Что такое Latency? Зачем ее измерять уже на этапе разработки Вашего продукта, что такое SLA, какие инструменты использовать, какие подводные камни существуют и главное, как ее правильно измерять. В данном докладе ответим на все эти вопросы, а также посмотрим на реальные данные измерений latency на примере ElasticSearch.
Tags: latency, SLA, ElasticSearch, tools
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
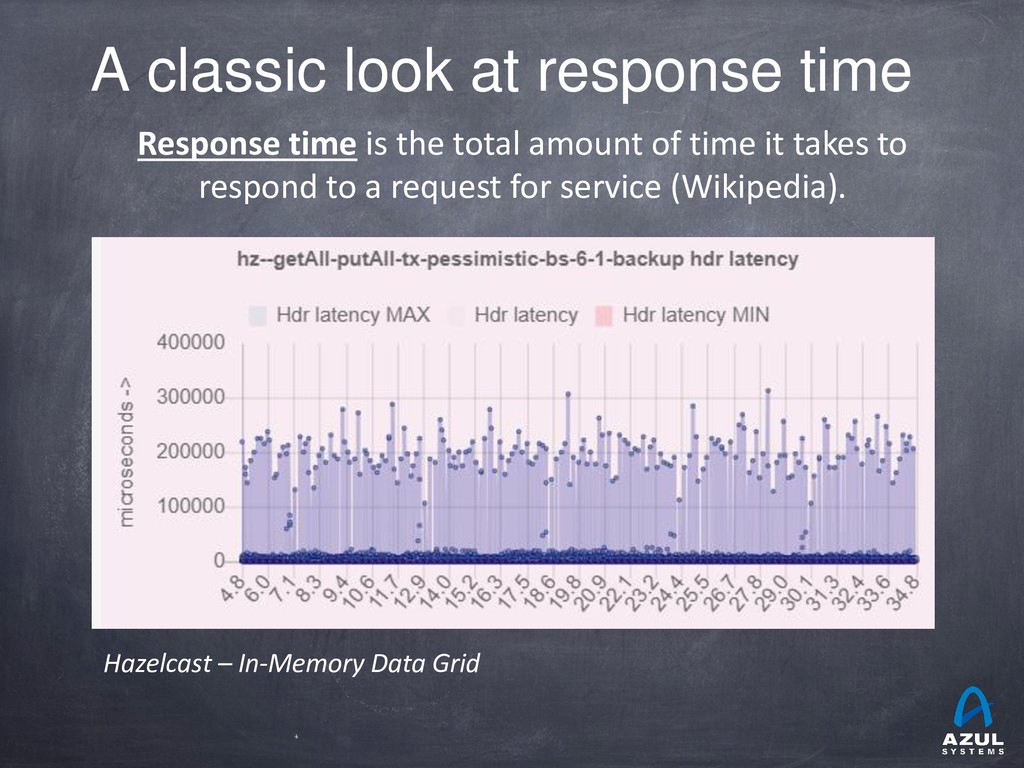{kind=link}
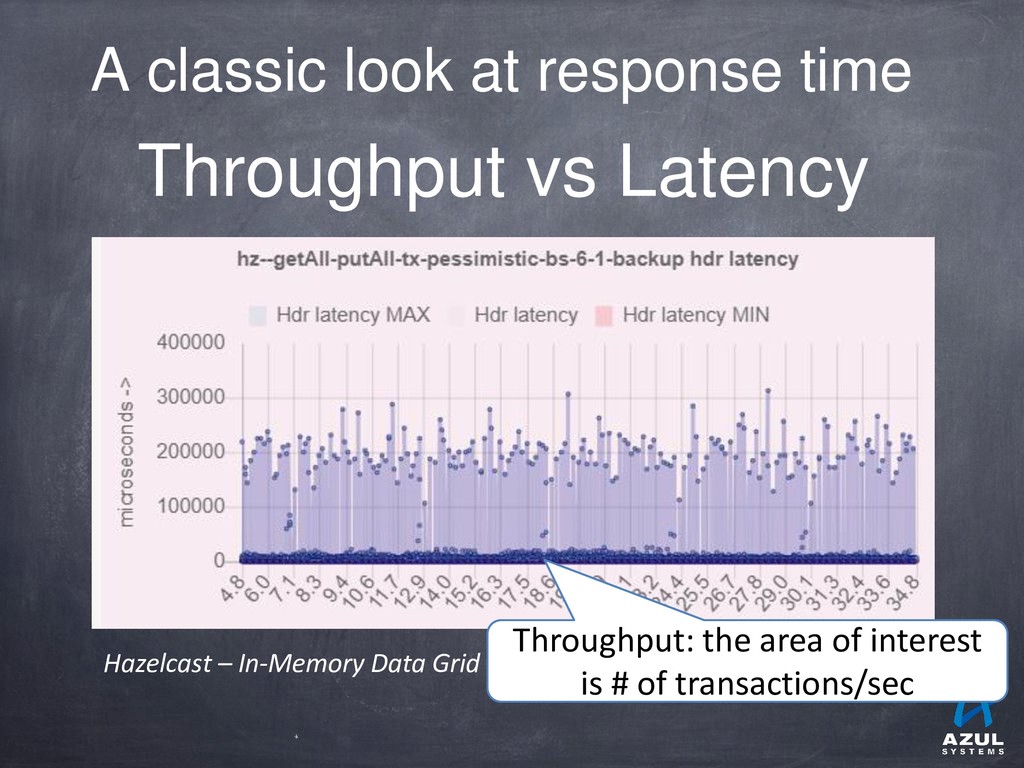{kind=link}
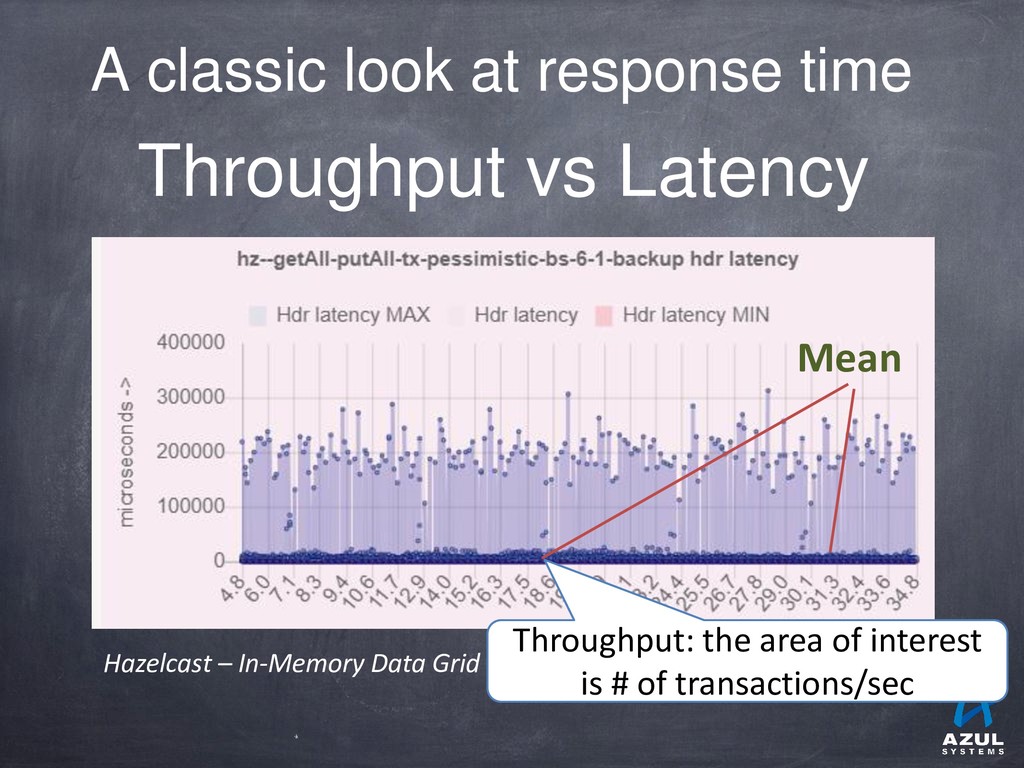{kind=link}
