. , Ak ∈ Rm×n Output: Invertible matrices (L, R) ∈ GL(m) × GL(n) such that ˜ Ai := LAi R⊤ satisfy k i=1 ˜ Ai ˜ A⊤ i = 1 m Im , k i=1 ˜ A⊤ i ˜ Ai = 1 n In . • Generalization of matrix scaling [Sinkhorn 1964] (popular in ML to approx OT) • Edmonds’ problem [Gurvits 2004; Garg, Gurvits, Oliveira, Wigderson 2020] • Brascamp–Lieb inequality [Garg, Gurvits, Oliveira, Wigderson 2018] • Tyler’s M-estimator [Franks, Moitra 2020], covariance estimation for matrix normal distribution [Dutilleul 1999; Drton, Kuriki, Hoff 2021] 4 / 19
matrix scaling [Sinkhorn 1964] ˜ A(2t+1) i = L ˜ A(2t) i where L satisfies L k i=1 ˜ A(2t) i ˜ A(2t)⊤ i L⊤ = Im m ˜ A(2t+2) i = ˜ A(2t+1) i R⊤ where R satisfies R k i=1 ˜ A(2t+1)⊤ i ˜ A(2t+1) i R⊤ = In n L, R can be easily computed by Cholesky or matrix square roots 5 / 19
matrix scaling [Sinkhorn 1964] ˜ A(2t+1) i = L ˜ A(2t) i where L satisfies L k i=1 ˜ A(2t) i ˜ A(2t)⊤ i L⊤ = Im m ˜ A(2t+2) i = ˜ A(2t+1) i R⊤ where R satisfies R k i=1 ˜ A(2t+1)⊤ i ˜ A(2t+1) i R⊤ = In n L, R can be easily computed by Cholesky or matrix square roots Theorem (Gurvits (2004)) If a solution to operator scaling exists, the operator Sinkhorn iteration ( ˜ A(t) i ) converges to a solution. 5 / 19
d matrix with i.i.d. standard normal entries L: d × d1 matrix, R: d × d2 matrix The distribution of L⊤GR is called the matrix normal distribution. Its covariance matrix is Σ2 ⊗ Σ1 , where Σ1 := R⊤R, Σ2 := L⊤L. L⊤ G ∼ N(0, 1) R 6 / 19
d matrix with i.i.d. standard normal entries L: d × d1 matrix, R: d × d2 matrix The distribution of L⊤GR is called the matrix normal distribution. Its covariance matrix is Σ2 ⊗ Σ1 , where Σ1 := R⊤R, Σ2 := L⊤L. L⊤ G ∼ N(0, 1) R Given data A1 , . . . , Am , the log-likelihood function is ℓ(Σ1 , Σ2 ) = − 1 2 tr m i=1 Σ−1 2 A⊤ i Σ−1 1 Ai − d2 2 log det Σ1 − d1 2 log det Σ2 + const. • With the change of variables (X, Y ) ← (Σ−1 1 , Σ−1 2 ), finding a stationary point of log-likelihood ℓ is equivalent to operator scaling. • Operator Sinkhorn iteration was previously known as the flip-flop algorithm [Dutilleul 1999]. 6 / 19
