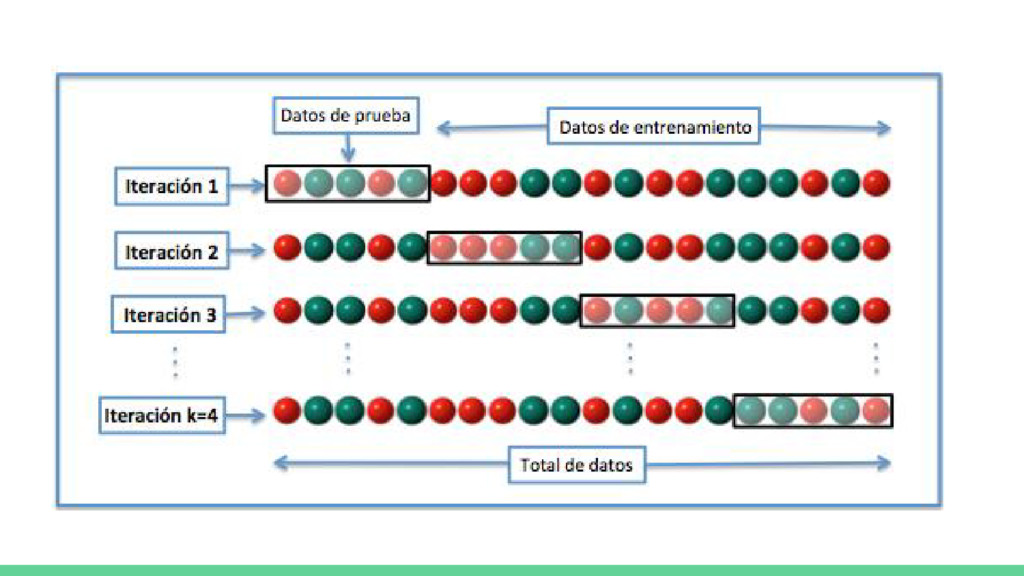
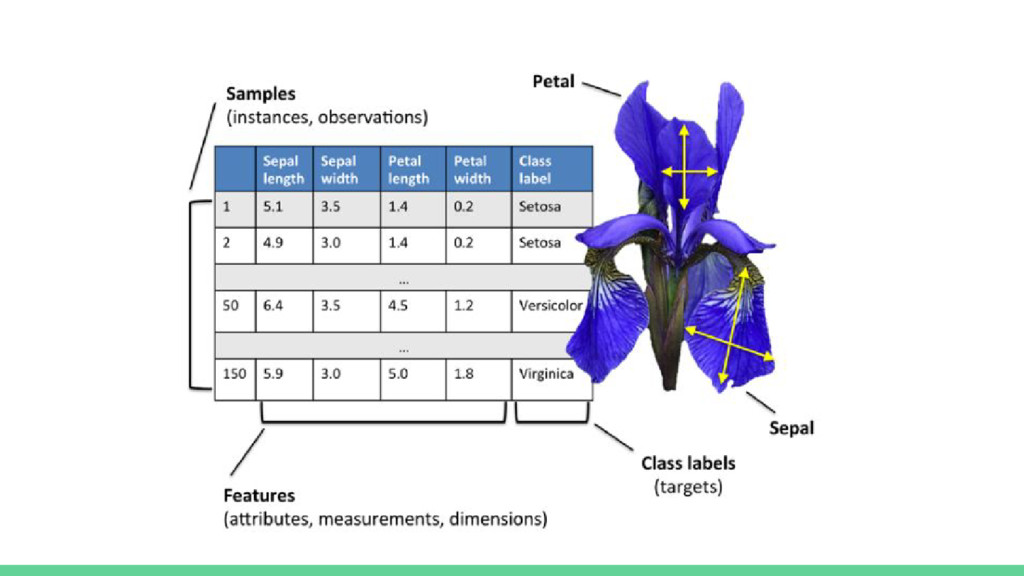
Definición de ciencia de datos • Definición de machine learning • Introducción al aprendizaje automático • Tipos de aprendizaje automático • Aprendizaje supervisado vs no supervisado • Problema del sobreentrenamiento • Pasos para construir un modelo de machine learning
Python para machine learning:Numpy, SciPy, Pandas • Instalación anaconda + jupyter notebook • Conjunto de datasets • Introducción a pandas • Librerías de visualización de datos con python • Ejemplos prácticos tratamiento de datos con pandas • Ejemplos prácticos visualización de datos • Otras librerías de machine learning con python
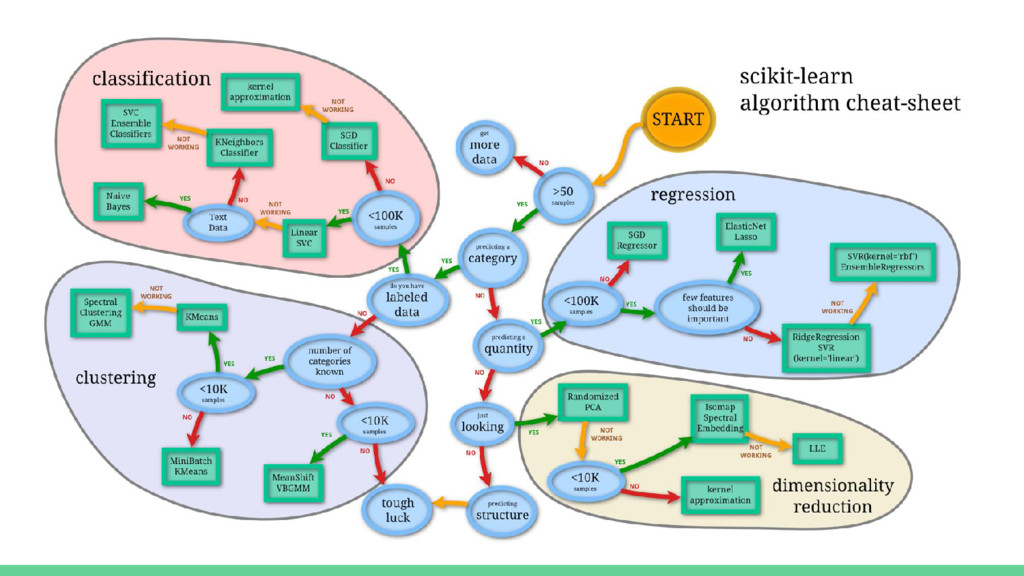