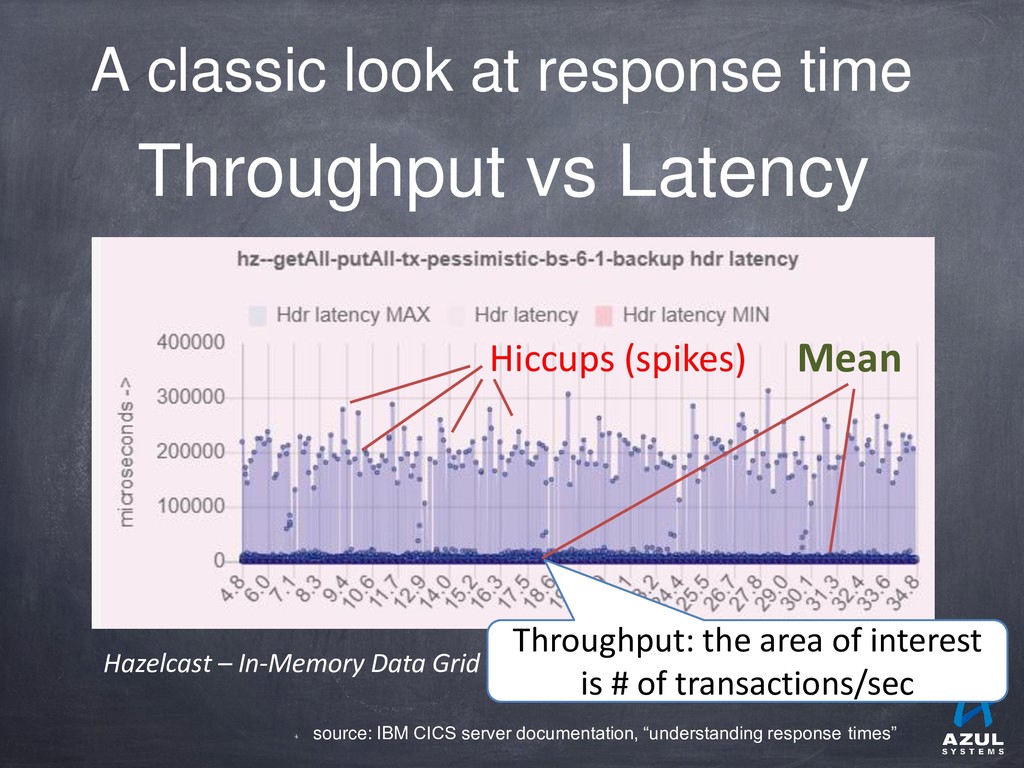{kind=link}
{kind=link}
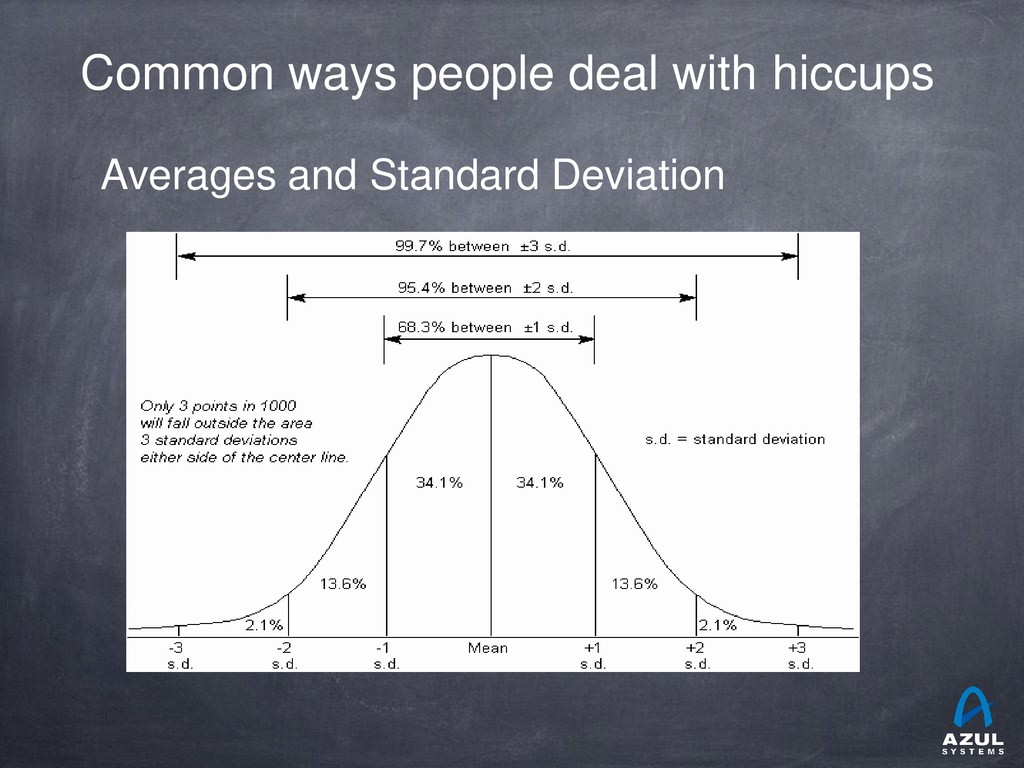{kind=link}
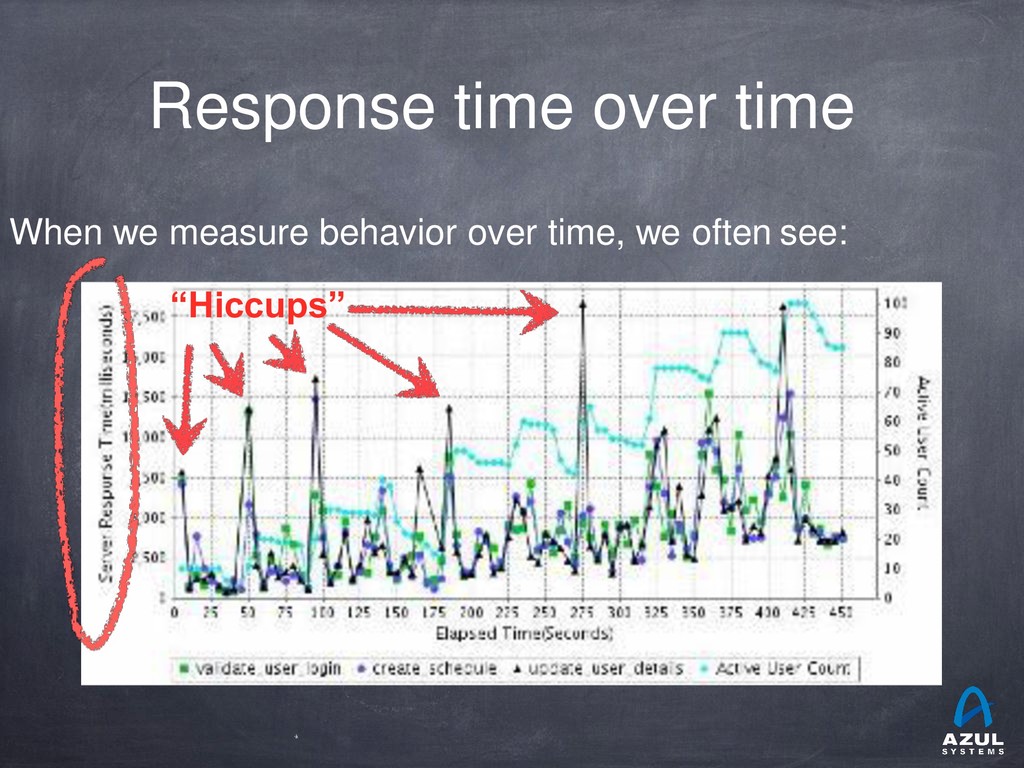{kind=link}
![Hiccups are [typically] strongly multi-modal They don’t look anything