇$ = 5) 𝑁: warm-up エポック数 (𝑁 = 5) 1. warm-up ステップ中は線形に温度を増加 (徐々に low-resource な⾔語をサンプリング) 2. warm-up ステップ後は 𝑇% で⼀定 (⼀定の分布でサンプリング) [Arivazhagan et al., 2019]
Task Scheduling: Noising • Dynamic Noising Ratio • 簡単なタスクから始め,徐々に難しいタスクをこなす •
サチュレーションを避け,訓練をし続けるように促す 5 𝑅# : ノイズ率の下限 𝑅$ : ノイズ率の上限 𝑀: warm-up エポック数 ノイズ率 𝑅: {𝑅& , 𝑅' } • 𝑅& : MLM における masking ratio • 𝑅' : DAE における text infilling タスクの blanking ratio 1. warm-up ステップ中は線形にノイズ率を増加 (徐々にタスクを難しくする) 2. warm-up ステップ後は 𝑅% で⼀定 (⼀定のノイズ率)
Experimental Setup • Data • ⾔語:En, Fr, Cs, De, Fi,
Lv, Et, Ro, Hi, Tr, Gu • 対訳データ: WMT • 単⾔語データ:NewsCrawl (+ CCNet) 5M • Back-translation • target-to-source の bilingual model を訓練 • 逆翻訳する単⾔語データは MTL で使うものと⼀緒 • Model • Transformer (big) • Transformer (3 enc/dec layers, 256 emb/hid dims) : low-resource な⾔語対 (Tr, Hi, Gu) の Bilingual models • m2o (X→En), o2m (En→X), m2m (X→X) 6
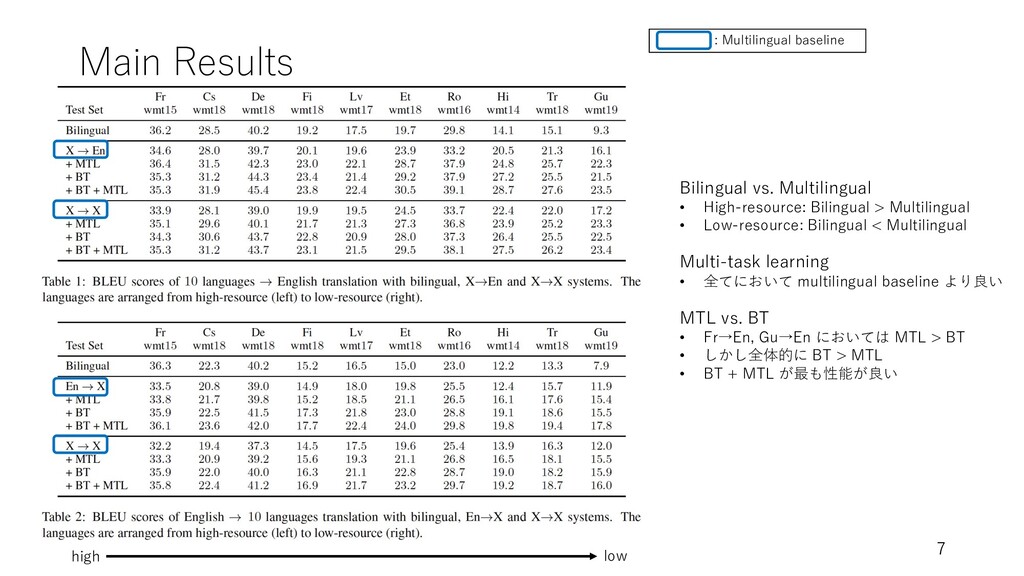
