services at DigitalOcean • Observations from across the industry: • What are the most innovative and successful companies doing? • How can we leverage what they are doing to enable ourselves to innovate faster? @prometheus 3
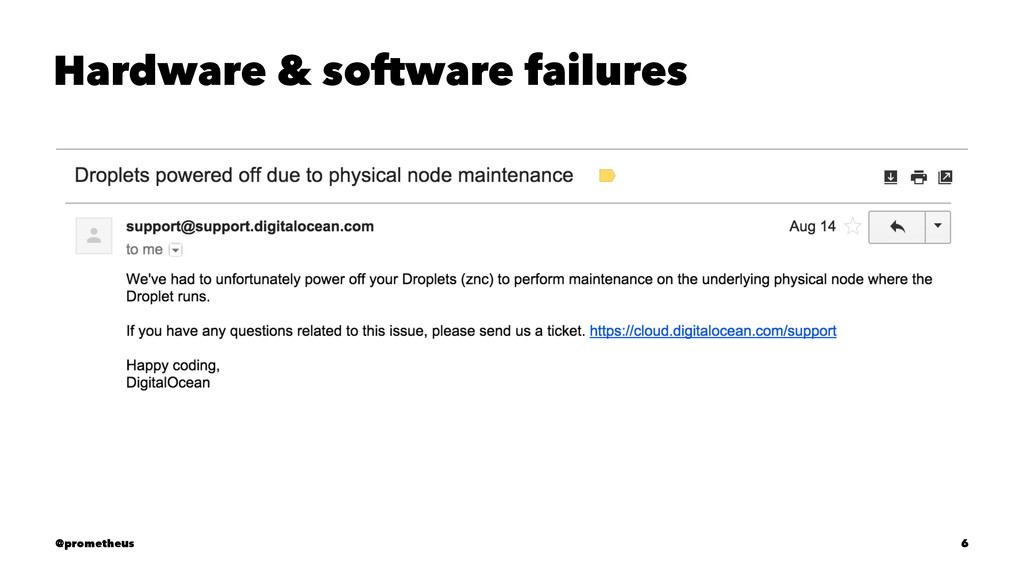
Easily forgotten, until that one business critical thing they were responsible for does not happen. • When it comes to operations, they are finicky at best. @prometheus 5
annualized failure rates higher than 4%. Different deployments have reported between 1.2 and 16 average server-level restarts per year. — Barroso and Hölzle in “The Data Center as a computer” @prometheus 7
deployed to a single server • Over time you break things down in to different components • Coordinating them becomes increasingly more involved • Is this really the business you are in? @prometheus 8
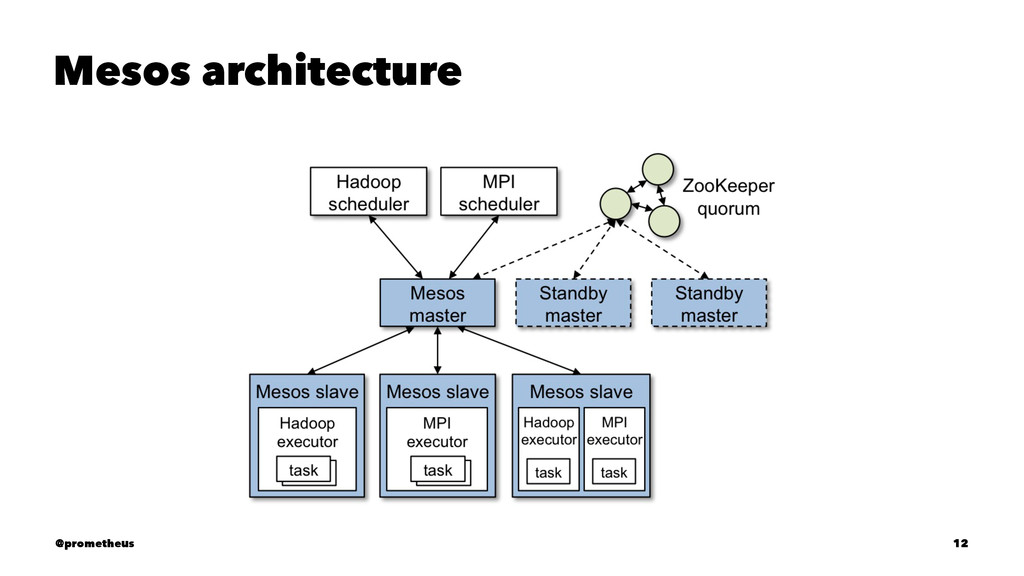
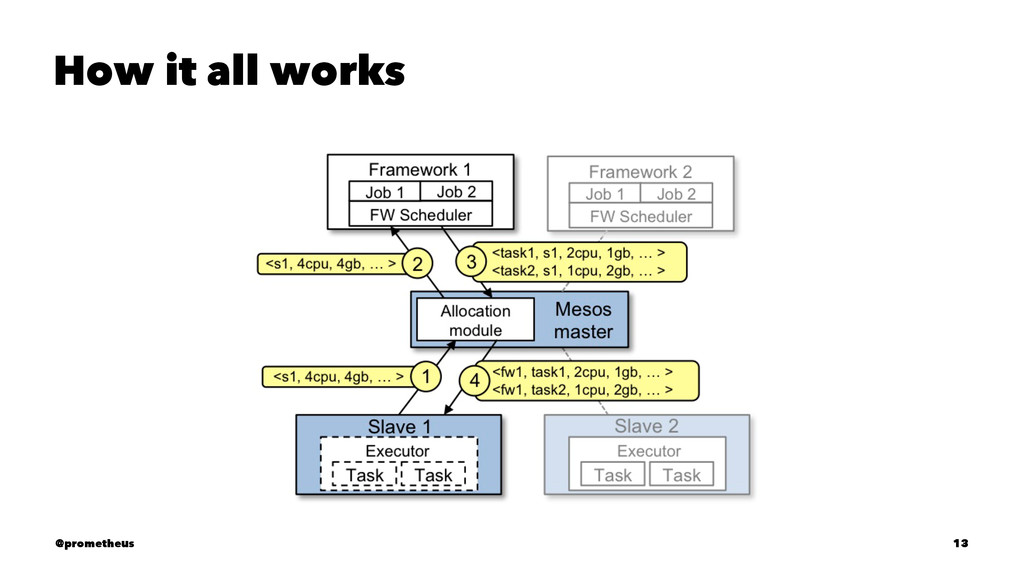
the most indispensable component of the cluster-level infrastructure layer. It controls the mapping of user tasks to hardware resources, enforces priorities and quotas, and provides basic task management services. A more useful version should present a higher level of abstraction, automate allocation of resources, and allow resource sharing at a finer level of granularity. — Barroso and Hölzle in “The Data Center as a computer” @prometheus 9
