Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
UMAPをざっくりと理解 / Overview of UMAP
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
kaityo256
PRO
May 01, 2025
Programming
6.1k
13
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
UMAPをざっくりと理解 / Overview of UMAP
UMAPをざっくりと理解
kaityo256
PRO
May 01, 2025
More Decks by kaityo256
See All by kaityo256
What is XAI?
kaityo256
PRO
0
89
勾配ブースティングと決定木の話 / gradient boosting and decision trees
kaityo256
PRO
7
1.7k
GNU Makeの使い方 / How to use GNU Make
kaityo256
PRO
16
5.9k
この講義について / 00-setup
kaityo256
PRO
2
450
GitHubによるWebアプリケーションのデプロイ / 07-github-deploy
kaityo256
PRO
2
370
演習:Gitの基本操作 / 04-git-basic
kaityo256
PRO
1
580
演習:Gitの応用操作 / 05-git-advanced
kaityo256
PRO
1
350
演習:GitHubの基本操作 / 06-github-basic
kaityo256
PRO
1
420
バージョン管理とは / 01-a-vcs
kaityo256
PRO
2
400
Other Decks in Programming
See All in Programming
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
190
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
AIエージェントで 変わるAndroid開発環境
takahirom
2
720
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
240
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
130
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
360
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
220
共通化で考えるべきは、実装より公開する型だった
codeegg
0
280
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
200
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
400
人間の目はかわらない、だからJPEGは30年もつ
yuzneri
9
15k
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
550
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
The browser strikes back
jonoalderson
0
1.4k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Transcript
