• I’ll be showing extremely easy algorithms No learning aspect to these algorithm, that is, they don’t form a model of the data. You can implement these on the train home.
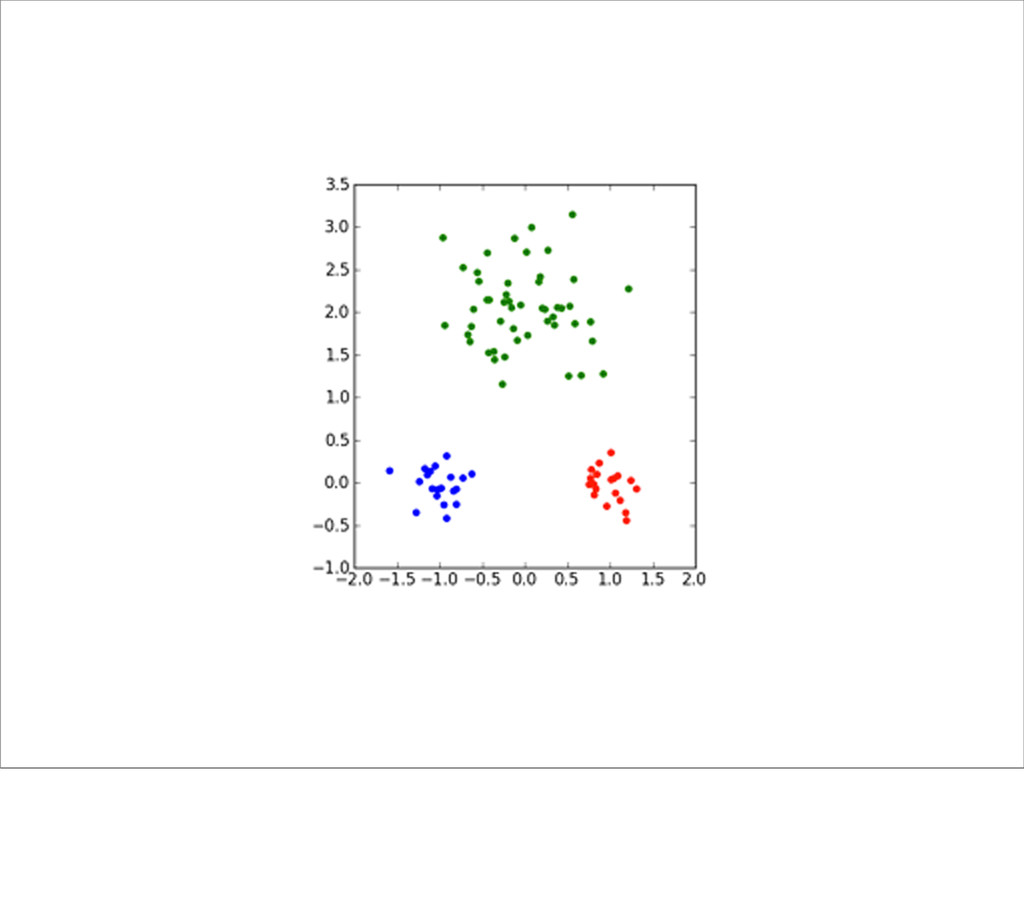
it looks like a duck, swims like a duck and quacks like a duck, then it probably is a duck. Important thing to note here is that you need a training set which already is labelled. Example problem: determine the origin of a wine from its chemical compound.
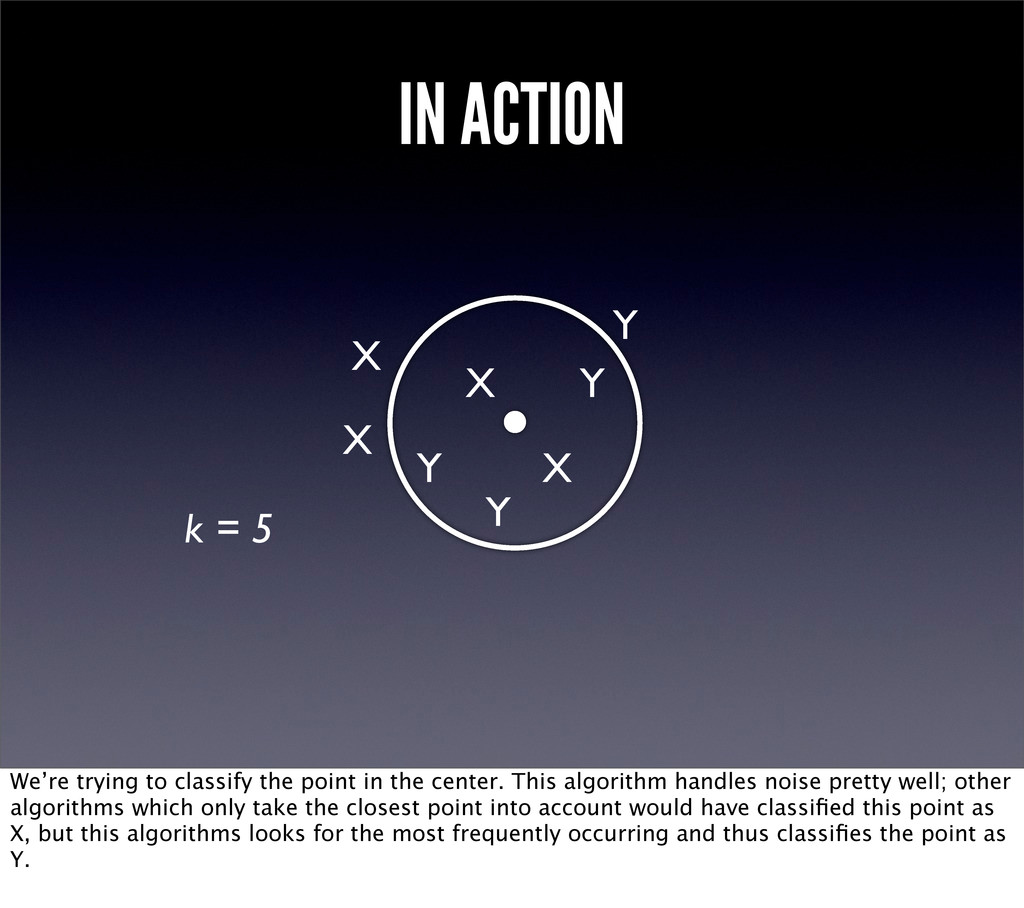
k = 5 We’re trying to classify the point in the center. This algorithm handles noise pretty well; other algorithms which only take the closest point into account would have classified this point as X, but this algorithms looks for the most frequently occurring and thus classifies the point as Y.
