Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データサイエンス12_分類.pdf
Search
自然言語処理研究室
July 02, 2018
Education
380
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データサイエンス12_分類.pdf
自然言語処理研究室
July 02, 2018
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
540
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
180
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
自然言語処理研究室 研究概要(2016年)
jnlp
0
220
Other Decks in Education
See All in Education
Soluciones al examen de Geografía 2026. JUNIO (Convocatoria Ordinaria)
juanmartin2026
1
7.1k
From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features
mfcabrera
0
220
自己紹介 / who-am-i
yasulab
6
7k
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
360
輻射安全管理系統2.0暨輻防e++學園平台說明會
aecrp
0
1.9k
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
160
アラムコSTEAMチャレンジ 実践報告書
codeforeveryone
0
190
Stardy 会社紹介資料
stardy
0
3.8k
[2026前期火5] 論理学(京都大学文学部 前期 第8回)「正規化定理の証明」
yatabe
0
250
View Manipulation and Reduction - Lecture 9 - Information Visualisation (4019538FNR)
signer
PRO
1
2.8k
現場最前線から教えるデータサイエンス1 -ITベンダーにおけるデータサイエンティスト-
hidetoshikawaguchi
0
140
2026年度春学期 統計学 第14回 分布についての仮説を検証する ― 仮説検定(1) (2026. 7. 2)
akiraasano
PRO
0
120
