Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データサイエンス13_解析.pdf
Search
自然言語処理研究室
July 09, 2018
Education
530
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データサイエンス13_解析.pdf
自然言語処理研究室
July 09, 2018
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
自然言語処理研究室 研究概要(2016年)
jnlp
0
220
Other Decks in Education
See All in Education
0526
cbtlibrary
0
190
Gitがない時代 インターネットがない時代の 開発話
sapi_kawahara
0
320
[2026前期火5] 論理学(京都大学文学部 前期 第2回)「論理的な正しさはどこにあるのか」
yatabe
0
1k
2026年度春学期 統計学 第10回 分布の推測とは - 標本調査,度数分布と確率分布 (2026. 6. 4)
akiraasano
PRO
0
120
Visionary Initiative: Future Intelligence 「未来の知性と社会の礎を築く」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
800
現場最前線から教えるデータサイエンス1 -ITベンダーにおけるデータサイエンティスト-
hidetoshikawaguchi
0
130
Modern Data Fetching Techniques in Angular
debug_mode
0
230
遊ぶかね欲しさの犯行(ルビ:労働)です
shirayanagiryuji
0
140
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
130
Where Data Meets Storytelling
georgesinnott
0
130
Laura Wilson - The Quarterly PR Pivot
laurawilsonbseo1
1
370
0506
cbtlibrary
0
210
Featured
See All Featured
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
460
Deep Space Network (abreviated)
tonyrice
0
220
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
A Tale of Four Properties
chriscoyier
163
24k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
How to build a perfect <img>
jonoalderson
1
5.8k
Raft: Consensus for Rubyists
vanstee
141
7.6k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
180
Building an army of robots
kneath
306
46k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
560
WCS-LA-2024
lcolladotor
0
680
RailsConf 2023
tenderlove
30
1.5k
Transcript
None
今日の内容 テキストの重要度 類似度 相関 相互情報量
Importance metrics of text
テキストの重要度のモデル化 テキストを単語の集合と考える。これを bag-of-words と呼ぶ。 つまりテキストは単語という構成要素に分解することができる、と考える。 各単語の並び順(文脈)や、テキスト全体での意味は無視
これで実際にテキストが理解できるという主張ではなく、あくまでも計算機 処理のための近似である。
単語の重要度:TFとIDF 単語 t の文書 d、文書集合をDとす ると、 TF (term frequency)
DF (document frequency) IDF (inverse document frequency)
単語の重要度:TFIDF TFIDF TFIDFの意味 重要な単語は頻出する:TF値として反映 重要な単語は文書ごとに異なる:IDF値として反映
TFIDF値も簡便でゆるい近似であって、一部は直感と一致しない
