Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
kaggler なら知っておきたい GPU の話
Search
kaerururu
December 12, 2023
Programming
3.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
kaggler なら知っておきたい GPU の話
社内勉強会で共有した資料です。
Flash Attention 論文と一般販売向け GPU の技術仕様の読み方や簡単な仕組みなどわかる範囲で説明しています。
kaerururu
December 12, 2023
More Decks by kaerururu
See All by kaerururu
LPIXEL×CADDi_kaerururu
kaerururu
3
600
Other Decks in Programming
See All in Programming
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
250
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
170
技術記事、 専門家としてのプログラマ、 言語化
mizchi
14
7.4k
Claude Team Plan導入・ガイド
tk3fftk
0
180
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.8k
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
220
Performance Engineering for Everyone
elenatanasoiu
0
270
AIエージェントで 変わるAndroid開発環境
takahirom
2
590
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
350
OS アップデート対応の取り組み方がもっと共有されてほしい
andpad
0
110
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
260
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Context Engineering - Making Every Token Count
addyosmani
9
1k
New Earth Scene 8
popppiees
3
2.4k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Ethics towards AI in product and experience design
skipperchong
2
330
Code Reviewing Like a Champion
maltzj
528
40k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
A Modern Web Designer's Workflow
chriscoyier
698
190k
Transcript
kaerururu Attention の効率化と GPU の話
contents - 話すこと - Attention の効率化の論文紹介 - cpu, gpu の概要やプログラム実行時にどのように連携しているか
- gpu 内部構造の話 - 話さ (せ) ないこと - cpu, gpu, メモリなどの正確な話 - (kaerururu が調べてまとめた内容なので、正確さの保証はできません🙏) - FlashAttention-2 の話
contents - 論文「FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness」の紹介
- CPU とか GPU の話 - まとめ
contents - 論文「FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness」の紹介
- CPU とか GPU の話 - まとめ
Flash Attention 概要 - link - 発行 : 2022/06 -
要点 - GPU メモリへの読み書きのレベルまで考慮してアーキテクチャ見直した。 - メモリ効率化 (O(N^2) → O(N), N : seq_len) できて高速化できた。 - モデルが処理できる token 数が増えて精度も上がった。 - Flash Attention 2 も出てる (2023/07/18) - https://arxiv.org/pdf/2307.08691.pdf
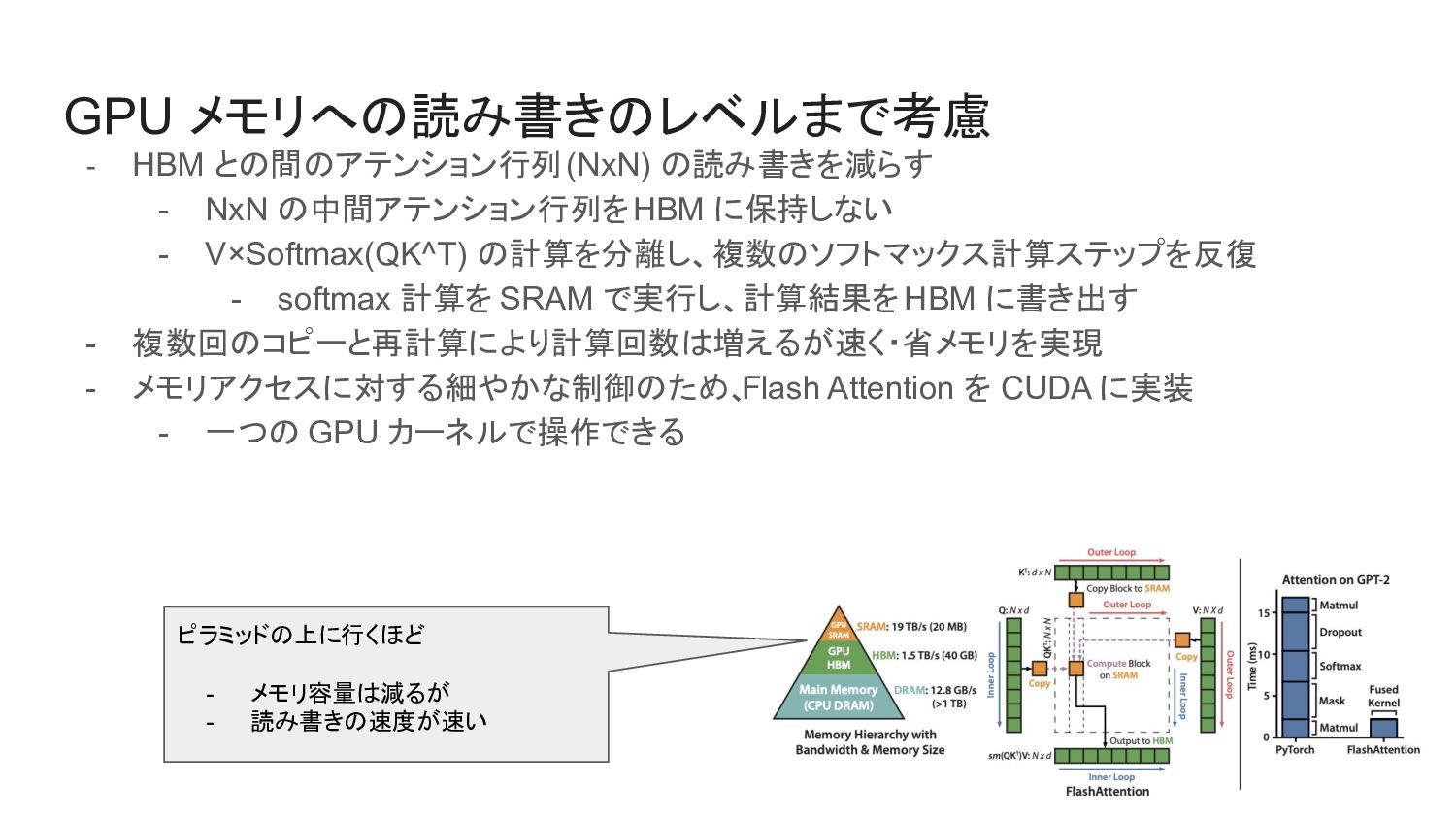
GPU メモリへの読み書きのレベルまで考慮 - HBM との間のアテンション行列 (NxN) の読み書きを減らす - NxN の中間アテンション行列を
HBM に保持しない - V×Softmax(QK^T) の計算を分離し、複数のソフトマックス計算ステップを反復 - softmax 計算を SRAM で実行し、計算結果を HBM に書き出す - 複数回のコピーと再計算により計算回数は増えるが速く・省メモリを実現 - メモリアクセスに対する細やかな制御のため、 Flash Attention を CUDA に実装 - 一つの GPU カーネルで操作できる ピラミッドの上に行くほど - メモリ容量は減るが - 読み書きの速度が速い