like](https://files.speakerdeck.com/presentations/6ab88a84f7444b9fa70729fdf942c620/slide_12.jpg){kind=link}
{kind=link}
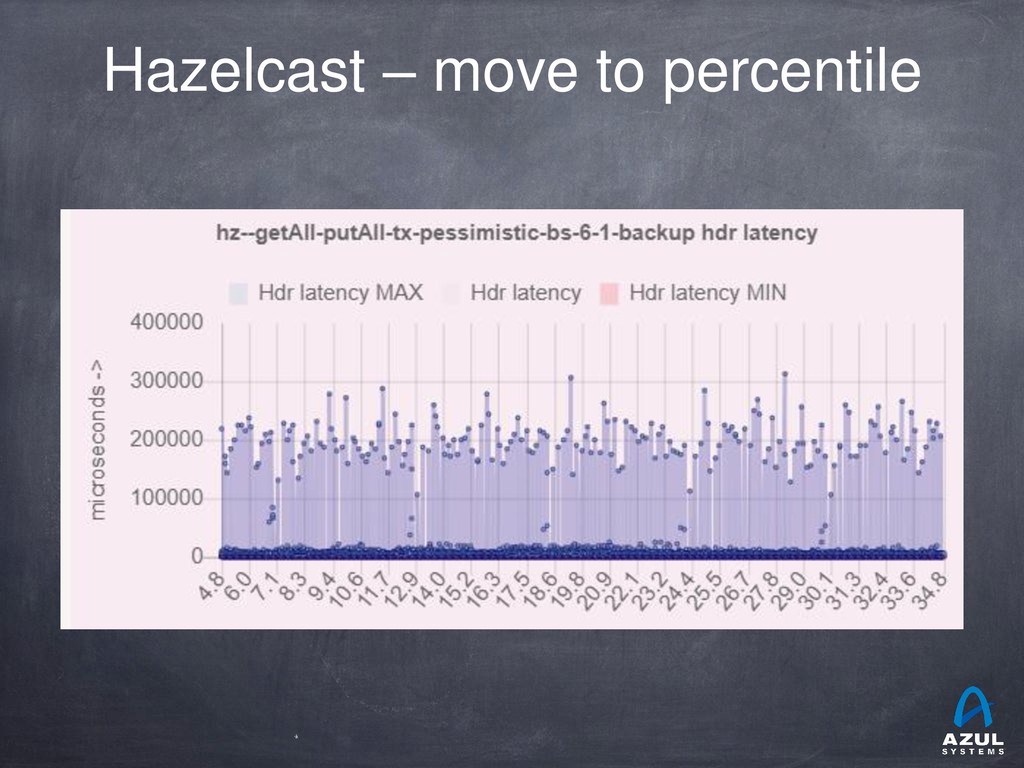{kind=link}
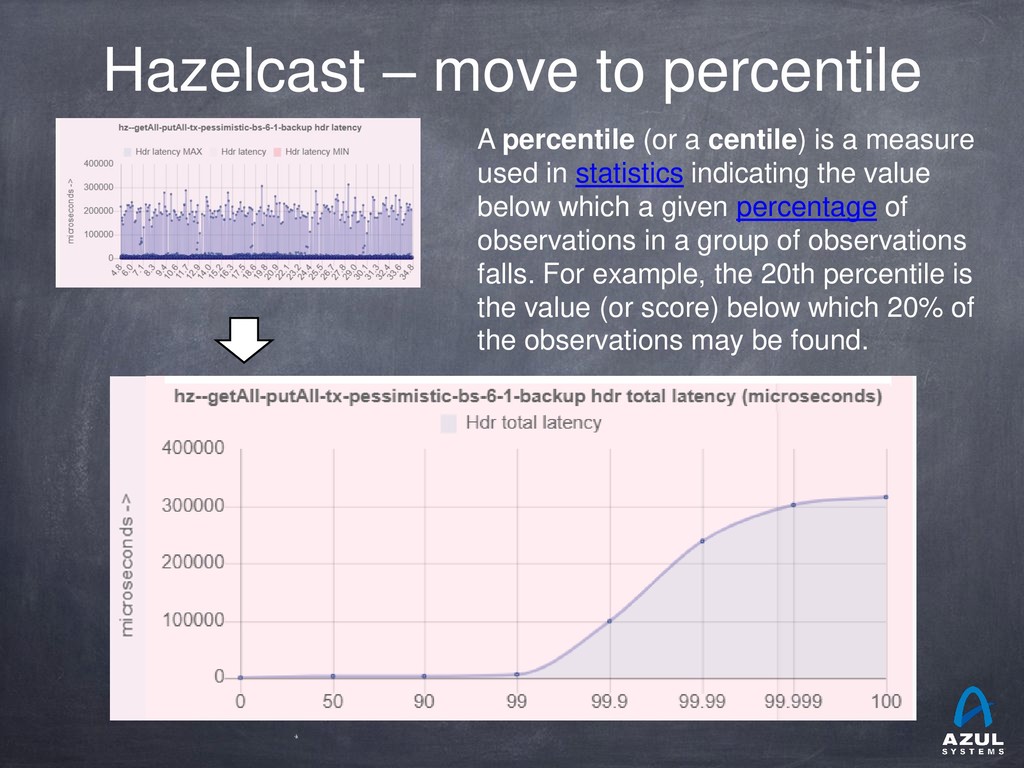{kind=link}
{kind=link}
{kind=link}
{kind=link}
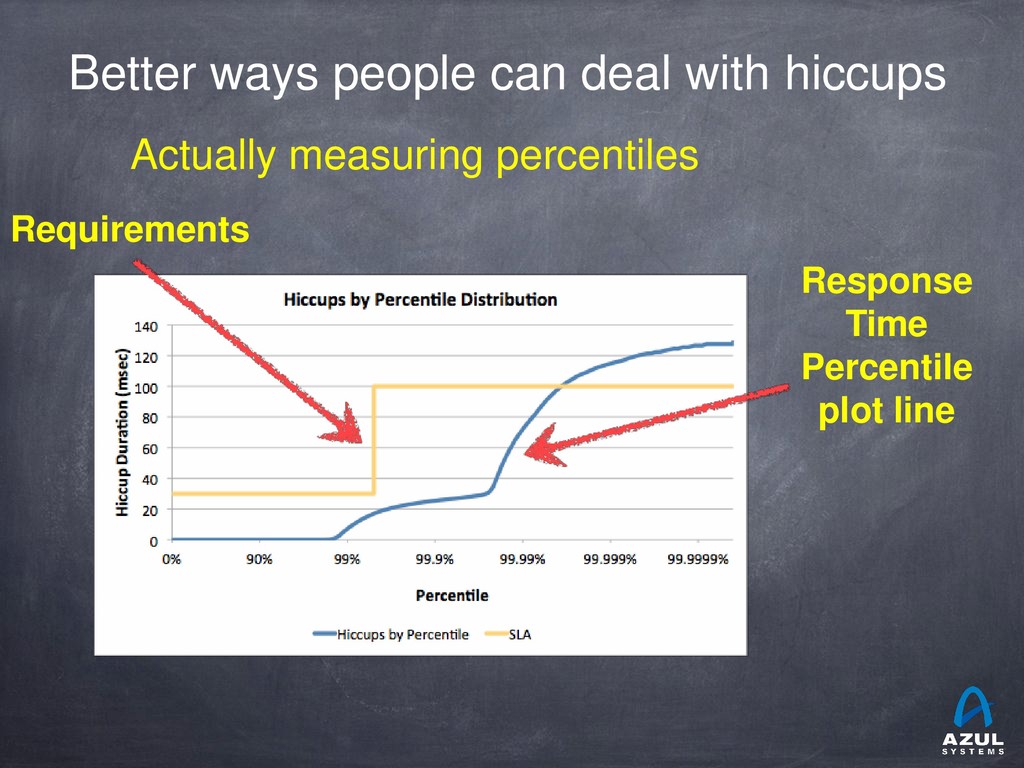{kind=link}