via overrelaxation • Depending on the parameter space where overrelaxation is applied, we propose three methods: Cholesky-OR, PD-OR, and Geodesic-OR • They extend overrelaxation acceleration for Sinkhorn iteration in matrix scaling [Thibault, Chizat, Dossal, Papadakis 2021; Oseledets, Rakhuba, Uschmajew 2023] • Prove global linear convergence of Geodesic-OR • Analyze local convergence rates of the proposed methods and derive an explicit formula for the optimal relaxation parameter 7 / 19
1 √ m Chol−1 k i=1 Ai R⊤ t Rt A⊤ i , Rt+1 = 1 √ n Chol−1 k i=1 A⊤ i L⊤ t+1 Lt+1 Ai Proposed Method 1 (Cholesky-OR) Lt+1 = (1 − ω)Lt + ω √ m Chol−1 k i=1 Ai R⊤ t Rt A⊤ i , Rt+1 = (1 − ω)Rt + ω √ n Chol−1 k i=1 A⊤ i L⊤ t+1 Lt+1 Ai 10 / 19
also a solution for any orthogonal Q. =⇒ It is convenient to work with SPD matrices (X, Y ) = (L⊤L, R⊤R). Operator Sinkhorn (in (L, R) vars) Lt+1 = 1 √ m Chol−1 k i=1 Ai R⊤ t Rt A⊤ i , Rt+1 = 1 √ n Chol−1 k i=1 A⊤ i L⊤ t+1 Lt+1 Ai Operator Sinkhorn (in (X, Y ) vars) Xt+1 = S1 (Yt ) := 1 m k i=1 Ai Yt A⊤ i −1 , Yt+1 = S2 (Xt+1 ) := 1 n k i=1 A⊤ i Xt+1 Ai −1 . 11 / 19
also a solution for any orthogonal Q. =⇒ It is convenient to work with SPD matrices (X, Y ) = (L⊤L, R⊤R). Operator Sinkhorn (in (L, R) vars) Lt+1 = 1 √ m Chol−1 k i=1 Ai R⊤ t Rt A⊤ i , Rt+1 = 1 √ n Chol−1 k i=1 A⊤ i L⊤ t+1 Lt+1 Ai Operator Sinkhorn (in (X, Y ) vars) Xt+1 = S1 (Yt ) := 1 m k i=1 Ai Yt A⊤ i −1 , Yt+1 = S2 (Xt+1 ) := 1 n k i=1 A⊤ i Xt+1 Ai −1 . Proposed Method 2 (PD-OR) Xt+1 = (1 − ω)Xt + ωS1 (Yt ), Yt+1 = (1 − ω)Yt + ωS2 (Xt+1 ) 11 / 19
(Fisher–Rao) metric yields a Hadamard manifold [Bhatia 2009; Boumal 2023]. Geodesic from X to Y γ(ω) = X#ω Y := X1/2(X−1/2Y X−1/2)ωX1/2 Xt = γ(0) S1 (Yt ) = γ(1) Xt+1 = γ(ω) Instead of a simple affine combination in linear space, take an “affine combination” along the geodesic: Proposed Method 3 (Geodesic-OR) Xt+1 = Xt #ω S1 (Yt ), Yt+1 = Yt #ω S2 (Xt+1 ) 12 / 19
the operator Sinkhorn iteration, the optimal ω is given by ωopt = 2 1 + 1 − β2 . Practice: Use an empirical estimate ˆ β2 obtained from the first (say) 10 iterations: ˆ β2 = err(A(10)) err(A(9)) , ω = 2 1 + 1 − ˆ β2 . err(A(t)): residual after t iterations 14 / 19
via overrelaxation • Depending on the parameter space where overrelaxation is applied, we propose three methods: Cholesky-OR, PD-OR, and Geodesic-OR • They extend overrelaxation acceleration for Sinkhorn iteration in matrix scaling [Thibault, Chizat, Dossal, Papadakis 2021; Oseledets, Rakhuba, Uschmajew 2023] • Prove global linear convergence of Geodesic-OR • Analyze local convergence rates of the proposed methods and derive an explicit formula for the optimal relaxation parameter 19 / 19