Keywords - メモリ - DRAM (dynamic) … 安価で大容量, メインメモリとして使用される -
SRAM (static) … 読み書きが高速で低消費電力。キャッシュメモリとして使用される。 - HBM(High Bandwidth Memory)や GDDR6 (graphics double data rate type six synchronous dynamic random-access memory) - GPU内のプロセッサとメモリ部分の接続に関する設計技術 - HBM はハイエンド, GDDR6 はエントリーモデル (NVIDIA RTX シリーズとか) に多い - プロセッサとメモリのデータ転送量をメモリ帯域幅という
評価 - 速さ1 - BERT-Large + Wikipedia の結果 - A100
* 8 を 10回実行 - 最初に accuracy 72% 到達した時点の速さを比較 - 提案手法は 15% 早い
評価 - 速さ2 - GPT-2 + OpenWebtext dataset の結果 -
モデル構造を変えていないため同 step における val pp は (ほぼ) 同じ - 学習曲線がほぼ同じ - 3x 速い
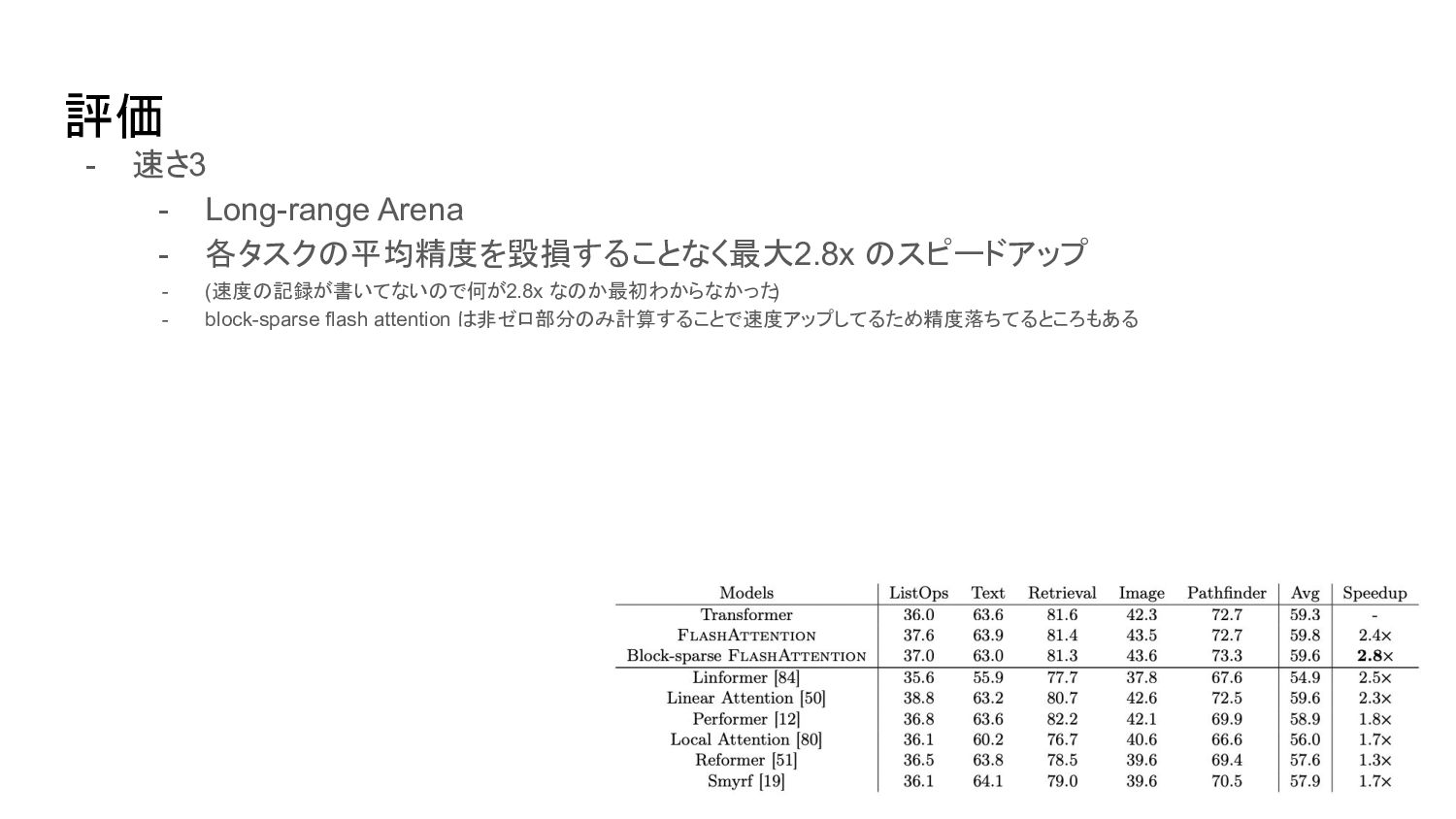
評価 - 速さ3 - Long-range Arena - 各タスクの平均精度を毀損することなく最大 2.8x のスピードアップ
- (速度の記録が書いてないので何が 2.8x なのか最初わからなかった ) - block-sparse flash attention は非ゼロ部分のみ計算することで速度アップしてるため精度落ちてるところもある
評価 - long sequence における精度 - メモリ効率がよくなったのでより長い sequence の学習も可能に -
Roberta Large - 専門的な医学テキスト - avg token : 2,395, max token : 14,562 - 専門用語が多く、考慮できる token 数が増えれば増えるほど精度 up - 欧州人権裁判所のテキスト - avg token : 2,197, max token : 493,92
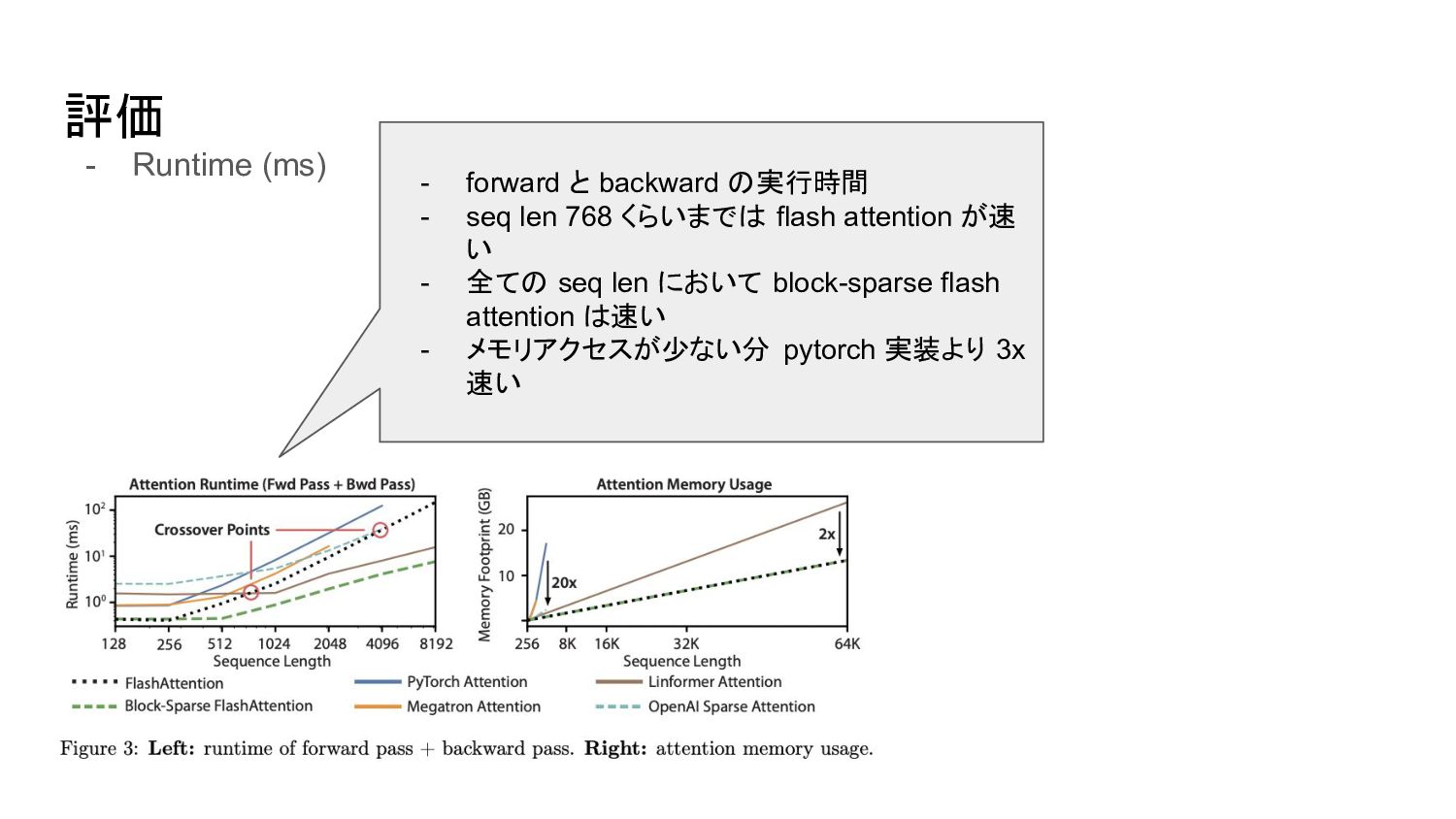
評価 - Runtime (ms) - forward と backward の実行時間 -
seq len 768 くらいまでは flash attention が速 い - 全ての seq len において block-sparse flash attention は速い - メモリアクセスが少ない分 pytorch 実装より 3x 速い
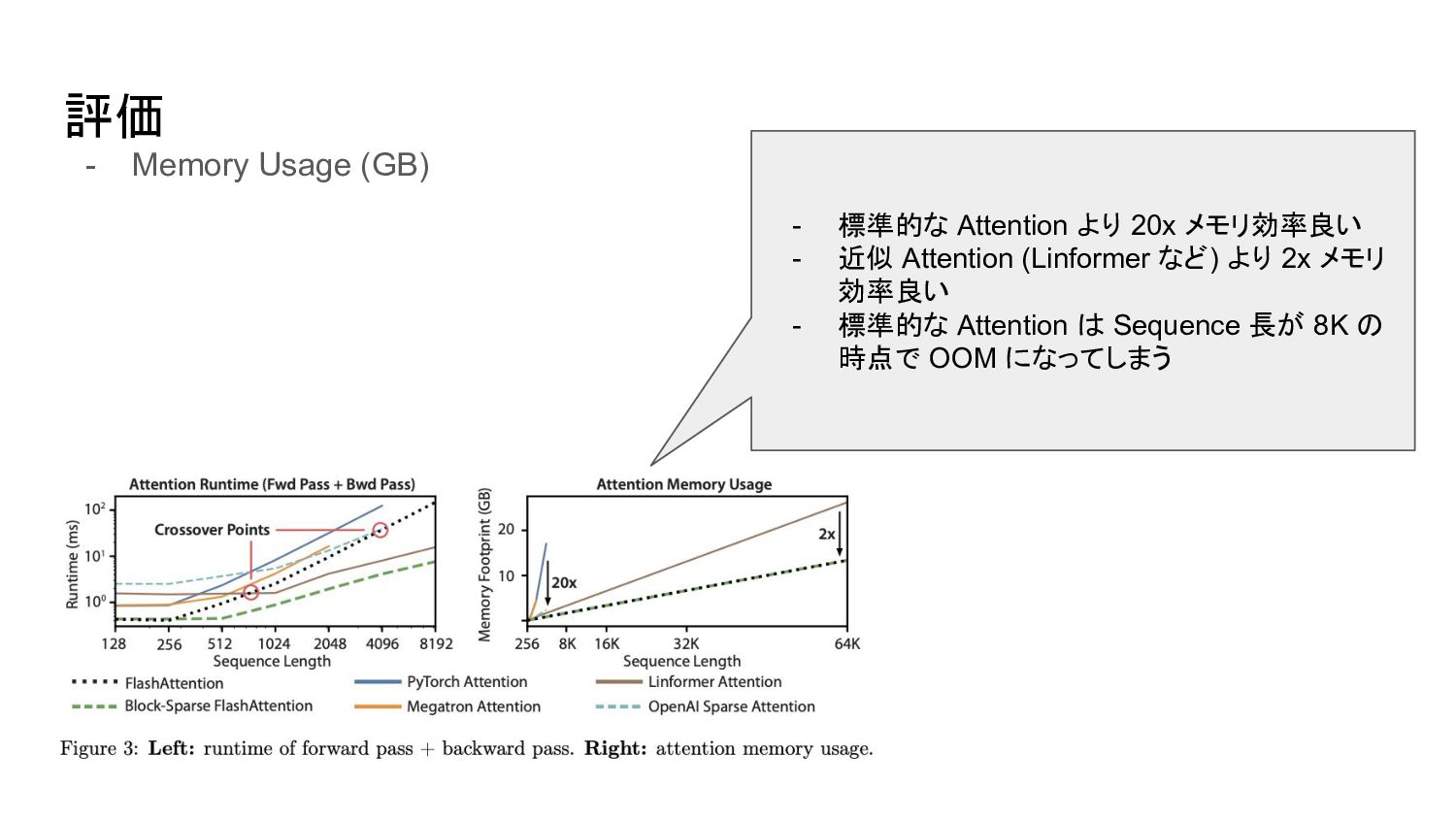
