Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データサイエンス14_システム.pdf
Search
自然言語処理研究室
July 16, 2018
Education
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データサイエンス14_システム.pdf
自然言語処理研究室
July 16, 2018
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス13_解析.pdf
jnlp
0
540
データサイエンス12_分類.pdf
jnlp
0
380
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
180
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
自然言語処理研究室 研究概要(2016年)
jnlp
0
220
Other Decks in Education
See All in Education
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
Human-AI Interaction - Lecture 11 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
1.1k
JAWS-UG初心者支部#81 GWにEduJAWSと何か作ろうもくもく会!
otsuki
0
150
Examen de Selectividad. Geografía julio 2026 (Convocatoria Extraordinaria). UCLM
juanmartin2026
1
10k
Course Review - Lecture 13 - Information Visualisation (4019538FNR)
signer
PRO
1
2.7k
新しいJavaを学んで・使っていこう! / osd26do
gishi_yama
0
200
焦燥を平穏に変えるエンジニアのための哲学
ichimichi
7
6.3k
Case Studies - Lecture 12 - Information Visualisation (4019538FNR)
signer
PRO
0
190
Portable & Reproducible Research Environments in the Age of AI Agents
denkiwakame
0
540
[2026前期火5] 論理学(京都大学文学部 前期 第11回)「ハーモニー:三層モデルと保存拡大」
yatabe
0
190
Info Session MSc Computer Science & MSc Applied Informatics