{kind=link}
{kind=link}
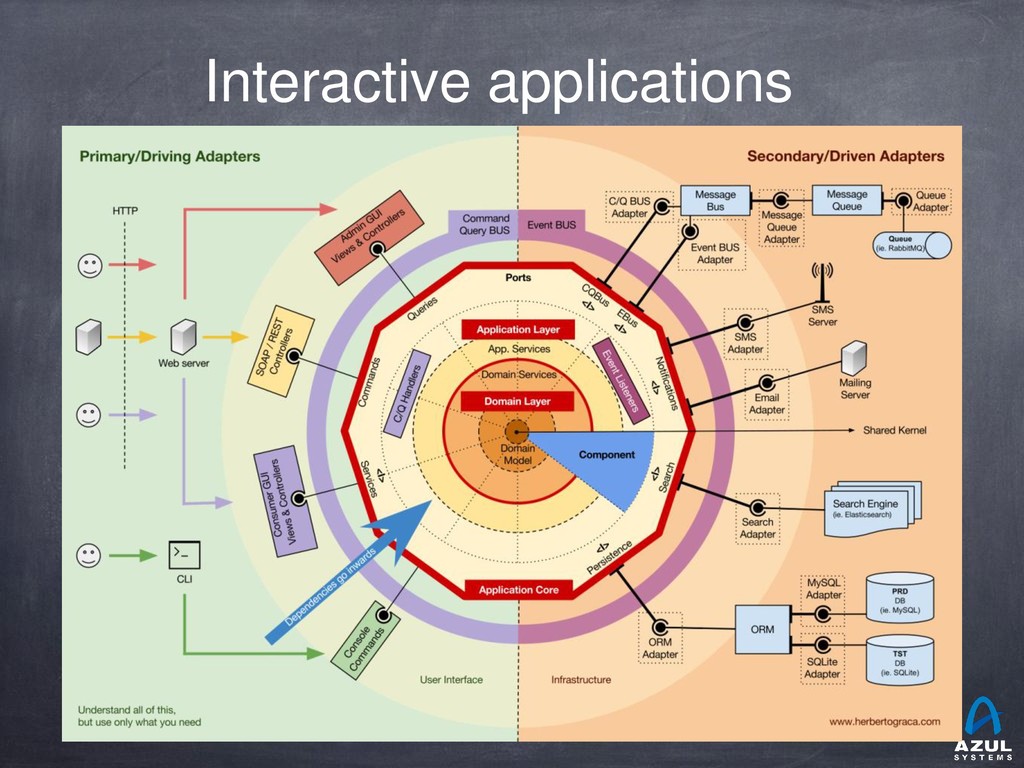{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
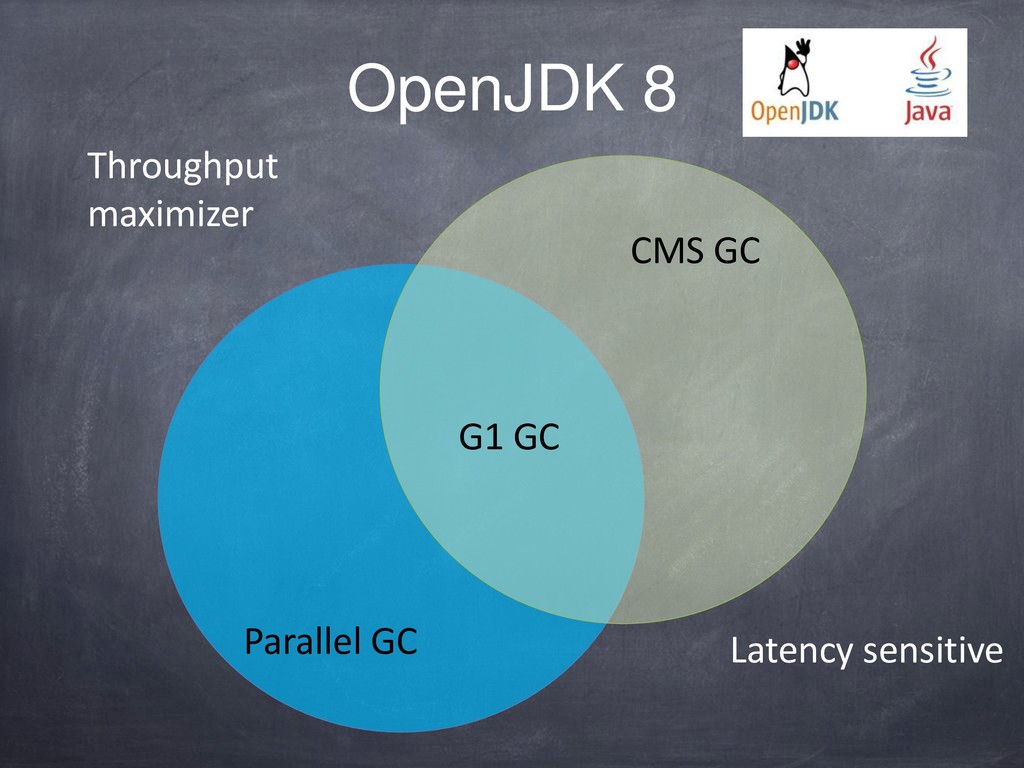{kind=link}
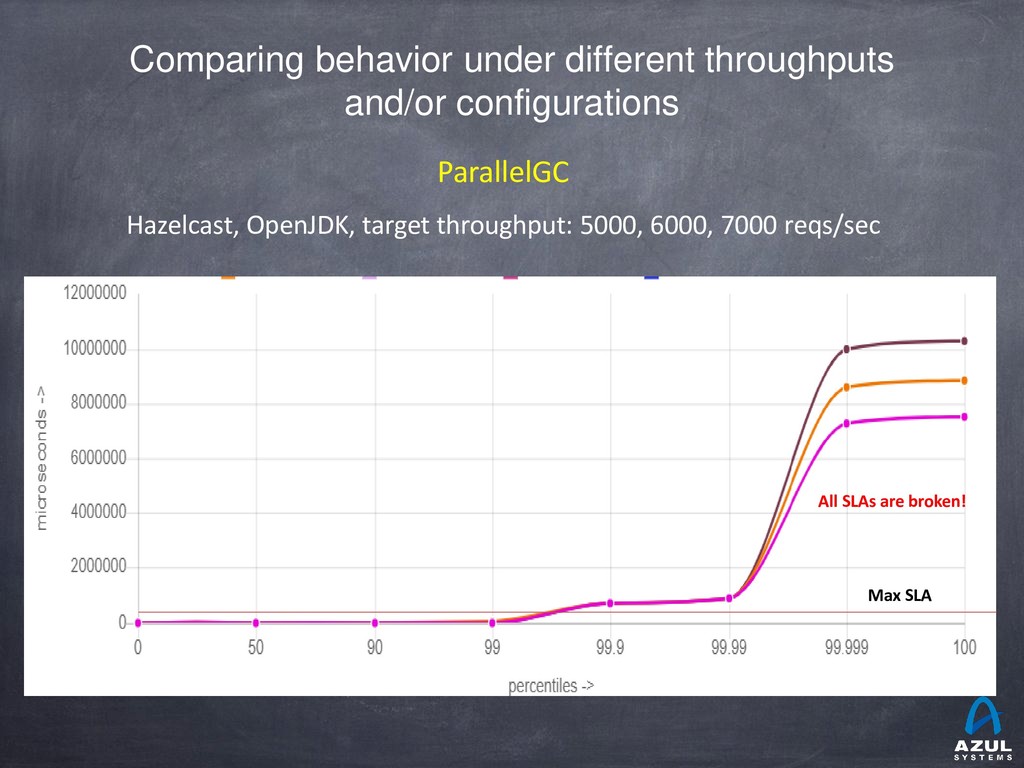{kind=link}
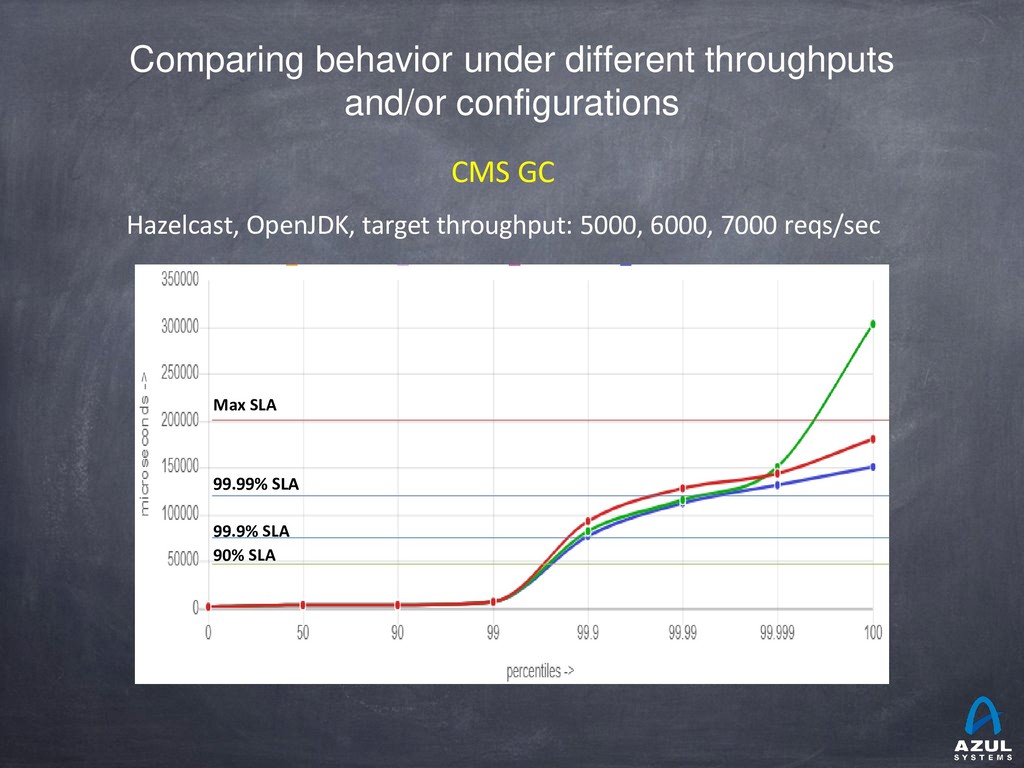{kind=link}
