#NLP #OpenDomainQuestionAnswering
카카오엔터프라이즈 AI Assistant 팀에서는 대량의 텍스트 데이터 내에서 이용자가 물어보는 내용에 대한 답을 빠르고 정확하게 찾아주는 시스템인 오픈도메인 질의응답 모델을 연구하고 있습니다. 본 세션에서는 AI Assistant팀의 오픈도메인 질의응답 모델에 대해 소개하고, 빠른 속도와 높은 정확도를 어떻게 달성했는지 설명합니다.
발표자 : phil.i
카카오엔터프라이즈 AI Assistant 팀 필입니다. 질의응답 시스템을 비롯한 다양한 한국어 자연어처리 기술을 연구하고 있습니다.
{kind=link}
{kind=link}
{kind=link}
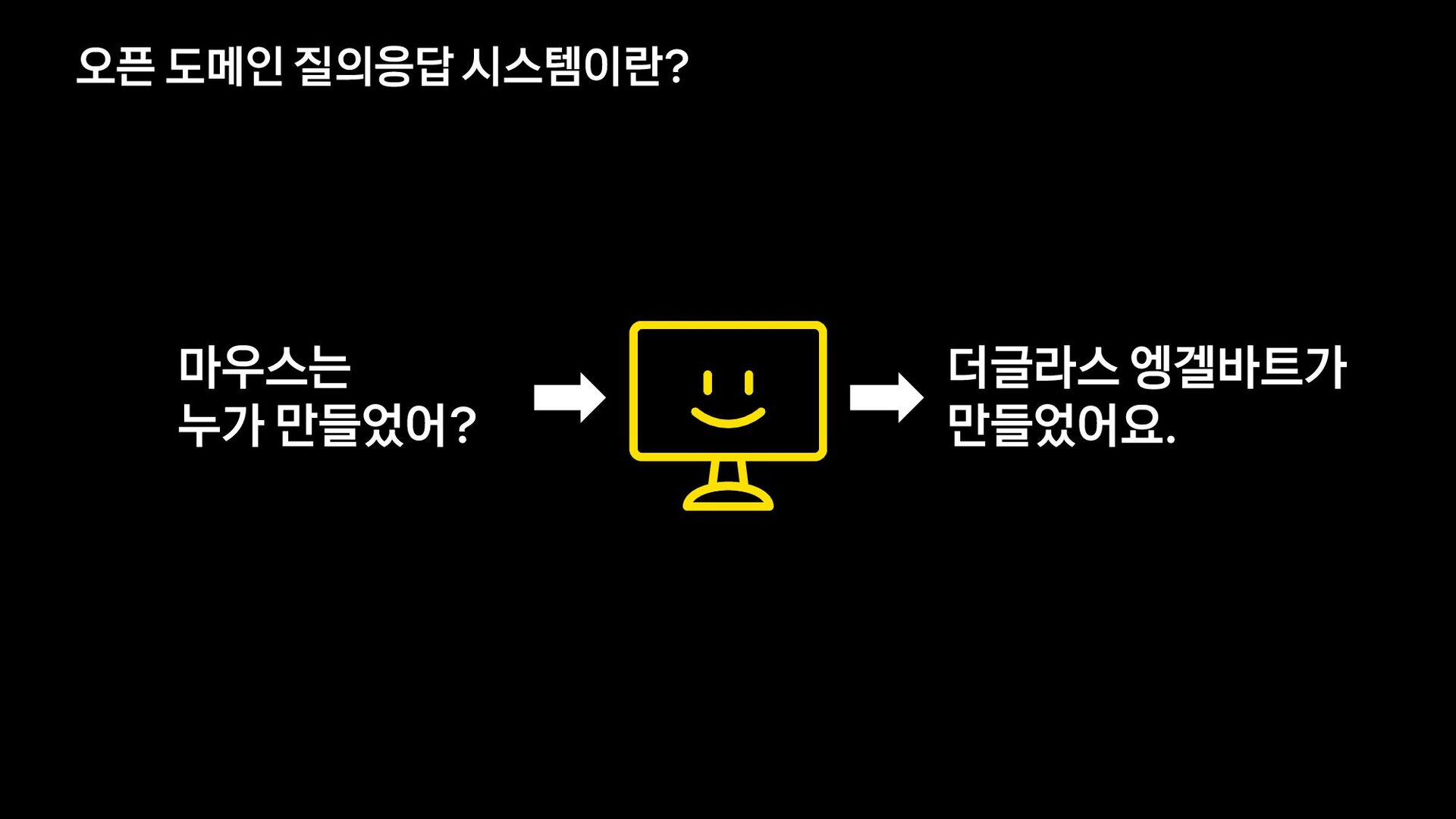{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