signer
PRO
0
300
Soluciones al examen de Geografía 2026. JULIO (Convocatoria Extraordinaria)
juanmartin2026
1
16k
Featured
See All Featured
What's in a price? How to price your products and services
michaelherold
247
13k
Un-Boring Meetings
codingconduct
0
350
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2.1k
A Soul's Torment
seathinner
6
3.1k
How to train your dragon (web standard)
notwaldorf
97
6.7k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Navigating Weather and Climate Data
rabernat
0
420
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
390
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
600
The Curse of the Amulet
leimatthew05
2
13k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
Chasing Engaging Ingredients in Design
codingconduct
0
240
Transcript
None
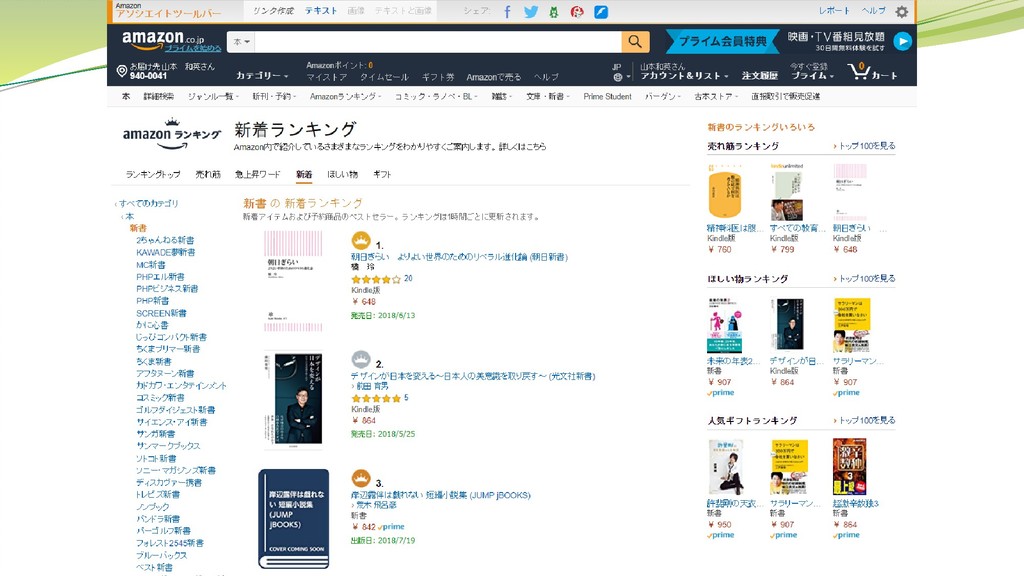
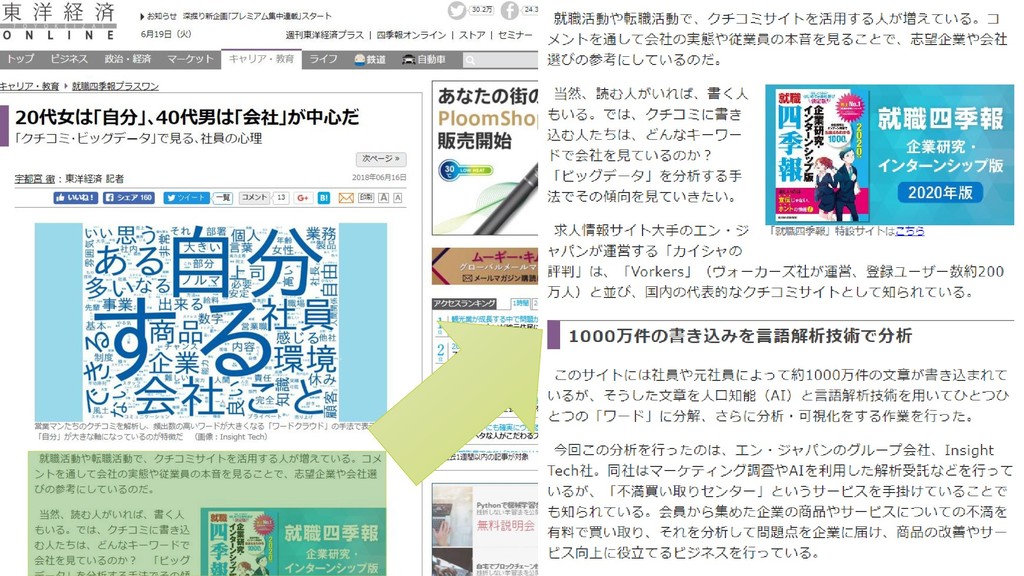
今日のメニュー 推薦システム 評判分析 システム評価
None
推薦システム サイト利用者の(購入)判断の際に参考となる情報を紹介するシステム 具体例 売れ筋ランキング 類似商品・関連商品の提示
書評、クチコミ 「これをリンク/購入した人は…を購入しています」
None
None
None
None
推薦システム誕生の背景 情報量の増大 検索すればいいのでは? 検索ではヒット件数が多すぎて絞り切れない どんなキーワードで検索していいのか分からない
推薦システムで利用される情報 明示的情報:利用者自身が入力した情報 星の数(1~5または7) 商品コメント 推測情報:利用者の行動から推測した情報
購入履歴:買ったということは興味がありそう 閲覧ページ、閲覧時間:ページを(長時間)見ているということは興味 がありそう