1 25 慶應義塾大学理工学部物理情報工学科 渡辺宙志 2025年5月1日 研究室ミーティング UMAPをざっくりと理解 UMAP: Uniform Manifold
Approximation and Projection for Dimension Reduction Leland McInnes, John Healy, James Melville, arXiv:1802.0326
2 25 UMAPとは? Uniform Manifold Approximation and Projection for Dimension
Reduction 次元削減手法の一つ 𝑓( Ԧ 𝑥) = Ԧ 𝑦 入力データ 高次元ベクトル 出力データ 低次元ベクトル (D=2 or 3) 広く使われている次元削減手法であるt-SNEに比べてクラスタ間の 分離に強く、計算負荷が小さい
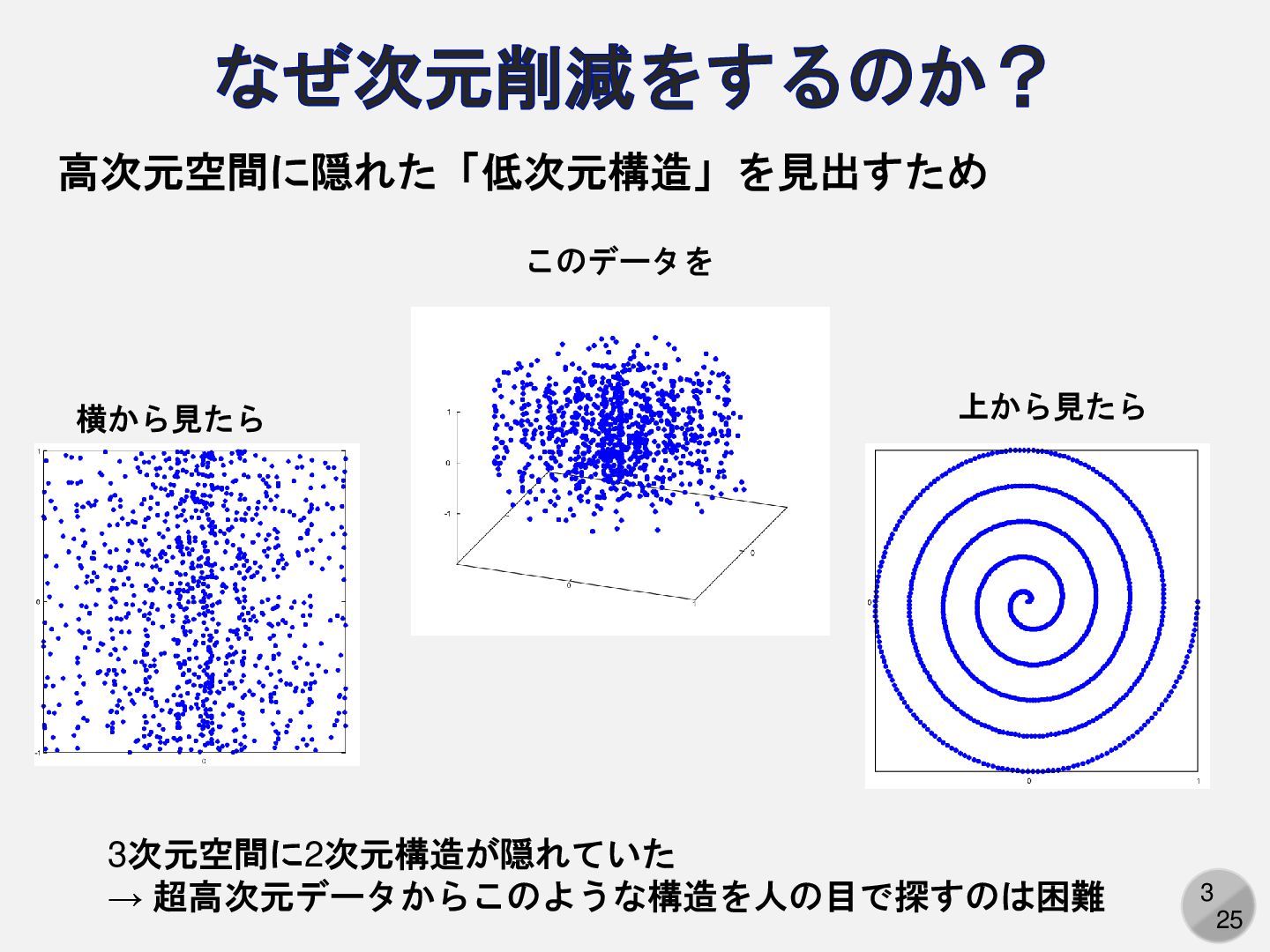
3 25 なぜ次元削減をするのか? 高次元空間に隠れた「低次元構造」を見出すため 上から見たら 横から見たら 3次元空間に2次元構造が隠れていた → 超高次元データからこのような構造を人の目で探すのは困難 このデータを
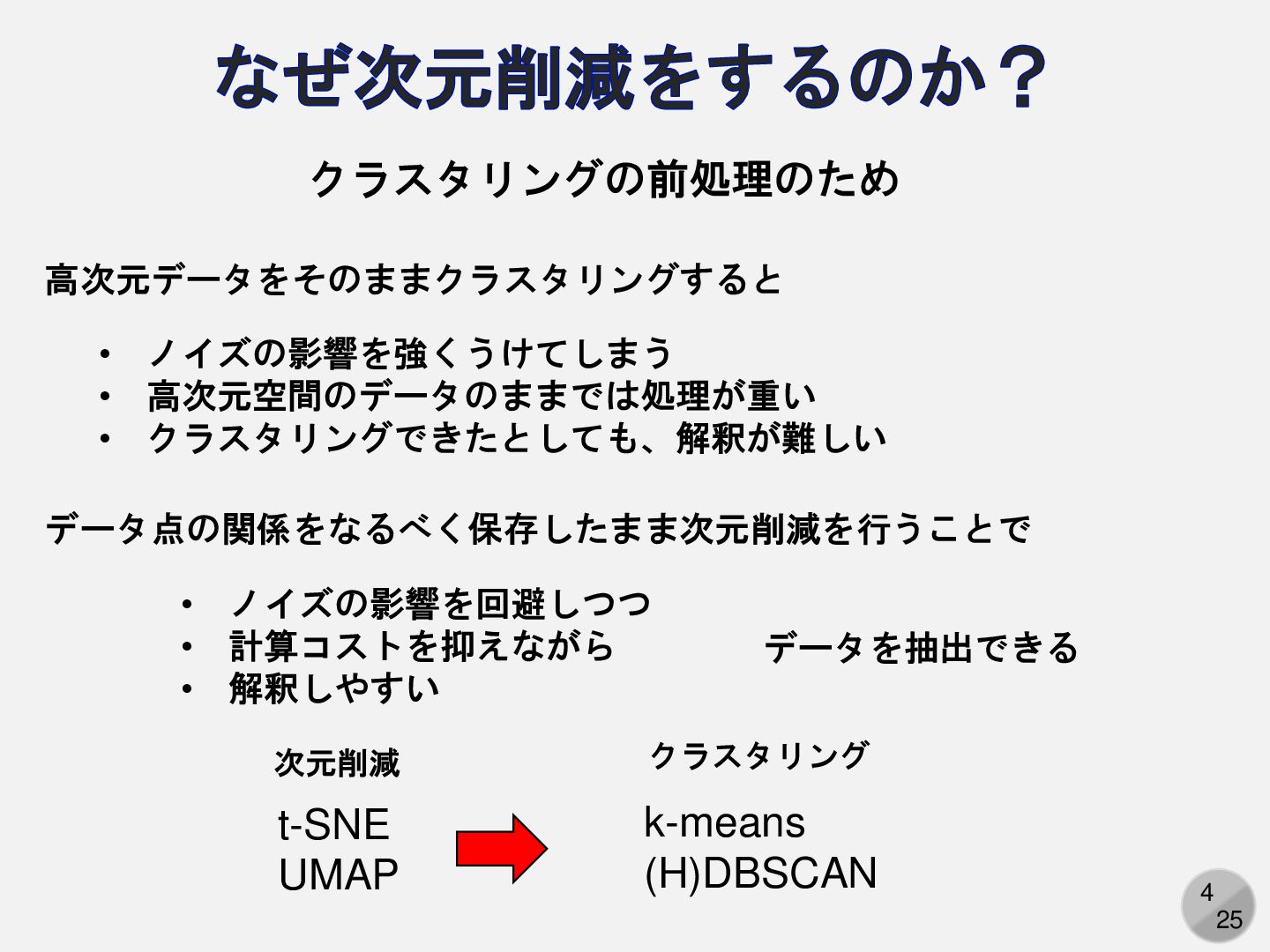
4 25 なぜ次元削減をするのか? • ノイズの影響を強くうけてしまう • 高次元空間のデータのままでは処理が重い • クラスタリングできたとしても、解釈が難しい データ点の関係をなるべく保存したまま次元削減を行うことで
• ノイズの影響を回避しつつ • 計算コストを抑えながら • 解釈しやすい データを抽出できる t-SNE UMAP 高次元データをそのままクラスタリングすると 次元削減 クラスタリング k-means (H)DBSCAN クラスタリングの前処理のため
