Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
E2E-VLP: End-to-End Vision-Language Pre-trainin...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Hiroto Tamura
October 08, 2021
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
2020/10/08 論文紹介
ACL2021 (
https://aclanthology.org/2021.acl-long.42/
)
Hiroto Tamura
October 08, 2021
More Decks by Hiroto Tamura
See All by Hiroto Tamura
Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
jinlafan
0
96
Bilingual Subword Segmentation for Neural Machine Translation
jinlafan
0
130
Multi-task Learning for Multilingual Neural Machine Translation
jinlafan
0
64
TMU Japanese-English Multimodal Machine Translation System for WAT 2020
jinlafan
0
140
Other Decks in Research
See All in Research
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
130
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
羽田新ルート運用6年の検証
1manken
0
180
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
230
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
240
260624_NLP-colloquium: Hubness
de9uch1
0
110
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
270
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
Claude Code × autoresearch 実践
mathbullet
0
210
Language and AI
ayaniwa
0
180
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.6k
Featured
See All Featured
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
The Curious Case for Waylosing
cassininazir
1
440
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
RailsConf 2023
tenderlove
30
1.5k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
380
The Spectacular Lies of Maps
axbom
PRO
1
870
Thoughts on Productivity
jonyablonski
76
5.3k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Transcript
ACL2021, M1 ⽥村弘⼈
Abstract • 多くの Vision and language pre-training (VLP) モデルは学習済の regional
features を⽤いている • 物体検出モデルは cross modal に最適化されてない • 2-step の訓練を必要とする (特徴量抽出 è VLP) • Pixel-BERT[Huang et al., 2020] • Spatial feature を使った end-to-end の VLP モデル (encoder-only) • Regional feature を使わないので抽出する⼿間が省け,レイテンシが効率的 • しかし,オブジェクト単位の情報を得ることができないのでモダリティ間のアライ メントをとることが難しい • E2E-VLP (提案⼿法) • Encoder は従来の分類タスク (MLM, ITM) を⾏う • Decoder の追加により⽣成タスクができる 1. Object detection (DETR[Carion et al., 2020]): cross-modal な物体検出ができる 2. Image captioning: 画像内の意味をよく理解するため • より洗練された cross-modal な表現を獲得できる 1
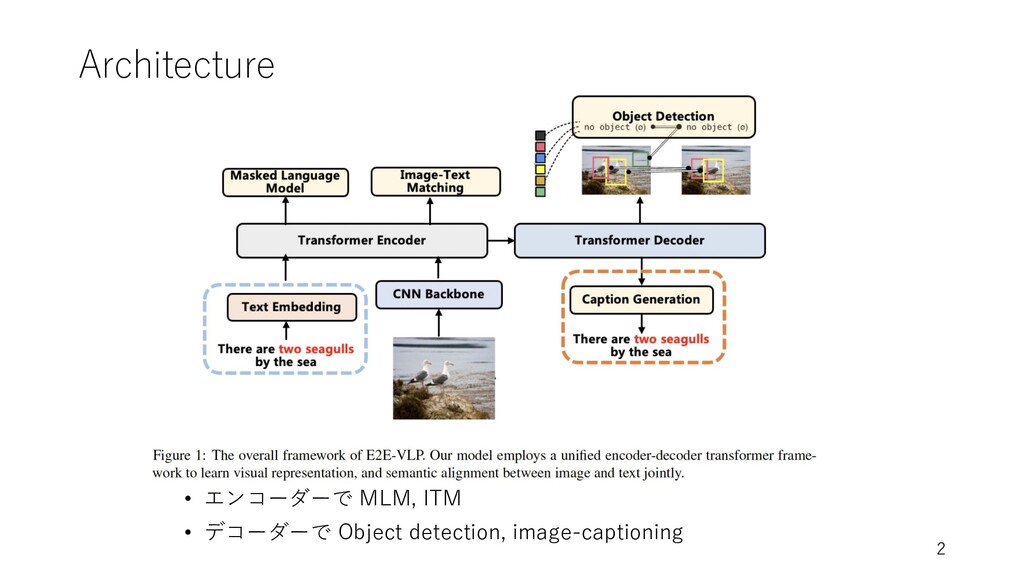
Architecture • エンコーダーで MLM, ITM • デコーダーで Object detection, image-captioning
2
Input representation • Sentence embeddings • サブワード列 {𝑤!, … ,
𝑤"}を⽤いて,embeddings 𝐸#"$ = {𝑒%&', 𝑒!, … , 𝑒", 𝑒'()}を得る • Image representation • 画像 𝑣*"+ ∈ ℝ,×.!×/!から CNN を通して spatial feature 𝑓*"+ ∈ ℝ%×.×/(𝐶 = 2048, 𝐻 = "! #$ , 𝑊 = %! #$ ) を得る. • それに 1×1 の畳み込みをしてチャンネル数を減らし,系列にするため次元を縮⼩し て,最終的な画像表現 𝑍*"+ = {𝑜!, … , 𝑜./} ∈ ℝ./×0を得る. • Encoder への⼊⼒はテキストと画像表現を結合したの {𝑒!"#, 𝑒$, … , 𝑒%, 𝑒#&', 𝑜$, … , 𝑜()} を⽤いる (single-stream) • テキストだけでなく,画像のサイズによって系列⻑が変わる 3
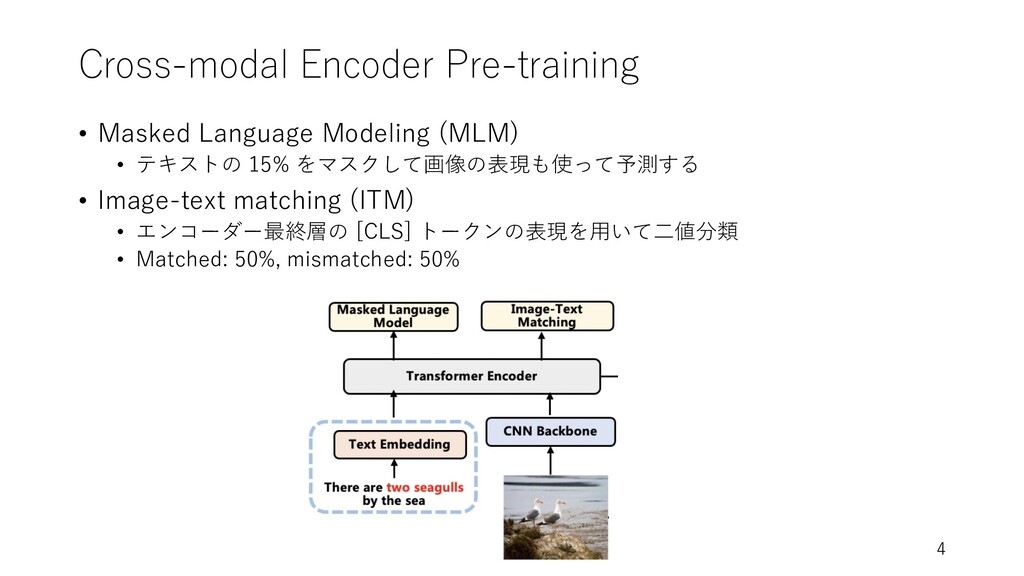
Cross-modal Encoder Pre-training • Masked Language Modeling (MLM) • テキストの