文の重要度 基本的には単語の重要度(TFIDF値など)を用いて算出する。 各単語の重要度の総和 課題:文が長くなればなるほど有利 各単語の重要度の平均
課題:長い文は一般的に不利 ではそうすればいいのか? アイデア募集中
similarity
集合の類似度 Jaccard 係数 Simpson 係数 Dice 係数
どう使い分けるのか?
表記の類似度 文字列を文字の集合と考えて類似度(重複の多さ)を計算する。 例えば、Jaccard係数で文字類似度を計算すると
表記の類似度2 ただ、必ずしもこれではうまくいかない。 このため、別の考え方で表記の類似度を計算する必要がある。
表記の類似度3 編集距離(edit distance):単語1を単語2に変換するのに何回の編 集操作が必要かを数値化 削除:ある1文字を削除する 挿入:ある1文字を挿入する
置換:ある1文字を別の1文字に置き換える
編集距離:例「ていし」と「さいかい」 ていし さいし (「て」を「さ」に置換) さいか (「し」を「か」に置換) さいかい (末尾に「い」を挿入) ていし ていしい
(末尾に「い」を挿入) ていかい (「し」を「か」に置換) さいかい (「て」を「さ」に置換) 無駄な操作を繰り返すことは可能 だが、最短のものを編集距離と呼 ぶ。 一般に同一の編集距離でも複数 の編集方法(編集手順)が存在す る。 編集距離には対称性がある。
編集距離の用途 スペルチェック aquire, hight, lisence, guage, …
表記ゆれの検出 バイオリンとヴァイオリン コンピュータとコンピューター 受付と受付け (?) メタノールとエタノール
correlation
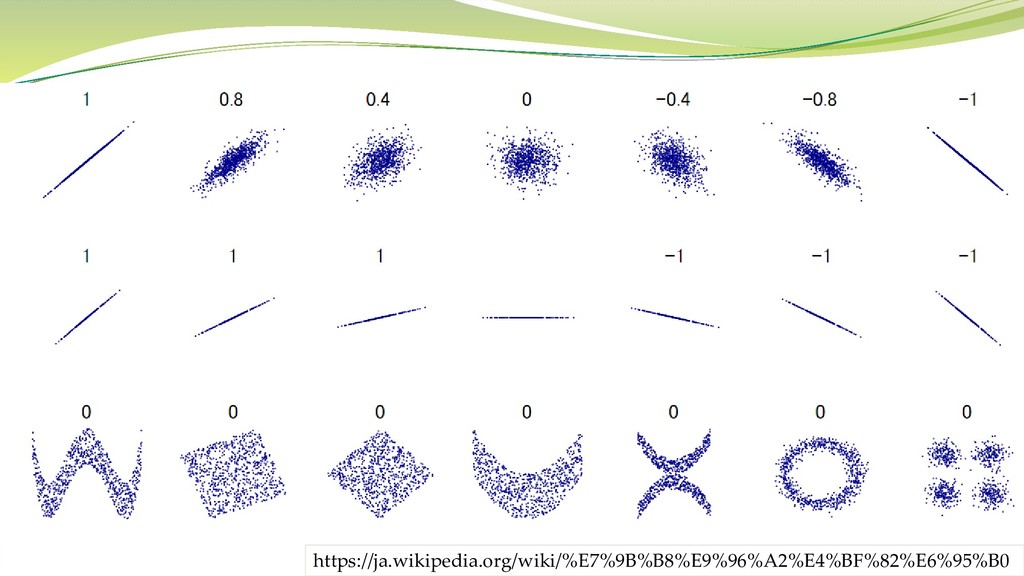
相関係数(ピアソンの積率相関係数) 相関係数 = = 1 σ − (−)
1 σ − 2 1 σ − 2 = σ − σ 2−2 σ 2−2 ここで、 は と の共分散 は の標準偏差 は の標準偏差 はデータ数 は の平均値 は の平均値
https://ja.wikipedia.org/wiki/%E7%9B%B8%E9%96%A2%E4%BF%82%E6%95%B0
順位相関係数 スペアマンの順位相関係数 = = 1 σ − (−)
1 σ − 2 1 σ − 2 = σ − σ 2−2 σ 2−2 ここで、 σ = σ = (+1) 2 σ 2 = σ 2 = (+1)(2+1) 6 = = 2 2 = 2 = (+1)2 4 であることを使って変形する。
順位相関係数 結局、 = 1 − 6 (2−1) σ( −
)2 となり、順位差の二乗和を計算する ことで求めることができる。 ノンパラメトリックな指標 正規分布を仮定する必要がな い それぞれの値でなく順位のみ分かる ような場合に使われる。 社会的調査
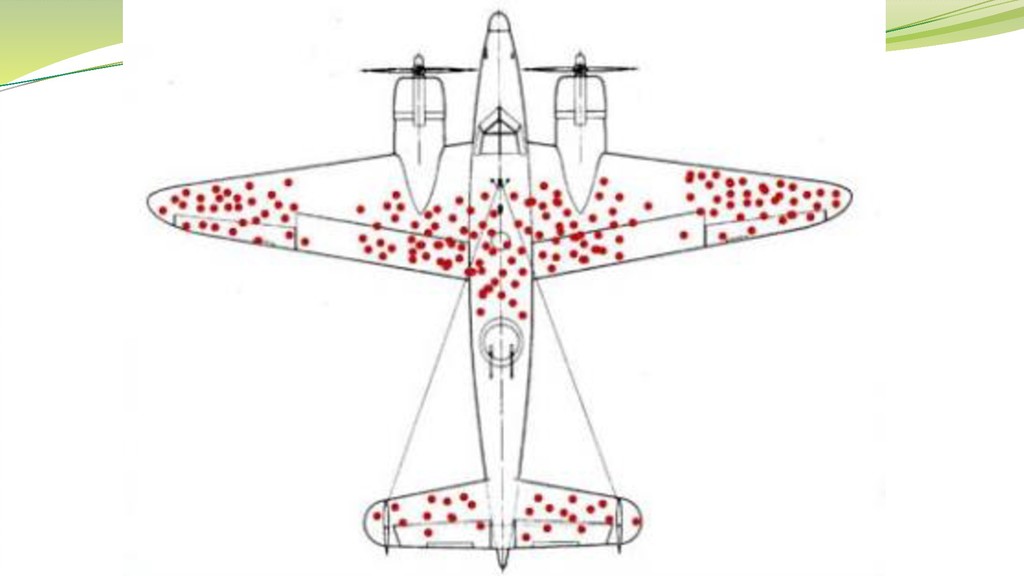
要注意の相関 アイスクリームの売り上げと溺死者数 潜在変数(気温)を介して両者が関係している 交通事故防止の看板数と交通事故件数 方向性が逆
音楽CD売り上げとサバの漁獲量 (おそらく)偶然 降水量と電車利用者数 大都市にのみ限定される
https://about.yahoo.co.jp/info/bigdata/special/2017/02/
相関と因果関係 仮に相関が高くても、因果関係があるのかをよく考える必要がある。 因果関係があれば相関があるが、相関があるからと言って因果関係があると はならない。 相関係数では因果関係の有無は分からない!
おかしな論理関係 「アイスクリームが多く売れると溺死者が多い。よって溺死者を減らすためにア イクリームの販売を制限すべきだ」 「看板が多くある地域は交通事故が多い。よって看板を減らせば交通事故 が減る」 「就職内定者を観察すると、ほとんどの内定者は雨の日に傘をさしていた。 よって雨の日に傘をさしている人は就職内定者である」
None
mutual information
自己相互情報量(pointwise mutual information, PMI) , = log (,) ()
= log (|) () = log (|) () 二つの事象がどの程度同時に起こるかを表現 例:(テキスト分析では)ある2単語が共起(同じ文に出現)するかどうか
相互情報量(mutual information, MI) 相互情報量は自己相互情報量の平均である。 , = σ, (,
) log (,) () 相互情報量が0であれば確率変数が独立である 相関係数が0であっても確率変数が独立とは限らない 相関係数は直線的関係しか考慮できないが、相互情報量はより柔軟に 「相関」を考慮できる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}