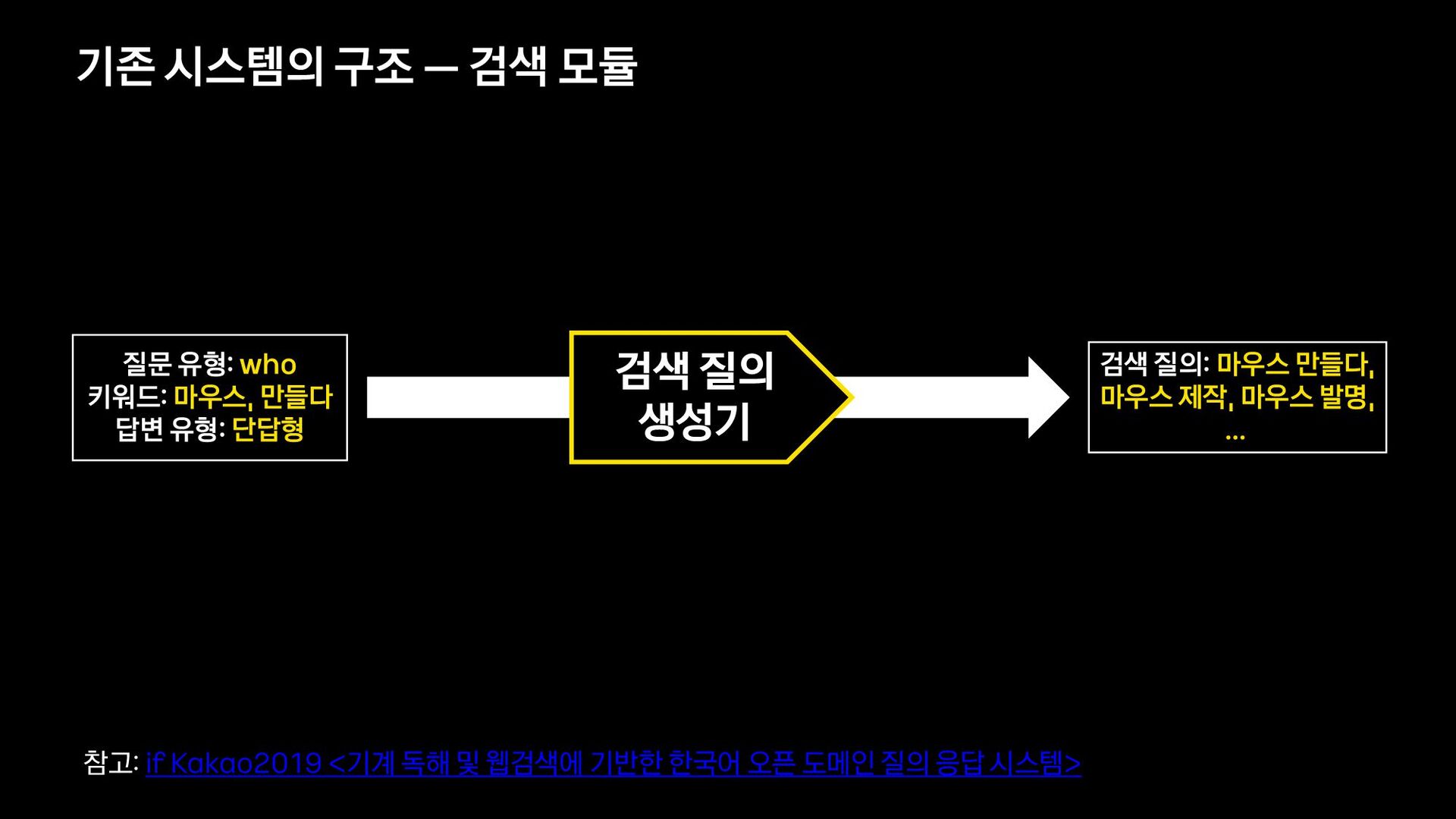{kind=link}
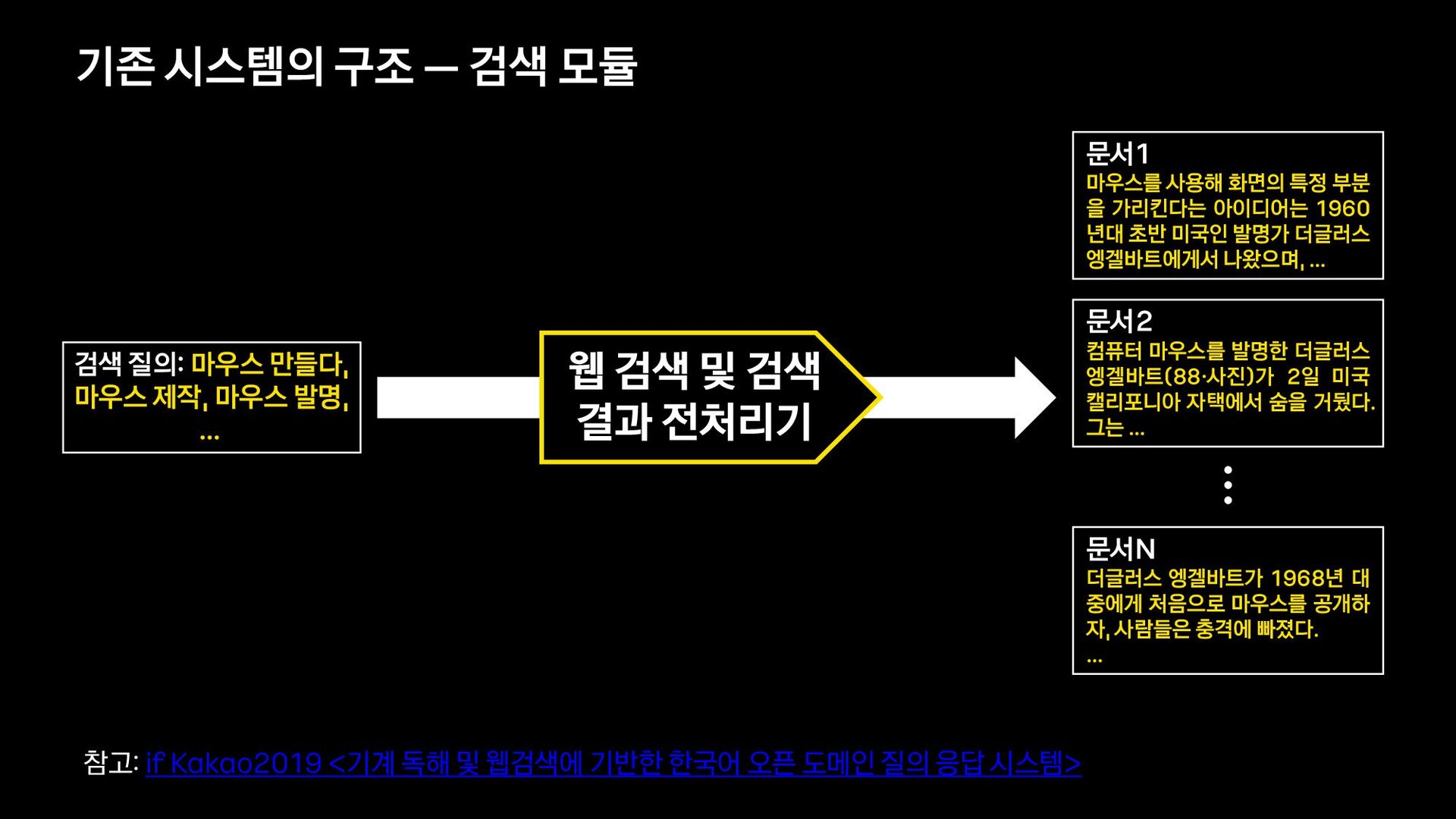{kind=link}
