its nature, low-resource n Require texts and their associated images n Small size of dataset causes low translation performance • Our proposals ØData Augmentation n With several data augmentation methods for both texts and images n Without external data ØDropnet n To effectively utilize the features of both texts and images n Regularization of the network training 4/12/2020 WAT 2020 1
ØAttentive encoder-decoder model n Encoder: Bidirectional GRU [Cho et al., 2014] n Decoder: Conditional GRU [Firat and Cho, 2016] • MMT w/ decoder initialization (MMTdecinit ) [Caglayan et al., 2017] ØInitialize the hidden state of the decoder of our NMT model with visual features ØThis architecture is also used for MMT models using augmented data • MMT w/ double attention (MMTdatt ) ØWe adopt hierarchical combination [Libovický and Helcl, 2017] 1. Calculate textual and visual context vectors from each encoder 2. Combine each context vector in another attention layer to obtain multimodal context vector 4/12/2020 WAT 2020 3
fully utilize two different types of features ØBy probabilistically dropping either the feature when combining features n This leads to regularization of the network training • We incorporate this method into MMTdatt model ØDrop either the textual or the visual context vector while training 4/12/2020 WAT 2020 4 At each decoding step during training, • With probability 𝑝!"# /2, Ø Either the textual or the visual context vector is selected to compute the multimodal context vector • With probability 1 − 𝑝!"# , Ø Both context vectors are used for computing the multimodal context vector Textual context vector Visual context vector Multimodal context vector Visual context vector Multimodal context vector 𝑝!"# /2 : or 1 − 𝑝!"# : or Multimodal context vector Textual context vector 𝑝!"# /2 : dropnet rate: 𝑝!"# ∈ 0, 1
ØSample the hypothesis from output distribution at each decoding step • Random noising [Xie et al., 2018] ØPenalize every hypothesis on the beam by adding noise 𝑟𝛽 to its hypothesisʼ score ØIf 𝛽 is sufficiently large, this method is similar to the method that randomly shuffles the ranks of the hypotheses according to their scores 4/12/2020 WAT 2020 6 Where 𝑟 is drawn from the uniform distribution on the interval 0, 1 , 𝛽 controls the noise intensity original a man with shorts and a hat is holding onto a little boy and a dog . 𝛽 = 5 a tree man with shorts and a hat is holding onto a little boy and a dog . 𝛽 = 10 a man with shorts and a hat is holding onto a little boy and a dog pulling it . 𝛽 = 20 bald man with shorts and boat hat warning a little child and with a boy . 36 dogs .