15% をマスクして画像の表現も使って予測する • Image-text matching (ITM) • エンコーダー最終層の [CLS] トークンの表現を⽤いて⼆値分類 • Matched: 50%, mismatched: 50% 4
Visual-enhanced Decoder • Object detection • DETR[Carion et al., 2020]
に倣い,object detection を⼆部マッチングで解く • 以下のロスを最⼩化する N 個の要素の順列 𝜎 を⾒つける (ハンガリアン法で効率化) • 得られた順列 9 𝜎 を⽤いてattribute, class prediction, box regression をする • Image-captioning • (エンコーダーからの)画像表現 𝑥 を⽤いる • Joint で訓練 5 ! 𝑦 = {! 𝑦! }!"# $ : true objects ℒ%&'() (𝑦! , ! 𝑦*(!) ): 正解と予測とのロス
DEtection TRansformer (DETR) [Carion et al., 2020] • N 個のオブジェクトを
single-pass で並列に予測する • 正解データの集合を予測する • ⼆部マッチングで予測と正解の割り当てをする (ハンガリアン法で効率化) • 得られた最適な割り当て 9 𝜎 を⽤いてロスを計算 6 デコーダーの各表現からクラスとボックスを FFN で予測 デコーダーの⼊⼒は N 個の学習される object queries
Experiments • Pre-training dataset • MSCOCO, Visual Genome: 6.01M image-text
pair • Hyper parameters • Encoder-decoder layer: 12-6 • dmodel : 256, heads: 12, dff : 1024 • Visual backbone • 学習済 ResNet152 を⽤いる • ResNet も学習する • Downstream tasks • VQA2.0, NLVR2, Image caption, Image-text retrieval 7
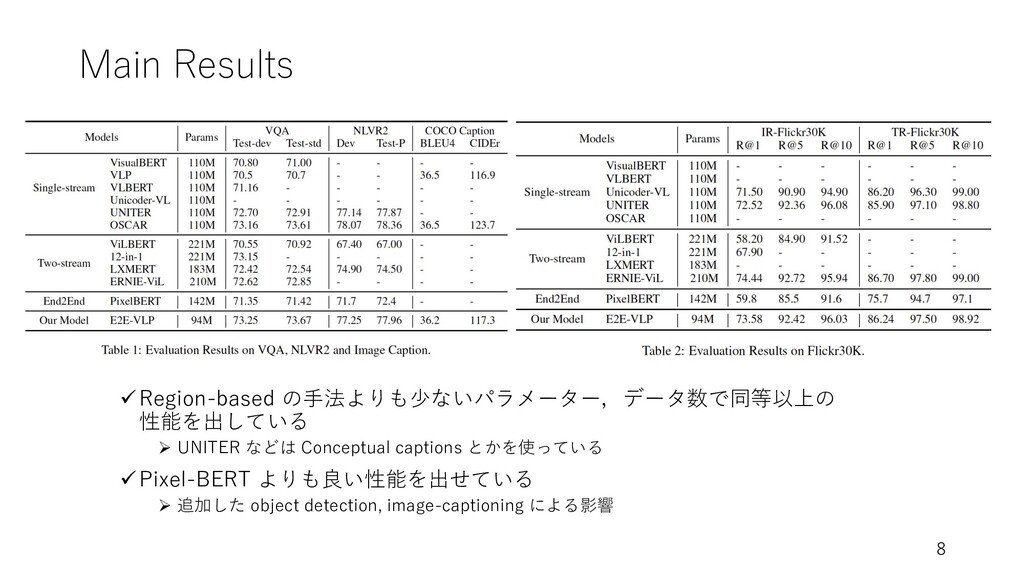
Main Results üRegion-based の⼿法よりも少ないパラメーター,データ数で同等以上の 性能を出している Ø UNITER などは Conceptual captions
とかを使っている üPixel-BERT よりも良い性能を出せている Ø 追加した object detection, image-captioning による影響 8
Importance of Visual Learning • Object detection (attribute prediction) と
image-captioning に対する Ablation 9 ü 全てのタスクが性能に貢献する Ø 先⾏研究 (2-step の regional feature を使う⼿法) と⼀致.Cross-modal タスクには重要 ü Image-captioning が他と⽐べるとあまり性能に貢献していない Ø VQA と NLVR2 はより洗練されたオブジェクトの表現を求めるから
Inference Efficiency • 1クエリに対する推論時間の平均を⽐較 10 ü 2-step のモデルより推論時間が⼩さい Ø 2-step