• Instalación y módulos • LinearRegression como algoritmo de regresión lineal • LogisticRegression como algoritmo de regresión logística • DecissionTreeClassifier y RandomForestClassifier como algoritmos de árboles de decisión • SVM como algoritmo de máquinas de vectores de soporte
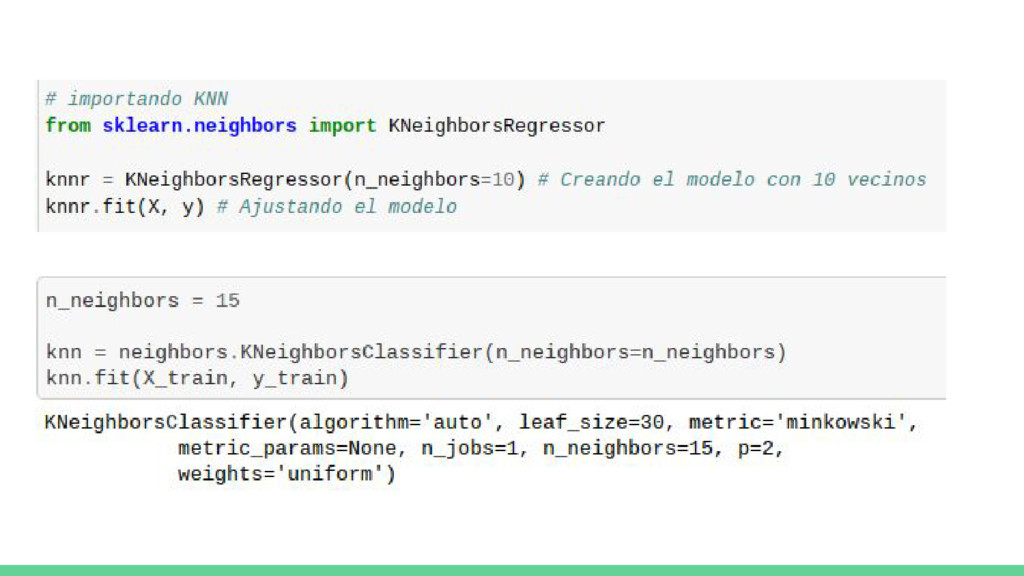
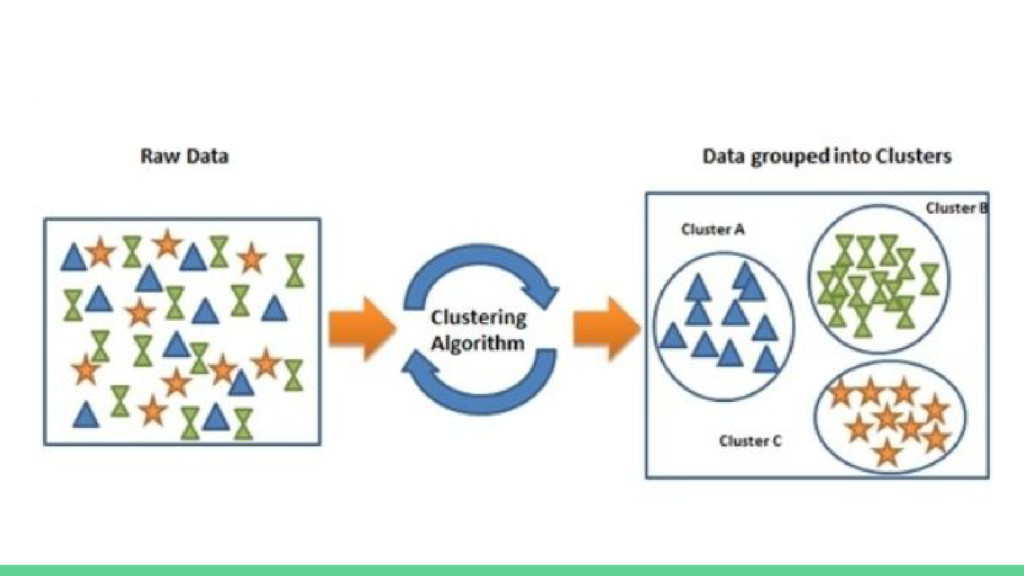
SVM en scikit-learn • KNeighborsClassifier como algoritmo de clasificación supervisada vecinos más cercanos • Implementación de KNeighborsClassifier en scikit-learn • Clustering y aprendizaje no supervisado • K-means como algoritmo de clustering • Implementación de K-means en scikit-learn • Ejemplo con Iris / Titanic Dataset