評価 - Memory Usage (GB) - 標準的な Attention より 20x
メモリ効率良い - 近似 Attention (Linformer など) より 2x メモリ 効率良い - 標準的な Attention は Sequence 長が 8K の 時点で OOM になってしまう
How to Use - Pytorch 2.0以降で公式にサポート - https://pytorch.org/blog/accelerated-pytorch-2/ - デフォルトで有効になっている
(が、制約があっていつも適用されるわけではないらしい ) - torch.backends.cuda.enable_flash_sdp(): Enables or Disables FlashAttention. - https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention
限界と展望 - IO 対応アテンション実装を構築する現在のアプローチでは、新しいアテンション実装ごとに新 しい CUDA カーネルを作成する必要がある。 - この実装が GPU
間で転送できない。 - DNN のすべてのレイヤーが GPU HBM に影響する。IO を意識した追加モジュールの実装 の必要性がある。 - 複数 GPU での I/O 最適な実装 - 単一 GPU では最適な実装ができた - アテンションの計算は複数の GPU にわたって並列化できる場合がある。 - 複数の GPU を使用すると、IO 分析に追加のレイヤーが追加され、 GPU 間のデータ転 送が考慮される。
contents - 論文「FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness」の紹介
- CPU とか GPU の話 - まとめ
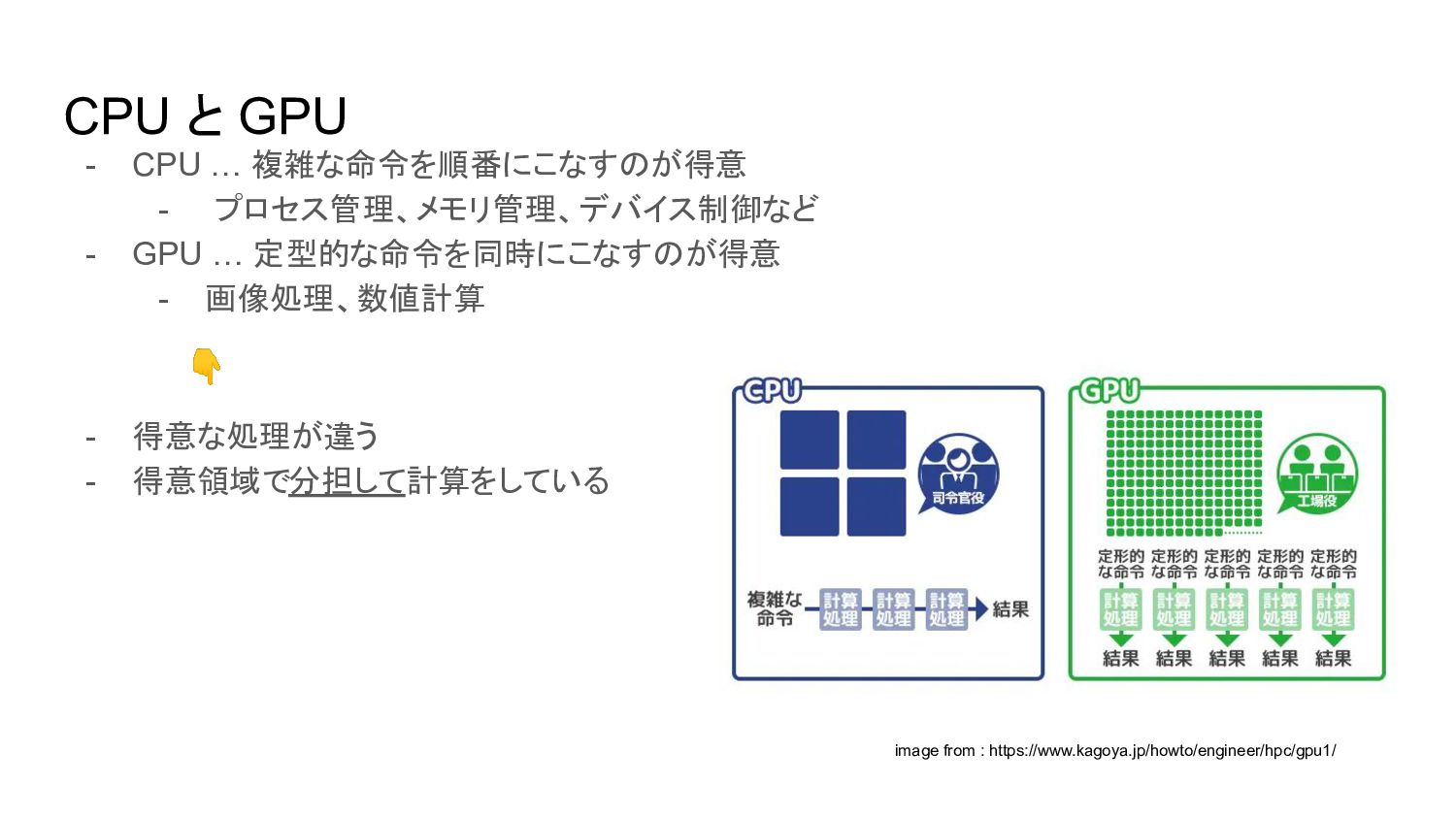
CPU と GPU - CPU … 複雑な命令を順番にこなすのが得意 - プロセス管理、メモリ管理、デバイス制御など -
GPU … 定型的な命令を同時にこなすのが得意 - 画像処理、数値計算 👇 - 得意な処理が違う - 得意領域で分担して計算をしている image from : https://www.kagoya.jp/howto/engineer/hpc/gpu1/
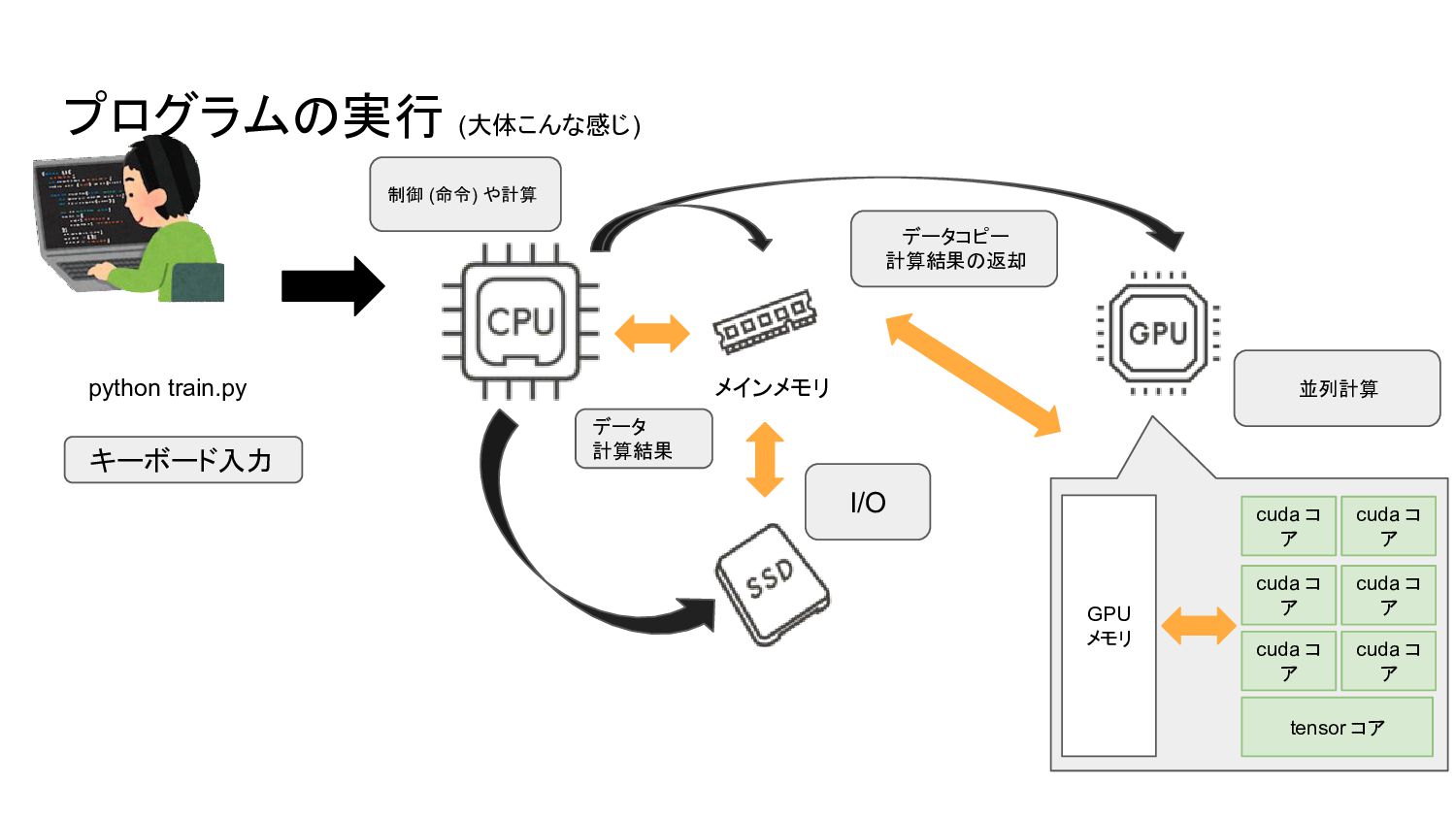
プログラムの実行 (大体こんな感じ) メインメモリ キーボード入力 python train.py データ 計算結果 I/O データコピー
計算結果の返却 並列計算 制御 (命令) や計算 tensor コア cuda コ ア cuda コ ア cuda コ ア cuda コ ア cuda コ ア cuda コ ア GPU メモリ
