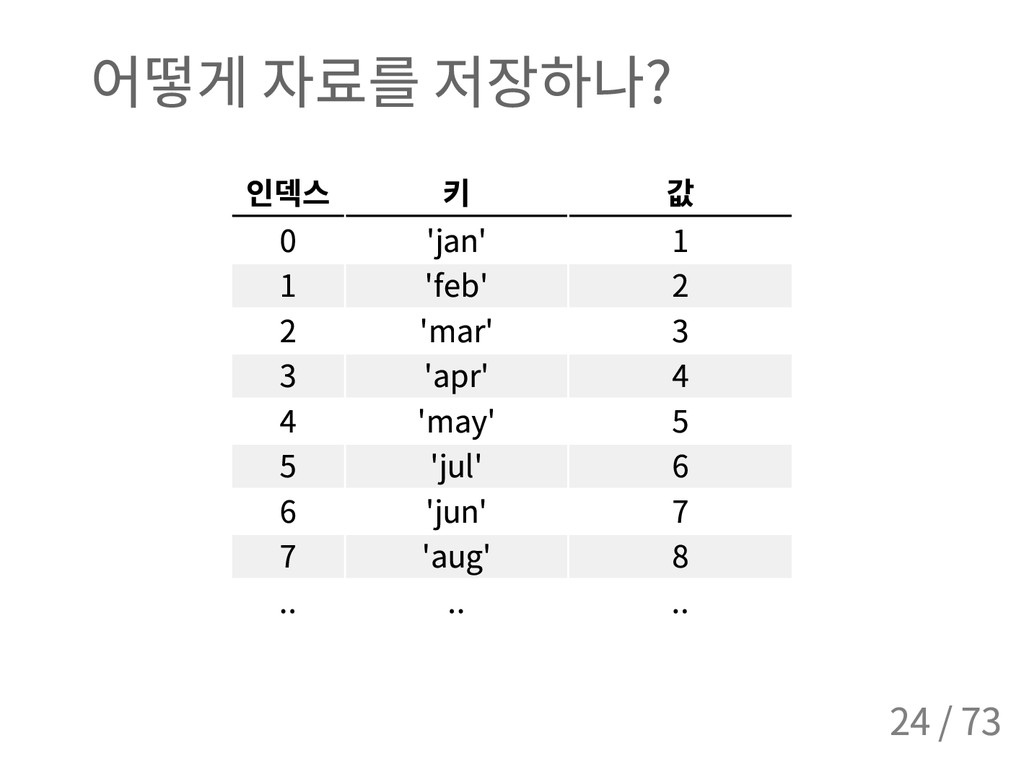
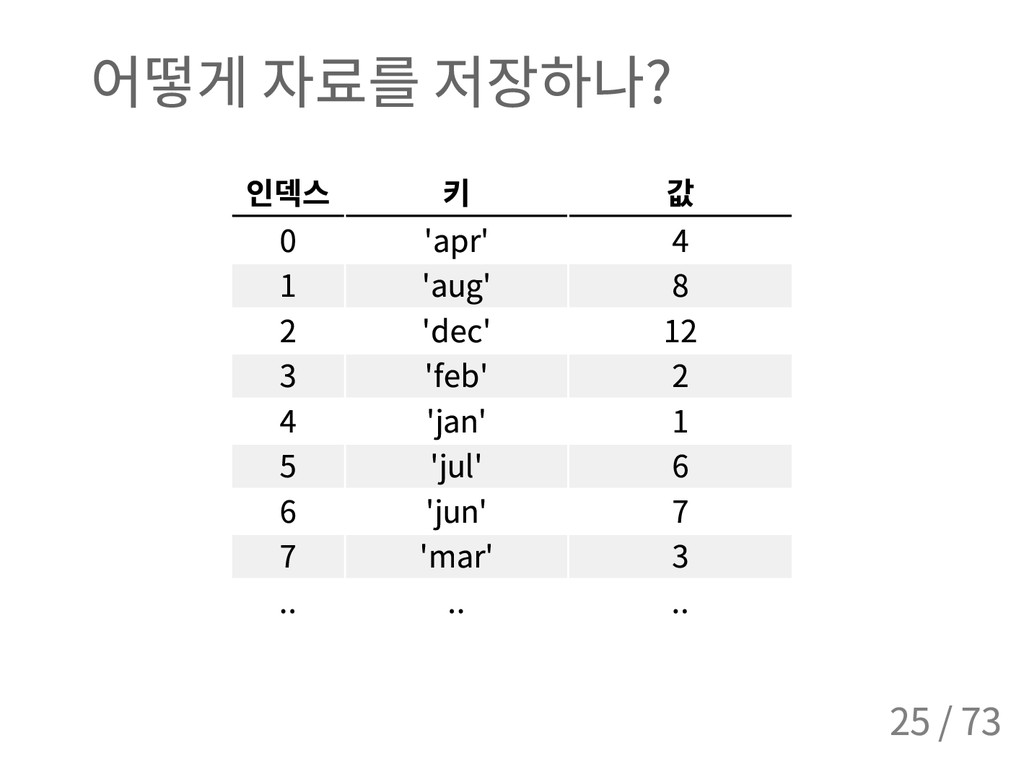
{ ' j a n ' : 1 , ' f e b ' : 2 , ' m a r ' : 3 , . . . } { ' a p r ' : 4 , ' a u g ' : 8 , ' d e c ' : 1 2 , ' f e b ' : 2 , . . } # d i c t ( ) 의 키워드 인자 > > > d i c t ( j a n = 1 , f e b = 2 , m a r = 3 , a p r = 4 , . . ) { ' a p r ' : 4 , ' a u g ' : 8 , ' d e c ' : 1 