al., 2017] model on the original training texts to augment training texts ØGenerate noisy training sentences (both English and Japanese) with the trained Transformer model Ø𝛽 values of random noising method are 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15 and 20 we used • Combine the noisy texts generated by different textual data augmentation methods for pretraining ØIf we combine each generated texts with the random noising method with 𝛽 = 1 and 𝛽 = 2 respectively, the mixed data comprise 119,124 sentences. 4/12/2020 WAT 2020 7
patch (256×256 size) of each image • Random cropping ØRandomly select a patch (256×256 size) of each image and crop it • Rotation ØRotate each image right or left on axis between −20° and 20° randomly 4/12/2020 WAT 2020 8 original center cropping random cropping rotation
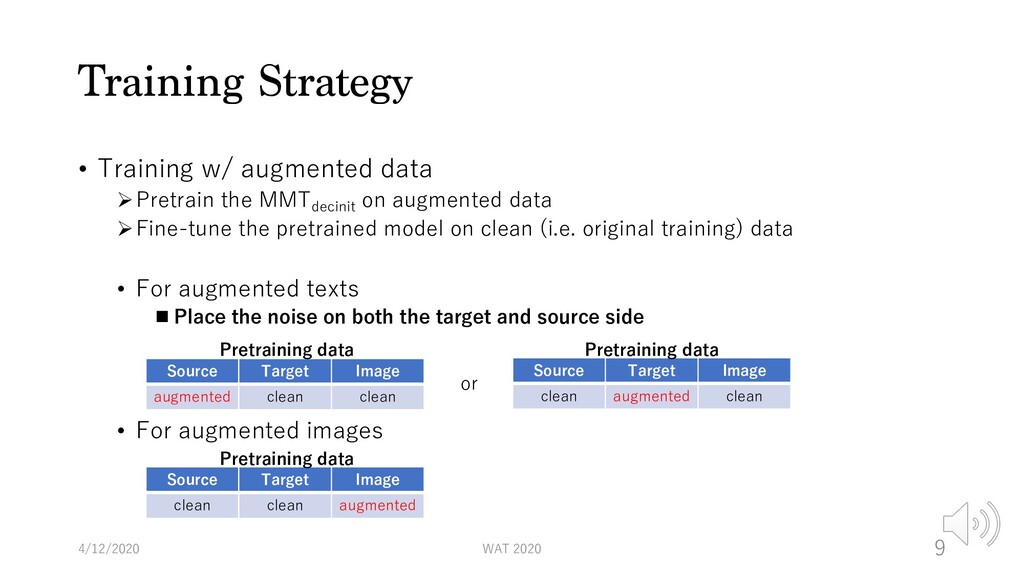
on augmented data ØFine-tune the pretrained model on clean (i.e. original training) data • For augmented texts n Place the noise on both the target and source side • For augmented images 4/12/2020 WAT 2020 9 Source Target Image clean clean augmented Pretraining data Source Target Image augmented clean clean Pretraining data or Source Target Image clean augmented clean Pretraining data
Flickr30k Entities and Flickr30k Entities Japanese dataset n Test: Provided by organizer ØImages: Flickr30k dataset • Preprocessing ØEnglish sentences n Lowercase, normalize, and tokenize with Moses scripts ØJapanese sentences n Tokenize using MeCab with IPA dictionary ØVocabulary n We use word-level vocabularies n English: 9,546 items, Japanese: 11,235 items 4/12/2020 WAT 2020 11
Øthe model X is pretrained on the augmented texts generated by random noising method with 𝛽 = 5; the augmented texts are on the source side. 2. “X w/ mix (sampling, 𝛽 = 4; target)” Øthe model X is pretrained on the augmented texts mixed up with two types of noisy texts (generated by sampling and random noising with 𝛽 = 4 methods); the augmented texts are on the target side. 4/12/2020 WAT 2020 14 Source Target Image random noising with 𝛽 = 5 clean clean Source Target Image clean sampling + random noising with 𝛽 = 4 clean 1. random noising (𝛽 = 5; source) 2. mix (sampling, 𝛽 = 4; target) pretraining data pretraining data