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
The World Runs on Bad Software
bkeepers
PRO
72
12k
The Spectacular Lies of Maps
axbom
PRO
1
880
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
300
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The agentic SEO stack - context over prompts
schlessera
0
850
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
520
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
920
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
250
Mobile First: as difficult as doing things right
swwweet
225
10k
Transcript
Data Science
今日の内容 機械学習とは データ分類手法 決定木 最近傍法
SVM
machine learning
機械学習とは データを解析して、そこから何らかの規則性や知識など、有益な情報を獲得 するアルゴリズムの総称 データは大量にあることが前提 以前からある技術だが、データの整備、計算機の性能向上など、複数の要 因が近年に重なって一気に普及した。
「ビッグデータ」時代 AIブーム 人工知能の中心的技術ではあるが、機械学習のみが人工知能ではない。
教師あり学習と教師なし学習 教師あり学習 「教師データ」(正解)を付与したデータに基づく機械学習 例:ある人にとってある本が面白いかどうかのデータ。このデータを用いて未 知の本に対して面白いかどうか(=おすすめ本)を自動判別する。 一般に高コスト、ただし手作業での情報付与とは限らない
教師なし学習 「教師データ」が付与されていないデータに基づく機械学習 (教師あり学習と比較して)データは大規模だが低精度
分類と回帰 「教師データ」も2種類に分けることができる。 分類 いくつかの選択肢の中の一つ 例:スパムメール 回帰
ある値 例:明日の最高気温
その他の機械学習 半教師あり学習 教師ありと教師なしの中間 一部のデータにのみ正解が付与されている 強化学習
正解は付与されていない アルゴリズムの出力結果がどの程度正しそうかという情報「報酬」を得ること ができる
data classification