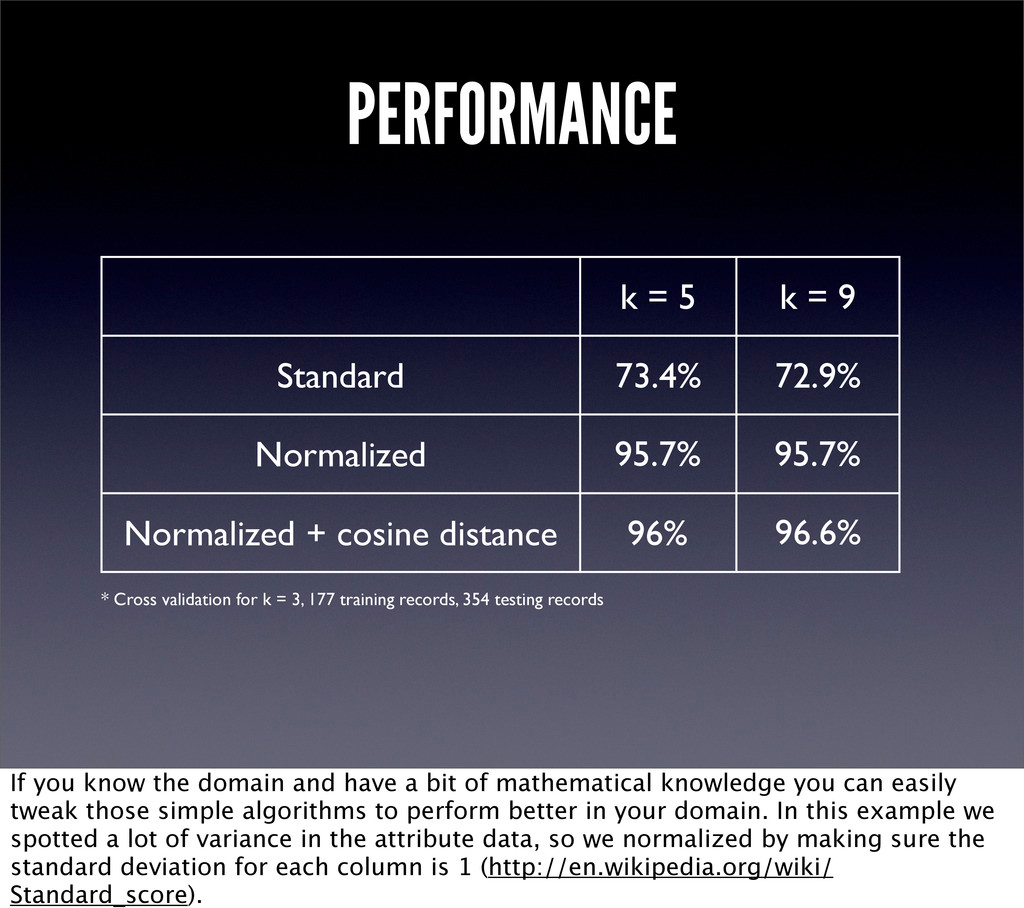
Normalized Normalized + cosine distance * Cross validation for k = 3, 177 training records, 354 testing records 96% 96.6% 95.7% 95.7% If you know the domain and have a bit of mathematical knowledge you can easily tweak those simple algorithms to perform better in your domain. In this example we spotted a lot of variance in the attribute data, so we normalized by making sure the standard deviation for each column is 1 (http://en.wikipedia.org/wiki/ Standard_score).
Incomplete data Decision trees Time complexity Space complexity Over fitting Under fitting Association rule discovery Preprocessing Regression Anomaly detection Visualization Naive Bayes Neural networks Support vector machines I only covered a small part. Lots of things to learn to become a data mining expert.
by Tan, Steinbach and Kumar • UC Irvine Machine Learning Repository http://archive.ics.uci.edu/ml/ • github.com/joelcox/miner Orange is a GUI application and Python package. Book is probably on of the better academic books I’ve seen, lots of examples. You can use the UC repository for testing data (but preferably your own data!). Also include links to relevant papers. Miner is a toy package, implements both algorithms covered in this talk (not too pretty).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}