5 25 次元削減の例(MNIST) 𝑥𝑖 = (0.0, 0.0, ... 0.4, 0.8,
..., 0.0) 784次元ベクトル 各手書き数字データは784次元空間上の点 これが7万点ある 784次元から2次元へ埋め込み 𝑦𝑖 = (0.2, 0.8) Ԧ 𝑦 = 𝑓( Ԧ 𝑥) UMAPには「数字が10種類ある」と教えていないのに10個の クラスタに分離できた 元のデータは784次元空間上の点 2次元ベクトル
6 25 次元削減でしたいこと 元の空間で近い点は、変換後の空間でも近くしたい | Ԧ 𝑥𝑖 − Ԧ 𝑥𝑗
|が小さいなら | Ԧ 𝑦𝑖 − Ԧ 𝑦𝑗 |も小さくしたい 𝑓( Ԧ 𝑥) = Ԧ 𝑦
7 25 UMAPのアルゴリズム 1. 通常のユークリッド距離でk個の隣接データ点を探す 2. k個の隣接データ点から距離のスケールパラメータを決める 3. 元の空間各点の接続重みを計算する 4.
接続重みを対称化する 5. 削減後の空間の接続重みを定義する 6. 元の空間と次元削減後の空間の接続重みの交差エントロ ピーを最小化するように低次元埋め込みを行う
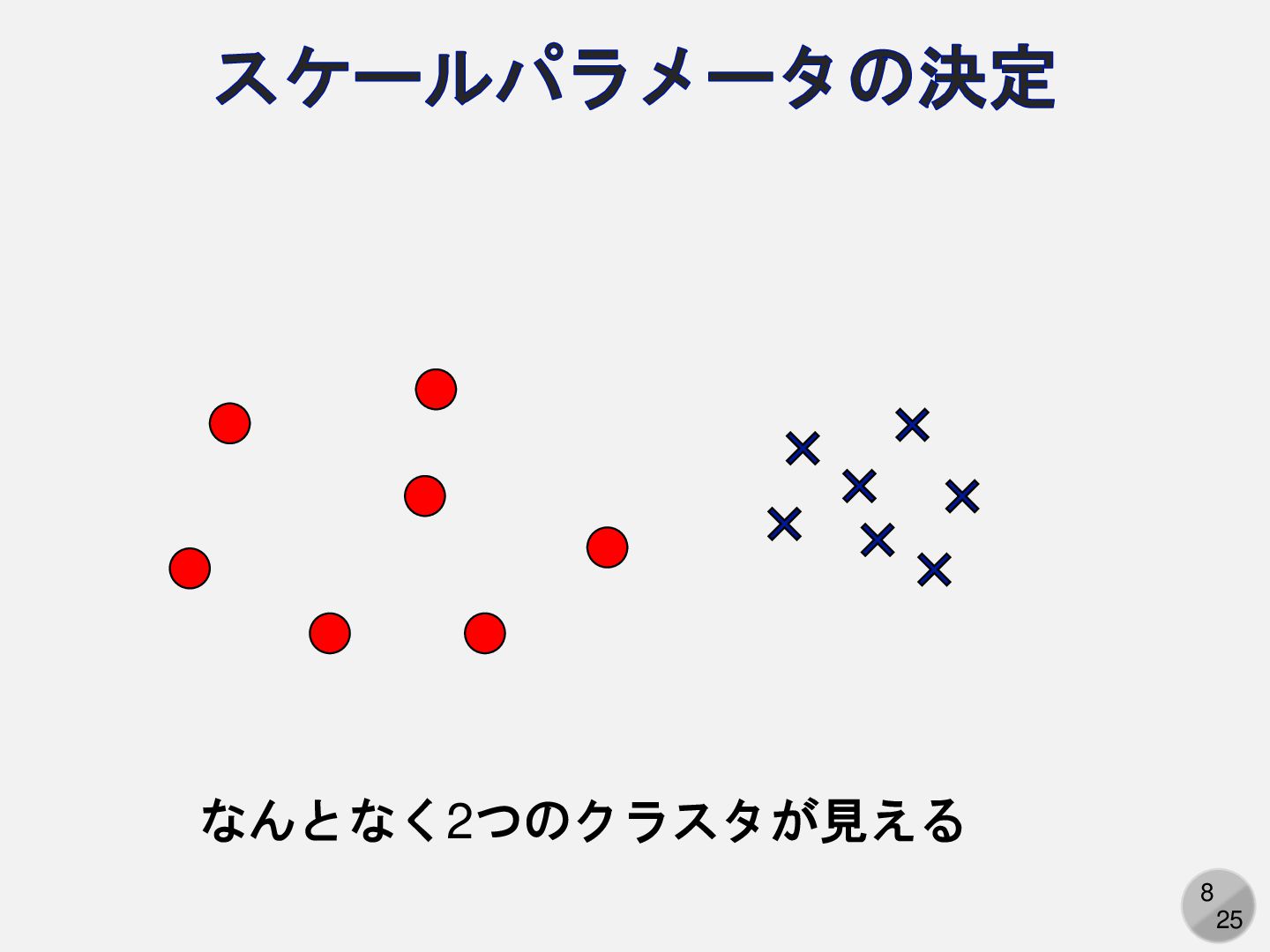
8 25 スケールパラメータの決定 なんとなく2つのクラスタが見える
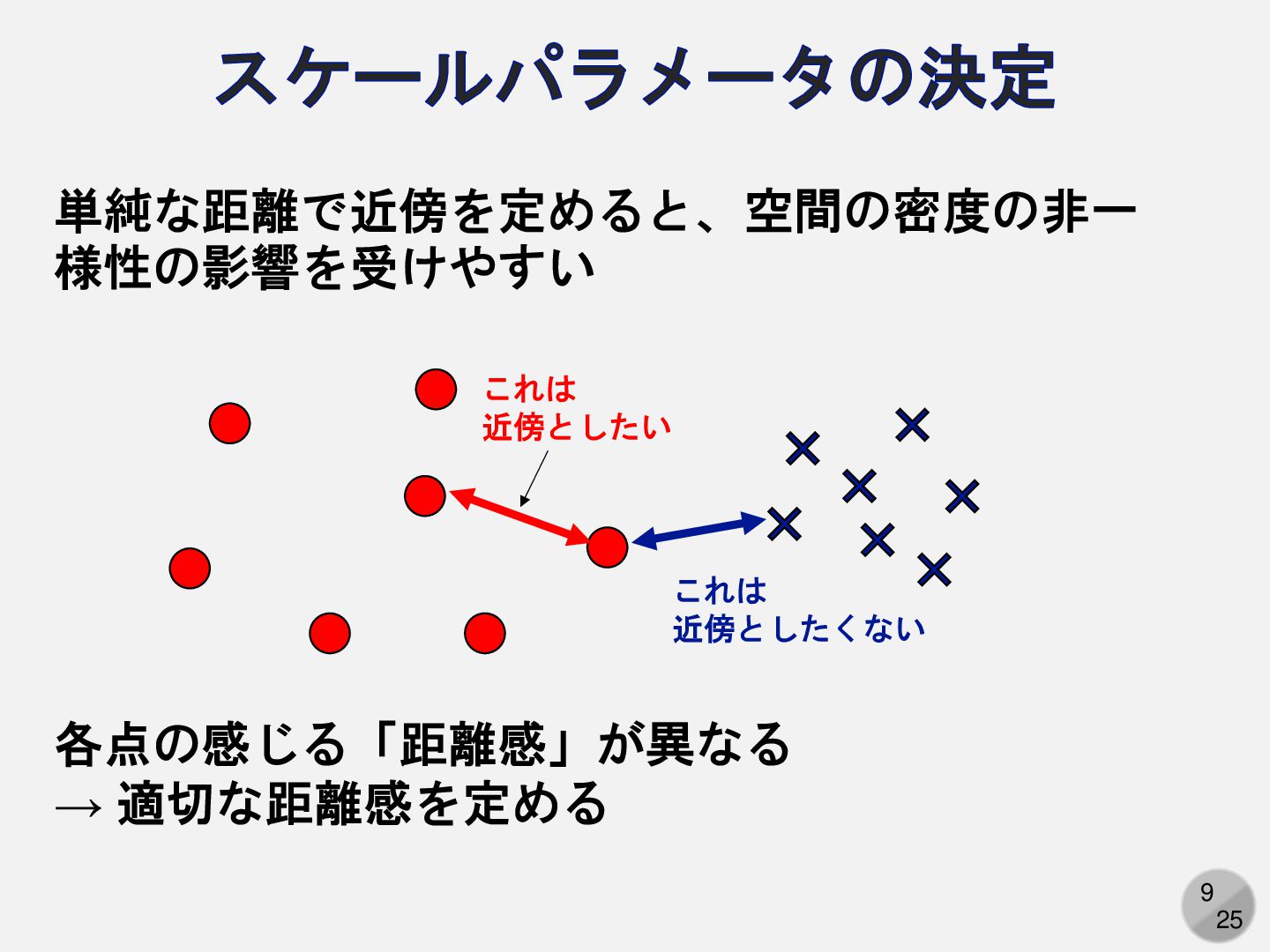
9 25 スケールパラメータの決定 各点の感じる「距離感」が異なる → 適切な距離感を定める これは 近傍としたい これは 近傍としたくない
単純な距離で近傍を定めると、空間の密度の非一 様性の影響を受けやすい
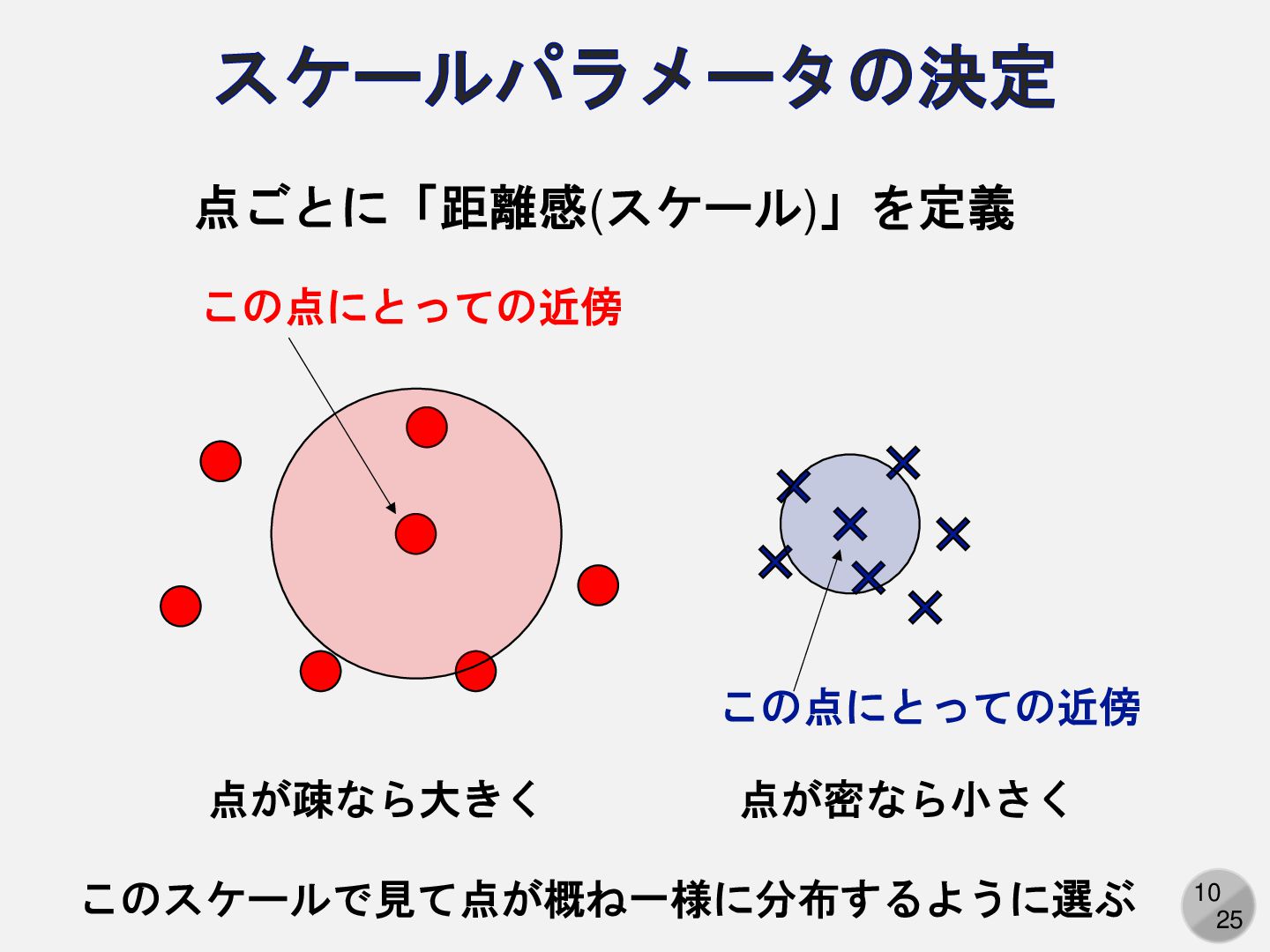