データを分類する 分類(classification) 未知の事例に対して、予め定義されたクラスのどれに所属するかを判断する処 理 クラス数は所与 教師あり学習
クラスタリング(clustering, クラスタ分析) 事例集合に対して、何らかの基準で類似するいくつかのクラスに分類する処理 クラス数は所与または自動決定 教師なし学習
決定木(けっていぎ, Decision Tree) データを木構造の形式で分類したもの エントロピー(乱雑さ)を分類基準に考える 解釈が容易
過学習しやすい=分類性能が(それほど)高くない これへの対処もいくつか検討されている
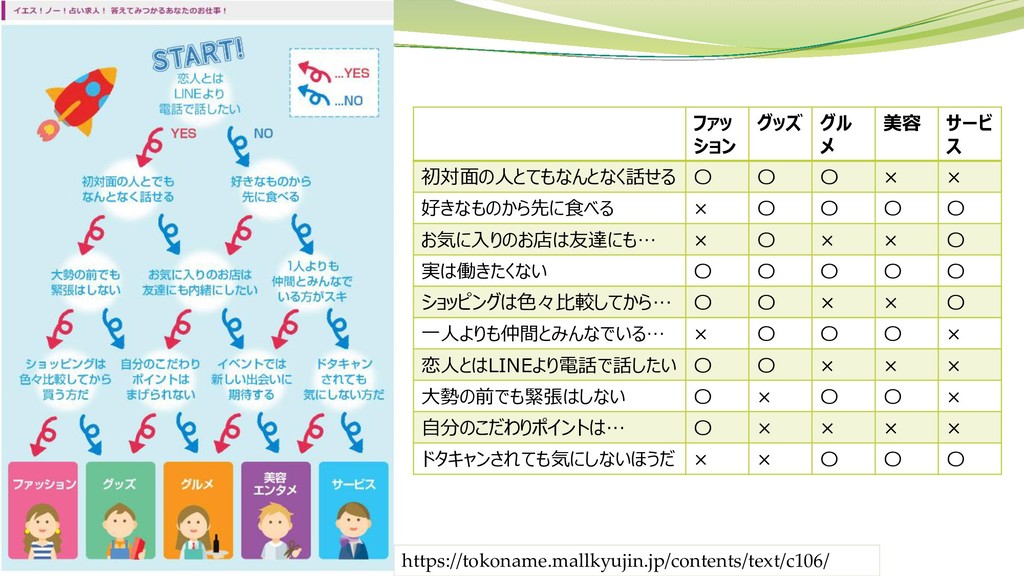
https://tokoname.mallkyujin.jp/contents/text/c106/
https://tokoname.mallkyujin.jp/contents/text/c106/ ファッ ション グッズ グル メ 美容 サービ ス 初対面の人とてもなんとなく話せる
〇 〇 〇 × × 好きなものから先に食べる × 〇 〇 〇 〇 お気に入りのお店は友達にも… × 〇 × × 〇 実は働きたくない 〇 〇 〇 〇 〇 ショッピングは色々比較してから… 〇 〇 × × 〇 一人よりも仲間とみんなでいる… × 〇 〇 〇 × 恋人とはLINEより電話で話したい 〇 〇 × × × 大勢の前でも緊張はしない 〇 × 〇 〇 × 自分のこだわりポイントは… 〇 × × × × ドタキャンされても気にしないほうだ × × 〇 〇 〇
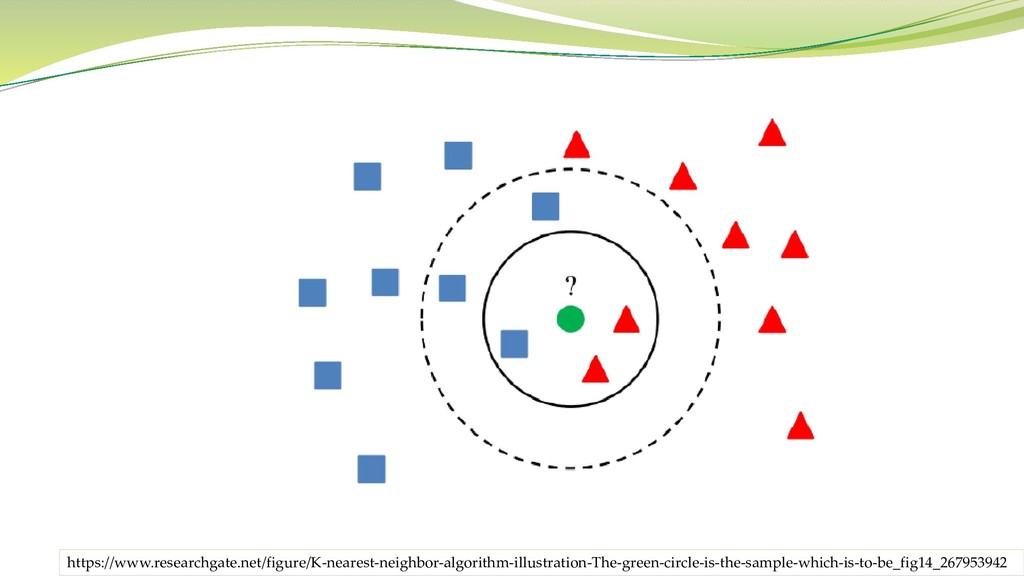
最近傍法(k近傍法, k-nearest neighbor method) 「一番近いk個のサンプルを参考にクラスを決める」クラス分類法 最も lazy な機械学習手法
kの値によって結果が変わることがある
https://www.researchgate.net/figure/K-nearest-neighbor-algorithm-illustration-The-green-circle-is-the-sample-which-is-to-be_fig14_267953942
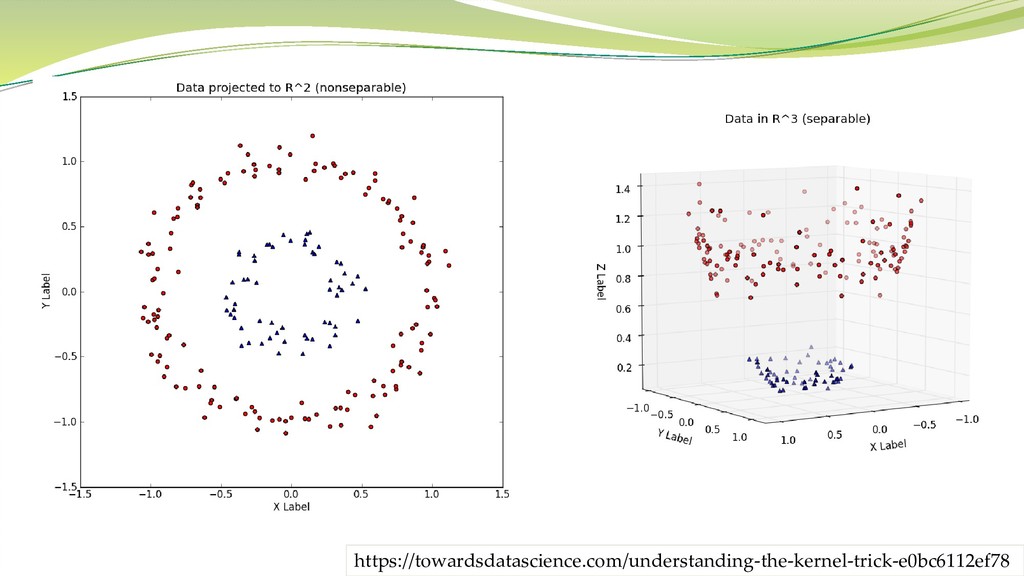
SVM(Support Vector Machine) N次元のベクトル(数値データ)を二値分類するための手法 決定木とは違って数値データのみが対象 マージン最大化
最も類似した項目(=サポートベクトル)をできるだけ明確に分類する仕組 み これはすなわち、SVMが統計的な分類手法ではないことも意味する カーネルトリック 分類しやすくするためにベクトルを高次元化するテクニック