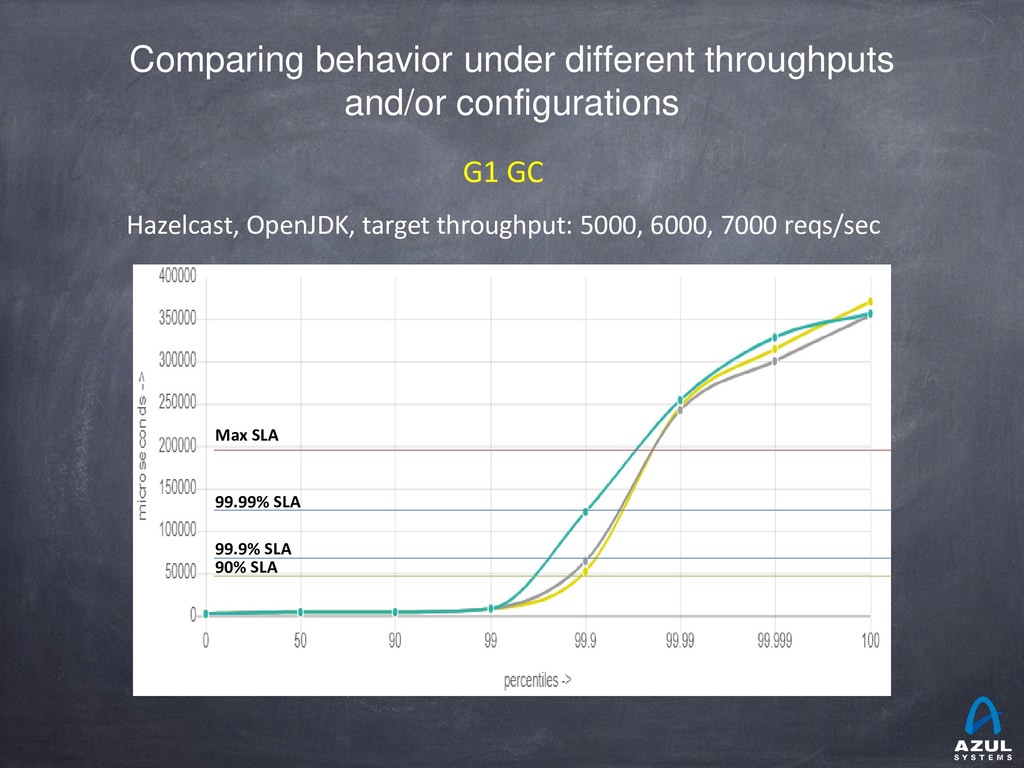{kind=link}
{kind=link}
{kind=link}
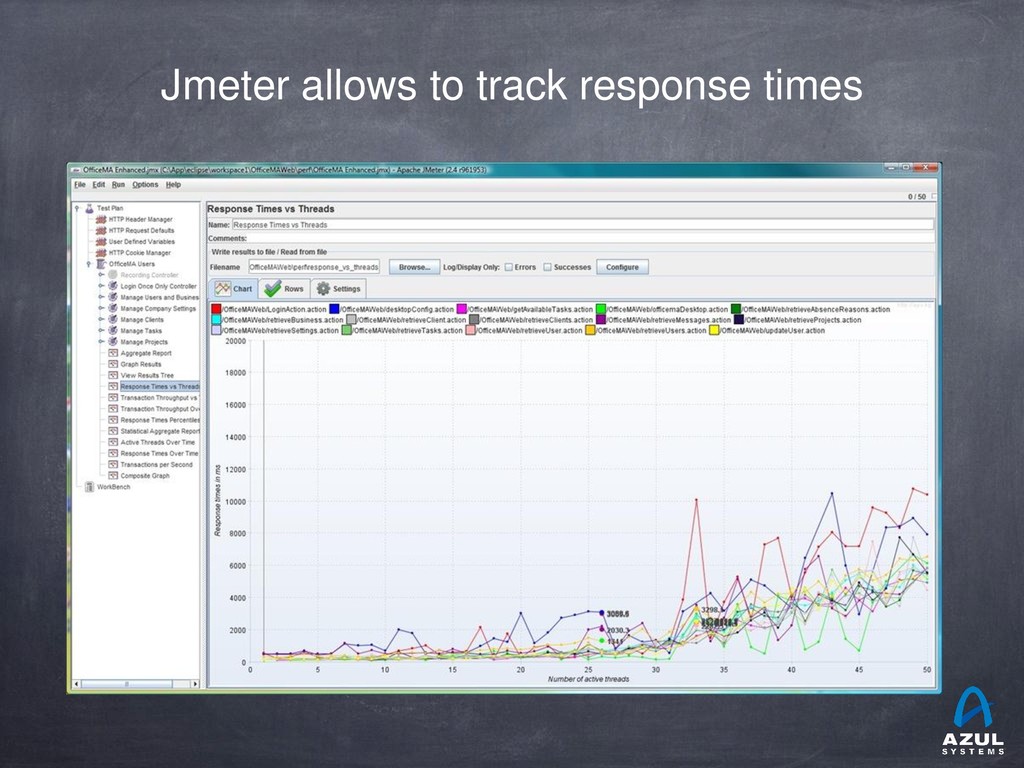{kind=link}
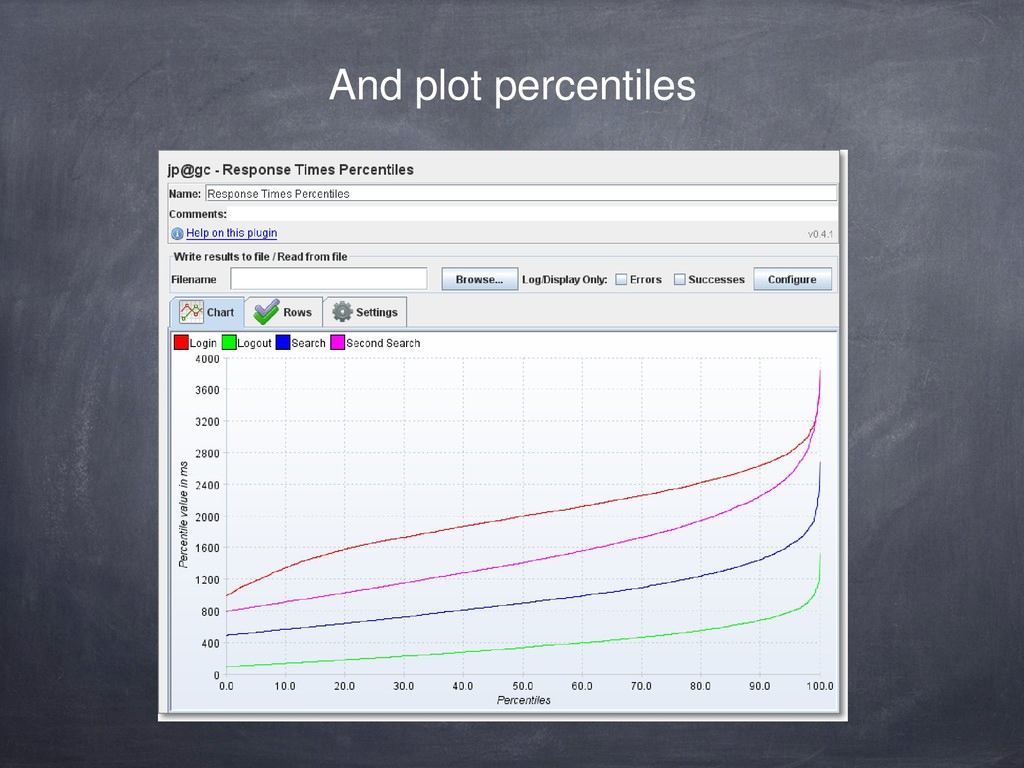{kind=link}
{kind=link}
{kind=link}
{kind=link}
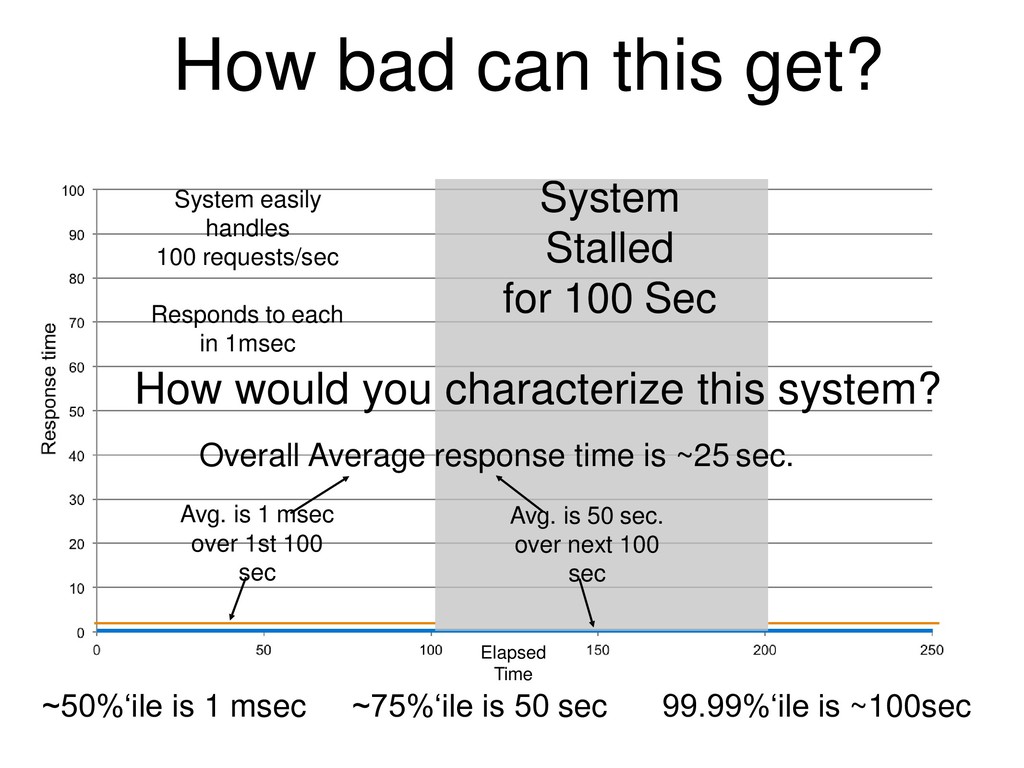{kind=link}
