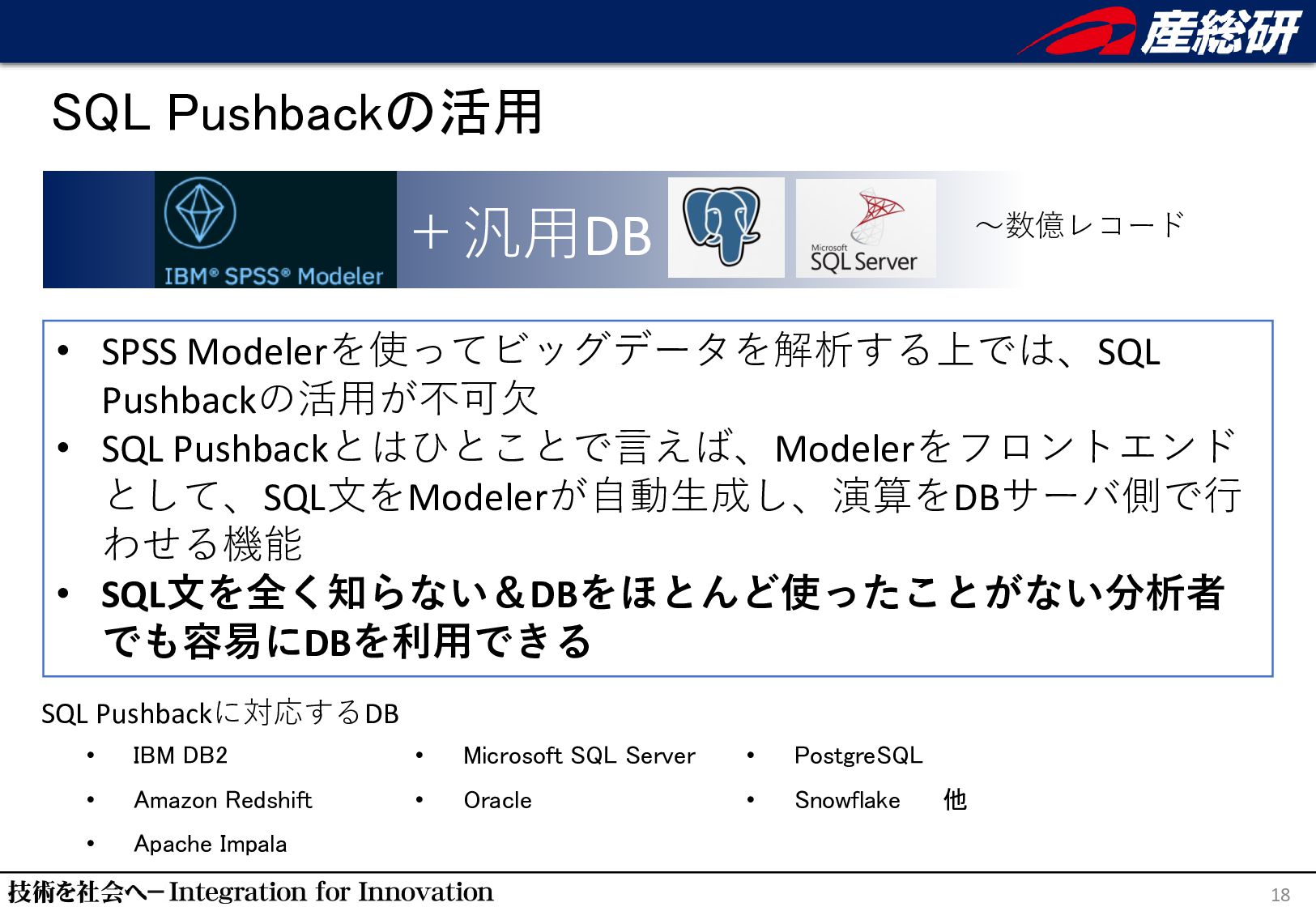
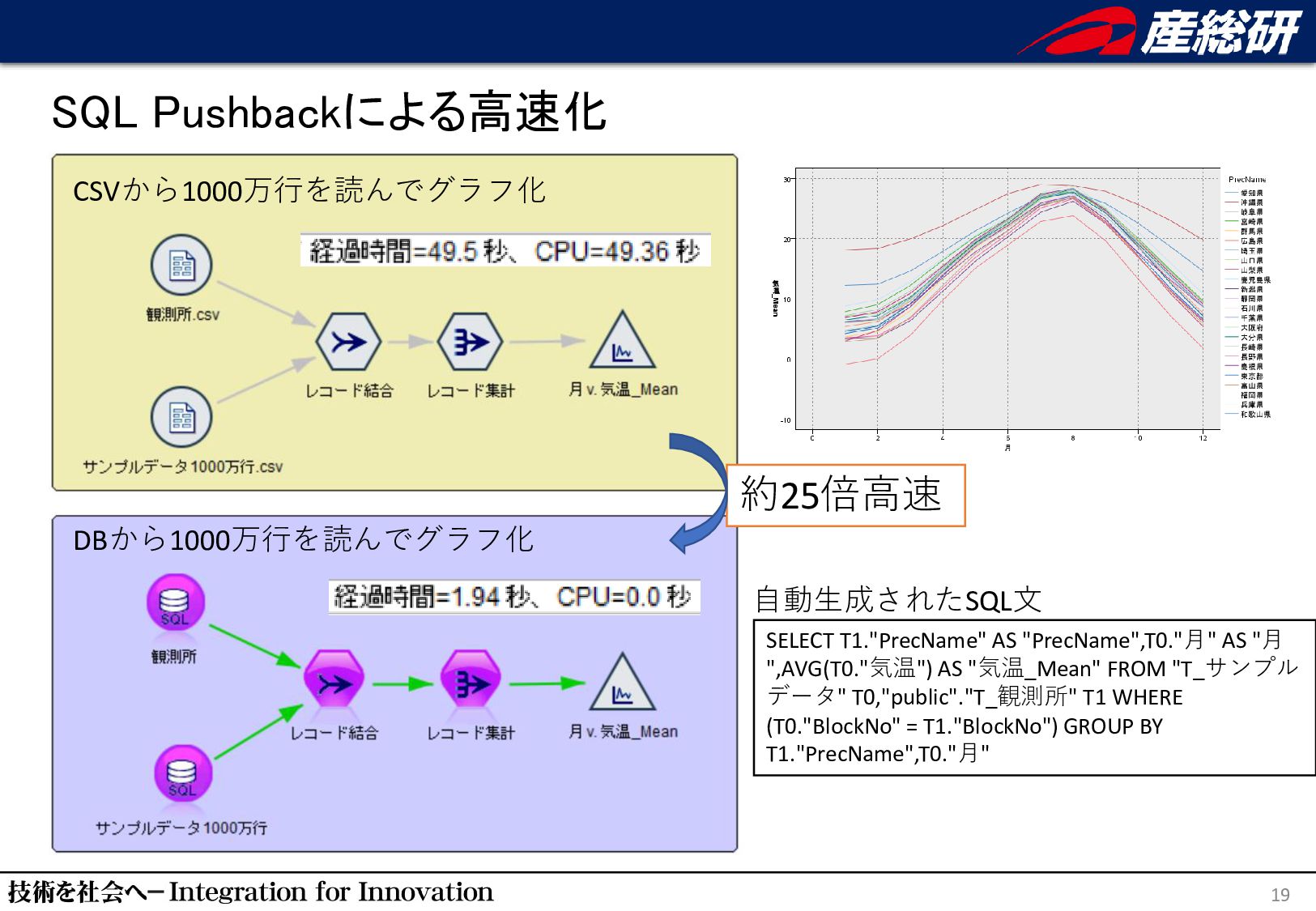
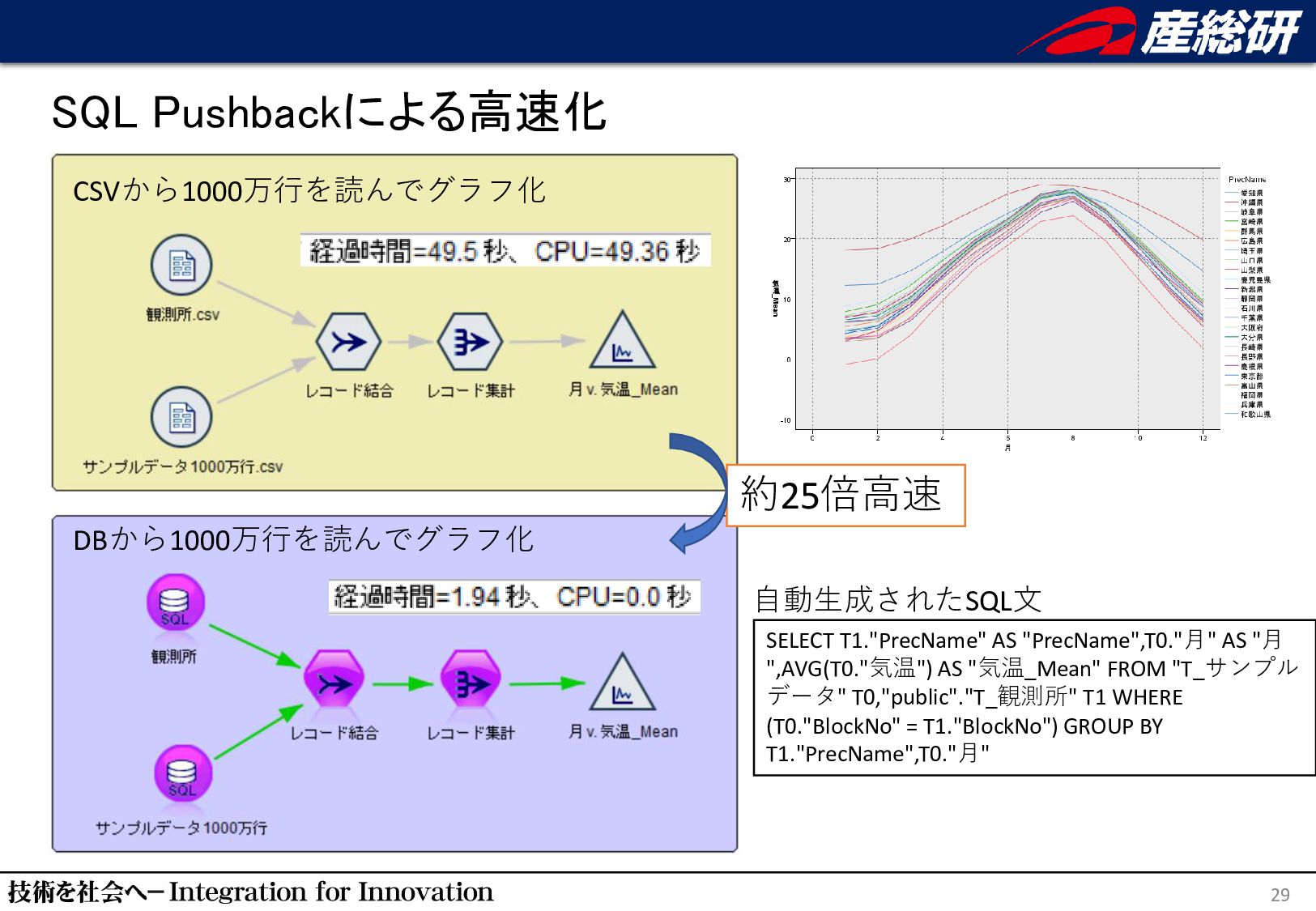
"月 ",AVG(T0."気温") AS "気温_Mean" FROM "T_サンプル データ" T0,"public"."T_観測所" T1 WHERE (T0."BlockNo" = T1."BlockNo") GROUP BY T1."PrecName",T0."月" 約25倍⾼速 自動生成されたSQL文
"月 ",AVG(T0."気温") AS "気温_Mean" FROM "T_サンプル データ" T0,"public"."T_観測所" T1 WHERE (T0."BlockNo" = T1."BlockNo") GROUP BY T1."PrecName",T0."月" 約25倍⾼速 自動生成されたSQL文
![国立研究開発法人 産業技術総合研究所 ゼロエミッション国際共同研究センター 本田 智則 [email protected] 大規模時系列データをハンドリングする 1](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ① PostgreSQLをダウンロードしてインストール 設定は全てデフォルトでOK ODBCドライバ「psqlODBC(64bit)」をインストール 21](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_20.jpg){kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ② PgAdmin(PostgreSQLの管理ツール)で適当な名前のDB を作成 ここでは仮に「DB_TEST」というDBを作成 22](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_21.jpg){kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ③ ODBC接続の設定 Windows上で、ODBC設定を開いて、システムDSN内「追 加」を開く 23](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_22.jpg){kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ④ PostgreSQL ODBC Driver(UNICODE)を選択 24](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_23.jpg){kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ⑤ ODBC接続設定を入力して保存 25 任意のDB名 ②で作成したDB名 インストール時に設定したPW デフォルトは5432](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_24.jpg){kind=link}
![15分でできる環境構築(しかもタダ![除くModeler]) ⑥ SPSS Modelerを開いて「ツール」→「データベース」を選択 し、データベース接続を設定 26 たったこれだけで準備完了!](https://files.speakerdeck.com/presentations/96f41ad08e4c4087a6b26bb6254f920b/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}