2 , ' f e b ' : 2 , . . } # ( k e y , v a l u e ) 쌍의 목록으로 만들기 > > > m o n t h _ n a m e s = [ ( ' j a n ' , 1 ) , ( ' f e b ' , 2 ) , ( ' m a r ' , 3 ) , ( ' a p r ' , 4 ) , ( ' m a y ' , 5 ) , ( ' j u n ' , 6 ) , . . ] > > > d i c t ( m o n t h _ n a m e s ) { ' a p r ' : 4 , ' a u g ' : 8 , ' d e c ' : 1 2 , ' f e b ' : 2 , . . } 7 / 73
![{ : 'awesome'} 구종만 [email protected] 1 / 73](https://files.speakerdeck.com/presentations/b530482012cd0132c2f91a02e52fa712/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
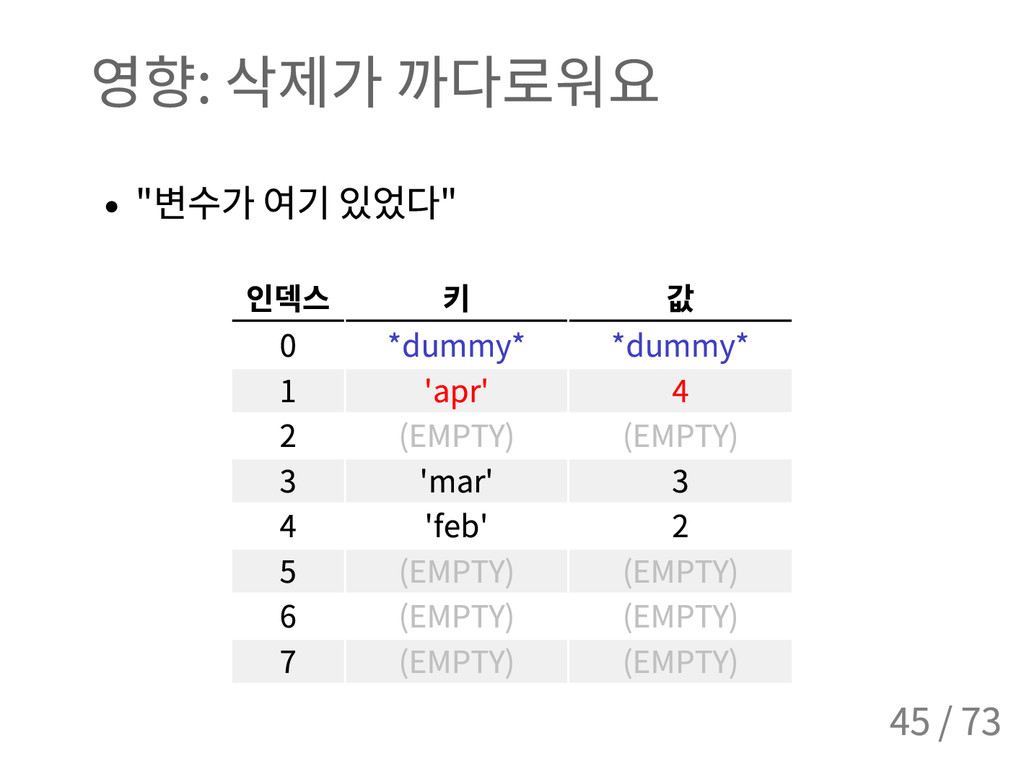{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
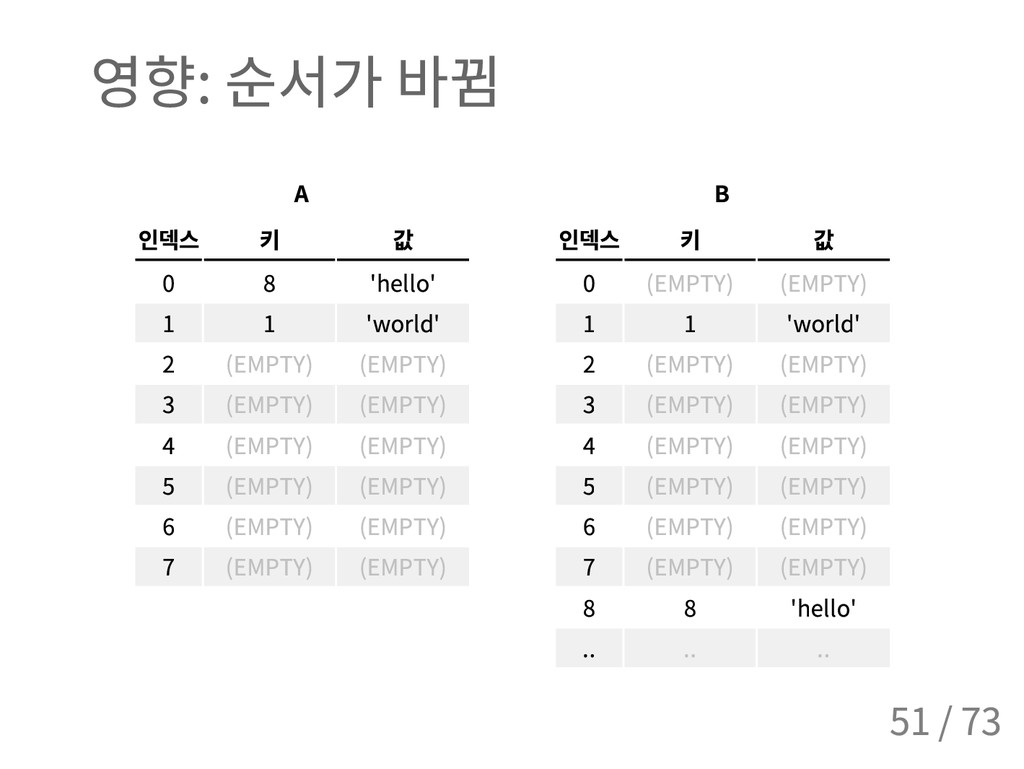{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}