Introducción a Apache Spark • Módulos de Apache Spark • Spark para Científicos de Datos • Instalación de Apache Spark • Instalar y ejecutar Pyspark con docker • Introducción a Pyspark • Consola interactiva en pyspark • SparkContext y esqueleto de una aplicación con pyspark
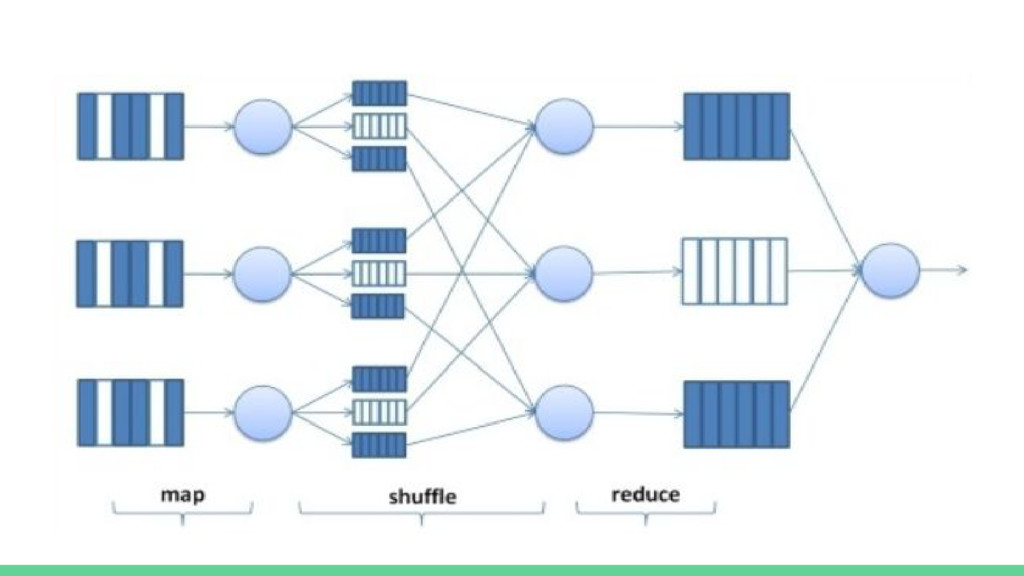
Datasets y RDD con pyspark • Crear un RDD en python con pyspark • Operaciones sobre un RDD • Transformaciones sobre un RDD • SparkSubmit para la ejecución de scripts python • Map-reduce con pyspark • Contador de palabras con pyspark • Palabras más frecuentes de un texto con pyspark • Lectura ficheros csv,json con pyspark
Trabajando con Spark SQL y dataframes • MLlib como módulo de machine learning con pyspark • Clustering con pyspark.Algoritmo Kmeans • Ejemplo clasificación Spam con mLlib
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}