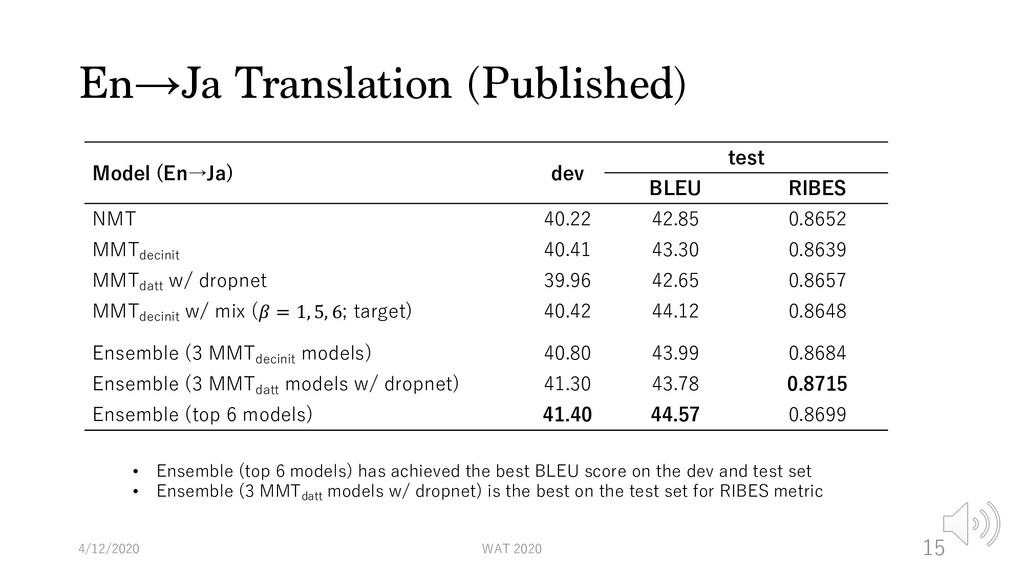
40.22 42.85 0.8652 MMTdecinit 40.41 43.30 0.8639 MMTdatt w/ dropnet 39.96 42.65 0.8657 MMTdecinit w/ mix (𝛽 = 1, 5, 6; target) 40.42 44.12 0.8648 Ensemble (3 MMTdecinit models) 40.80 43.99 0.8684 Ensemble (3 MMTdatt models w/ dropnet) 41.30 43.78 0.8715 Ensemble (top 6 models) 41.40 44.57 0.8699 4/12/2020 WAT 2020 15 • Ensemble (top 6 models) has achieved the best BLEU score on the dev and test set • Ensemble (3 MMTdatt models w/ dropnet) is the best on the test set for RIBES metric
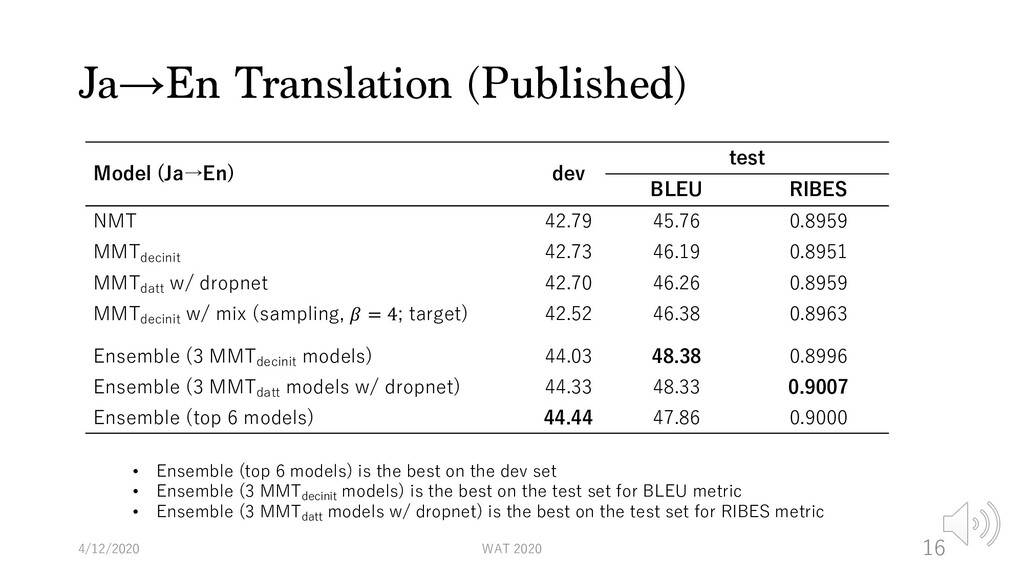
test BLEU RIBES NMT 42.79 45.76 0.8959 MMTdecinit 42.73 46.19 0.8951 MMTdatt w/ dropnet 42.70 46.26 0.8959 MMTdecinit w/ mix (sampling, 𝛽 = 4; target) 42.52 46.38 0.8963 Ensemble (3 MMTdecinit models) 44.03 48.38 0.8996 Ensemble (3 MMTdatt models w/ dropnet) 44.33 48.33 0.9007 Ensemble (top 6 models) 44.44 47.86 0.9000 • Ensemble (top 6 models) is the best on the dev set • Ensemble (3 MMTdecinit models) is the best on the test set for BLEU metric • Ensemble (3 MMTdatt models w/ dropnet) is the best on the test set for RIBES metric
BLEU RIBES MMTdatt w/o dropnet 39.89 0.8193 42.16 0.8726 MMTdatt w/ dropnet 40.39 0.8206 42.72 0.8730 • Calculate the average score of three models on the dev set; each model has a different seed ü Models with dropnet are better than those without dropnet Ø Incorporating the dropnet method into MMTdatt model can help improve the translation performance
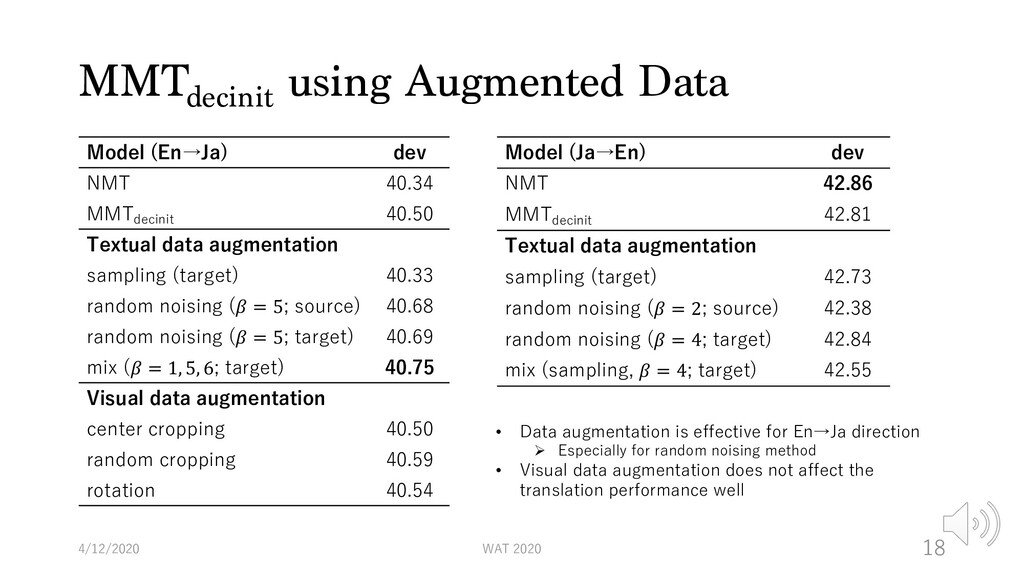
40.50 Textual data augmentation sampling (target) 40.33 random noising (𝛽 = 5; source) 40.68 random noising (𝛽 = 5; target) 40.69 mix (𝛽 = 1, 5, 6; target) 40.75 Visual data augmentation center cropping 40.50 random cropping 40.59 rotation 40.54 4/12/2020 WAT 2020 18 Model (Ja→En) dev NMT 42.86 MMTdecinit 42.81 Textual data augmentation sampling (target) 42.73 random noising (𝛽 = 2; source) 42.38 random noising (𝛽 = 4; target) 42.84 mix (sampling, 𝛽 = 4; target) 42.55 • Data augmentation is effective for En→Ja direction Ø Especially for random noising method • Visual data augmentation does not affect the translation performance well
