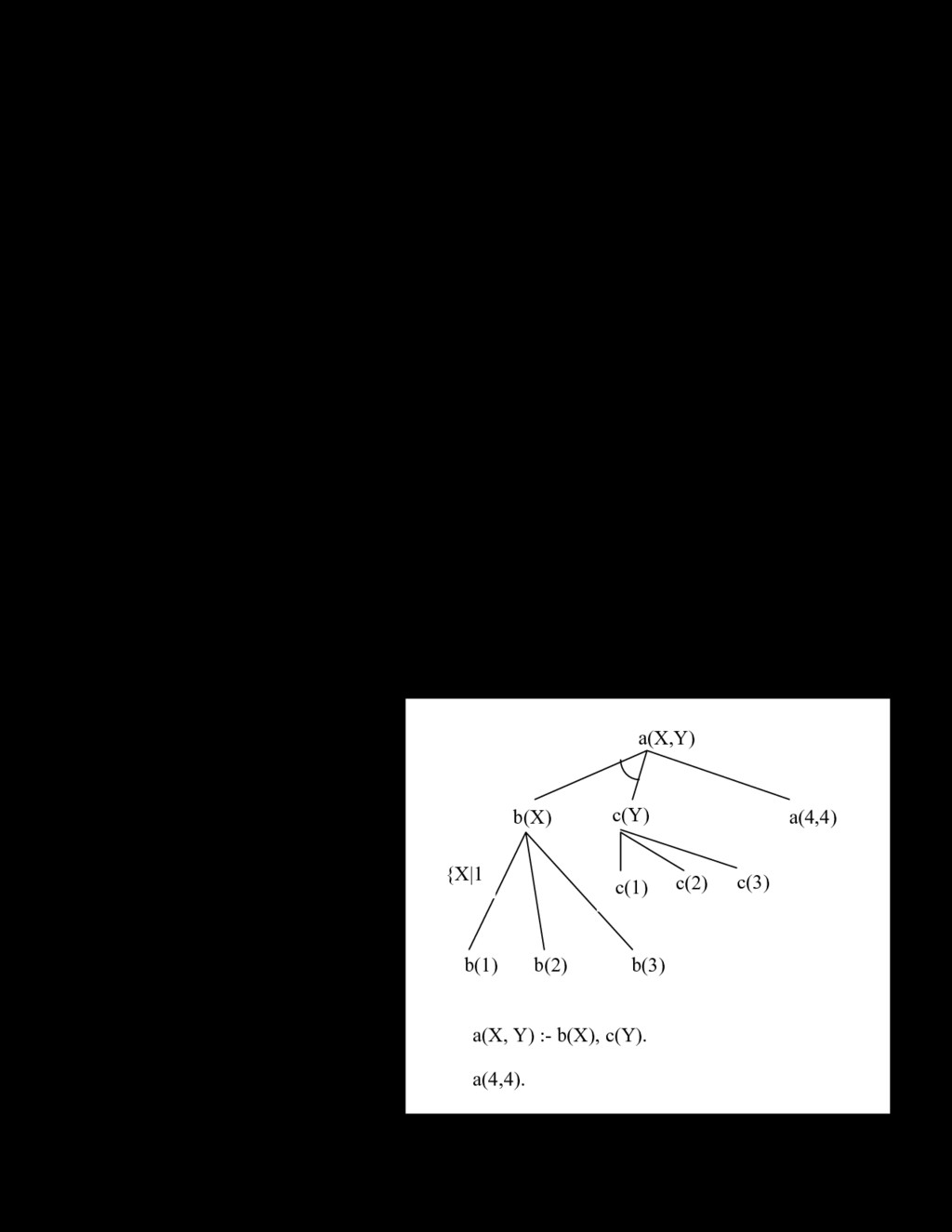
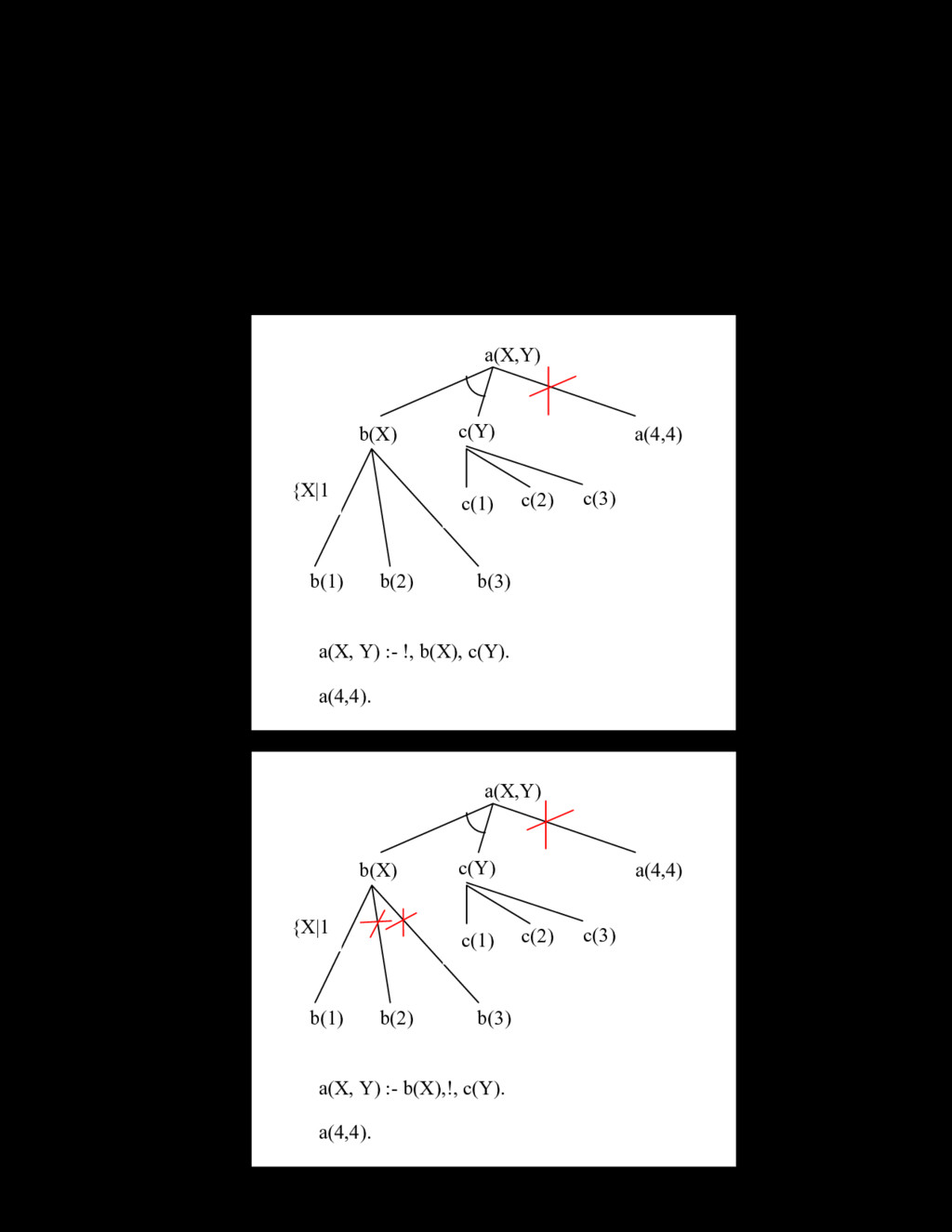
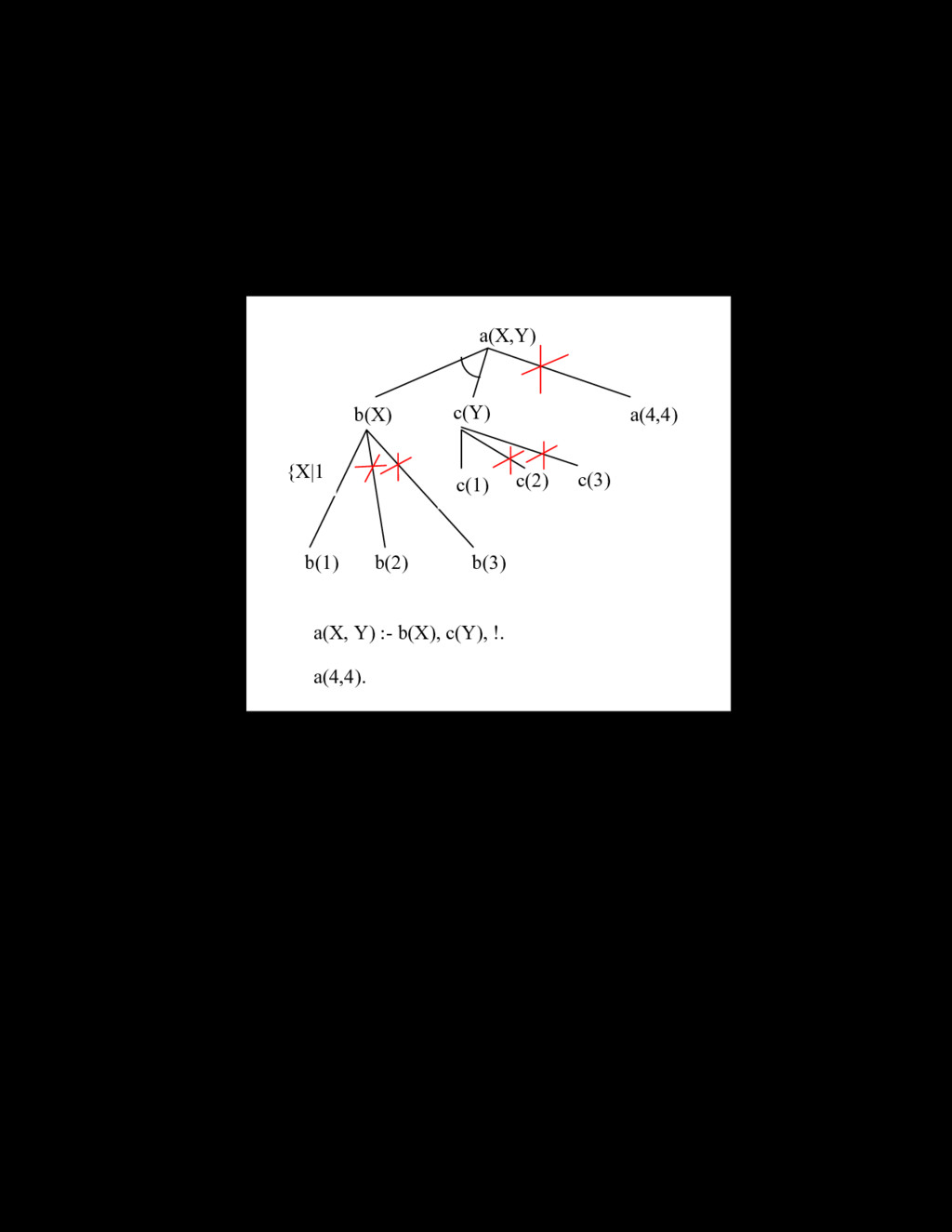
= [a, b, c, d, e, f] Để hiểu rõ thêm về danh sách, chúng ta xét ví dụ sau: hãy viết chương trình đảo ngược danh sách. my_reverse([],[]). my_reverse([H|T],L):- my_reverse(T,R),append(R,[H],L). Câu truy vấn có thể là: 1 ? – my_reverse([a,b,c,d],Y). Y=[d,c,b,a] Ví dụ tiếp theo là sắp xếp danh sách theo thứ tự tăng dần. Để giải bài toán này, chúng ta sẽ xây dựng vị từ có hai tham số sapxep(X,Y), với X là danh sách cần sắp xếp, Y là kết quả danh sách đã sắp xếp. Trong ví dụ dưới đây, ta sử dụng giải thuật sắp xếp theo kiểu chèn, sử dụng biến trung gian sapxep (X,Y):-i_sort(X,[],Y). i_sort([],Y,Y). i_sort([H|T],Z,Y):-insert(H,Z,Y1),i_sort(T,Y1,Y). insert(X,[Y|T],[Y|NT]):-X>Y,insert(X,T,NT). insert(X,[Y|T],[X,Y|T]):-X=<Y. insert(X,[],[X]). 8. Thuật toán suy diễn trong Prolog
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![giỏi] VÀ …VÀ [Yến là sinh viên thì Yến học](https://files.speakerdeck.com/presentations/5da051a7810d41b6a02925020f6f9f8a/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 ? – append([a,b,c],[d,e,f],X). % nối hai danh sách X](https://files.speakerdeck.com/presentations/5da051a7810d41b6a02925020f6f9f8a/slide_105.jpg){kind=link}
{kind=link}
{kind=link}