Main Results 7 Bilingual vs. Multilingual • High-resource: Bilingual >
Multilingual • Low-resource: Bilingual < Multilingual Multi-task learning • 全てにおいて multilingual baseline より良い MTL vs. BT • Fr→En, Gu→En においては MTL > BT • しかし全体的に BT > MTL • BT + MTL が最も性能が良い : Multilingual baseline high low
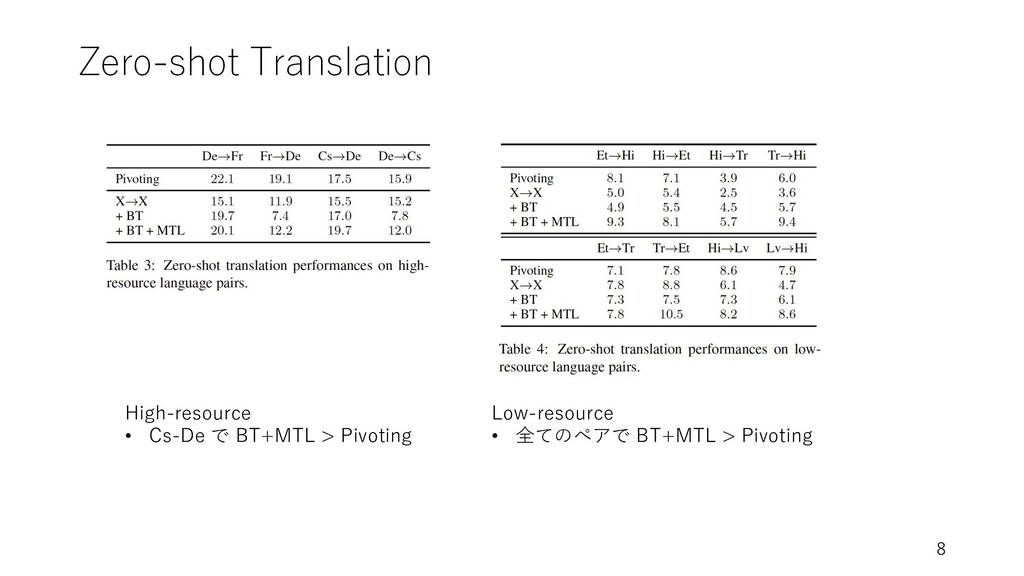
Zero-shot Translation 8 High-resource • Cs-De で BT+MTL > Pivoting
Low-resource • 全てのペアで BT+MTL > Pivoting
MTL vs. Pre-training • MTL と mBART[Liu et al., 2020]
を⽐較 • CC25 で事前訓練済みの mBART(公式のやつ)をMTL と同じ対訳データで fine-tuning 9 全ての⾔語ペアで MTL > mBART • NMT においては self-supervised+MT タスクを joint で 学習する⽅が pre-training+fine-tuning よりも良い 効率的 • mBART は事前学習に En: 55B, Fr: 10B tokens • MTL は En: 100M, Fr: 100M tokens
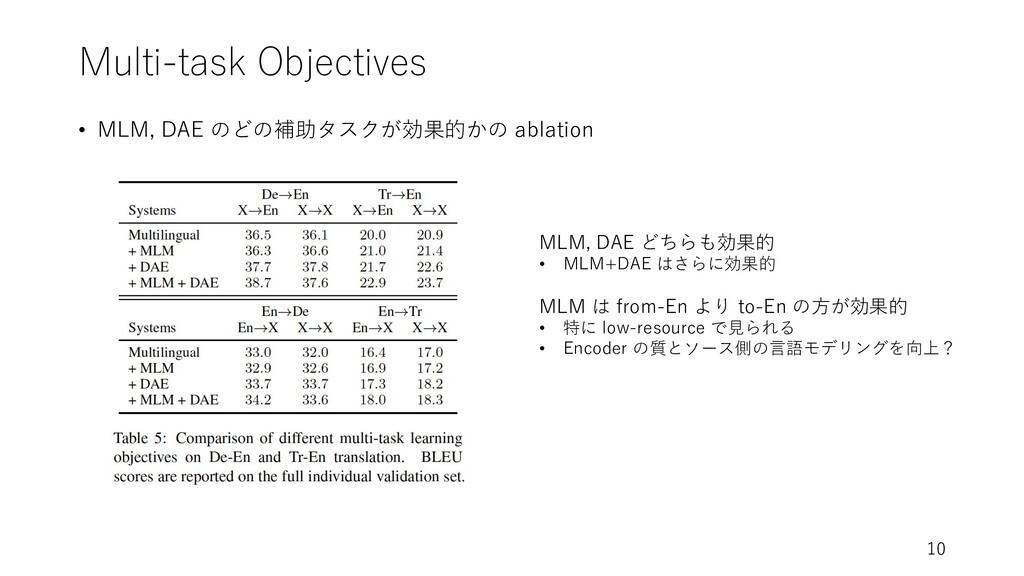
Multi-task Objectives • MLM, DAE のどの補助タスクが効果的かの ablation 10 MLM, DAE
どちらも効果的 • MLM+DAE はさらに効果的 MLM は from-En より to-En の⽅が効果的 • 特に low-resource で⾒られる • Encoder の質とソース側の⾔語モデリングを向上?