servers • Do you care about where it runs or that it just runs? • Think in resources instead of servers • Do you care about where it runs or what it needs to run? @prometheus 10
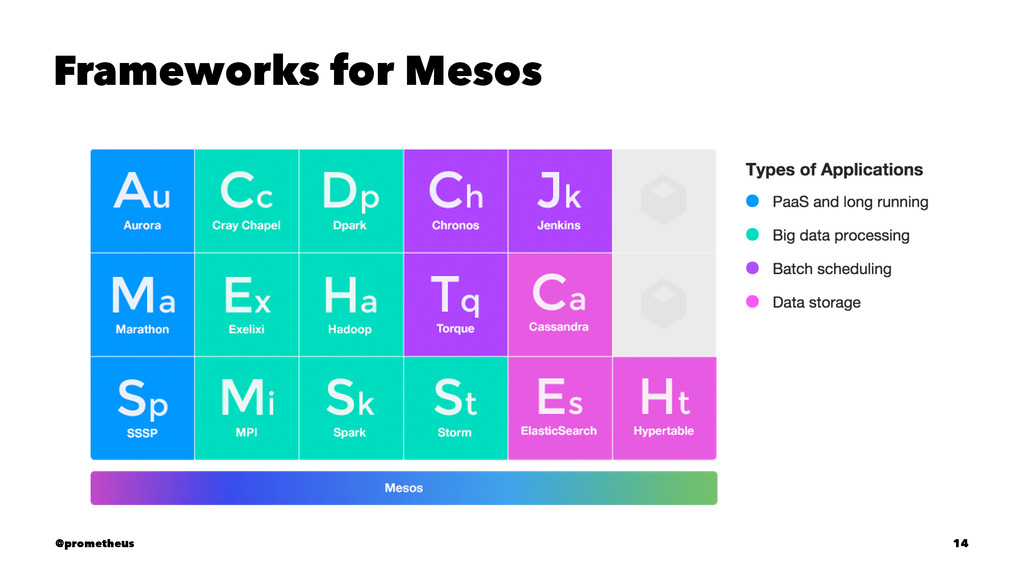
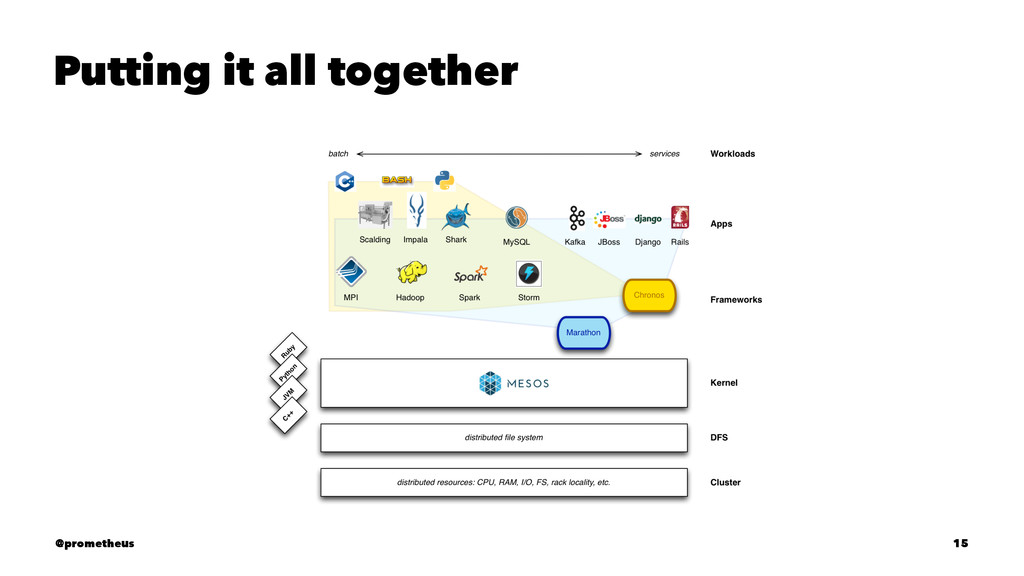
compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively. Mesos runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elastic Search) with API’s for resource management and scheduling across entire datacenter and cloud environments. @prometheus 11
• Speed wins in the marketplace • Remove friction from product development • High trust, low process, no hand-offs between teams • Freedom and responsibility culture • Don’t do your own undifferentiated heavy lifting • Use simple patterns automated by tooling • Self service makes impossible things instant @prometheus 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“The Data Center as a computer” [Resource Management] is perhaps](https://files.speakerdeck.com/presentations/d2da3bb0523501327aec02fb58ce8c77/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}