10 25 スケールパラメータの決定 この点にとっての近傍 この点にとっての近傍 点ごとに「距離感(スケール)」を定義 このスケールで見て点が概ね一様に分布するように選ぶ 点が疎なら大きく 点が密なら小さく
11 25 スケールパラメータの決定 𝐷𝑌 :埋め込み次元 𝑟𝑖𝑗 :点𝑖, 𝑗間の距離 𝜌𝑖 :点𝑖の最近接点への距離
Ω𝑖 :点𝑖の近傍の集合 以上の情報から、点𝑖のスケールパラメータ𝜎𝑖 を以下のように定める 𝑗∈Ω𝑖 exp − (𝑟𝑖𝑗 − 𝜌𝑖 ) 𝜎𝑖 = log2 𝐷𝑌 実際には二分探索で𝜎𝑖 を求める
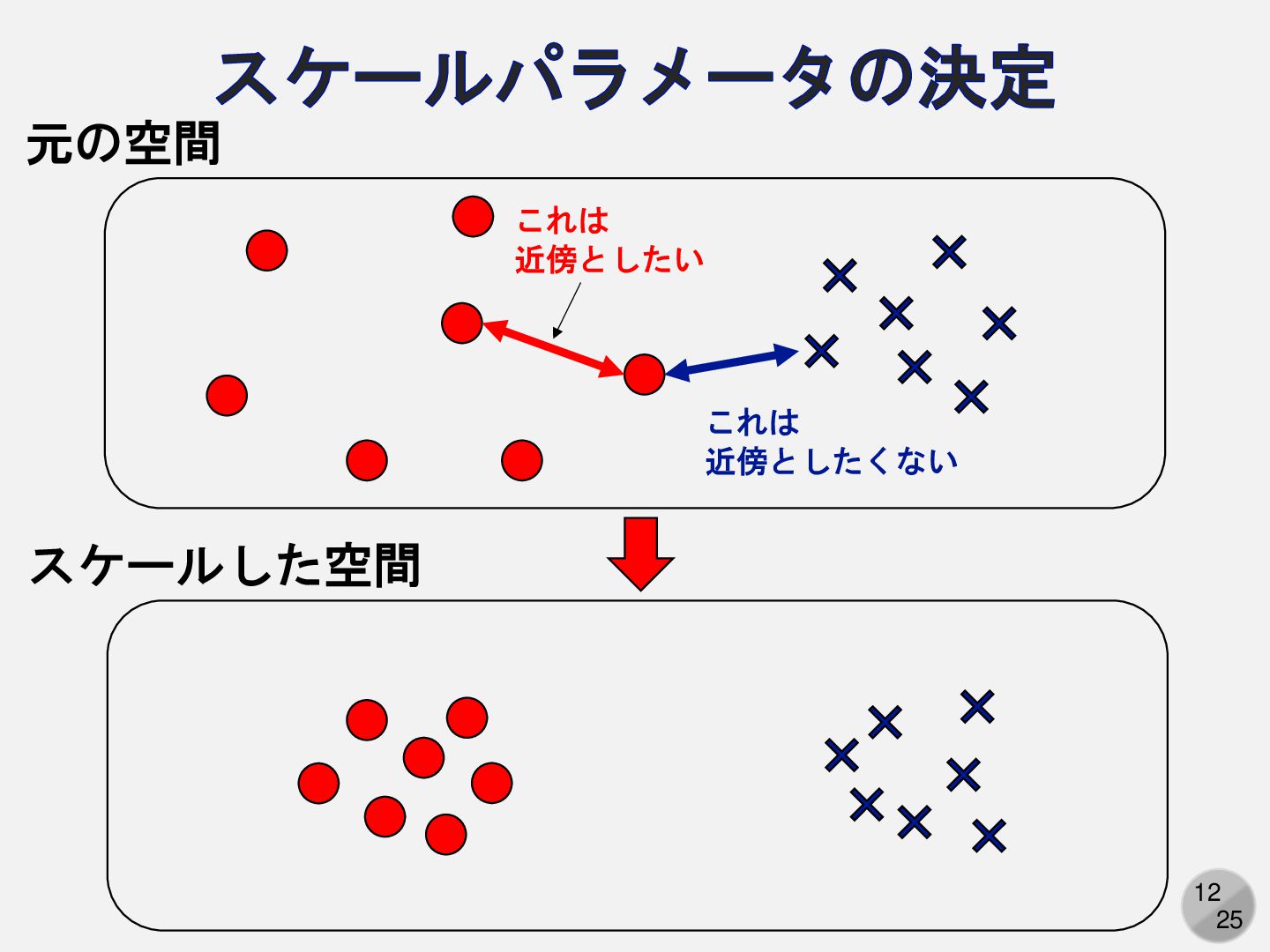
12 25 スケールパラメータの決定 元の空間 スケールした空間 これは 近傍としたい これは 近傍としたくない
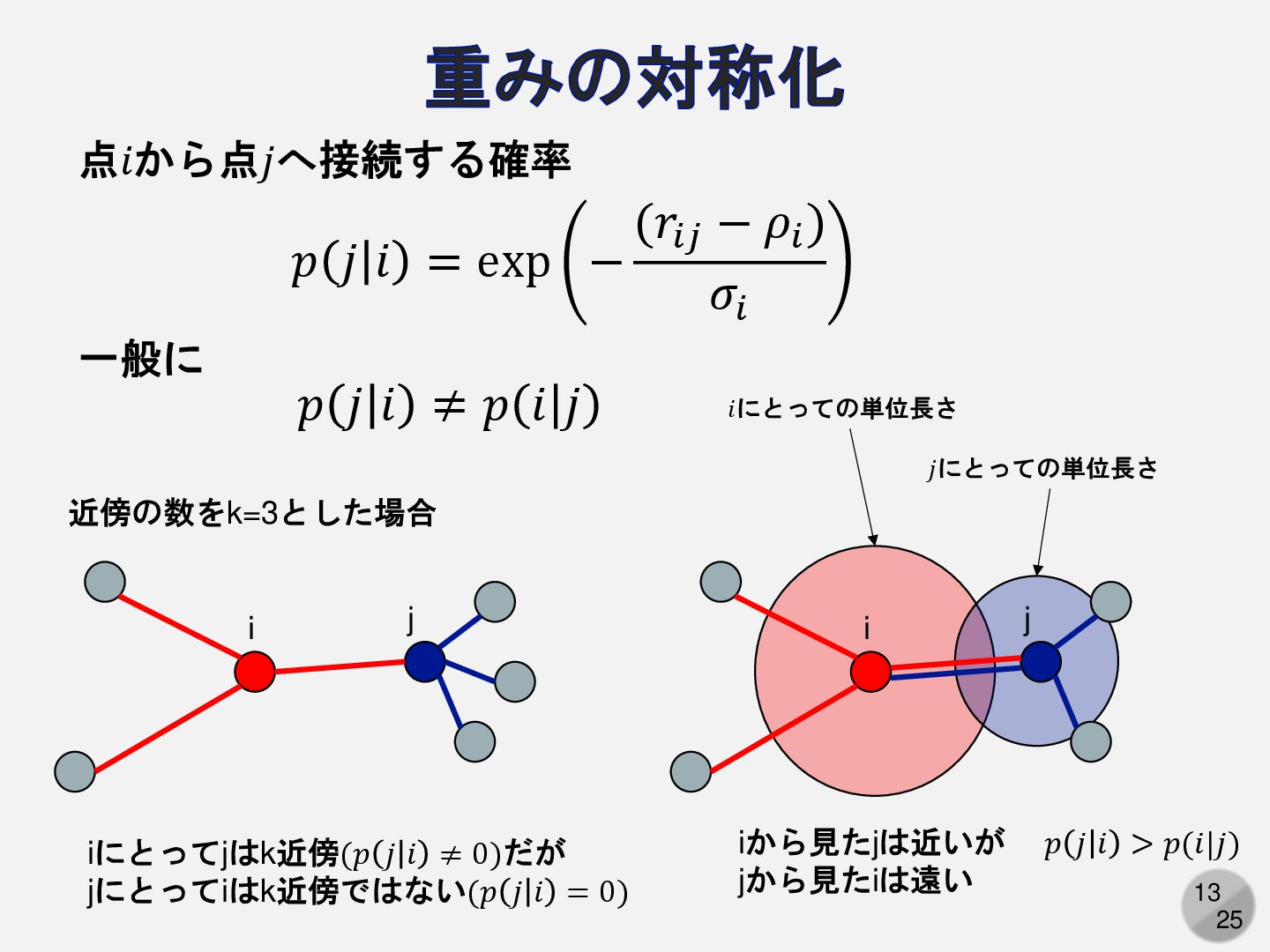
13 25 重みの対称化 近傍の数をk=3とした場合 i j iにとってjはk近傍(𝑝 𝑗 𝑖 ≠
0)だが jにとってiはk近傍ではない(𝑝 𝑗 𝑖 = 0) i j iから見たjは近いが jから見たiは遠い 𝑝 𝑗 𝑖 = exp − (𝑟𝑖𝑗 − 𝜌𝑖 ) 𝜎𝑖 点𝑖から点𝑗へ接続する確率 𝑝 𝑗 𝑖 ≠ 𝑝 𝑖 𝑗 一般に 𝑝 𝑗 𝑖 > 𝑝(𝑖|𝑗) 𝑖にとっての単位長さ 𝑗にとっての単位長さ
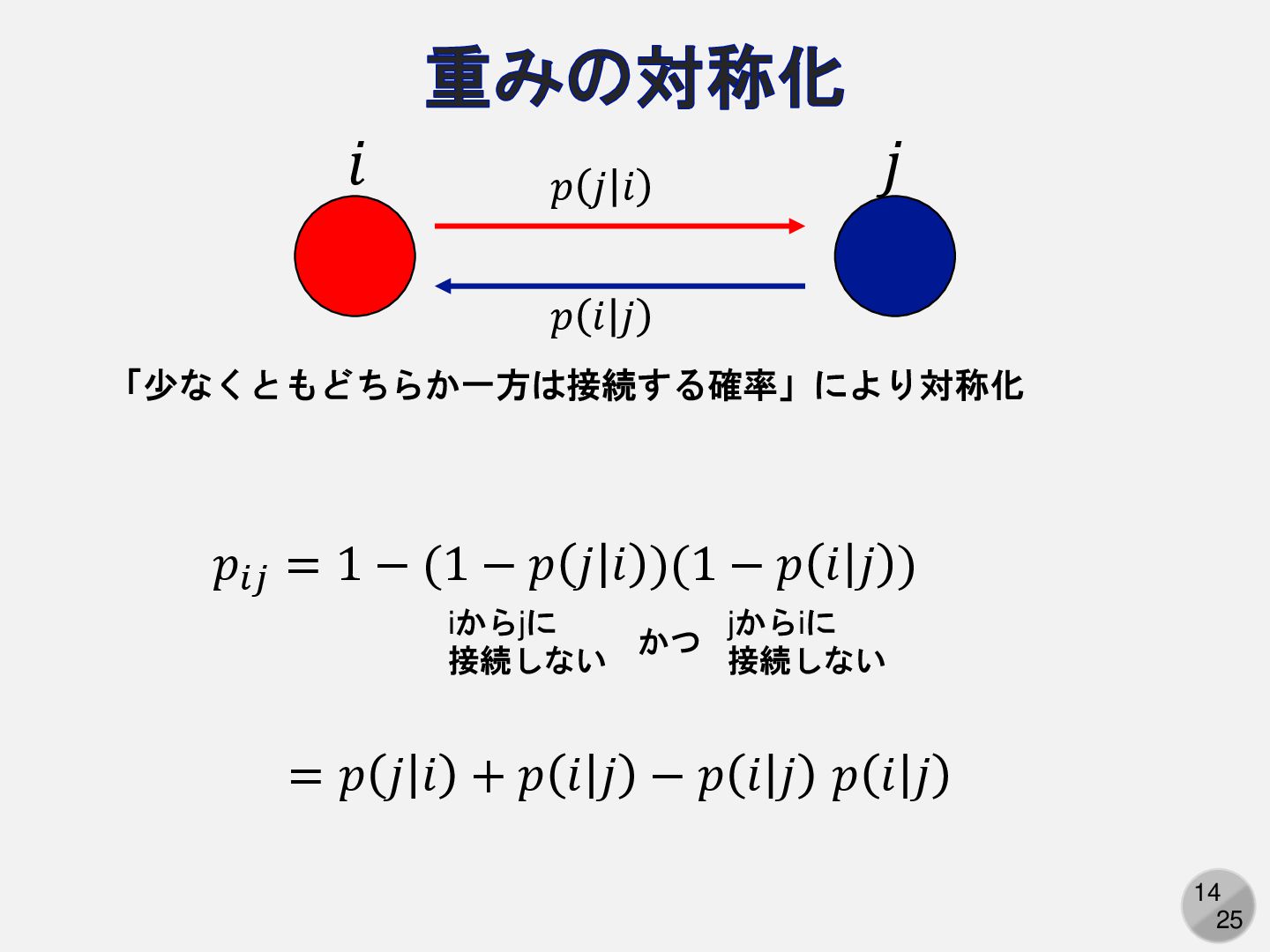
14 25 重みの対称化 𝑝𝑖𝑗 = 1 − (1 − 𝑝
𝑗 𝑖 )(1 − 𝑝 𝑖 𝑗 ) 「少なくともどちらか一方は接続する確率」により対称化 iからjに 接続しない jからiに 接続しない かつ 𝑖 𝑗 𝑝 𝑗 𝑖 𝑝 𝑖 𝑗 = 𝑝 𝑗 𝑖 + 𝑝 𝑖 𝑗 − 𝑝 𝑖 𝑗 𝑝 𝑖 𝑗
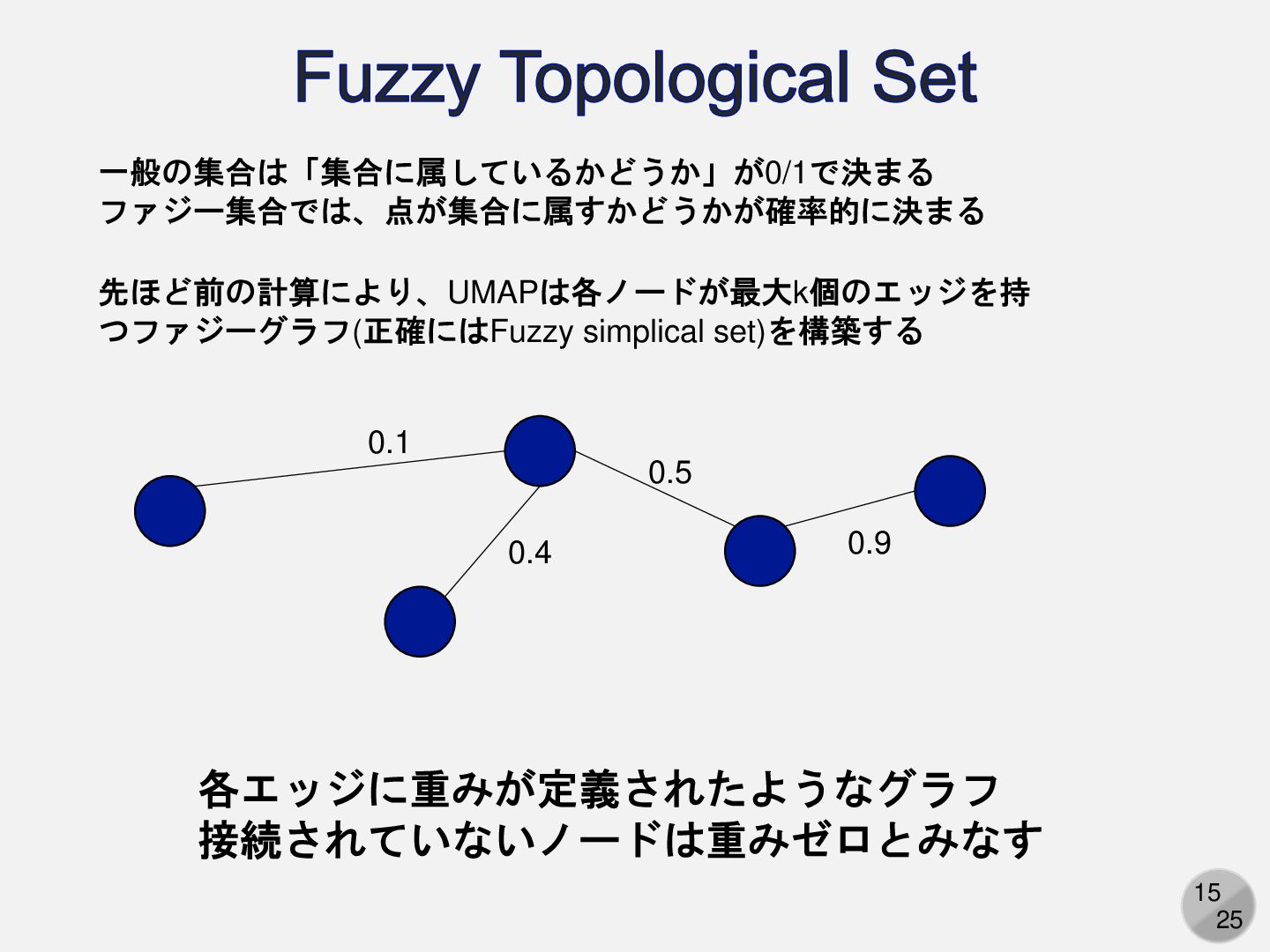