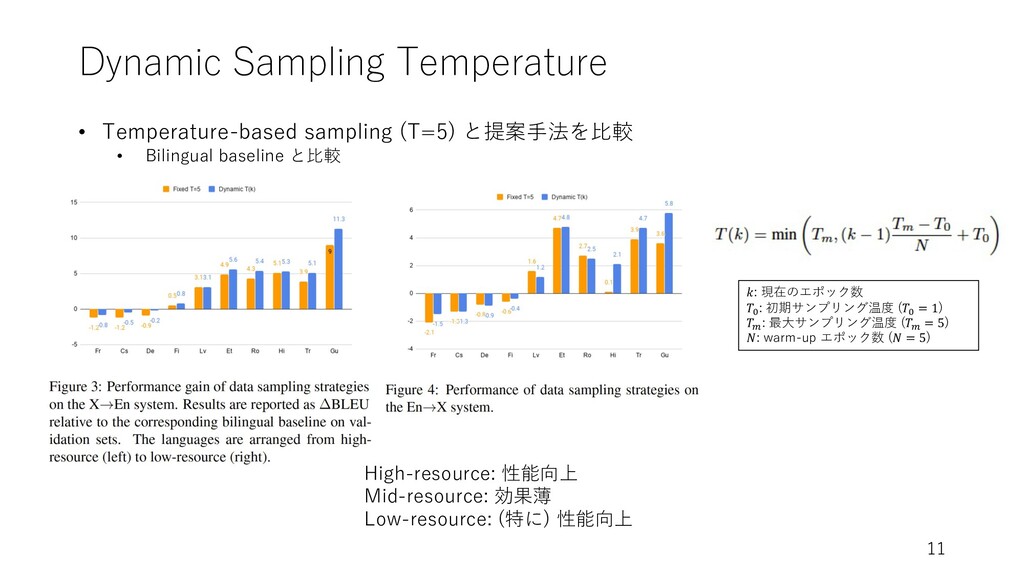
Dynamic Sampling Temperature 11 𝑘: 現在のエポック数 𝑇# : 初期サンプリング温度 (𝑇#
= 1) 𝑇$ : 最⼤サンプリング温度 (𝑇$ = 5) 𝑁: warm-up エポック数 (𝑁 = 5) High-resource: 性能向上 Mid-resource: 効果薄 Low-resource: (特に) 性能向上 • Temperature-based sampling (T=5) と提案⼿法を⽐較 • Bilingual baseline と⽐較
Noising Scheme • MLM (token-level or word-level ?) と DAE
(span-level or word-level ?) のノイズの違い を⽐較 • Multilingual baseline と⽐較 12 MLM • word-level > token-level DAE • span-level > word-level
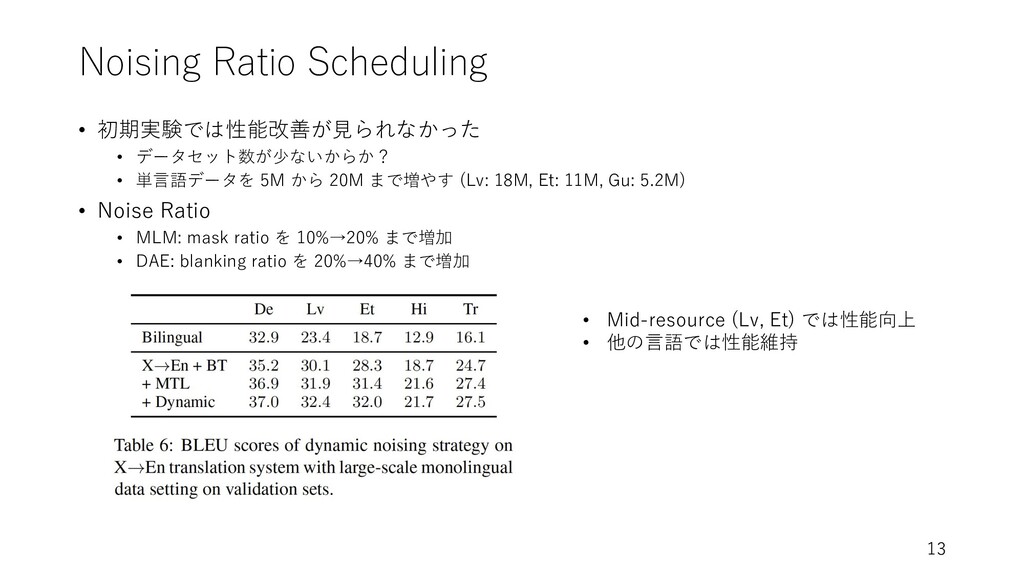
Noising Ratio Scheduling • 初期実験では性能改善が⾒られなかった • データセット数が少ないからか? • 単⾔語データを 5M
から 20M まで増やす (Lv: 18M, Et: 11M, Gu: 5.2M) • Noise Ratio • MLM: mask ratio を 10%→20% まで増加 • DAE: blanking ratio を 20%→40% まで増加 13 • Mid-resource (Lv, Et) では性能向上 • 他の⾔語では性能維持
MTL for Cross-lingual Transfer Learning for NLU • NLU の下流タスクにおいて
