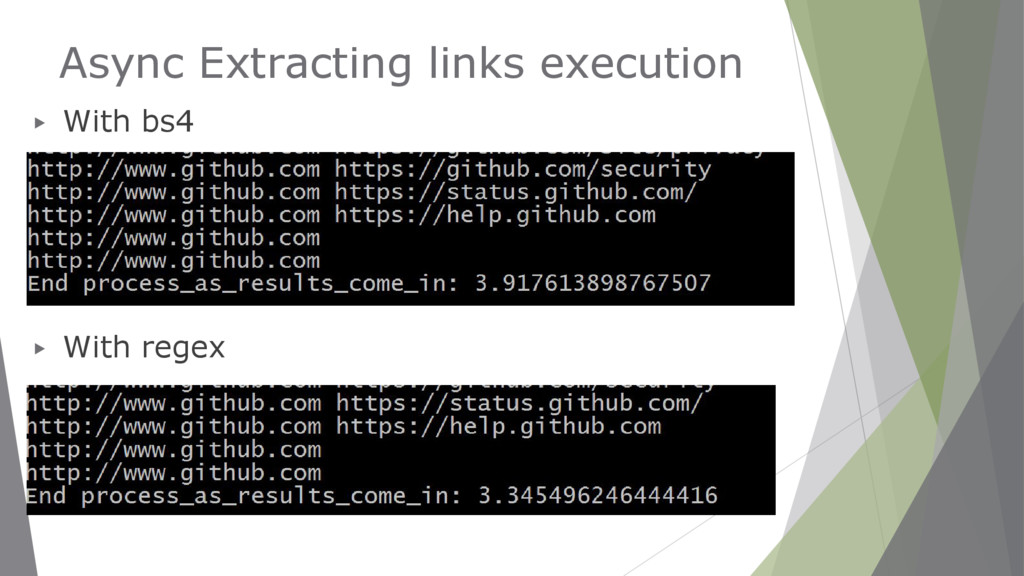
element <title> ▪ get(‘href’)→Returns the attribute href value ▪ (element).text → Returns the text inside an element for link in soup.find_all('a'): print(link.get('href'))
that systematically browses the World Wide Web, typically for the purpose of Web indexing. A Web crawler may also be called a Web spider. https://en.wikipedia.org/wiki/Web_crawler
for asynchronous operations. ▶ Scrapy has better support for html parsing. ▶ Scrapy has better support for unicode characters, redirections, gzipped responses, encodings. ▶ You can export the extracted data directly to JSON,XML and CSV.
asynchronous code using callbacks or coroutines. ▶ Event loop function like task switcher,just the way operating systems switch between active tasks on the CPU. ▶ The idea is that we have an event loop running until all tasks scheduled are completed. ▶ Features and tasks are created through the event loop.