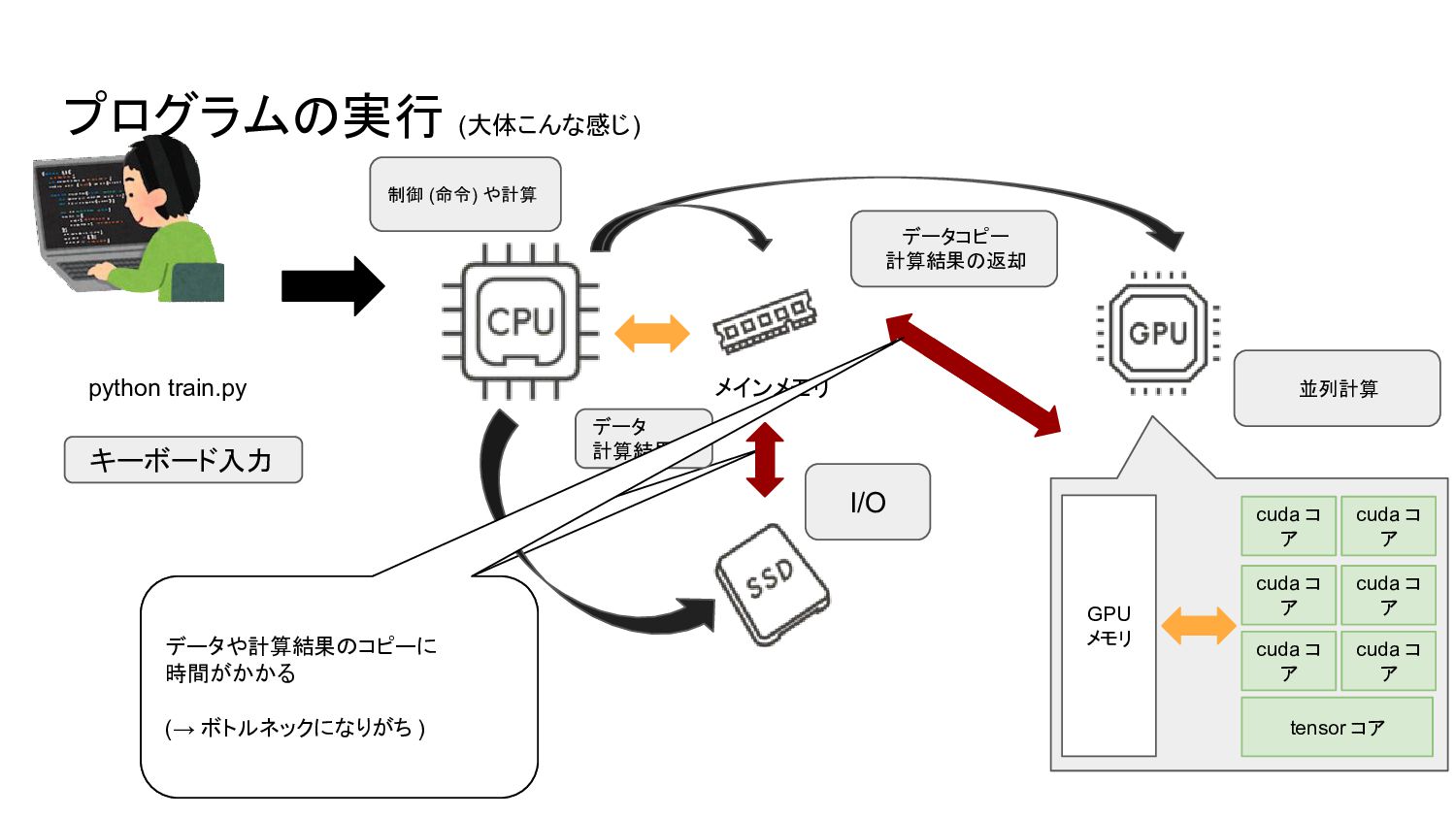
プログラムの実行 (大体こんな感じ) メインメモリ キーボード入力 python train.py データ 計算結果 I/O データコピー
計算結果の返却 並列計算 制御 (命令) や計算 tensor コア cuda コ ア cuda コ ア cuda コ ア cuda コ ア cuda コ ア cuda コ ア GPU メモリ データや計算結果のコピーに 時間がかかる (→ ボトルネックになりがち )
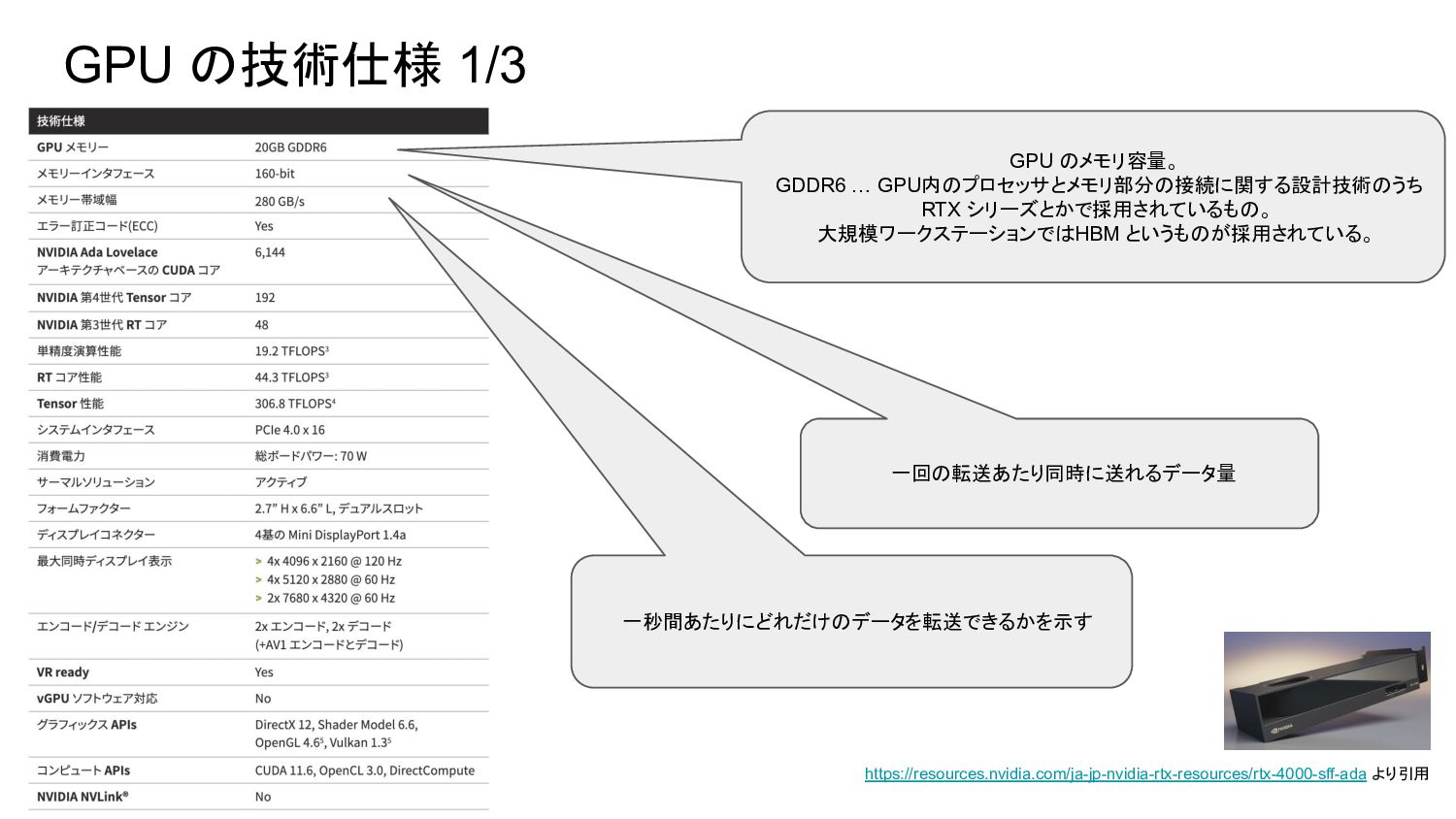
GPU の技術仕様 1/3 https://resources.nvidia.com/ja-jp-nvidia-rtx-resources/rtx-4000-sff-ada より引用 GPU のメモリ容量。 GDDR6 … GPU内のプロセッサとメモリ部分の接続に関する設計技術のうち
RTX シリーズとかで採用されているもの。 大規模ワークステーションでは HBM というものが採用されている。 一回の転送あたり同時に送れるデータ量 一秒間あたりにどれだけのデータを転送できるかを示す
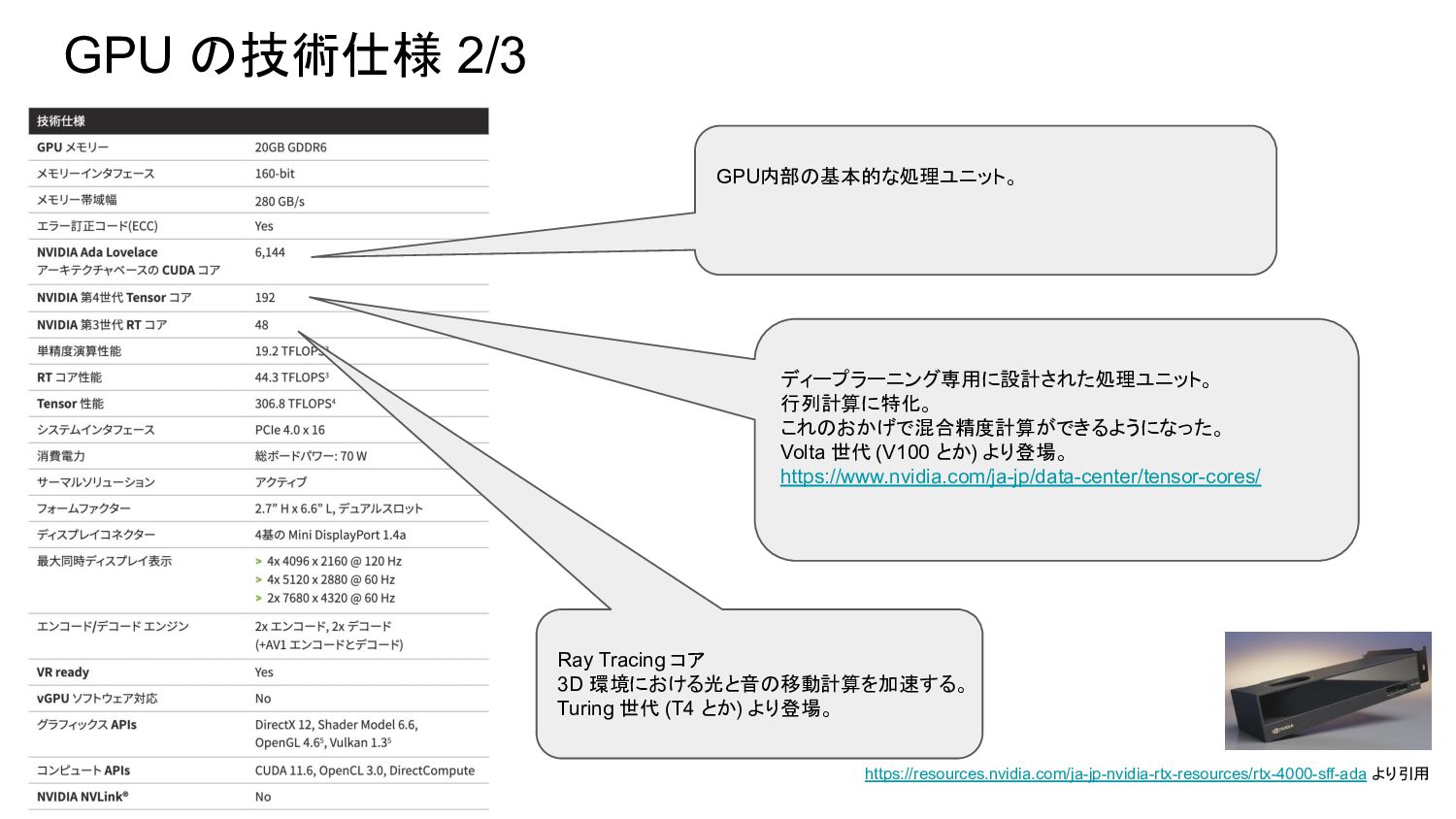
GPU の技術仕様 2/3 https://resources.nvidia.com/ja-jp-nvidia-rtx-resources/rtx-4000-sff-ada より引用 Ray Tracing コア 3D 環境における光と音の移動計算を加速する。
Turing 世代 (T4 とか) より登場。 GPU内部の基本的な処理ユニット。 ディープラーニング専用に設計された処理ユニット。 行列計算に特化。 これのおかげで混合精度計算ができるようになった。 Volta 世代 (V100 とか) より登場。 https://www.nvidia.com/ja-jp/data-center/tensor-cores/
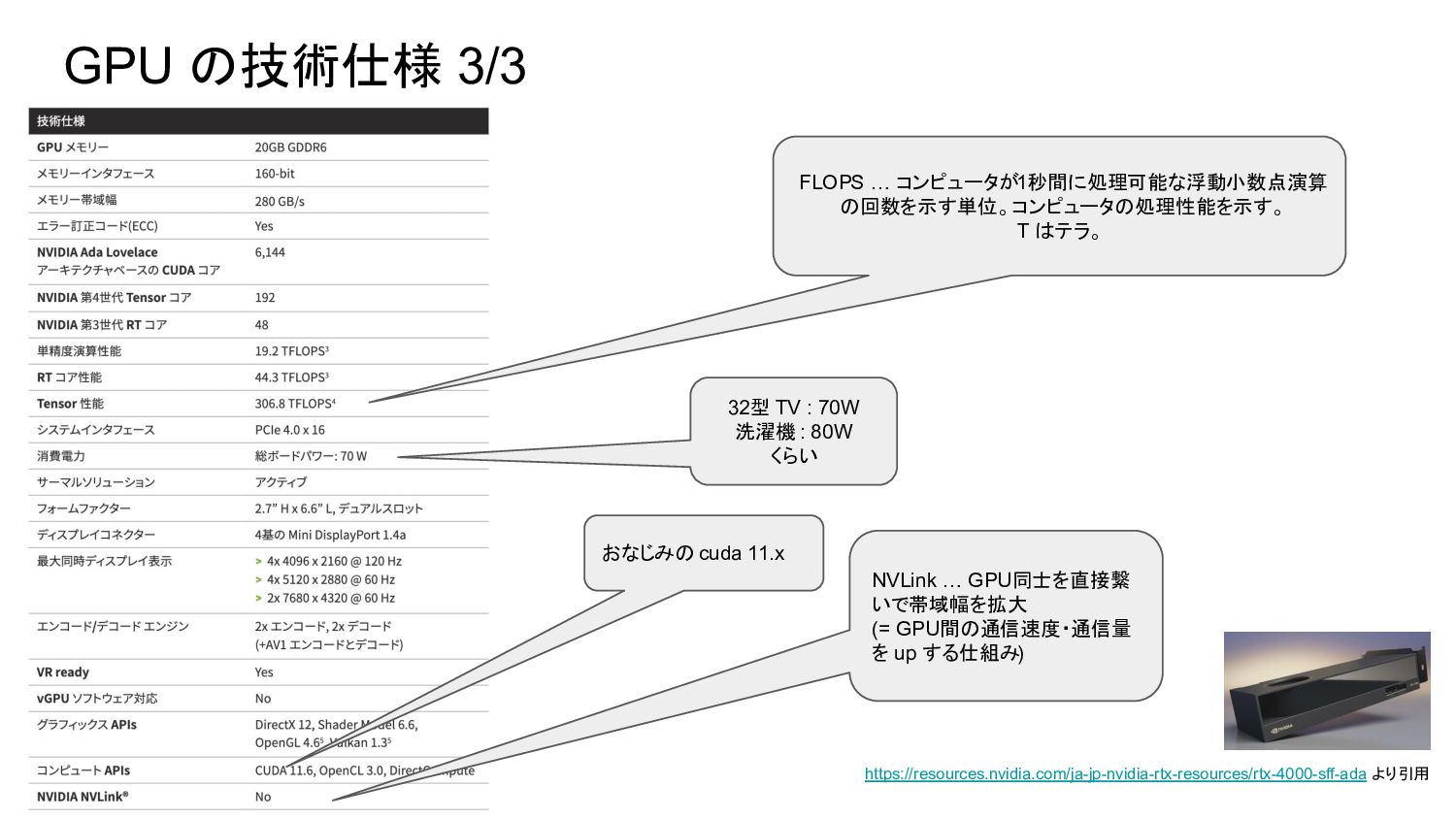
GPU の技術仕様 3/3 https://resources.nvidia.com/ja-jp-nvidia-rtx-resources/rtx-4000-sff-ada より引用 32型 TV : 70W 洗濯機
: 80W くらい NVLink … GPU同士を直接繋 いで帯域幅を拡大 (= GPU間の通信速度・通信量 を up する仕組み) おなじみの cuda 11.x FLOPS … コンピュータが1秒間に処理可能な浮動小数点演算 の回数を示す単位。 コンピュータの処理性能を示す。 T はテラ。
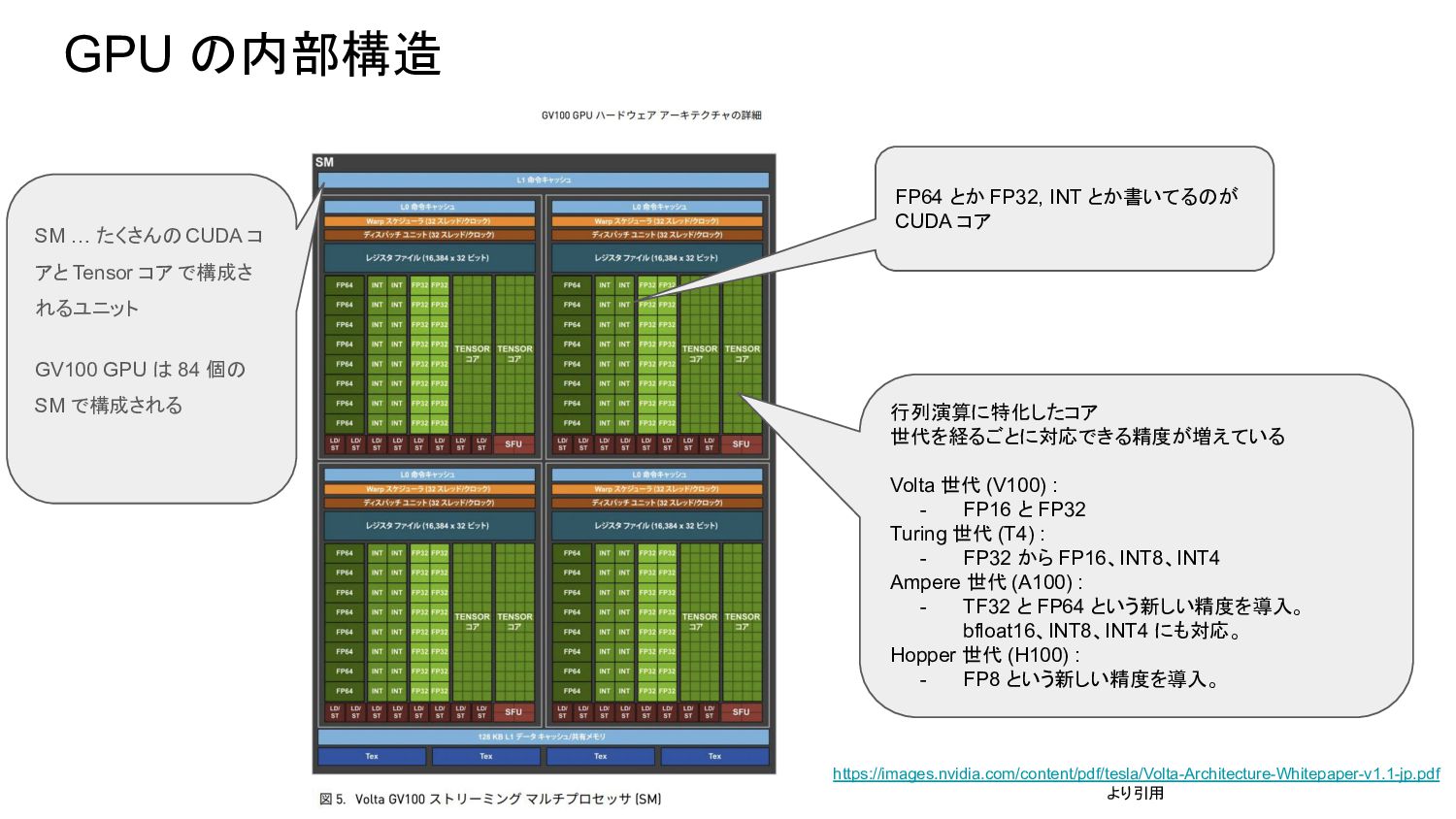
