◦ Focus on Computer Vision ◦ Some Expertise in NLP • M.Sc. in Computer Science at TU Berlin • Hugging Face Fellow ◦ Leading CV Study Group on discord: https://huggingface.co/join/discord ◦ Past Study Groups: https://github.com/huggingface/community-events/ tree/main/computer-vision-study-group @[email protected] linkedin.com/in/johko @johko990 huggingface.co/johko
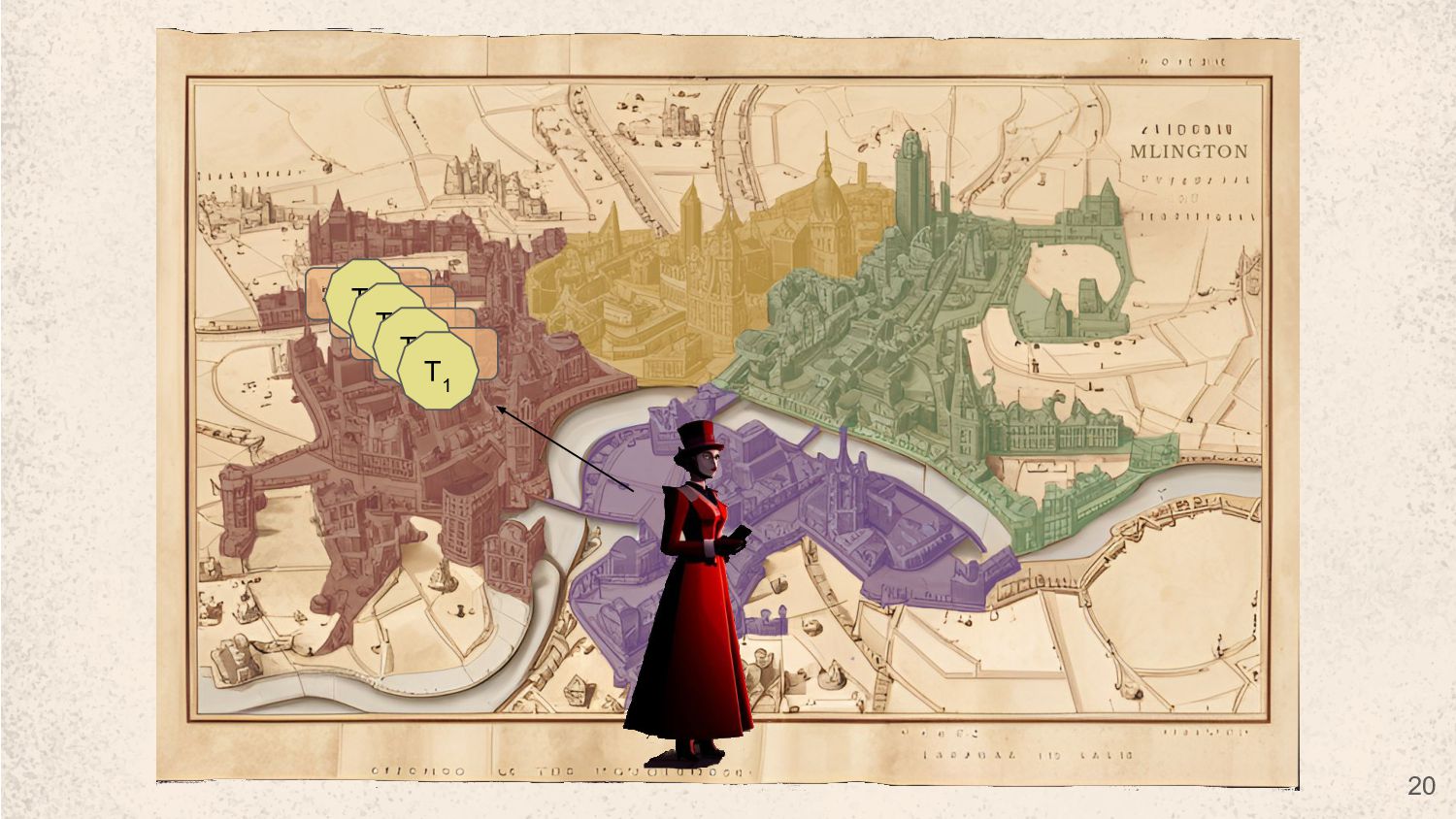
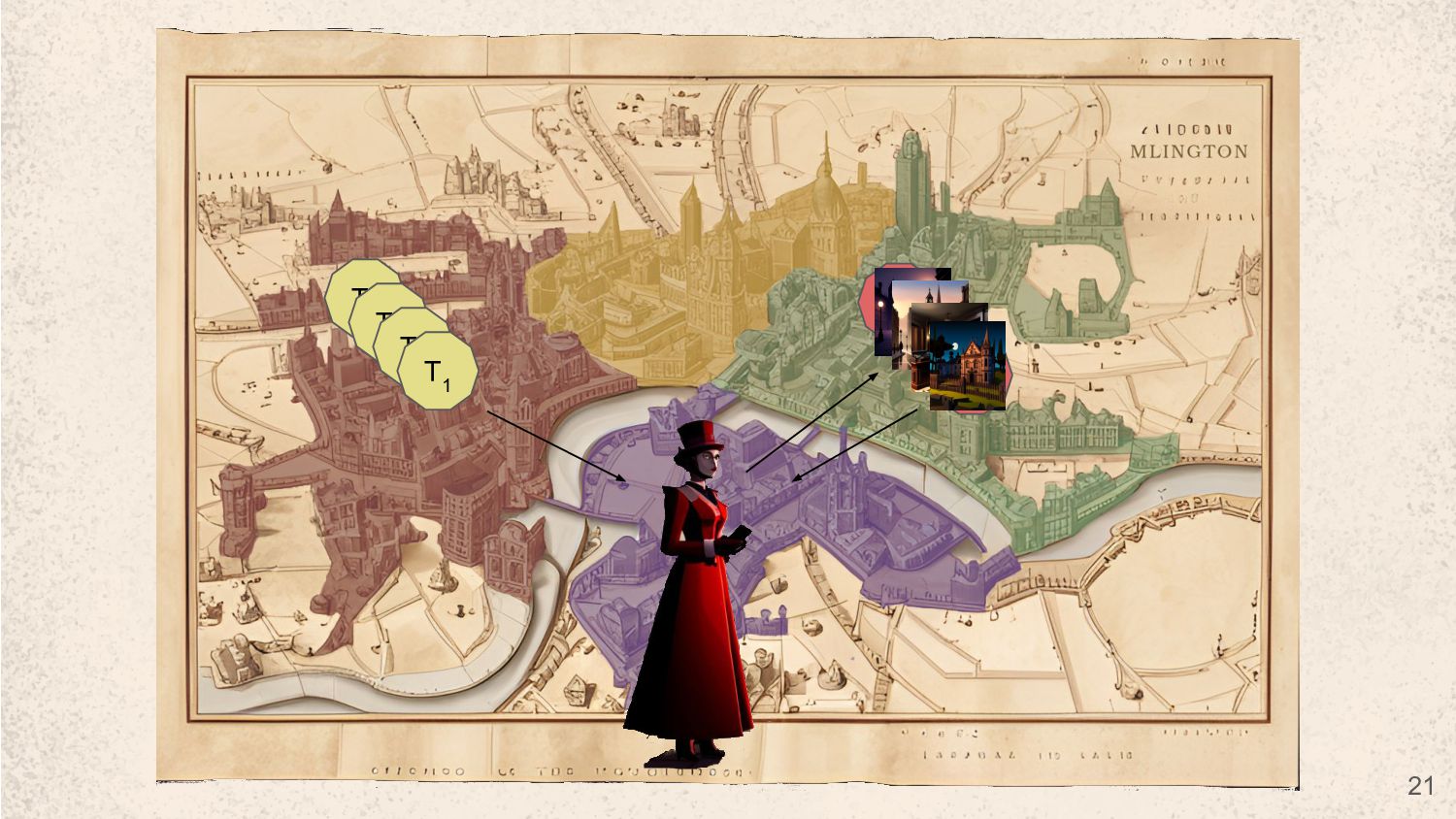
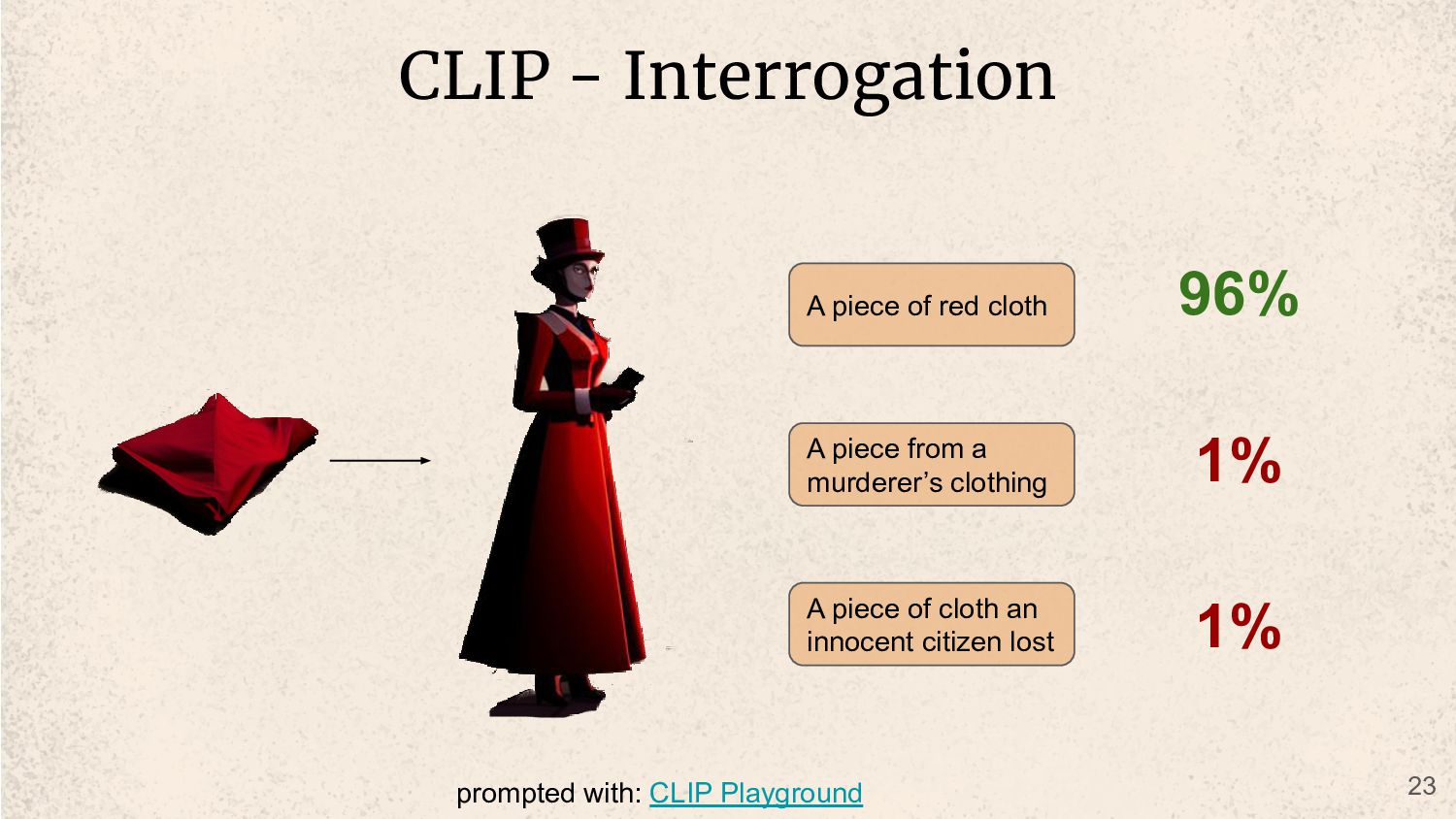
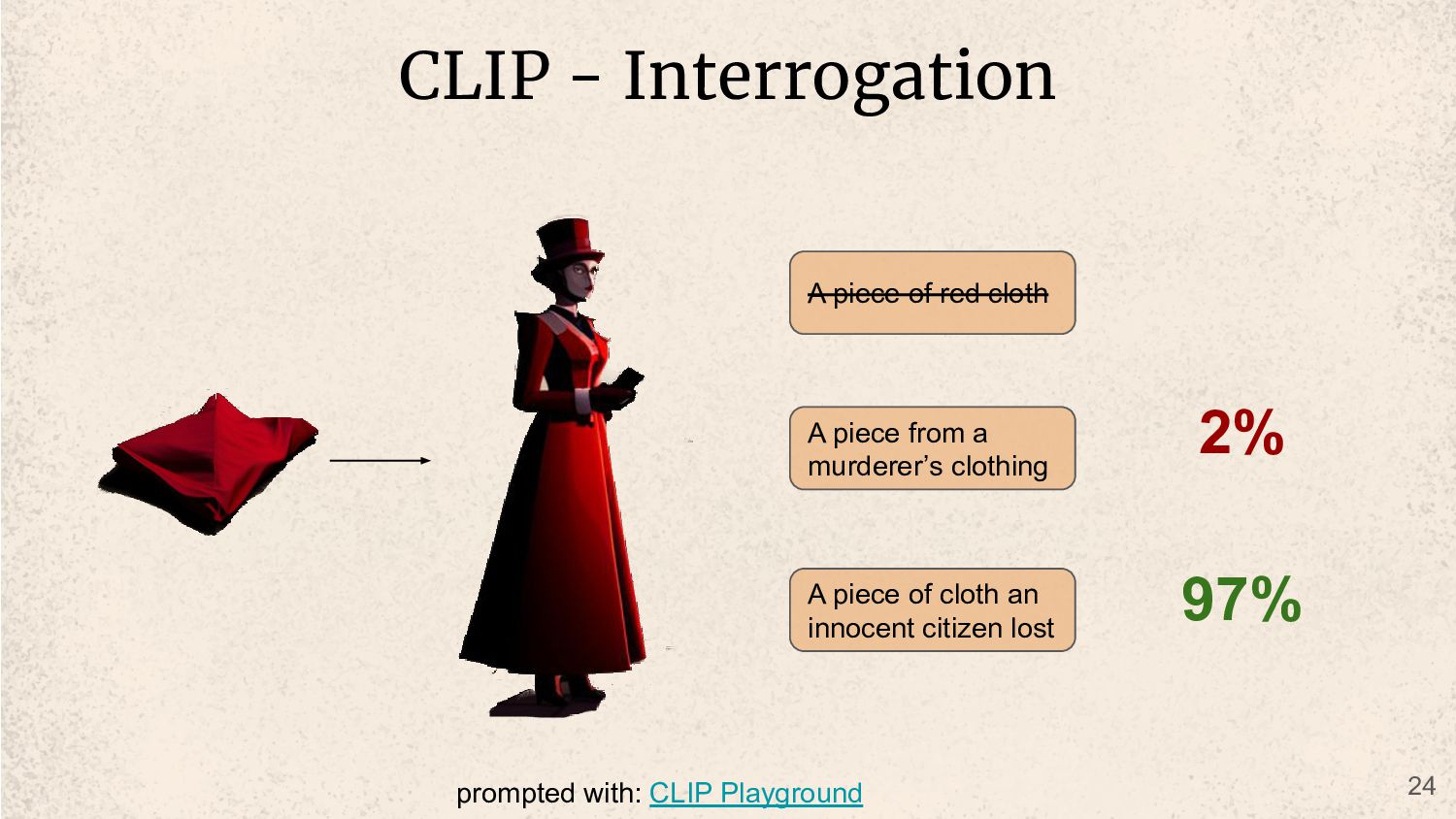
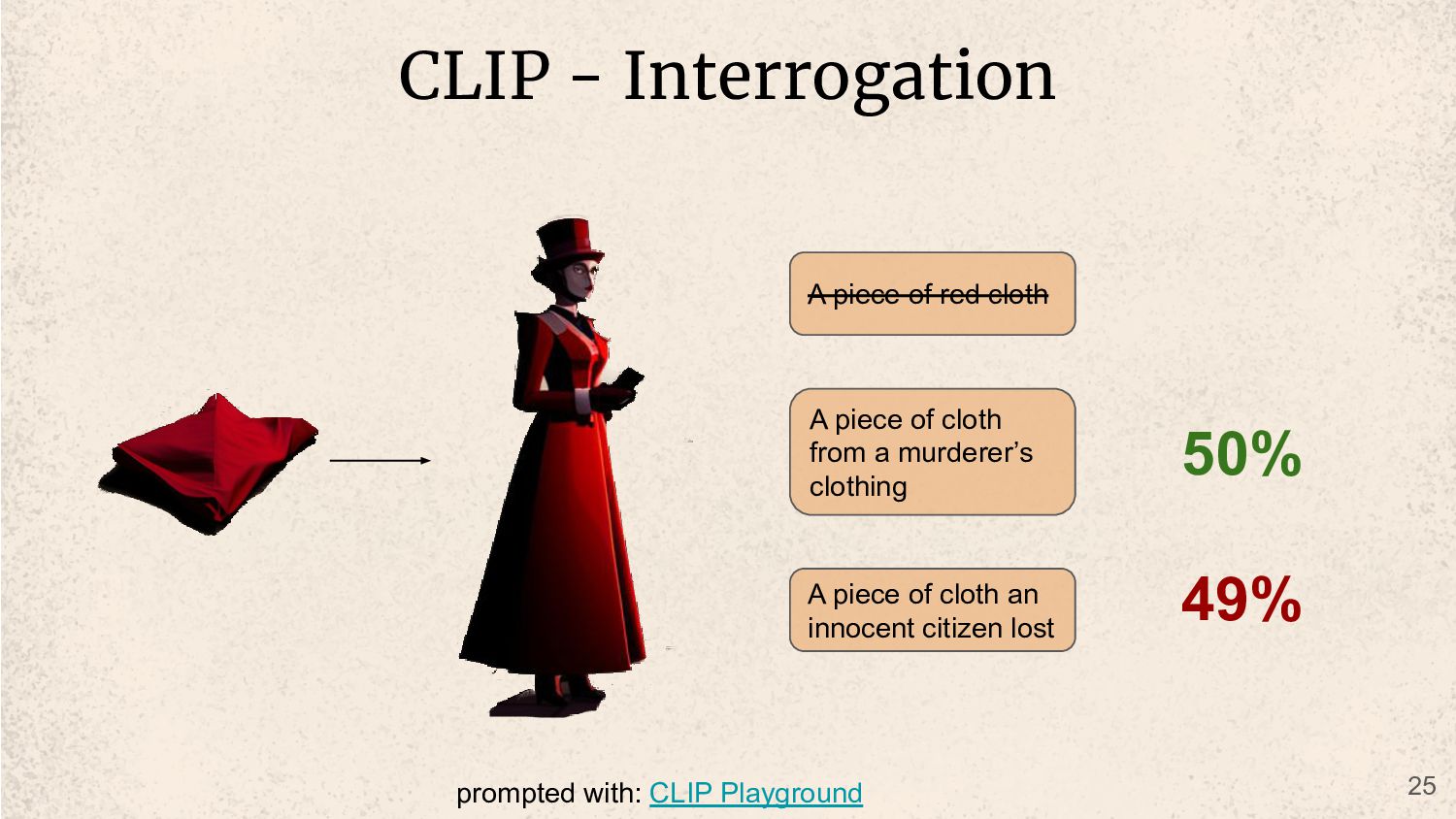