requiring multiple threads or processes. ▶ Coroutines are like functions, but they can be suspended or resumed at certain points in the code. ▶ Coroutines allow write asynchronous code that combines the efficiency of callbacks with the classic good looks of multithreaded.
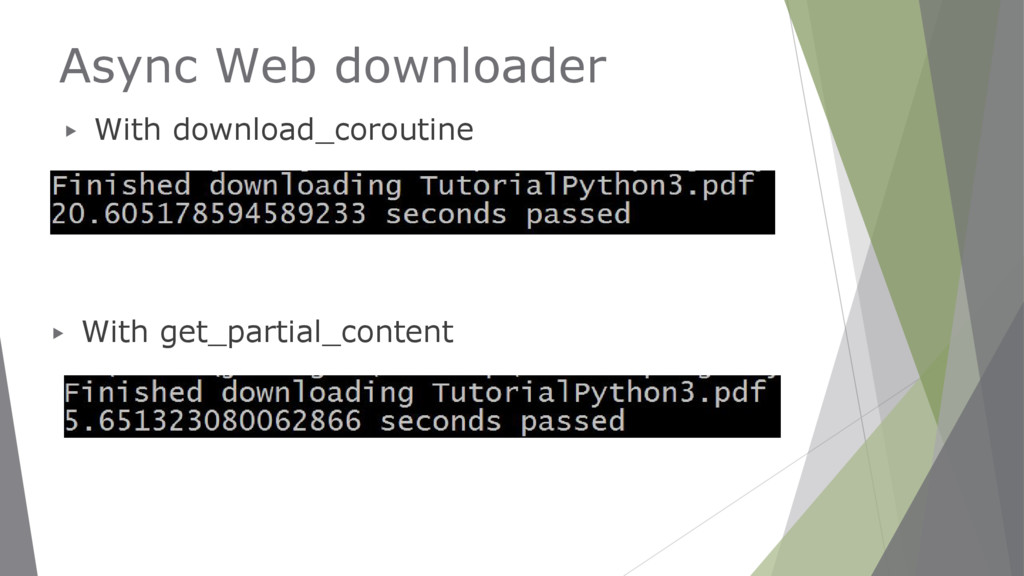
#methods equivalents async def getpage_with_aiohttp(url): with aitohttp.ClientSession() as session: async with session.get(url) as response: return await response.read()
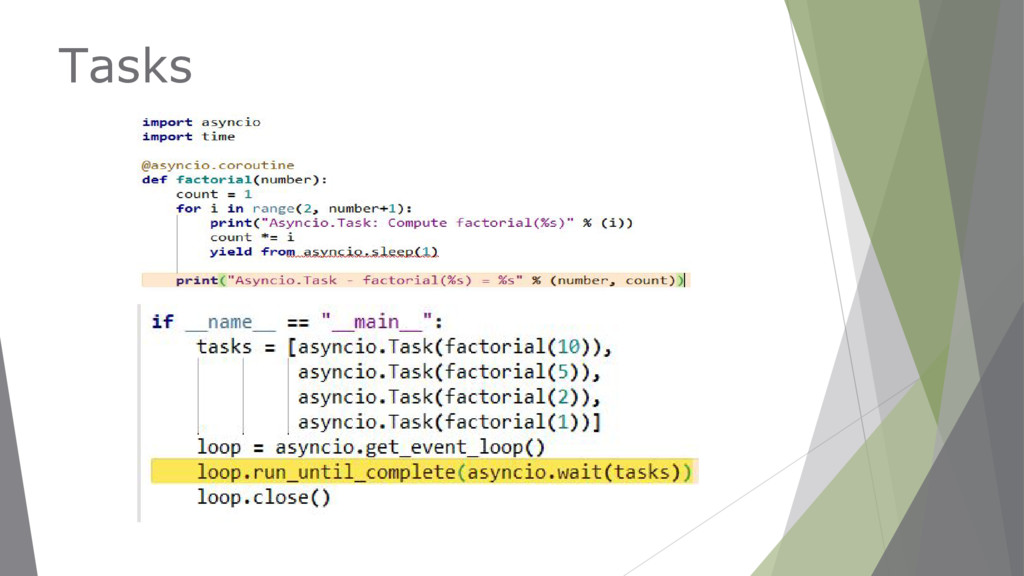
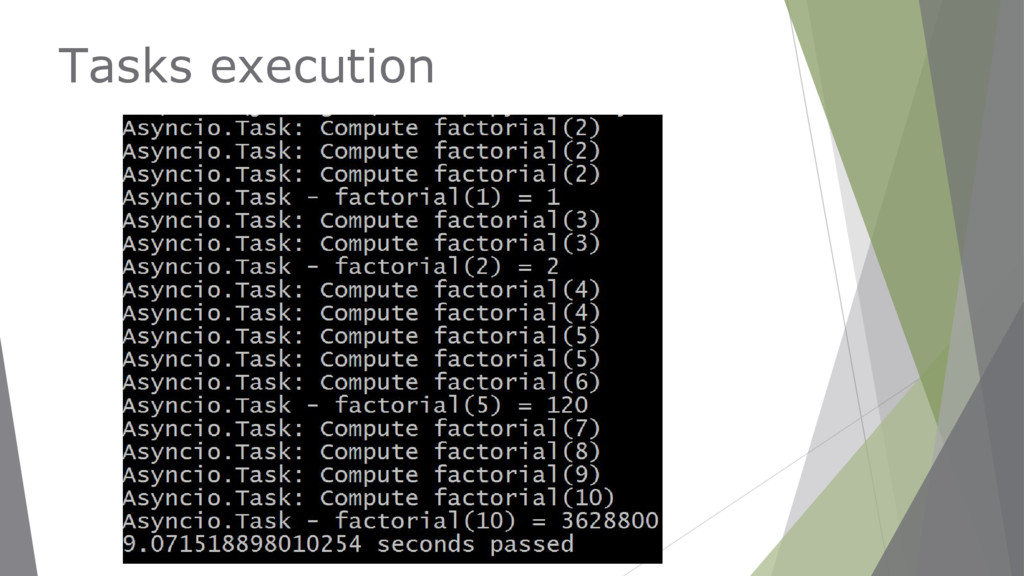
to encapsulate and manage coroutines. ▶ Allow independently running tasks to run concurrently with other tasks on the same event loop. ▶ When a coroutine is wrapped in a task, it connects the task to the event loop.
