Tomas Mikolov, Martin Karafiat, Lukas Burget, JanCernocky, and Sanjeev Khudanpur. Recurrent neural network based language model. In 11th Annual Conference of the International Speech Communication Association, pp.1045–1048, 2010.
written by Nguyen Van Hai.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
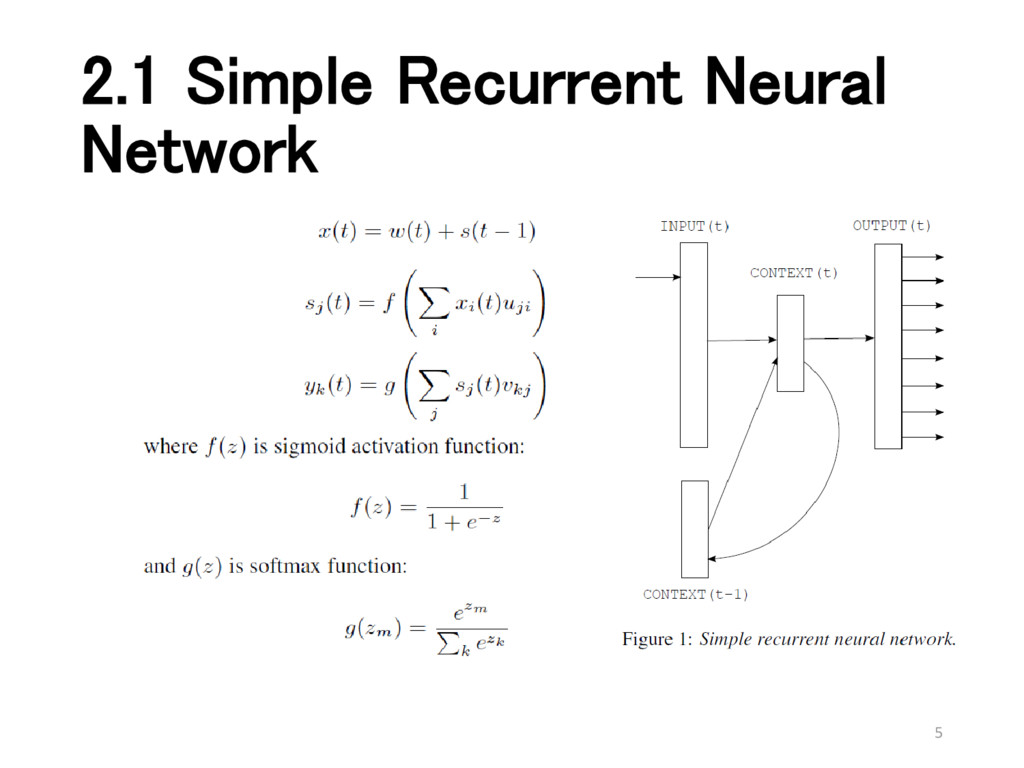{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
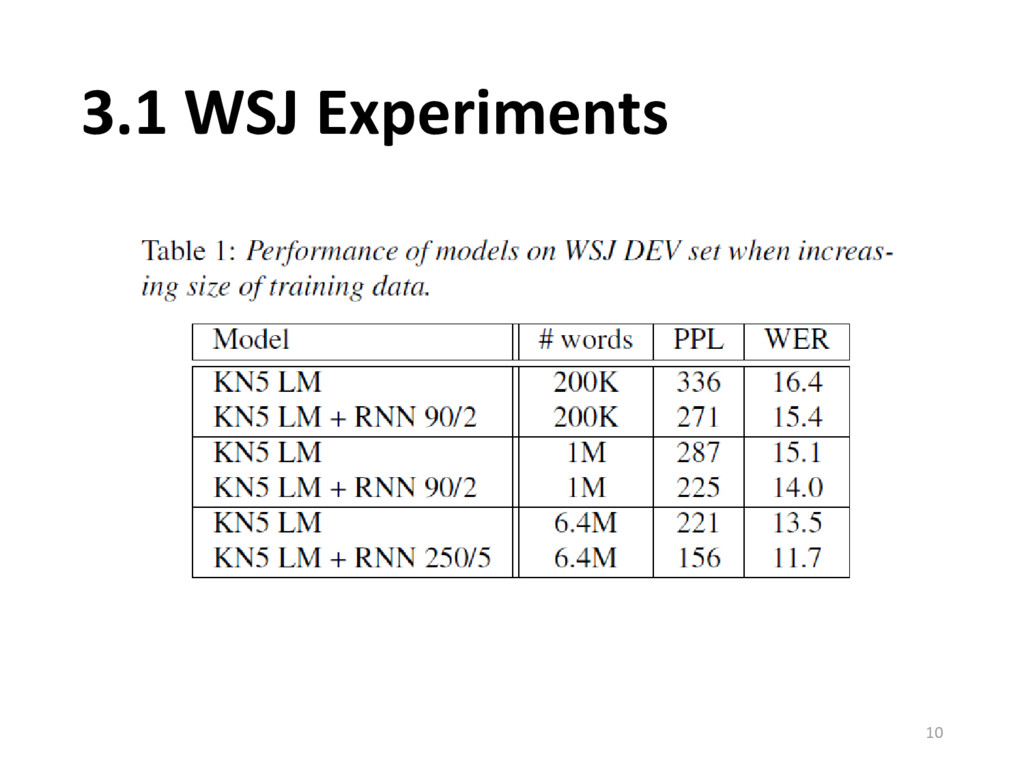{kind=link}
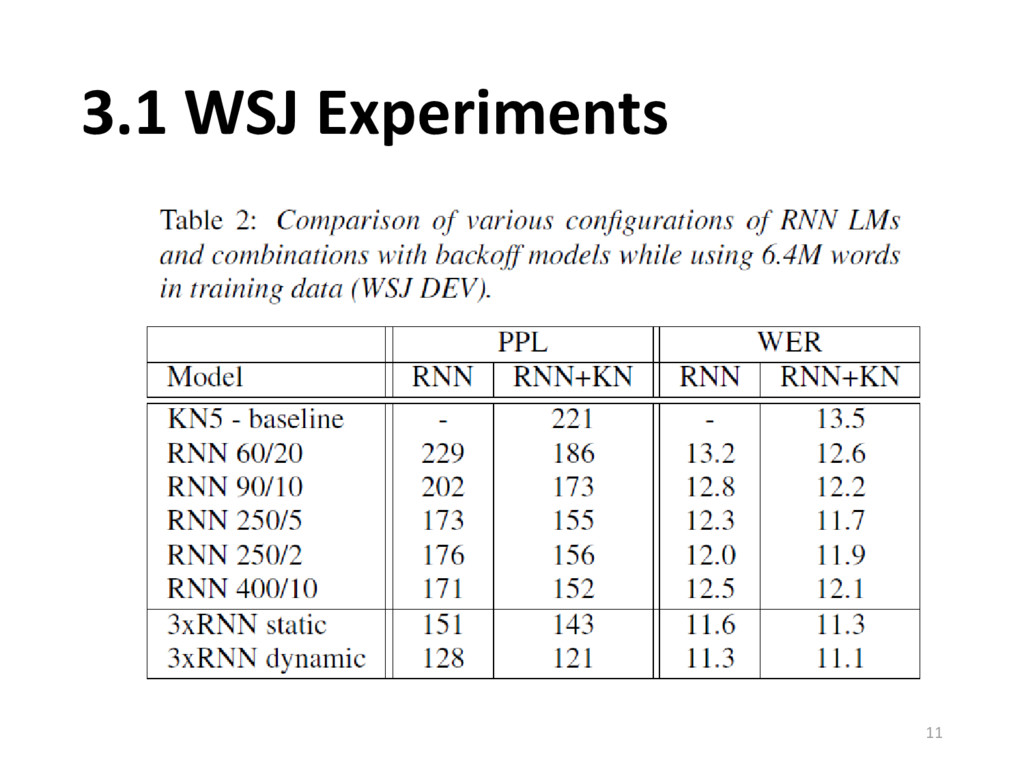{kind=link}
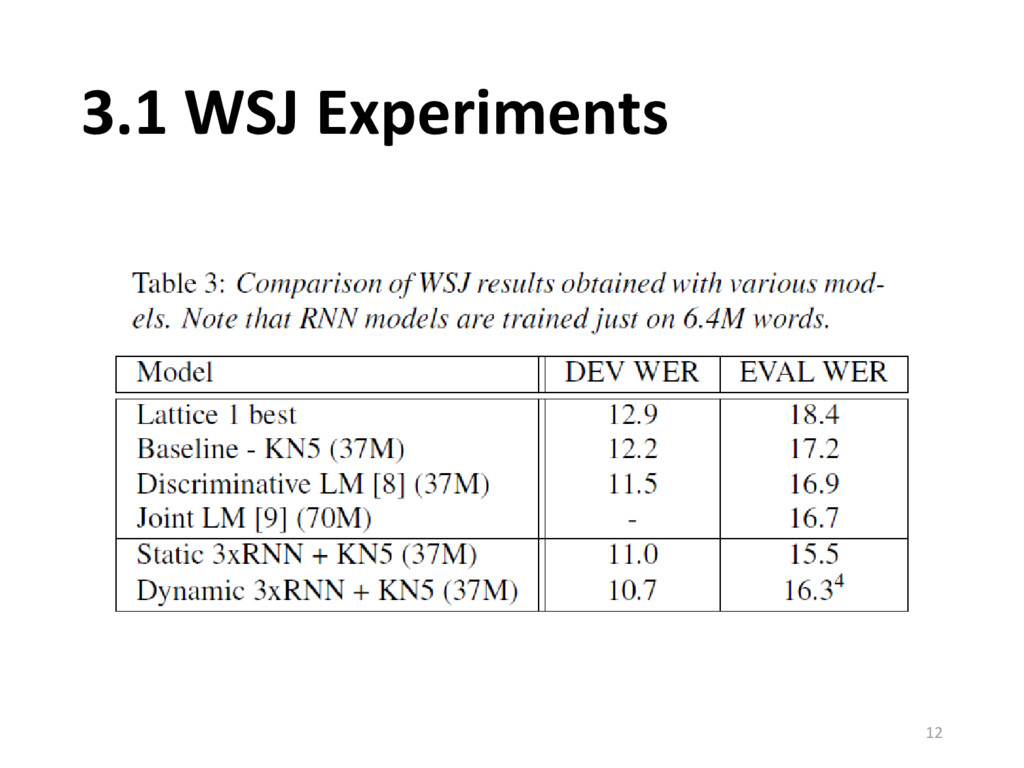{kind=link}
{kind=link}
{kind=link}