GPU の内部構造 https://images.nvidia.com/content/pdf/tesla/Volta-Architecture-Whitepaper-v1.1-jp.pdf より引用 FP64 とか FP32, INT とか書いてるのが CUDA
コア 行列演算に特化したコア 世代を経るごとに対応できる精度が増えている Volta 世代 (V100) : - FP16 と FP32 Turing 世代 (T4) : - FP32 から FP16、INT8、INT4 Ampere 世代 (A100) : - TF32 と FP64 という新しい精度を導入。 bfloat16、INT8、INT4 にも対応。 Hopper 世代 (H100) : - FP8 という新しい精度を導入。 SM … たくさんの CUDA コ アと Tensor コア で構成さ れるユニット GV100 GPU は 84 個の SM で構成される
GPU の内部構造 - Ada - NVIDIA Ada Lovelace アーキテクチャ -
NVIDIA ADA GPU ARCHITECTURE - A100 - NVIDIA A100 Tensor コア GPU アーキテクチャ - V100 - NVIDIA TESLA V100 GPU アーキテクチャ - RTX 4000 SFF Ada - NVIDIA RTX 4000 SFF Ada 世代グラフィックス カード - NVIDIA GPU の Generation ごとの whitepaper - Ada : NVIDIA ADA GPU ARCHITECTURE - Ampare (A100 とかの A) : NVIDIA AMPERE GA102 GPU ARCHITECTURE - Turing (T4 とかの T): NVIDIA TURING GPU ARCHITECTURE - Volta (V100 とかの V) - Datasheet - V100 : https://images.nvidia.com/content/technologies/volta/pdf/volta-v100-datasheet-update-us-1165301-r5.pdf - A100 : https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-nvidia-us-218850 4-web.pdf
次読むと良さそうな論文
次読むと良さそう - SELF-ATTENTION DOES NOT NEED O(n^2) MEMORY - https://arxiv.org/pdf/2112.05682.pdf