15 25 Fuzzy Topological Set 一般の集合は「集合に属しているかどうか」が0/1で決まる ファジー集合では、点が集合に属すかどうかが確率的に決まる 先ほど前の計算により、UMAPは各ノードが最大k個のエッジを持 つファジーグラフ(正確にはFuzzy simplical
set)を構築する 0.1 0.4 0.9 0.5 各エッジに重みが定義されたようなグラフ 接続されていないノードは重みゼロとみなす
16 25 低次元埋め込み 𝑓( Ԧ 𝑥) = Ԧ 𝑦 高次元空間
低次元空間 各エッジの重みが同じようになるように低次元に埋め込む (低次元で対応するデータ点の位置を決める)
17 25 距離のスムージング クラスター内で点の距離が近くなりすぎるのを防ぐため「最低距離」を 定め、それを用いて距離のスムージングを行う 𝑦𝑖𝑗 :次元削減後の点𝑖, 𝑗間のユークリッド距離 𝑙0 :最低距離(ハイパーパラメータ)
𝑎, 𝑏: 𝑙0 から決まるパラメータ 𝑞𝑖𝑗 = 1 1 + 𝑎𝑦𝑖𝑗 2𝑏 上記を用いて ただし𝑎, 𝑏は𝜙 𝑑 = 1 + 𝑎𝑑2𝑏 −1 が以下の関数に最も近くなるように フィッティングで決める 𝜓 𝑑 = ቊ = 1 𝑑 ≤ 𝑙0 = exp(−(𝑑 − 𝑙0 )) otherwise
18 25 距離のスムージング 𝑞𝑖𝑗 = 1 1 + 𝑎𝑦𝑖𝑗 2𝑏
以下を次元削減後の空間の点𝑖, 𝑗間の重みとする • 0 < 𝑞𝑖𝑗 ≤ 1を満たす • 距離𝑦𝑖𝑗 が小さいほど重み𝑞𝑖𝑗 が大きくなる • 𝑎 = 𝑏 = 1の場合、Studentのt分布に帰着 • 𝑙0 より小さい場合の重みの変化を無視する 次元削減前の重み𝑝𝑖𝑗 と、次元削減後の重み𝑞𝑖𝑗 をなるべく近づける最適化を行う
19 25 コスト関数 Ƹ 𝑝𝑖𝑗 :元の空間で𝑖, 𝑗が接続しているか 1:接続、0:接続していない ො 𝑞𝑖,𝑗