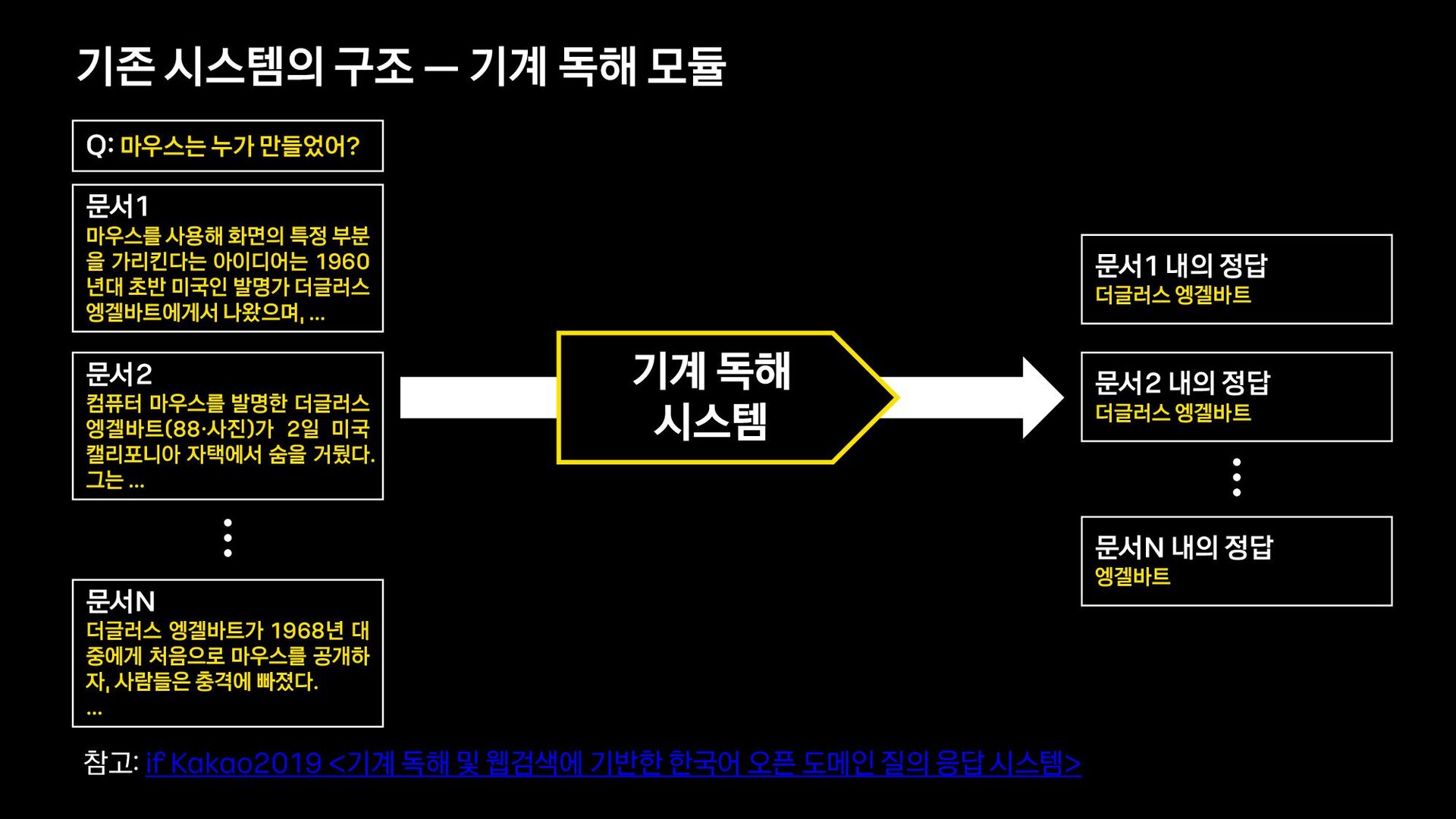{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
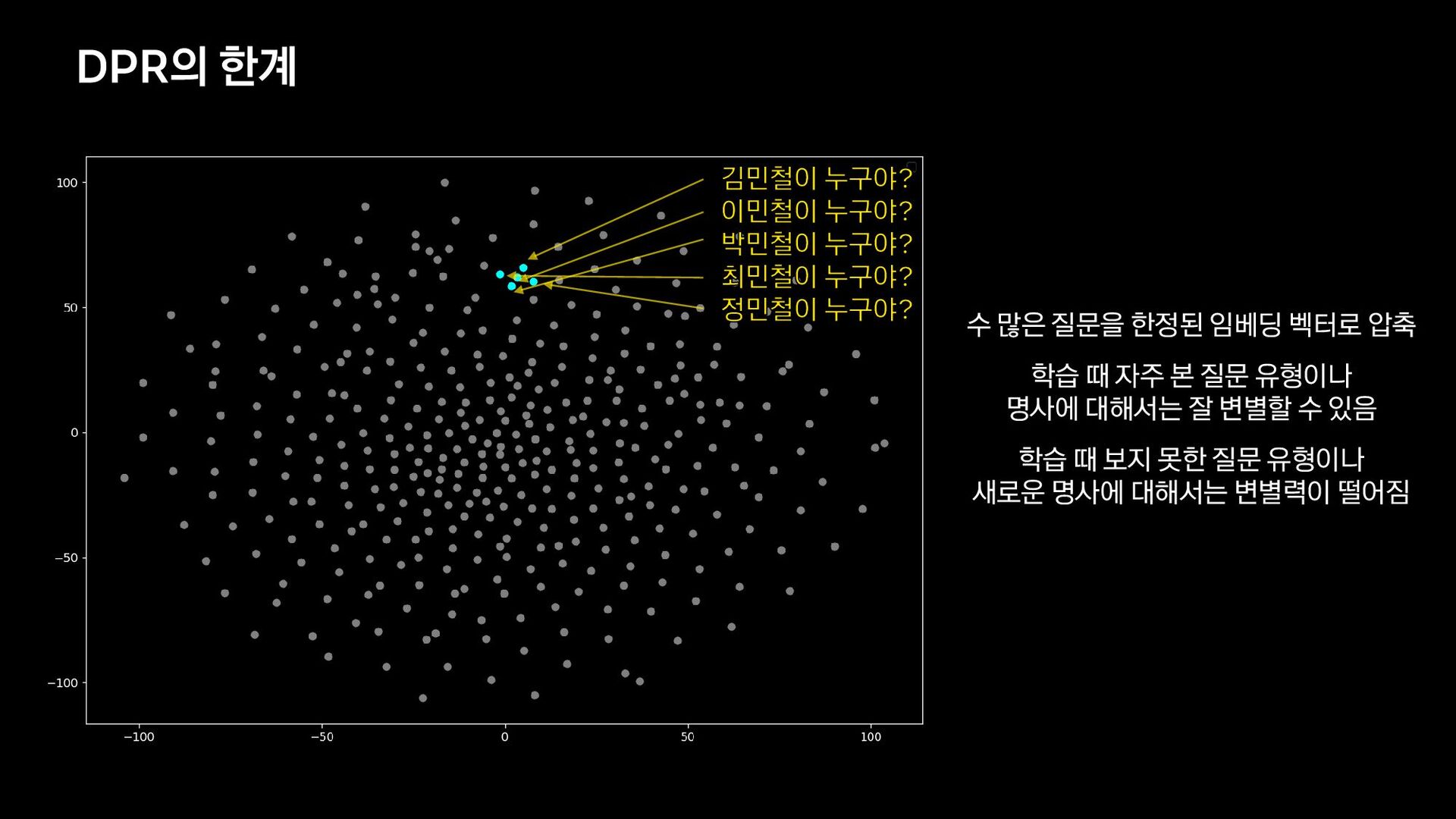{kind=link}