street in victorian era london at night an old manor in the woods a busy city street in victorian era at day time inside a fancy victorian era shop a dark city street in victorian era london at night an old manor in the woods a busy city street in victorian era at day time 9% 85% 1% 60% 18
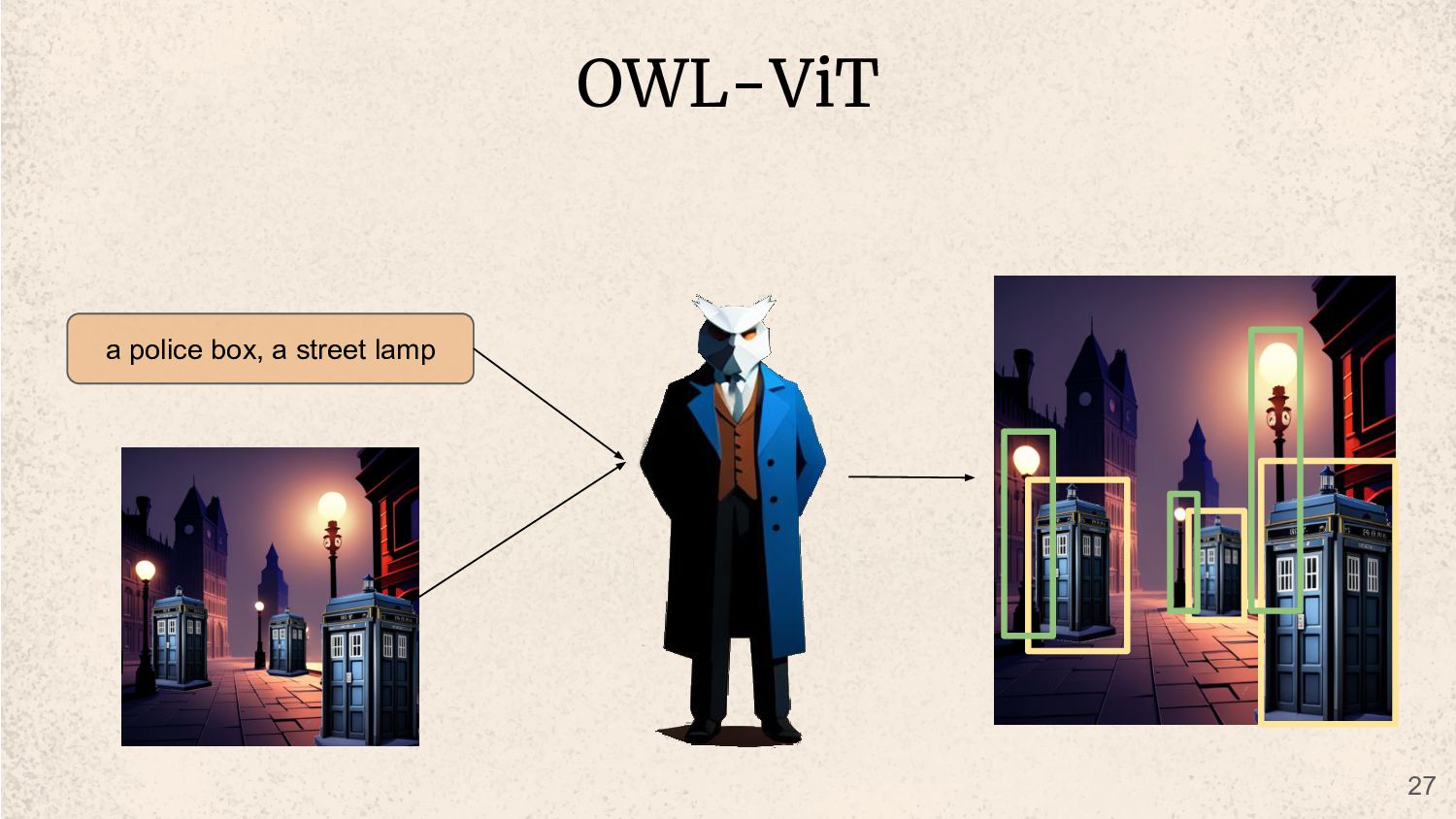