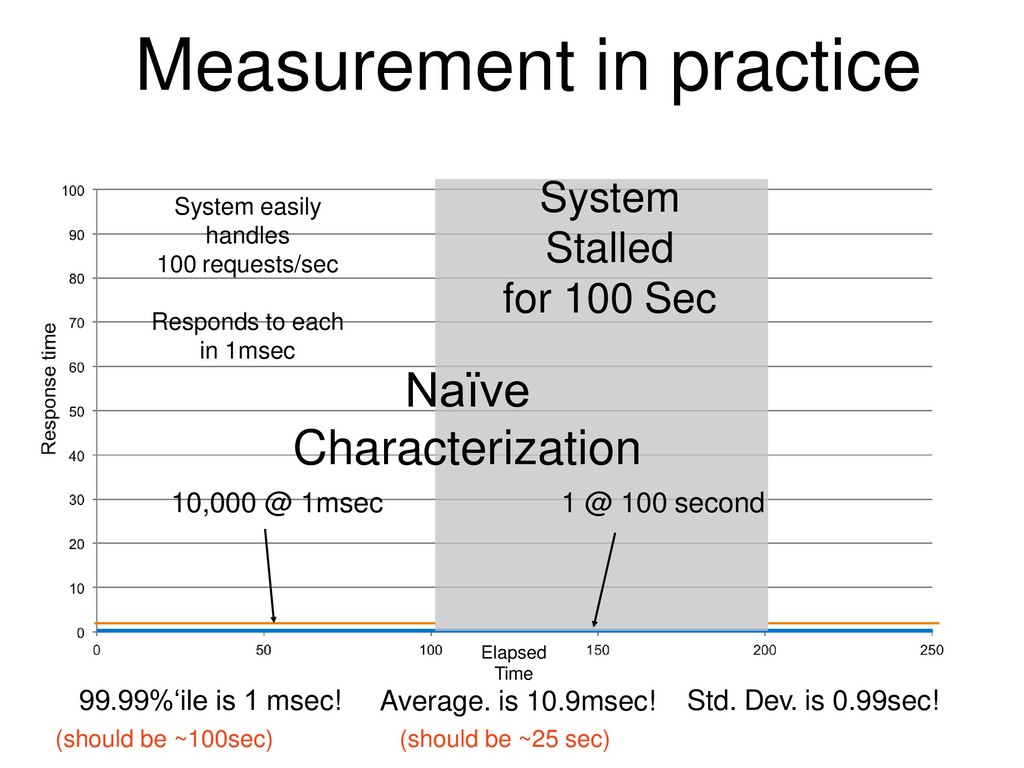{kind=link}
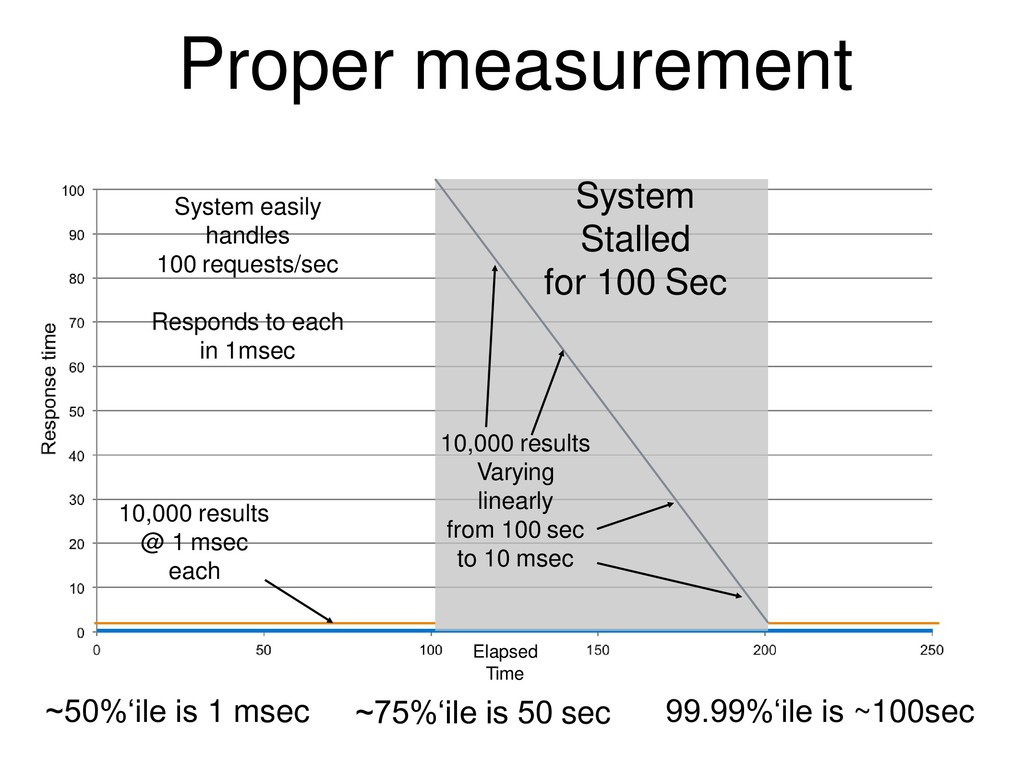{kind=link}
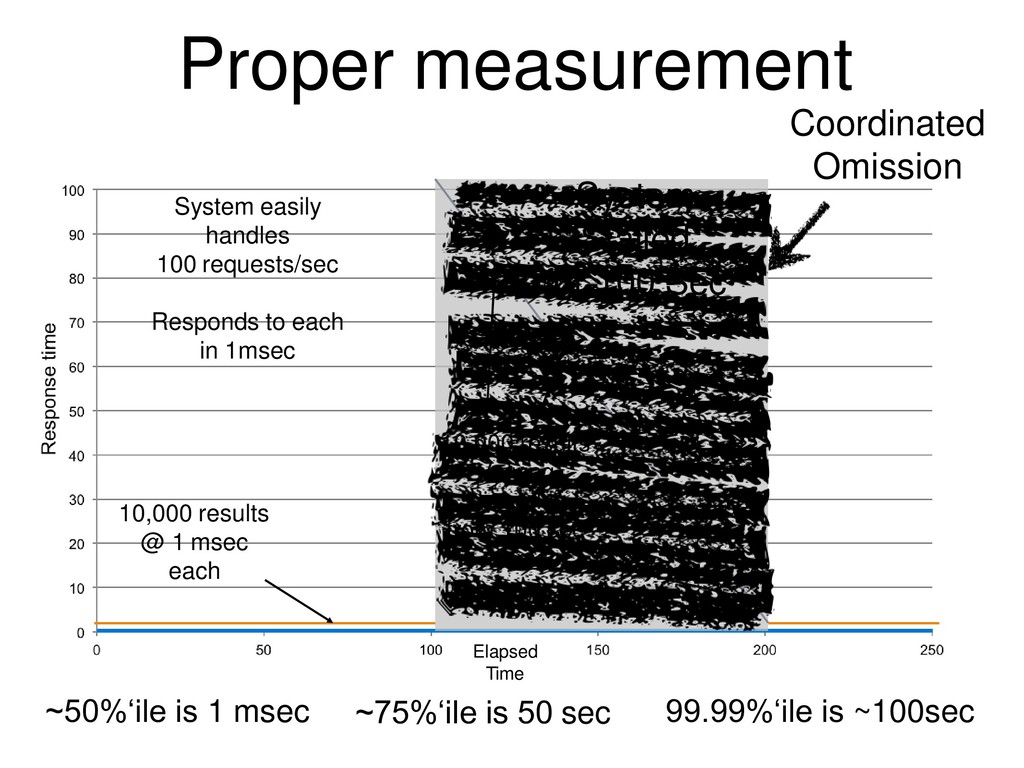{kind=link}
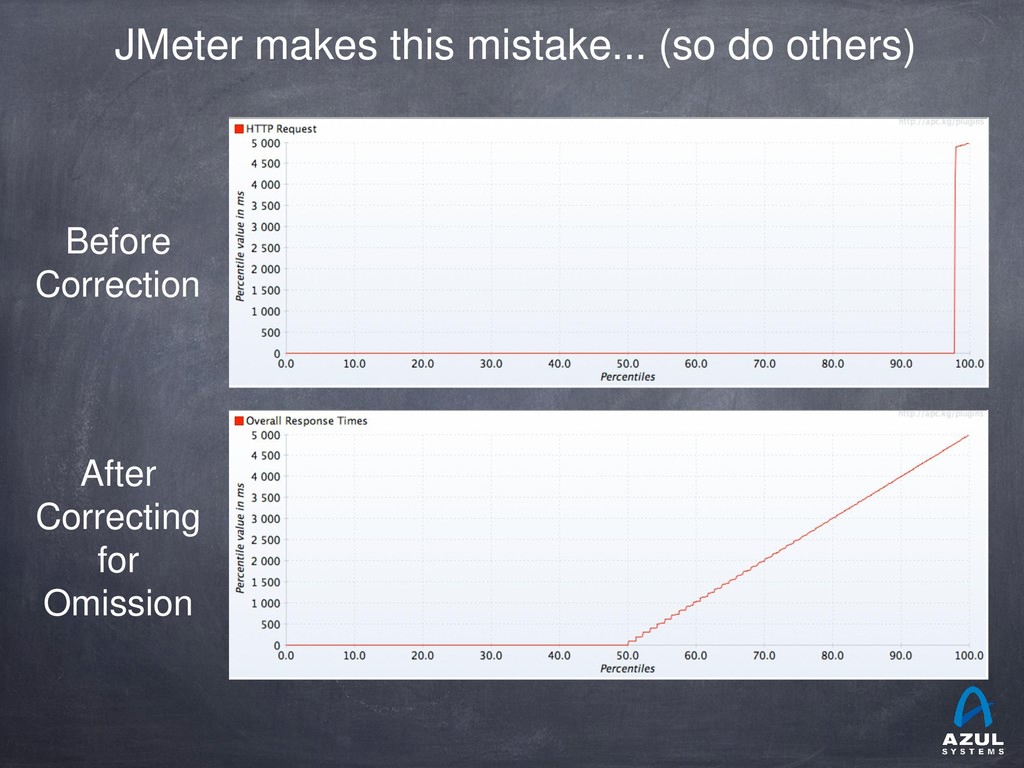{kind=link}
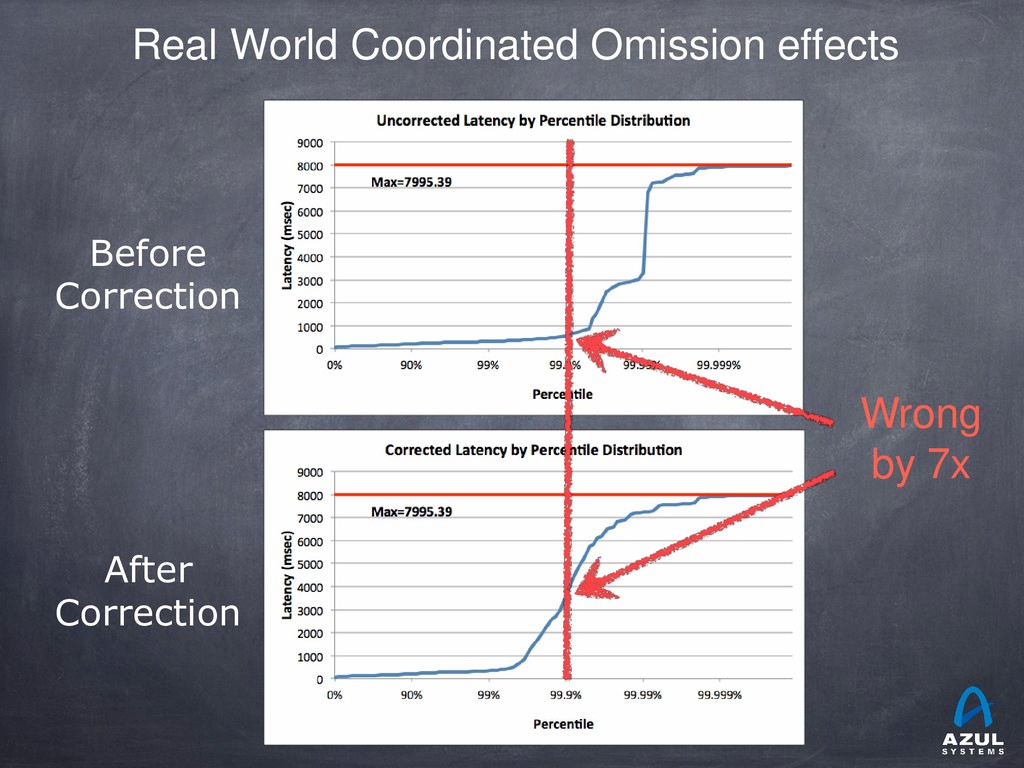{kind=link}