{kind=link}
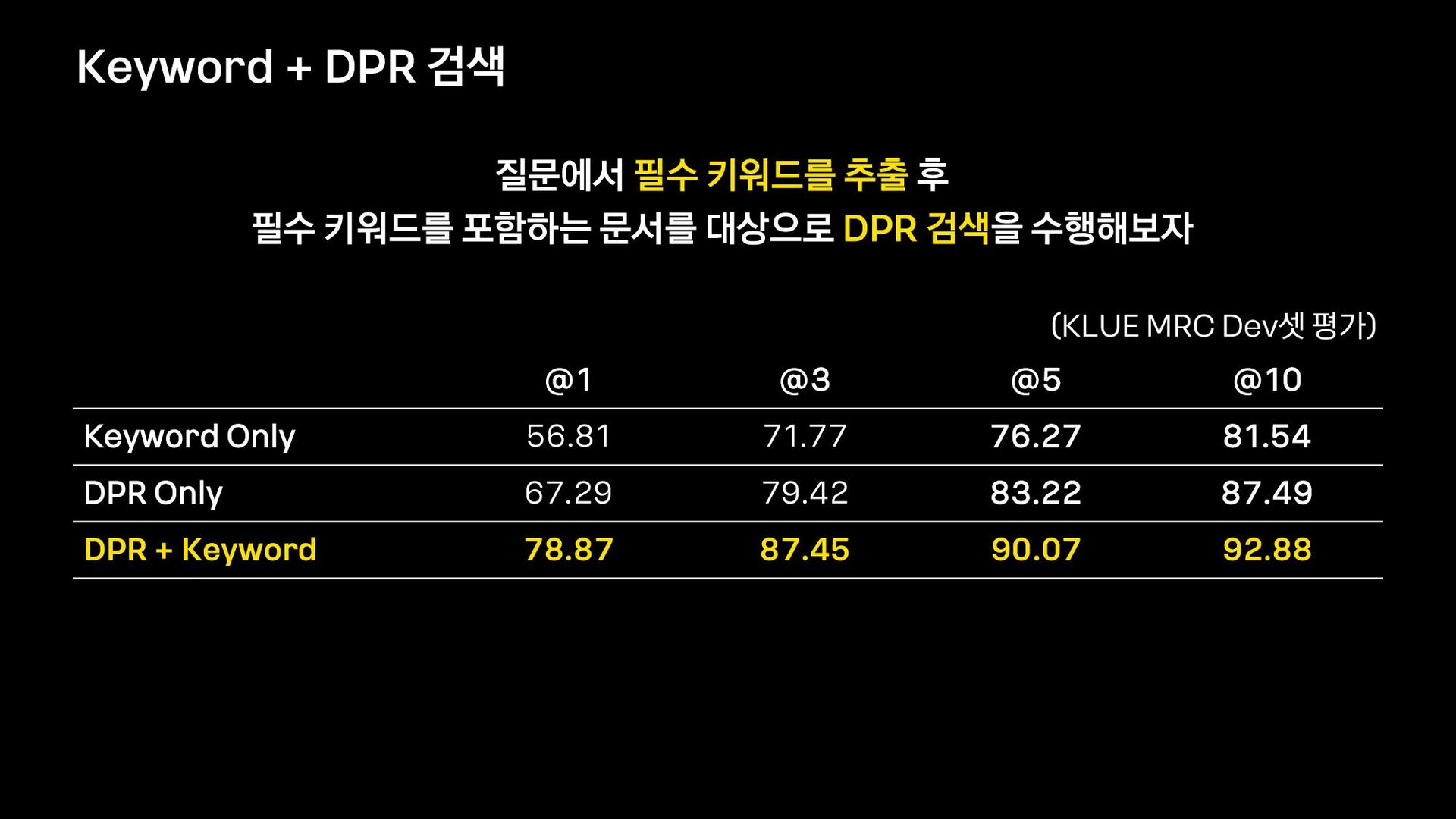{kind=link}
{kind=link}
{kind=link}
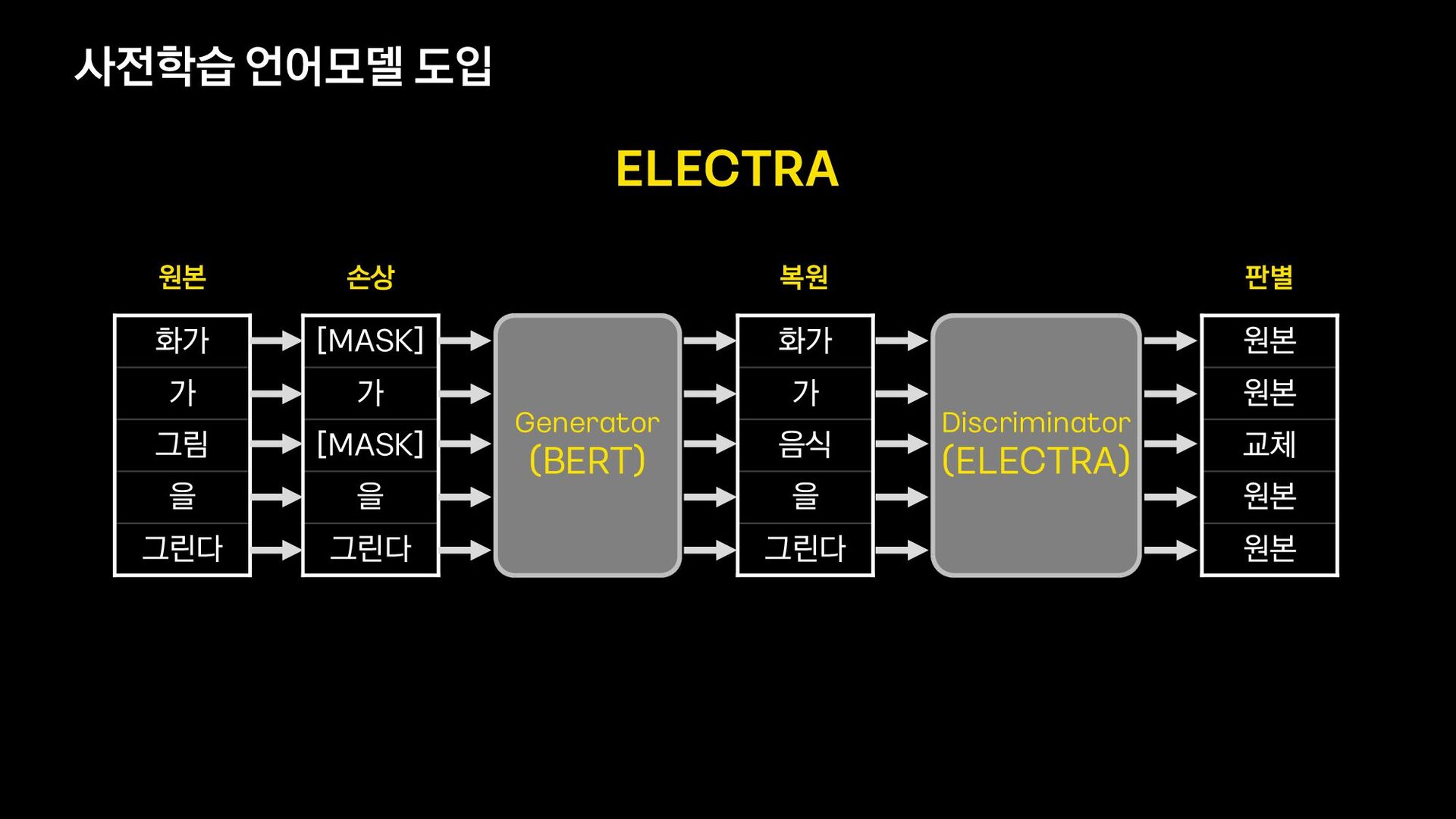
