Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データサイエンス11_前処理.pdf
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
June 25, 2018
Education
500
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データサイエンス11_前処理.pdf
自然言語処理研究室
June 25, 2018
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
自然言語処理研究室 研究概要(2016年)
jnlp
0
220
Other Decks in Education
See All in Education
自己紹介 / who-am-i
yasulab
6
7k
[2026前期火5] 論理学(京都大学文学部 前期 第11回)「ハーモニー:三層モデルと保存拡大」
yatabe
0
160
0526
cbtlibrary
0
190
0415
cbtlibrary
0
230
[2026前期火5] 論理学(京都大学文学部 前期 第8回)「正規化定理の証明」
yatabe
0
220
Catecismo 26 #1 - Aula inaugural
cm_manaus
0
200
プロポーザルを書く技術とアンチパターン/proposal-writing-and-antipatterns
moriyuya
13
3.5k
良書紹介08_ 頭のいい子がやっているすごいグラフの読み方
bunnchinn3
0
110
JAWS-UG初心者支部#81 GWにEduJAWSと何か作ろうもくもく会!
otsuki
0
150
生成AI時代の情報発信
molmolken
0
140
2026年度春学期 統計学 第7回 データの関係を知る(2)ー 回帰と決定係数 (2026. 5. 21)
akiraasano
PRO
0
180
Modern Data Fetching Techniques in Angular
debug_mode
0
230
Featured
See All Featured
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Code Review Best Practice
trishagee
74
20k
We Are The Robots
honzajavorek