En→Ja Ja→En source 40.21 42.01 target 40.59 42.50 • Pretrain the models on the noisy data generated by random noising method with 13 different 𝛽 values (i.e., 𝛽 = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20) • Fine-tune these models on clean data • Calculate the average of these 13 modelsʼ scores on the dev set ü Placing noise on the target side is better than on the source side Ø This is useful under low-resource or MMT situations ?
man with blue sleeveless shirt and sunglasses paints a face while on his knees . NMT ⻘い袖なしのシャツを着てサングラスをかけた男性が, 膝の上に顔を塗っている。 (on his knees) MMTdecinit ⻘い袖なしシャツとサングラスを⾝につけた男性は、 膝の上に顔を描いている。 (on his knees) MMTdatt w/ dropnet ⻘い袖なしのシャツを着てサングラスをかけた男性が 膝の上に顔を描いている。 (on his knees) Ensemble (3 MMTdecinit models) ⻘い袖なしのシャツを着てサングラスをかけた男性が、 膝の上に顔を塗っている。 (on his knees) Ensemble (top 6 models) ⻘い袖なしのシャツを着てサングラスをかけた男性が、 膝をついて顔を描いている。 (while kneeling) Reference ⻘い袖無しシャツにサングラスの男性が、 ひざまづいて顔を描いている。 (while kneeling)
older man in a orange wrap looks into the camera on the sidewalk of a city . NMT オレンジ⾊の布を着た年配の男性が街の歩道でカメラを (wrap) 覗き込んでいる。 MMTdecinit オレンジ⾊の布を⾝につけた年配の男性が街の歩道でカ (wrap) メラを覗き込んでいる。 MMTdatt w/ dropnet オレンジ⾊のラップトップを着た年配の男性が、街の歩 (laptop) 道でカメラを覗き込んでいる。 Ensemble (3 MMTdecinit models) オレンジ⾊のラップトップを着た年配の男性が、街の歩 (laptop) 道でカメラを覗き込んでいる。 Ensemble (top 6 models) オレンジ⾊のラップトップを着た年配の男性が、街の歩 (laptop) 道でカメラを覗き込んでいる。 Reference オレンジ⾊の布をまとった年配の男性が街の歩道でカメ (wrap) ラの中を⾒る。
performance ØData augmentation is useful for the En→Ja direction ØThe random noising method positively affects translation performance ØPlacing noise on the target side is more effective than on the source side • Future work: ØInvestigate why placing noise on the target side is effective ØStudy how the dropnet method works in MMTdatt models 4/12/2020 WAT 2020 22
{kind=link}
{kind=link}
{kind=link}
![NMT and MMT Models • NMT [Caglayan et al., 2017]](https://files.speakerdeck.com/presentations/c6922ec2f41249a3a526f172ee6cc2fd/slide_3.jpg){kind=link}
![Dropnet Method • Dropnet [Zhu et al., 2020] ØProposed to](https://files.speakerdeck.com/presentations/c6922ec2f41249a3a526f172ee6cc2fd/slide_4.jpg){kind=link}
{kind=link}
![Textual Data Augmentation Methods • Sampling [Edunov et al., 2018]](https://files.speakerdeck.com/presentations/c6922ec2f41249a3a526f172ee6cc2fd/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}