のモデルは全推論時間の 80 % が regional feature の抽出に使われ ている Ø 性能は上回っている ü Pixel-BERT と⽐べ,パラメーター数・推論時間ともに少ない Ø E2E-VLP のモデルの次元が⼩さい (256)
Architecture Selection • Encoder (Transformer) と ResNet のレイヤ数を変化させる 11 ü
レイヤ数を⼤きくするほど性能向上 n ⾼品質の画像の抽出器を使うと性能が上がる è 先⾏研究と⼀致
Impact of Input Image Size • 画像サイズにより系列⻑が変わる {𝑒%&', 𝑒!, …
, 𝑒", 𝑒'(), 𝑜!, … , 𝑜./} • 性能と推論時間への影響は? 12 ü 画像サイズが⼤きいと推論時間は遅くなり性能向上 n 画像に関する情報をより埋め込めるため ü 画像サイズが⼩さいと推論時間は早くなり性能減少 ü 画像サイズによる性能とレイテンシのトレードオフ
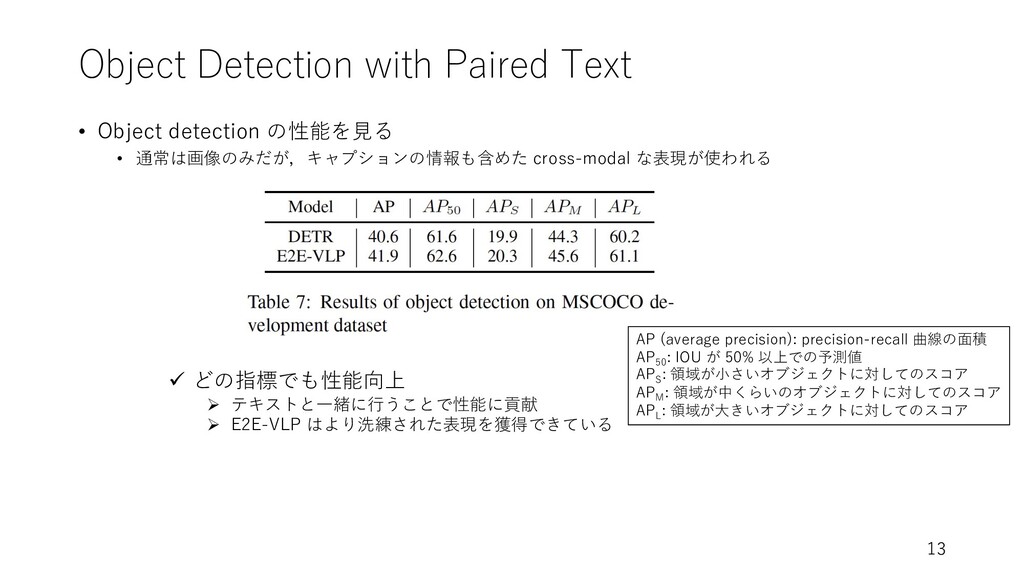
Object Detection with Paired Text • Object detection の性能を⾒る •
通常は画像のみだが,キャプションの情報も含めた cross-modal な表現が使われる 13 ü どの指標でも性能向上 Ø テキストと⼀緒に⾏うことで性能に貢献 Ø E2E-VLP はより洗練された表現を獲得できている AP (average precision): precision-recall 曲線の⾯積 AP50 : IOU が 50% 以上での予測値 APS : 領域が⼩さいオブジェクトに対してのスコア APM : 領域が中くらいのオブジェクトに対してのスコア APL : 領域が⼤きいオブジェクトに対してのスコア
Conclusion • End-to-end の spatial feature を使った VLP を提案した •
Encoder-decoder モデルで,デコーダーで画像に関する⽣成タスク (Object detection, image-captioning) を⾏う • Object detection でオブジェクトに関するテキストと画像の意味的なアライメントを 獲得 • 2-step のモデルよりも推論時間が少なく,パラメーター効率も良く,性能も同等以上 • Future Work • 低レイヤでのテキストと画像のインタラクションを調査 • 他の VL pre-training タスクを⼊れてみる 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Visual-enhanced Decoder • Object detection • DETR[Carion et al., 2020]](https://files.speakerdeck.com/presentations/8cc13e00826e4329ac280b4841b53f49/slide_5.jpg){kind=link}
![DEtection TRansformer (DETR) [Carion et al., 2020] • N 個のオブジェクトを](https://files.speakerdeck.com/presentations/8cc13e00826e4329ac280b4841b53f49/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}