0
270
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
Statistics for Hackers
jakevdp
799
230k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Transcript
None
山本担当分(11回~15回) 第11回 テキストデータと前処理 第12回 機械学習、データの分類 第13回 類似度、重要度、相関
第14回 推薦システムとシステム評価 第15回 全体まとめと達成度確認テスト
今日の内容 テキストデータ テキストマイニング 前処理 言語データの種類
文字コード ノイズ除去
Text data
テキストデータの種類 Webクローリングテキスト URLを限定せず、無差別大量にほしい時 新聞記事 公開テキスト
Twitter、各種クチコミなど 流行が知りたい、自社製品の評判を知りたい等 非公開テキスト(組織内文書) 日報、アンケート、カルテ、文献
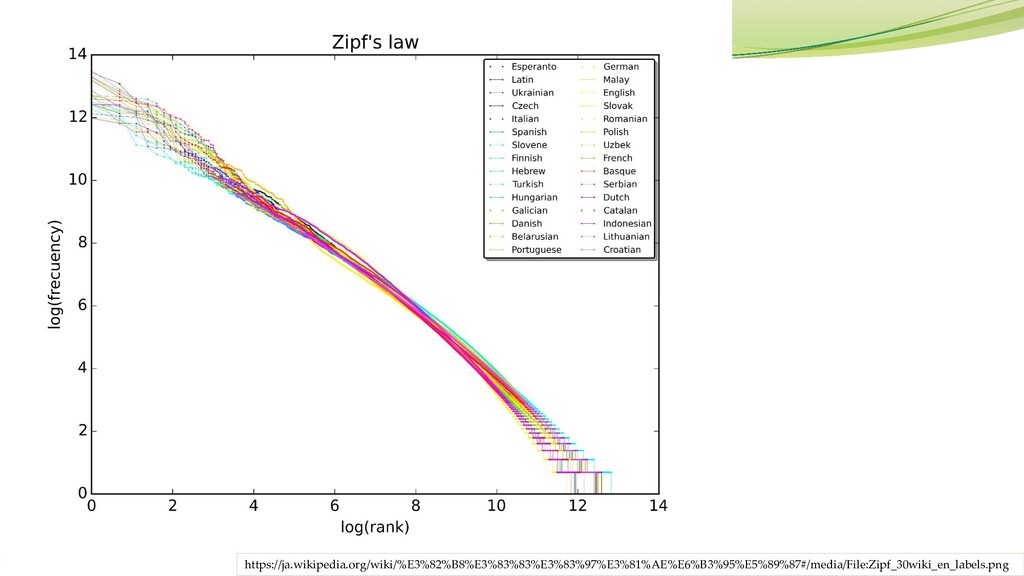
ジップの法則 (Zipf’s law) 出現頻度が k 番目に大きい要素が全体に占める割合が 1/k に比例する という経験則
すなわち、どのような単語統計を取っても、極めて少数の単語が高頻度で あり、多数の単語は低頻度である。 言語統計だけの性質でなく、アクセス頻度、人口、収入など様々な社会現 象において概ねこの性質が成立することが確認されている。 テキストデータの解析は(概要把握だけなら)易しく、(全容把握は)難しい。
https://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%83%E3%83%97%E3%81%AE%E6%B3%95%E5%89%87#/media/File:Zipf_30wiki_en_labels.png
Text mining
テキストマイニング(text mining) 最近ではテキストアナリティックス(text analytics)とも呼ぶ。 大量のテキストを対象に何らかの有益な知見を得るための一連の作業 実際に行う作業は多岐にわたる
データの分類・クラスタリング 情報抽出 情報可視化
データマイニングとの違い 対象とするデータが構造化データかどうかの違い データマイニング:数値や◦×など、何らかの表形式になっているデータが 分析対象 テキストマイニング:テキスト(自然言語文)が分析対象。これを自然 言語処理を使って何らかの表形式に変換する処理が必要