http://www.bogotobogo.com/python/scikit-learn/scikit_machine_learning_Support_Vector_Machines_SVM.php
http://www.bogotobogo.com/python/scikit-learn/scikit_machine_learning_Support_Vector_Machines_SVM.php
https://towardsdatascience.com/understanding-the-kernel-trick-e0bc6112ef78
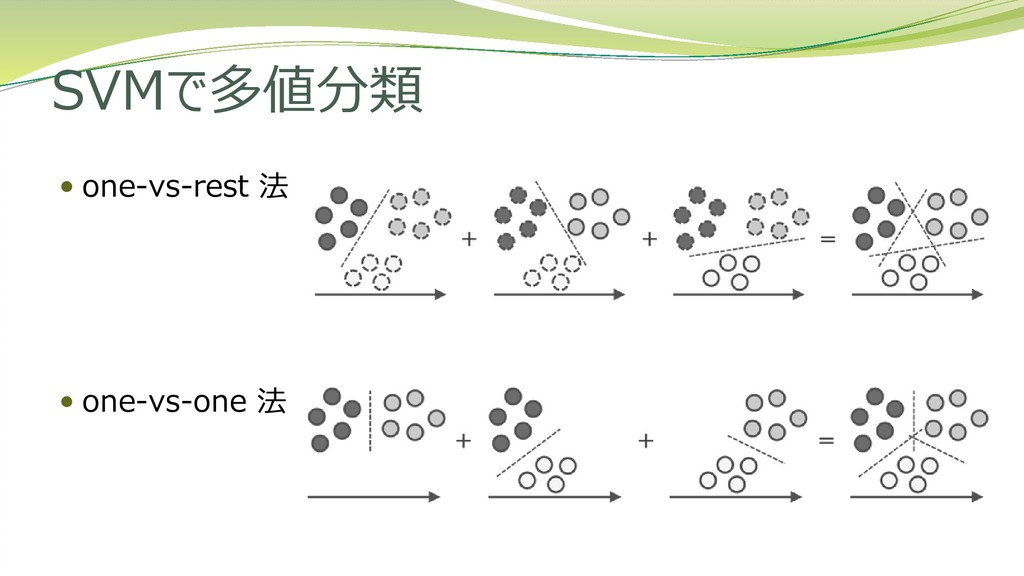
SVMで多値分類 one-vs-rest 法 one-vs-one 法
clustering
ハード/ソフトなクラスタリング ハードなクラスタリング 各事例はただ一つのクラスに属する ソフトなクラスタリング 各事例が複数のクラスに属することが許されている
クラスタリングの分類 凝集型(agglomerative) 事例数=クラス数が初期状態 だんだん凝集することでクラス数が減少していく 分割型(divisive)
初期状態は全事例が同一のクラスに所属する だんだん分割することでクラス数が増加していく
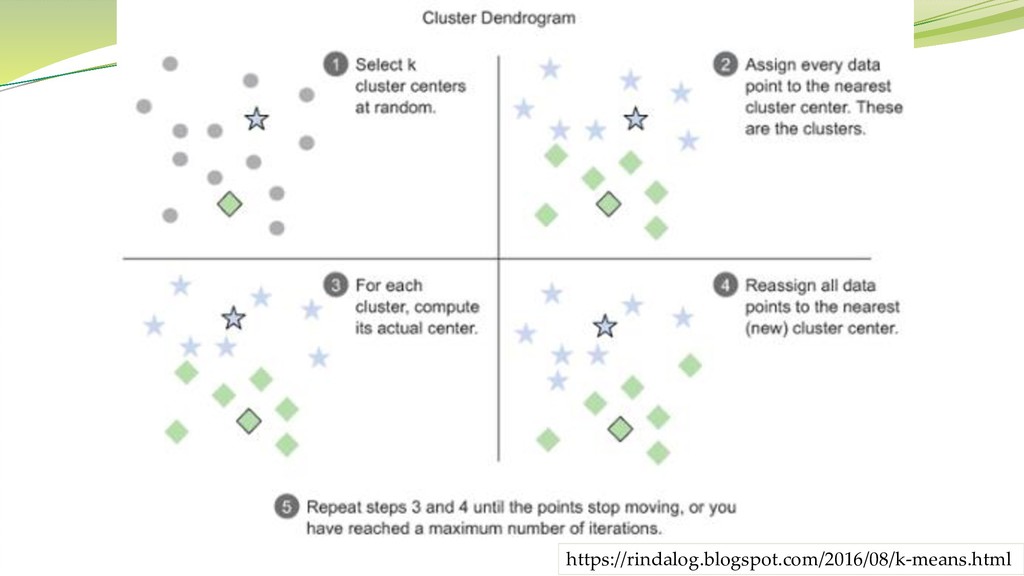
K-means (k平均法)アルゴリズム シンプルで効率的なクラスタリングアルゴリズム 初期シードを与え、収束するまで反復処理を繰り返す(次ページ)。 O(kn) (k:クラス数、n:事例数)の類似度比較を行う。通常、収束するま での反復処理の回数は非常に少ない。
問題:初期シードの与え方によって一般に結果が異なる。 対策1:シードを変えていろいろやってみる。 対策2:シードの与え方を少しまじめに考える。
https://rindalog.blogspot.com/2016/08/k-means.html
階層的凝集クラスタリング 初期化:すべての事例を異なったクラスに割り当てる 反復処理:最も類似度が高い2クラスを求め、それらを併合(1クラス 化)する。これを繰り返す。 終了条件:すべてが一つのクラスになるまで。 併合履歴はそのまま二分木になる
階層的凝集クラスタリング(続き) 類似度計算方法: 単一リンク:各事例対の類似度の中の最大値 完全リンク:各事例対の類似度の中の最小値 平均リンク:各事例対の類似度の平均値
重心:クラスの中心間の類似度
類似度とは何? ユークリッド距離:空間上の2点間の距離 , = ( − )2
コサイン類似度:ベクトルの角度(のコサイン値)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}