a result. ▶ A Future will returns the results when they are available, and once it receives results, it will pass them along to all the registered callbacks. ▶ Each future is a task to be executed in the event loop
▶ The argument indicates the number of simultaneous requests we want to allow. ▶ sem = asyncio.Semaphore(5) with (await sem): page = await get(url, compress=True)
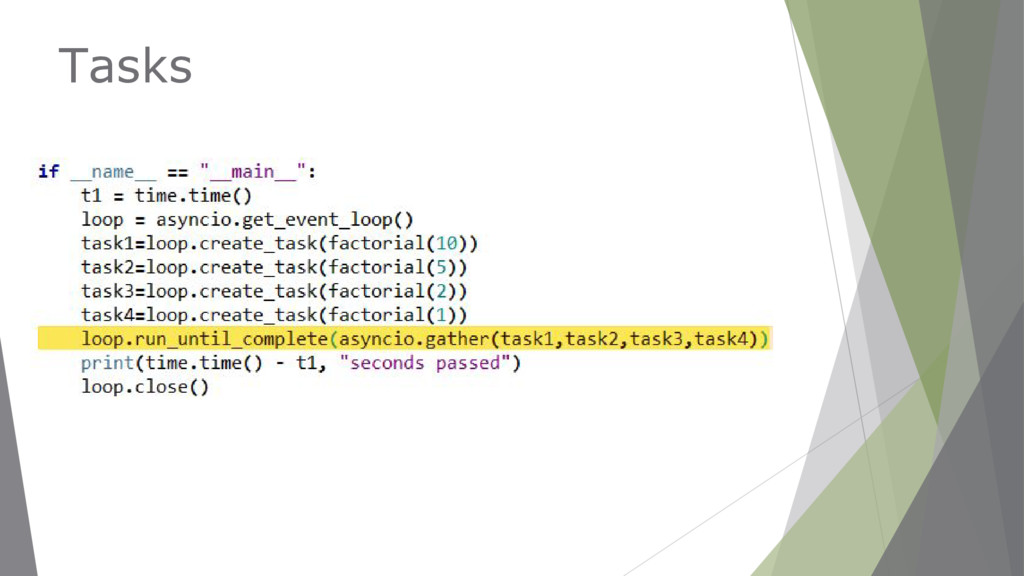
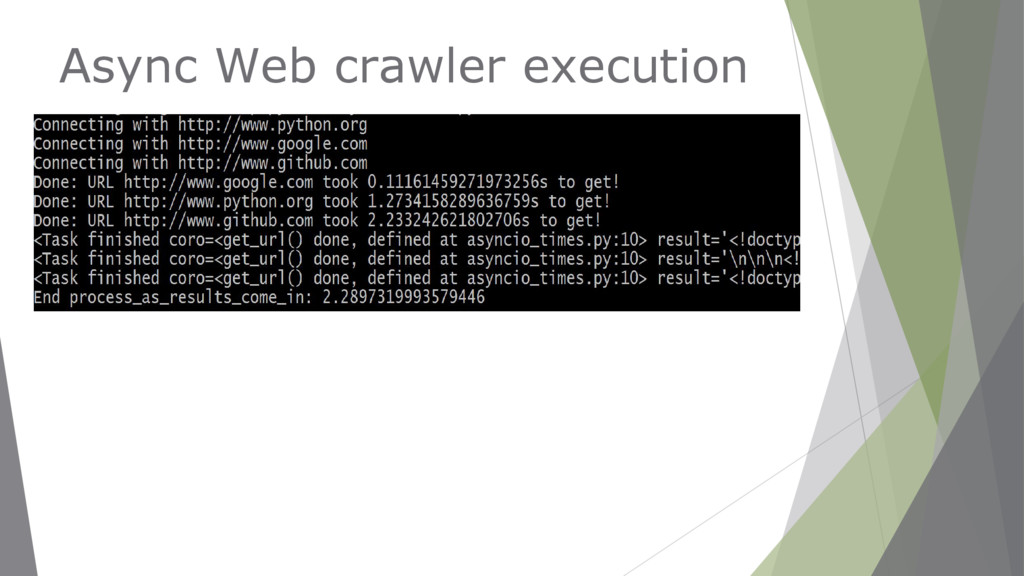
links on a web page and add the responses to a queue to be processed as we go. ▶ Coroutines allow running independent tasks and processing their results in 3 ways: ▶ Using asyncio.as_completed →by processing the results as they come. ▶ Using asyncio.gather→ only once they have all finished loading. ▶ Using asyncio.ensure_future
wait_time = random.randint(1, 4) yield from asyncio.sleep(wait_time) print('Done: URL {} took {}s to get!'.format(url, wait_time)) return url, wait_time @asyncio.coroutine def process_results_as_come_in(): coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']] for coroutine in asyncio.as_completed(coroutines): url, wait_time = yield from coroutine print('Coroutine for {} is done'.format(url)) def main(): loop = asyncio.get_event_loop() print(“Process results as they come in:") loop.run_until_complete(process_results_as_come_in()) if __name__ == '__main__': main() asyncio.as_completed
wait_time = random.randint(1, 4) yield from asyncio.sleep(wait_time) print('Done: URL {} took {}s to get!'.format(url, wait_time)) return url, wait_time @asyncio.coroutine def process_once_everything_ready(): coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']] results = yield from asyncio.gather(*coroutines) print(results) def main(): loop = asyncio.get_event_loop() print(“Process results once they are all ready:") loop.run_until_complete(process_once_everything_ready()) if __name__ == '__main__': main() asyncio.gather
loop=None, return_exceptions=False) Return a future aggregating results from the given coroutine objects or futures. All futures must share the same event loop. If all the tasks are done successfully, the returned future’s result is the list of results (in the order of the original sequence, not necessarily the order of results arrival). If return_exceptions is True, exceptions in the tasks are treated the same as successful results, and gathered in the result list; otherwise, the first raised exception will be immediately propagated to the returned future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}