つまり、自然言語処理によって言語情報が何らかの表形式に変換できれば、 以降で用いられる技術は同一。
preprocessing
前処理の重要性 データ処理は「きれいな」データが対象 しかし、実際のデータはきれいでないことがほとんど 特にテキストデータ(言語データ)は半端ないことが多い 目的とする処理をする以前に、データに対する前処理が必須
データサイエンスの現場において、その 業務は「前処理」と呼ばれるデータの 整形に90%以上の時間を費やすと 言われています。「前処理」を効率よく こなすことで、予測モデルの構築やデー タモデリングといった本来のデータサイエ ンス業務に時間を割くことができるわけ です。
None
None
テキスト処理以前の前処理 データのスケーリング 例えばX軸とY軸の2次元空間を考えるとき、数値が X >>> Y である とY軸の影響はほとんどない。
データのシャッフル 多くの場合データの整列順には何らかの偏りがある(つまり何らかのソートが されている)。この先頭Nサンプルで訓練や評価を行っても偏るのは当然で ある。 ノイズの除去 何らかの方法で予めノイズの除去が可能であればクリーニングを行う。
テキストの整形とクリーニング 文字コード JIS、シフトJIS、EUC-JP、Unicode(UTF-8、UTF-16) 今ならUTF-8に統一するのが現実的 改行コード
CRLF(Windows)、CR(Mac OS)、LF(Linux) (入手時の環境ではなく)開発環境に揃えるべき (HTMLテキスト等に対する)タグの除去
None
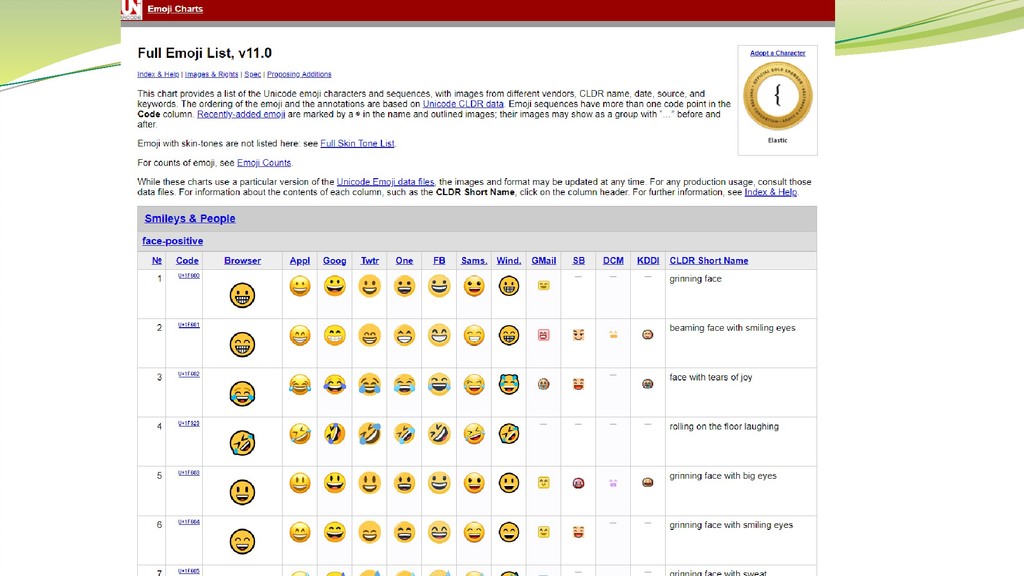
おまけ:絵文字のお話 2000年ごろから、日本のケータイ3社が勝手に拡張する 2007年 Googleが絵文字の開発を開始 2008年 ソフトバングがiPhone 3Gを発売、絵文字が搭載。
2010年 Unicode 6.0 で絵文字が採用 つまり、 日本発祥の(ケータイ)絵文字が世界標準になった ただし採用される絵文字は同一ではない 絵文字の普及と同時に Unicode が世界に普及した
フォーマットの変換 1行を1単語とする 1行を1文とする 1行を1文書とする これらは何をどう処理したいかによって選択する必要がある
単語分割 日本語の場合は、文字列を単語に分割する必要がある。 形態素解析 日本語の形態素解析器は下記の通り JUMAN(老舗) /