推薦システムで起こった発想の転換 1.店の視点(売りたいものを売る)から購入者の視点(買いたいものを買う)へ の発想の転換 書店では、店員が読んで面白い/誰かに依頼された/これを売ると利益率が 高い、など様々な(店側の)理由で売りたいものを並べていた (例えば)アマゾンでは、購入者に意見・感想を書かせ、あるいは購入行動の 情報を新規利用者に提示することで購入意欲を高めている。つまり、店は予め 売りたい商品を決めていない。
2.大衆から個別への発想の転換=個人適用 個人によって興味関心が違うことを前提とした売り方 インターネットやIT化に伴って省コストで実現可能
発想の転換(続き) 自然言語処理から見ると、もう一つ重要な発想の転換がある。 「内容を理解せずに推薦する」 すなわち、店の人(あるいはアマゾン)は本を読まず、音楽を聴かず、購入者 の行動履歴や購買履歴を情報源にして推薦している。 これはある意味、推薦システムの構築に自然言語処理は不要であることを
意味している。 ただし、「良い推薦」のためにはテキスト解析が必要なことも事実。
推薦システムの分類 協調フィルタリング クチコミ等の情報を利用して高評価なものを提示 内容ベースフィルタリング 内容を解析して類似したもの・高評価なものを提示
推薦システムの問題点 協調フィルタリングにおいて新規ユーザーや新商品に対応できない コールドスタート問題 偽のクチコミ、サクラ、ゴミ、スパム 意図的に高い評価を与える
意図的に低い評価を与える 大規模化 規模拡大によって上記ゴミが増え、結果的に評価の信頼性が下がる
None
(クチコミ分析、ソーシャルリスニング)
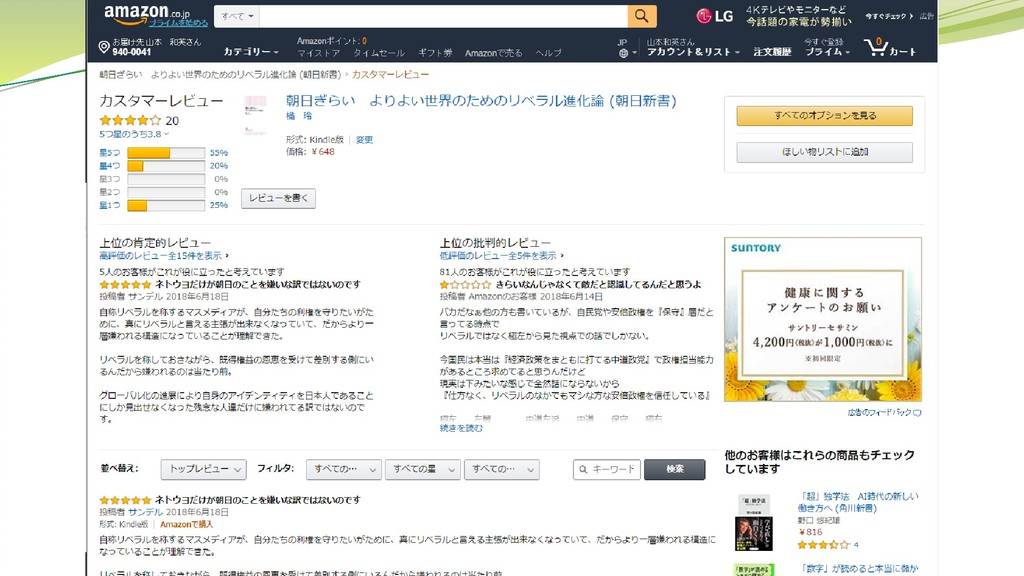
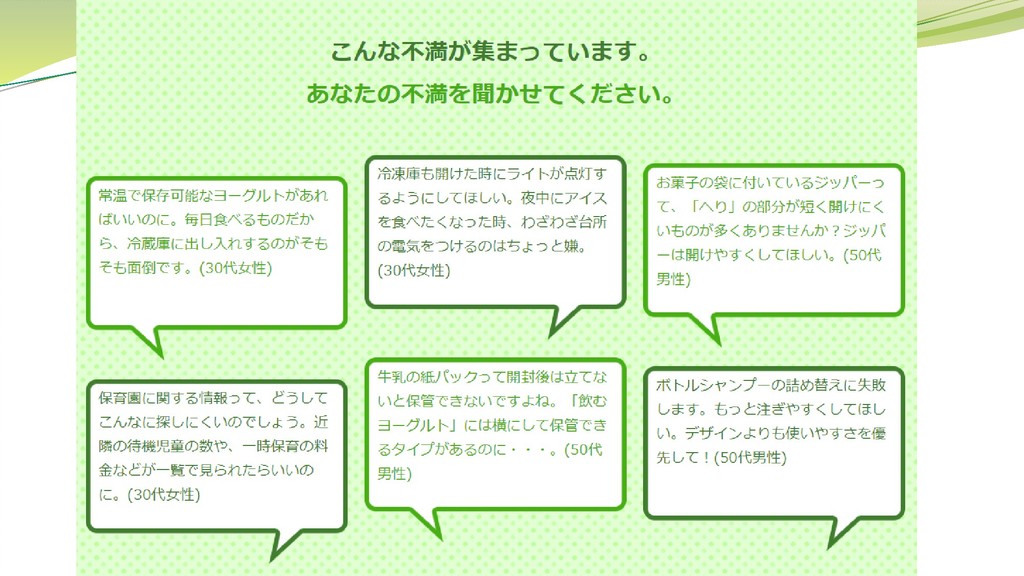
評判分析 クチコミやレビュー、アンケートなど、主観的な文章を解析して、著者の意見 や感情、その他情報などを自動的に読み取る技術 多くの場合は対象テキストが大量であることが前提 解析結果を何らかの形で取りまとめて提示 2値分類(肯定的/否定的)
特定情報のみ抽出(固有表現抽出) 高頻度語を提示
評判分析の対象 通販サイト Amazon、楽天など ソーシャルメディア FacebookやLINEは閉鎖性が高いので主に Twitter
が使われる Q&Aサイト Yahoo!知恵袋、OKWAVEなど レビューサイト 価格.com、@cosmeなど ブログサイト
何を分析するのか? 商品・サービスの注目度、話題度 言及数をカウント Twitterの場合、言及者数も計数可能 どれだけ好評か?
肯定/否定の割合を計算 商品・サービスに関連するキーワード 「花火」「限定」「サッカー」 メディア別 Twitterで特に話題になる等
None
None
None
None