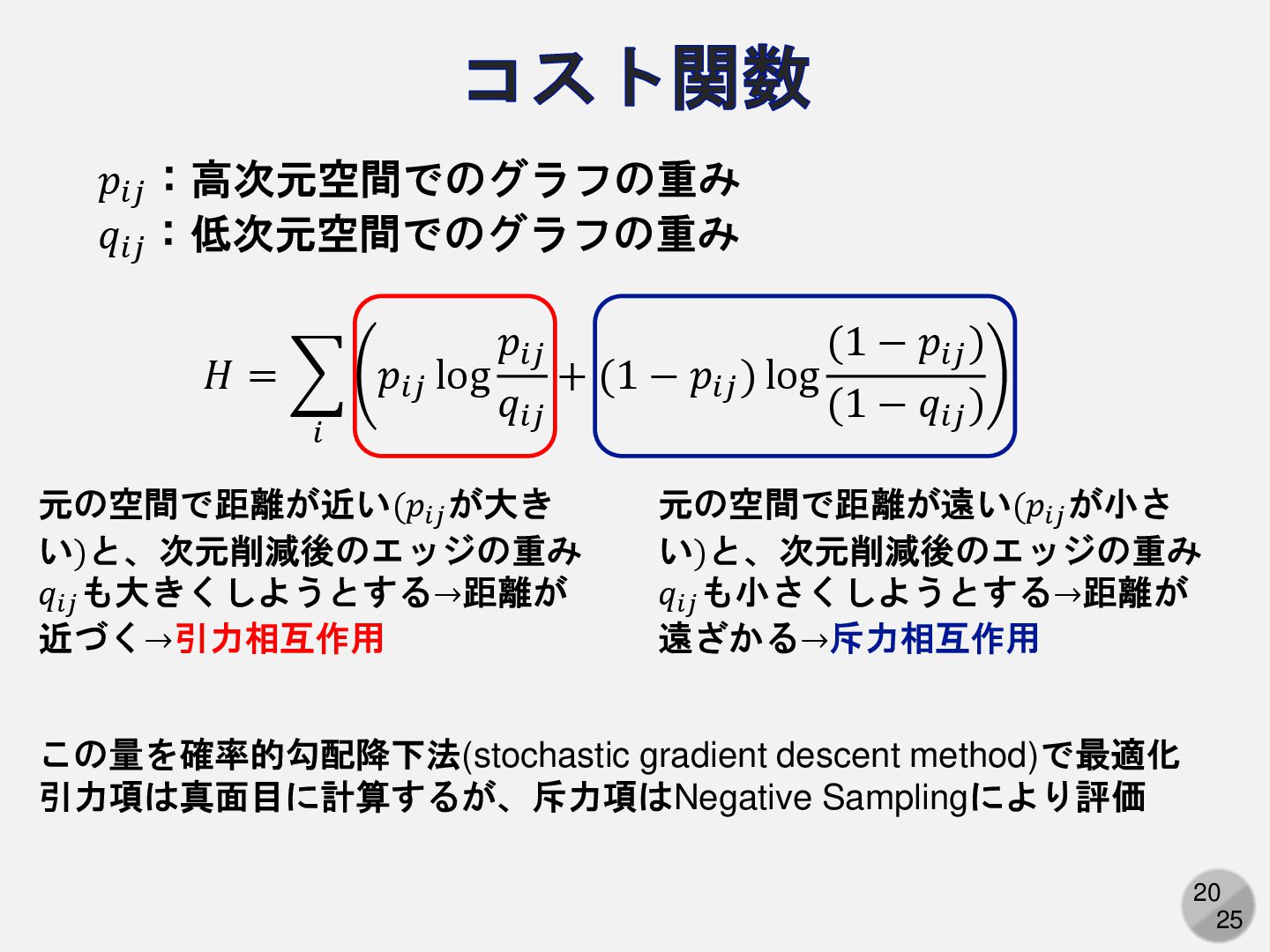
:次元削減後の空間でエッジ𝑖が接続しているか 𝐻 = 𝑖,𝑗 𝑃 Ƹ 𝑝𝑖𝑗 = 1 log 𝑃 Ƹ 𝑝𝑖𝑗 = 1 𝑃(𝑞𝑖𝑗 = 1) + 𝑃 Ƹ 𝑝𝑖𝑗 = 0 log 𝑃 Ƹ 𝑝𝑖𝑗 = 0 𝑃(ො 𝑞𝑖𝑗 = 0) この量を最小化するように低次元配置を決める = 𝑖 𝑝𝑖𝑗 log 𝑝𝑖𝑗 𝑞𝑖𝑗 + (1 − 𝑝𝑖𝑗 ) log (1 − 𝑝𝑖𝑗 ) (1 − 𝑞𝑖𝑗 ) ※ 数式上はKLダイバージェンスに見えるが、論文には交差エントロピーと書いてある
20 25 コスト関数 元の空間で距離が近い(𝑝𝑖𝑗 が大き い)と、次元削減後のエッジの重み 𝑞𝑖𝑗 も大きくしようとする→距離が 近づく→引力相互作用 元の空間で距離が遠い(𝑝𝑖𝑗
が小さ い)と、次元削減後のエッジの重み 𝑞𝑖𝑗 も小さくしようとする→距離が 遠ざかる→斥力相互作用 この量を確率的勾配降下法(stochastic gradient descent method)で最適化 引力項は真面目に計算するが、斥力項はNegative Samplingにより評価 𝐻 = 𝑖 𝑝𝑖𝑗 log 𝑝𝑖𝑗 𝑞𝑖𝑗 + (1 − 𝑝𝑖𝑗 ) log (1 − 𝑝𝑖𝑗 ) (1 − 𝑞𝑖𝑗 ) 𝑝𝑖𝑗 :高次元空間でのグラフの重み 𝑞𝑖𝑗 :低次元空間でのグラフの重み
21 25 ハイパーパラメタの影響 少ない ← 近傍点数k → 大きい 最低距離 短い
長い ↑ ↓ 近傍点数が大きすぎる→小さな構造を取りこぼす 最低距離が長すぎる→クラスタを分離できない 異なるクラスタが 重なっている クラスタが 接近しすぎている
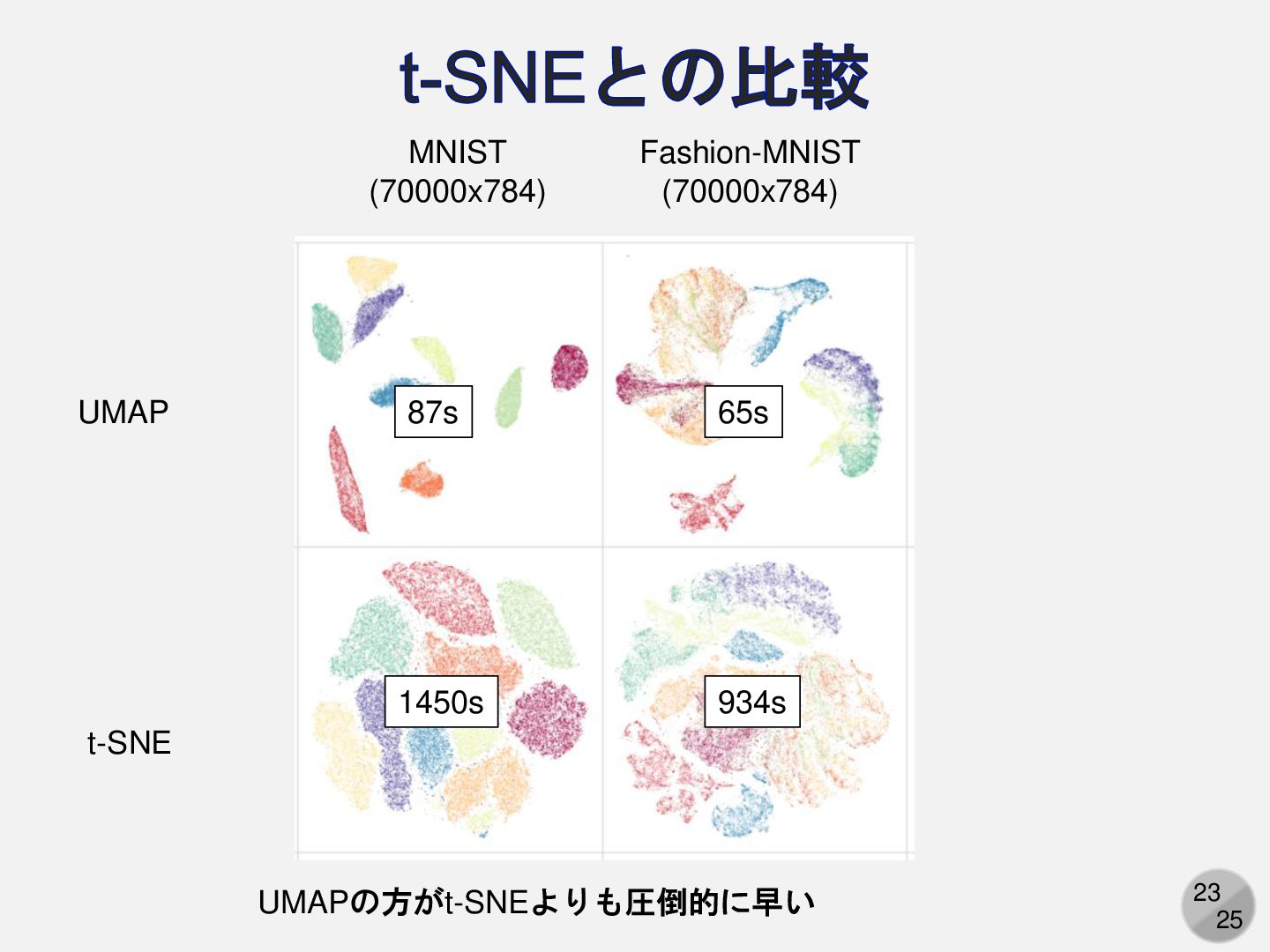
22 25 t-SNEとの比較 t-SNEよりもUMAPの方がクラスタが明瞭に分かれている MNIST (70000x784) Fashion-MNIST (70000x784) UMAP t-SNE