JUMAN++ (改良版) ChaSen MeCab (最もよく使われる) Sudachi
参考:Webで単語分割 http://reed.kuee.kyoto-u.ac.jp/nl-resource/cgi-bin/juman.cgi
http://chamame.ninjal.ac.jp/
参考:Webで単語分割 http://www.sofnec.co.jp/az-demo/cgi-bin/mecabtest.cgi
https://tool.konisimple.net/text/hinshi_keitaiso
文字種の統一 全角文字と半角文字の統一 漢数字(一、ニ、三)と算用数字(1, 2, 3)の統一 記号の統一
(年号の統一):西暦と和暦
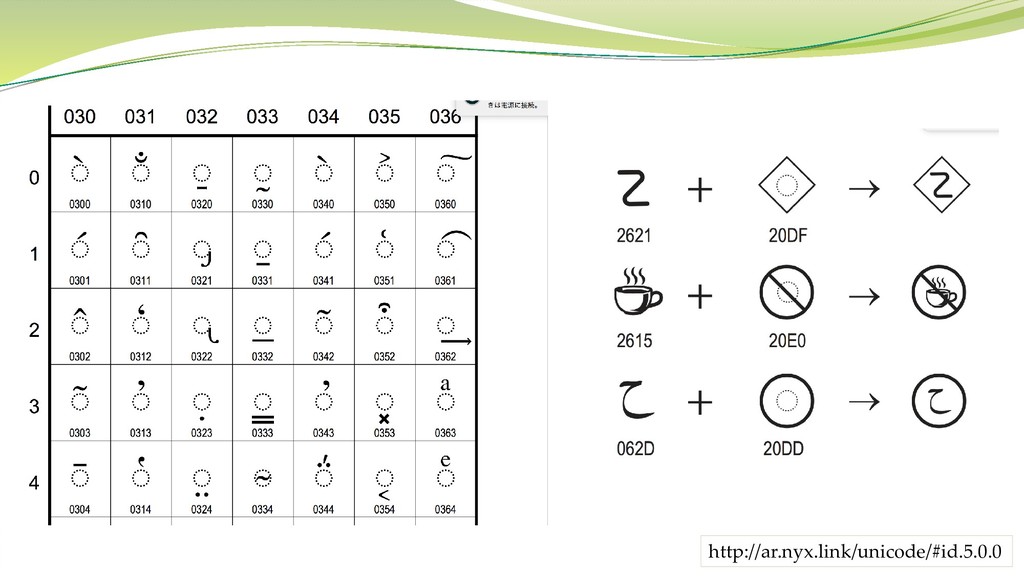
Unicode の文字統一 Unicode には結合文字列(Combining Characters) という概念があり、連 続する二つの文字コードの合成によって1文字を表現することができる。 日本語の濁点・半濁点など
この結果、例えば「だ」という文字は、全く同一の文字でありながら 「た」+(濁点) 「だ」 の2種類の文字コードが存在することになる。 これは検索など様々な処理において非常に面倒。よって統一する必要がある。 NFKC(Normalization Form KC)正規化
http://ar.nyx.link/unicode/#id.5.0.0
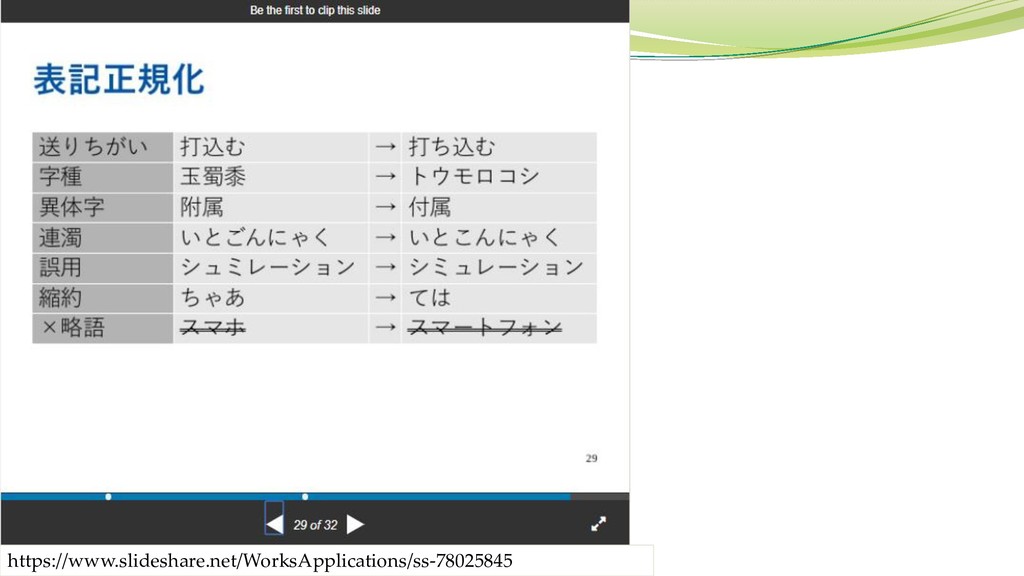
表記ゆれ 特に日本語には、様々な表記ゆれ (多様な表現)が存在する。 文字種 「りんご」と「リンゴ」と「林檎」 旧漢字
「付属」と「附属」 「竜馬」と「龍馬」 部分的なひらがな化 「改ざん」と「改竄」 送りがなの異なり 「受け付ける」と「受付ける」 外来語 「コンピュータ」と「コンピューター」 「バイオリン」と「ヴァイオリン」 口語的表現 「~ている」と「~てる」 「すばしっこい」と「すばしこい」
表記ゆれ(続き) 表記ゆれに対処できる自然言語処理ツールは存在しなかった。 より正確には、部分的にしか対応できていなかった。 2017年に Sudachi というツールが発表。
ワークス徳島人工知能NLP研究所
https://www.slideshare.net/WorksApplications/ss-78025845
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}