{kind=link}
{kind=link}
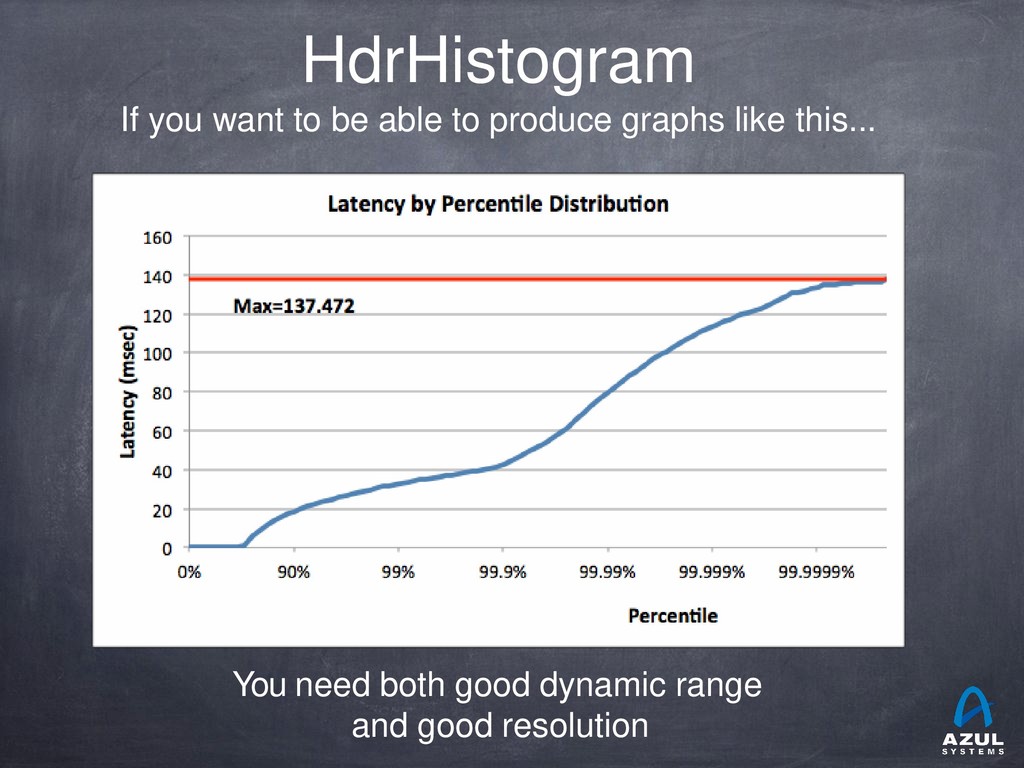{kind=link}
{kind=link}
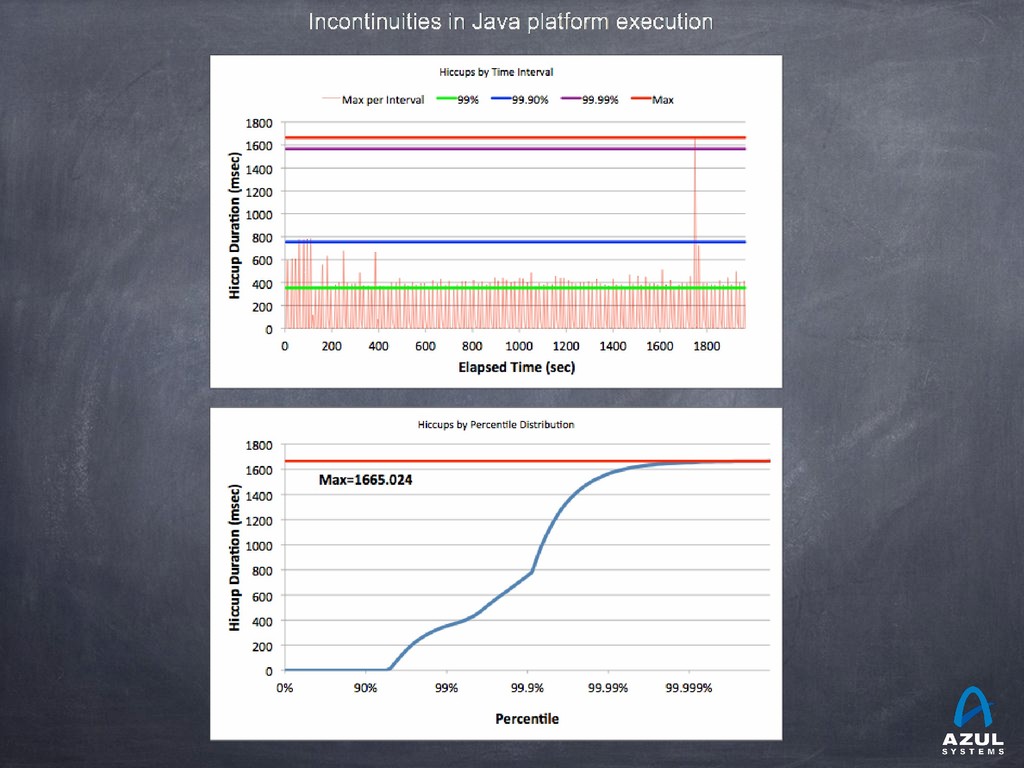{kind=link}
{kind=link}
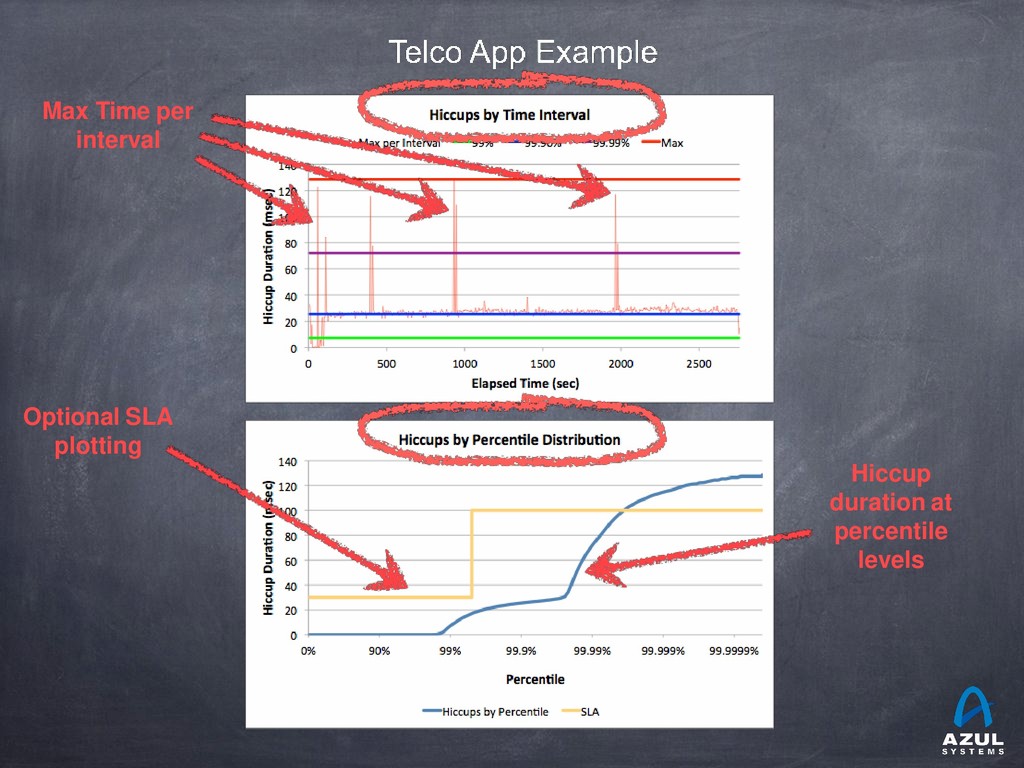{kind=link}
{kind=link}
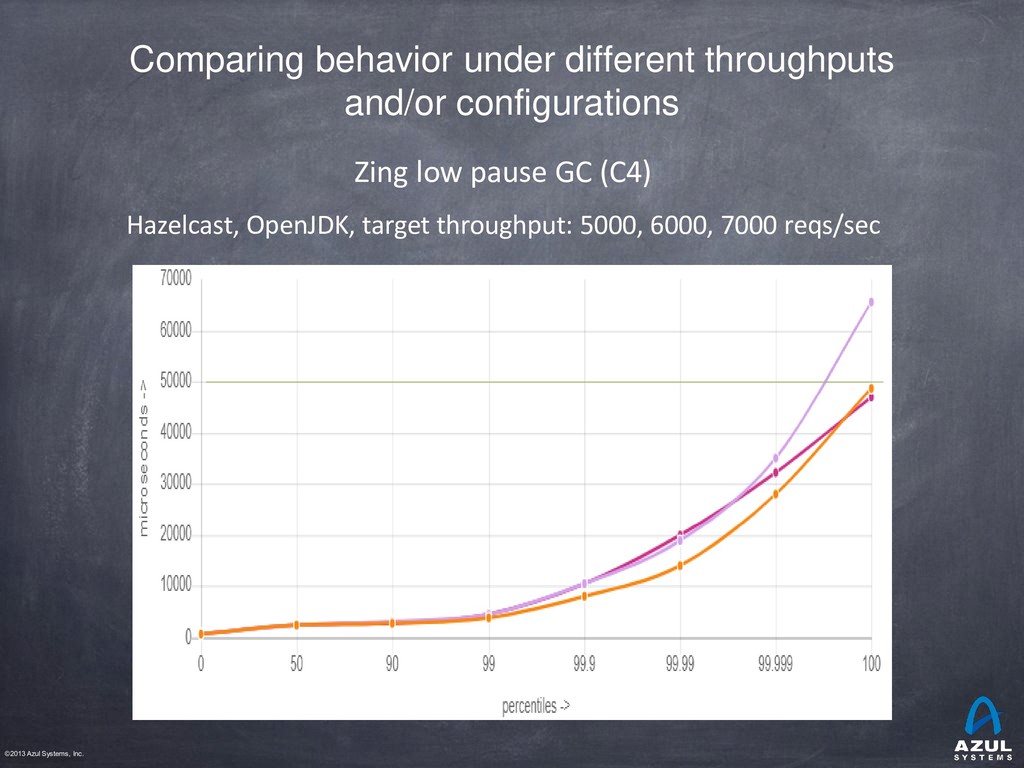{kind=link}
{kind=link}