- Flash Attention-2: Faster Attention with Better Parallelism and Work Partitioning - https://arxiv.org/pdf/2307.08691.pdf
contents - 論文「FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness」の紹介
- CPU とか GPU の話 - まとめ
まとめ - Flash Attention 論文を紹介した - メモリのアクセスやデータの転送速度を考慮し、 CUDA で計算することによって高速化と省メモリ化を実 現した
- pytorch 2.0 からはデフォルトで利用できるようになった - 続編となる Flash Attention 2 論文も登場した
おしまい
Appendix
Keywords - FLOPS … コンピュータが1秒間に処理可能な浮動小数点演算の回数を示す単位。 コンピュータの処理性能を示す単位と してよく用いられる。 - GPGPU …
General-purpose computing on graphics processing units, 3Dグラフィックス以外の計算処理も行わせるこ と。 - プロセッサ … コンピュータの構成要素のうち、データの演算や変換、プログラムの実行、他の装置の制御などを担う処理装 置のことを指すことが多い。この意味では「PU」(Processing Unit:プロセッシングユニット)も同義。
参考になりそうなページ - cuda graph - https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/#nccl-support-for-cuda-graphs - numpy code の
compile - https://pytorch.org/blog/compiling-numpy-code/ - flash attention の著者実装 - https://github.com/Dao-AILab/flash-attention - flash attention 使ってみた 記事 - https://zenn.dev/nhandsome/articles/388b2ebb57d5d1 - https://qiita.com/jovyan/items/11deb9d4601e4705a60d - flash attention pytorch 実装 - https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention - flash attention が pytorch 2.0 で公式実装された blog - https://pytorch.org/blog/accelerated-pytorch-2/