None
評判分析の難しさ 高頻度=特徴語とは限らない ストップワード サクラ問題 各種表現
これでおいしくないとは言わせない おいしすぎてつらい ~店のほうが断然おいしい 客が誰もいなくて神秘的 もう来ない
None
オープンテストとクローズドテスト オープンテスト(open test) システム作成時に使ったデータ以外の入力(未知の入力)に対してシステムの性 能を評価するテスト方法。これがいわゆるシステム性能となる。 クローズドテスト(closed test)
システム作成時に何らかの形で参照したデータに対してシステムの性能を評価 するテスト方法。 通常はオープンテストを行えばよいが、クローズドテストの性能もシステム開発時の 参照として意味がある。 例えば、一般にクローズドテストの結果>オープンテストの結果なので、クローズ ドテストで低い値しか得られない時はそもそもオープンテストの意味がないなど。
交差検定(cross validation) できるだけ多くのオープンテストを行うための工 夫 データをn分割してオープンテストを繰り返す (これをn-fold cross validationと呼ぶ)
この特別な場合として、データを1件のみ訓 練から除外して交差検定を行うことをジャック ナイフ法または leave-one-out法と呼ぶ 最大限の訓練データが確保できるが、そ の一方で実験負荷が最大になる。
システム評価 出力(スイング) 非出力(見送り) 正解 (ストライク) True Positive(TP) (ホームラン) False Negative(FN)
(見逃し三振) 不正解 (ボール) False Positive(FP) (空振り三振) True Negative(TN) (ボール見送り) 各事例に対して、システムは正解と判断したもののみを出力する。
適合率、再現率、正解率 適合率(precision) 再現率(recall) 正解率(accuracy)
F-measure F-measure (F-score, F尺度)は再 現率と適合率の調和平均である。 これを変形して、
マイクロ平均とマクロ平均 マイクロ平均 マクロ平均 A社は900人面接で内定者90人 B社は100人面接で内定者50人
マイクロ平均の内定率(=内定者比率)は (90+50)/(900+100)=14% マクロ平均の内定率(=会社別平均)は (10%+50%)/2=30%
None
テキスト分析は甘くない まず何を知りたいのかを明確に 目的なく分析しても平凡な結果 しか得られない 分析には限界がある データの規模は十分か?
収集データに偏りはないか? 解析誤りがどの程度含まれる か? レポートの提出をお待ちしています。
「データの 世紀」
履修・聴講いただきありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}