23 25 t-SNEとの比較 MNIST (70000x784) Fashion-MNIST (70000x784) UMAP t-SNE UMAPの方がt-SNEよりも圧倒的に早い
87s 65s 1450s 934s
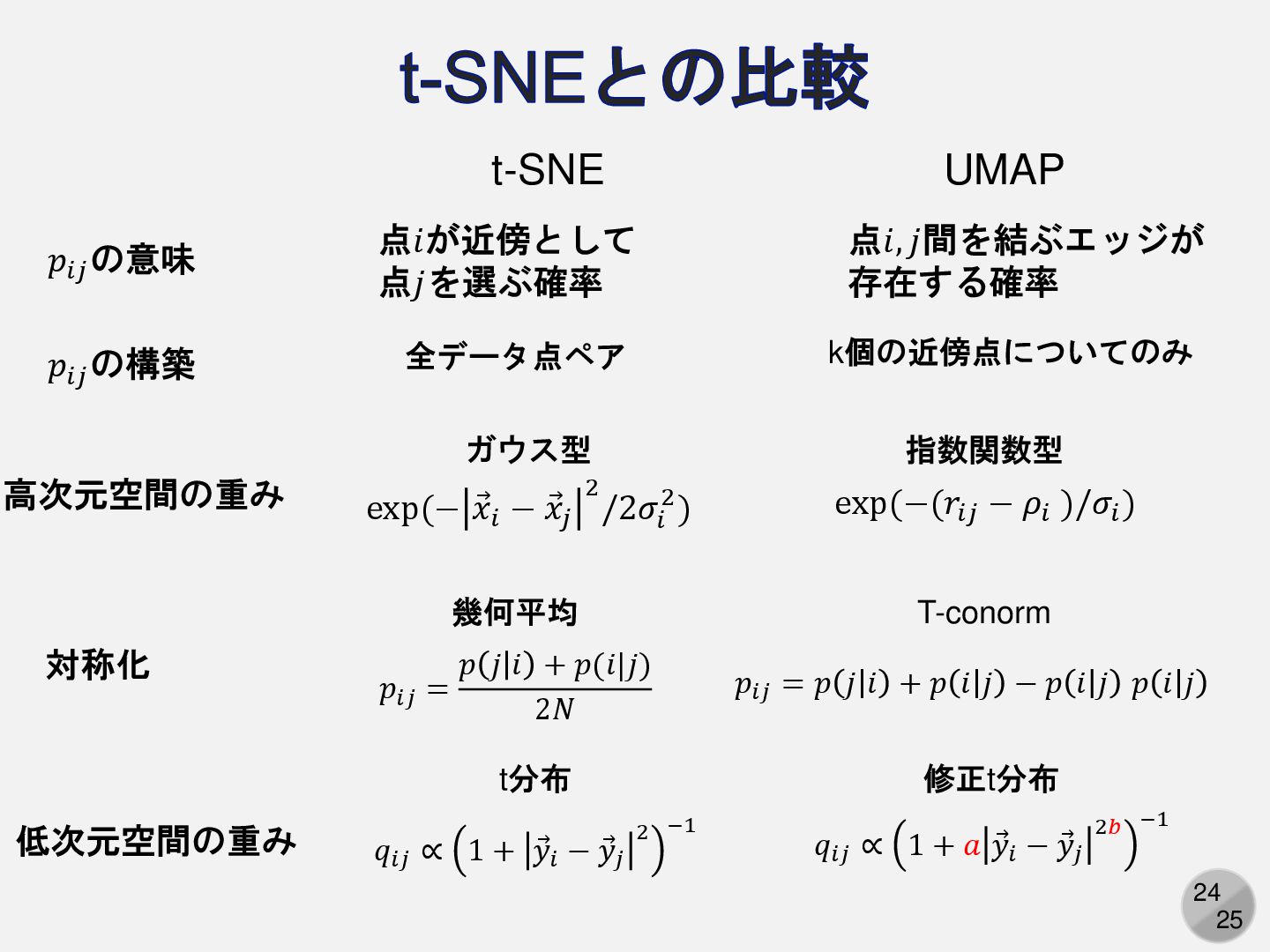
24 25 t-SNEとの比較 t-SNE UMAP 高次元空間の重み exp(− Ԧ 𝑥𝑖 −
Ԧ 𝑥𝑗 2 /2𝜎𝑖 2) ガウス型 exp(−(𝑟𝑖𝑗 − 𝜌𝑖 )/𝜎𝑖 ) 指数関数型 低次元空間の重み t分布 𝑞𝑖𝑗 ∝ 1 + Ԧ 𝑦𝑖 − Ԧ 𝑦𝑗 2 −1 修正t分布 𝑞𝑖𝑗 ∝ 1 + 𝑎 Ԧ 𝑦𝑖 − Ԧ 𝑦𝑗 2𝑏 −1 𝑝𝑖𝑗 の構築 全データ点ペア 𝑝𝑖𝑗 の意味 点𝑖が近傍として 点𝑗を選ぶ確率 点𝑖, 𝑗間を結ぶエッジが 存在する確率 k個の近傍点についてのみ 対称化 𝑝𝑖𝑗 = 𝑝 𝑗 𝑖 + 𝑝(𝑖|𝑗) 2𝑁 幾何平均 𝑝𝑖𝑗 = 𝑝 𝑗 𝑖 + 𝑝 𝑖 𝑗 − 𝑝 𝑖 𝑗 𝑝 𝑖 𝑗 T-conorm
25 25 まとめ • UMAPはファジートポロジカル構造に着目することで次元削減する アルゴリズム • 最初にk個の近傍点を探し、その近傍点の重みのみを考えるため、 計算が軽い •
重要なハイパーパラメタは近傍点数kと最低距離min_dist 近傍点数: 注目したい領域のサイズを決める 小さすぎるとノイズに埋もれ、大きすぎると小さい構造を取りこぼす 最低距離: 引力が働く距離の下限。これより小さいと引力が抑制される 大きすぎるとクラスターがつぶれ、小さすぎるとクラスターが分離できない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}