参考になりそうなページ - HBM, GDDR6 - https://itandcfd.com/hbm/1140/ - GeForce グラフィックス カード
| NVIDIA - NVIDIA A100 Tensor コア GPU アーキテクチャ - NVLink と NVSwitch: 最速の HPC データ センター プラットフォーム - NVIDIA - CUDAを用いた数値解析の高速化 - いろんな Core - https://www.nvidia.com/ja-jp/data-center/tensor-cores/ - https://images.nvidia.com/content/pdf/tesla/Volta-Architecture-Whitepaper-v1.1-jp.pdf - https://www.gsic.titech.ac.jp/supercon/main/attwiki/index.php?plugin=attach&refer=SupercomputingContest2018& openfile=SuperCon2018-GPU.pdf - mlperf - https://developer.nvidia.com/blog/boosting-mlperf-training-v1-1-performance-with-full-stack-optimization/
参考になりそうなページ - cpu - https://jp.fujitsu.com/family/familyroom/syuppan/family/webs/serial-comp/index2.html - 入力装置 - https://jp.fujitsu.com/family/familyroom/syuppan/family/webs/serial-comp/index5.html -
long-range-arena - https://ai-scholar.tech/articles/transformer/long-range-arena - https://huggingface.co/blog/optimize-llm
Cuda Graphs - cuda 10 より提供開始 - 一連の CUDA カーネルを、個別に起動される一連の操作ではなく、単一のユニット、つまり操作のグラ
フとして定義およびカプセル化可能 - 単一の CPU 操作で複数の GPU 操作を起動するメカニズムを提供 - 起動のオーバーヘッドが削減 - GPU を大規模に使う実験において効果あり https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/#nccl-support-for-cuda-graphs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}