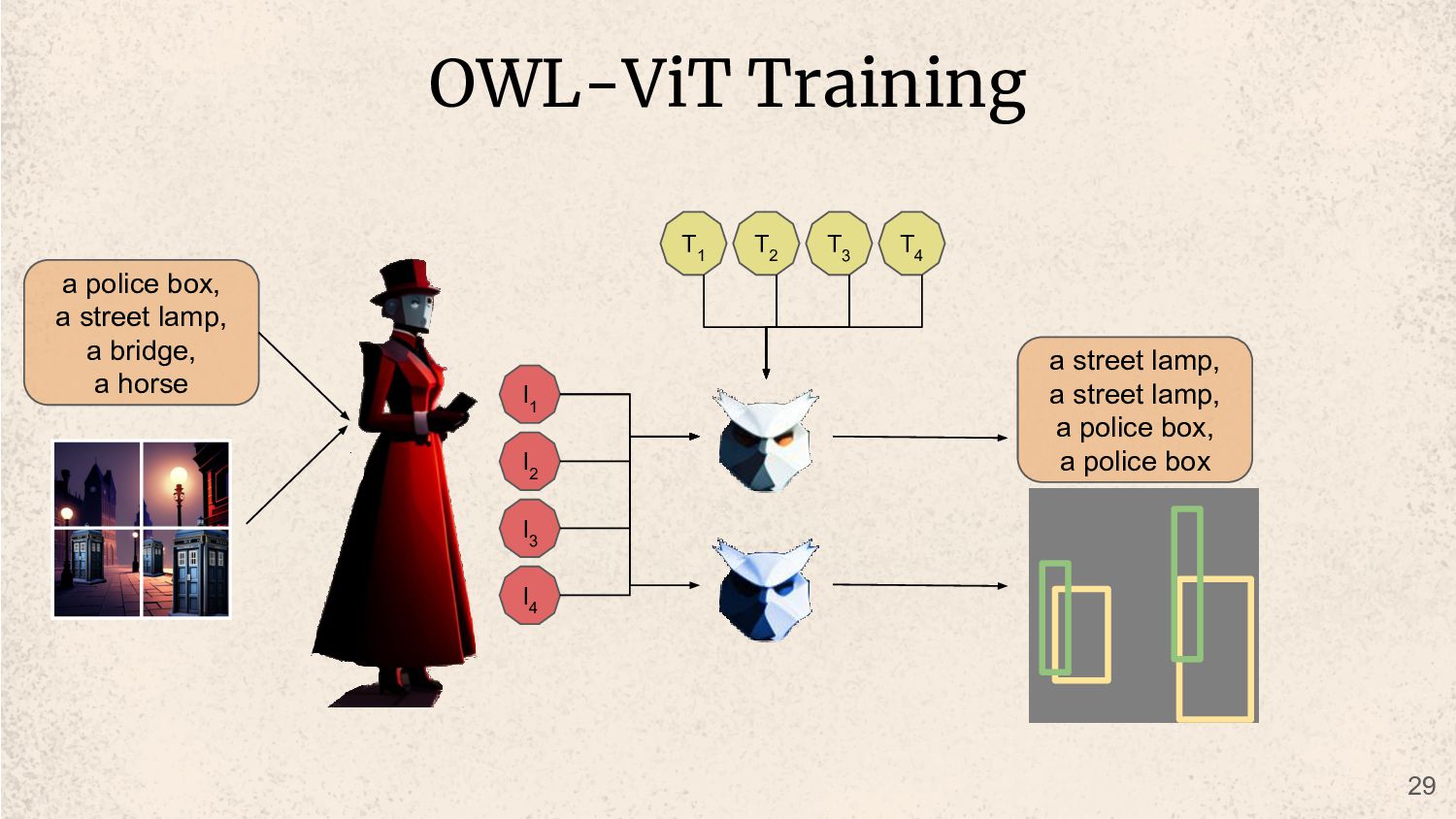
a bridge, a horse inside a fancy victorian era shop a dark city street in victorian era london at night an old manor in the woods a busy city street in victorian era at day time 28
CLIPProcessor, CLIPModel model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw) inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True) outputs = model(**inputs) logits_per_image = outputs.logits_per_image # this is the image-text similarity score probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the probabilities 44
predictions [batch_size, 2] target_sizes = torch.Tensor([image.size[::-1]]) # Convert outputs (bounding boxes and class logits) to COCO API results = processor.post_process(outputs=outputs, target_sizes=target_sizes) i = 0 # Retrieve predictions for the first image for the corresponding text queries text = texts[i] boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"] score_threshold = 0.1 for box, score, label in zip(boxes, scores, labels): box = [round(i, 2) for i in box.tolist()] if score >= score_threshold: print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}") 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}