Massive multlingual MT < XLM-Roberta [Siddhant et al., 2020] • Multilingual MT: NMT タスクで訓練 (parallel) • XLM-Roberta: MLM タスクで訓練 (monolingual) • MTL は MT+MLM+DAE で訓練しているのでこの差を埋めれるかも? • 対訳データ: in-house (30M / language) • 単⾔語データ: CC-Net (40M / language) • 訓練後,encoder を取り出して feedforward layer をつけて下流タスクで fine-tuning 14 MLM MT MT+MLM+DAE Encoder layers: 12 Decoder layers: 6 Hidden dims: 768
Conclusion • joint で学習するMTL (MT+MLM+DAE) フレームワークを提案 • low-resource, high-resource でも性能向上
• データのサンプリングとノイズの強度に対してのスケジューリング⼿法を提案 • 特に sampling scheduling が効果的 • NMT においては MTL > pre-training+fine-tuning であることを⽰した • NLU タスクにおいても効果を⽰した 15
{kind=link}
{kind=link}
{kind=link}
![Task Scheduling: Sampling • Temperature-based Sampling [Arivazhagan et al., 2019]](https://files.speakerdeck.com/presentations/c0439f068dc14345be967c58f759f4e0/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MTL vs. Pre-training • MTL と mBART[Liu et al., 2020]](https://files.speakerdeck.com/presentations/c0439f068dc14345be967c58f759f4e0/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}