convex cone. The cone C induces a partial order ≤C on Rd: x ≤C y ⇐⇒ y − x ∈ C. 68 ! u 0 ! u = {ru ; r > 0} dH (u,u 0 ) Figure 4.7: Left: the Hilber vizualization of the contracti It can be shown to be means that ∃r > 0, u naming “projective”). dH(u, u ) = 0 if and on distance on bounded o is a complete metric s the Hilbert metric on norm between vectors [Peyré, Cuturi 2019] Definition (Hilbert metric) dH (x, y) = log M(y/x) m(y/x) defines a distance between rays in C (the Hilbert metric for C), where M(y/x) = inf{α ≥ 0 : y ≤C αx}, m(y/x) = sup{β ≥ 0 : y ≥C βx}. 2 / 4
+ (cone of symmetric positive semidefinite matrices). • X ≤C Y ⇐⇒ X ⪯ Y . • dH (X, Y ) = log κ(XY −1). κ(·) = condition number • Positivity improving ⇐⇒ Φ(C) ⊆ int C Φ(X) = k i=1 Ai XA⊤ i , Φ∗(Y ) = k i=1 A⊤ i Y Ai . Theorem (Birkhoff–Hopf) A positivity improving CP map Φ is a contraction with respect to dH : there exists Λ(Φ) ∈ (0, 1) such that dH (Φ(X), Φ(Y )) ≤ Λ(Φ)dH (X, Y ) holds. Moreover, the same contraction factor holds for Φ∗. 3 / 4
{kind=link}
{kind=link}
{kind=link}
![Operator Scaling [Gurvits 2004] Input: Matrices A1 , . .](https://files.speakerdeck.com/presentations/8b803082521540dc9b06a5beace8b475/slide_3.jpg){kind=link}
![Operator Sinkhorn Iteration [Gurvits 2004] Generalization of Sinkhorn iteration for](https://files.speakerdeck.com/presentations/8b803082521540dc9b06a5beace8b475/slide_4.jpg){kind=link}
![Operator Sinkhorn Iteration [Gurvits 2004] Generalization of Sinkhorn iteration for](https://files.speakerdeck.com/presentations/8b803082521540dc9b06a5beace8b475/slide_5.jpg){kind=link}
![Application: Covariance Estimation [Drton, Kuriki, Hoff 2021] G: d ×](https://files.speakerdeck.com/presentations/8b803082521540dc9b06a5beace8b475/slide_6.jpg){kind=link}
![Application: Covariance Estimation [Drton, Kuriki, Hoff 2021] G: d ×](https://files.speakerdeck.com/presentations/8b803082521540dc9b06a5beace8b475/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
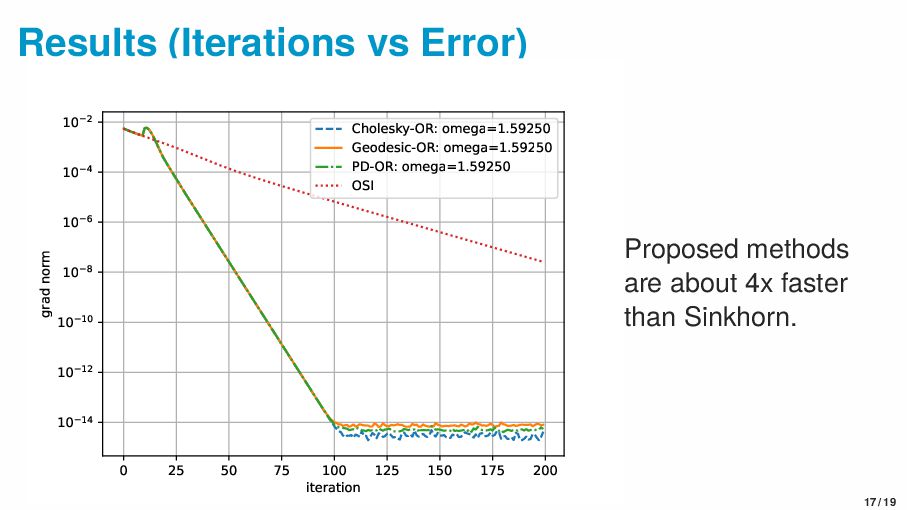{kind=link}
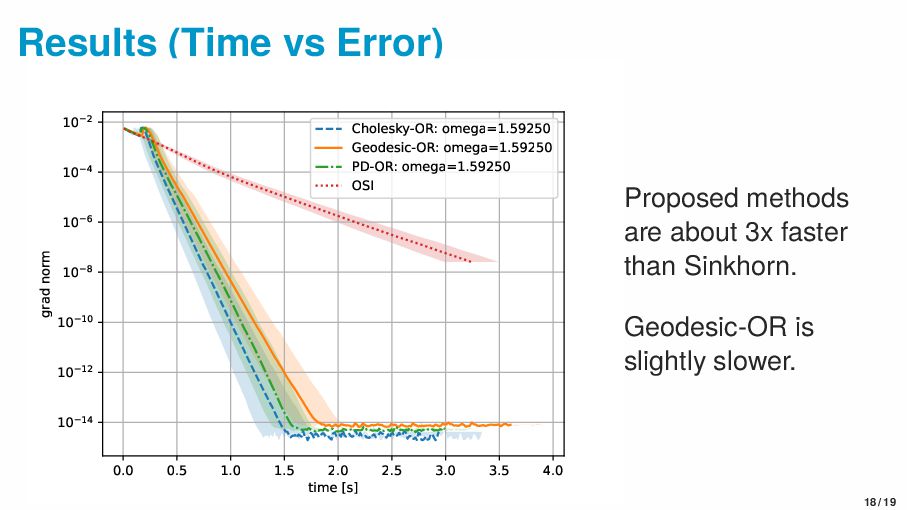{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}