![사전학습 언어모델 도입 화가 가 그림 을 그린다 [MASK] 가](https://files.speakerdeck.com/presentations/064512ddd3034a42badc5e63ba30d25d/slide_26.jpg){kind=link}
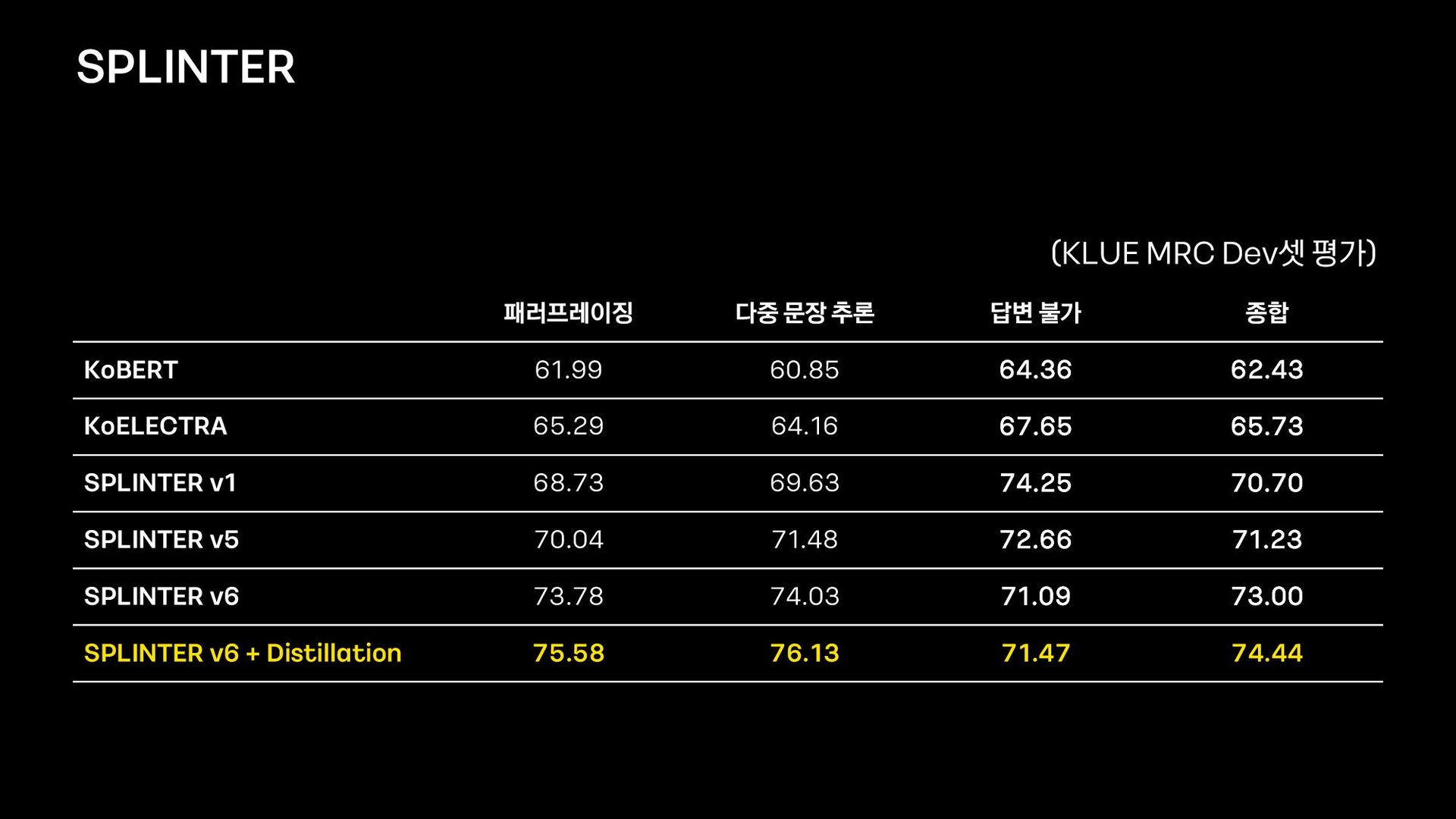
{kind=link}
{kind=link}
![SPLINTER 정치권 [Q1] 찬반대립.. 대선이슈 관측 정부가 원전확대정책을 고수하겠다는 입장을](https://files.speakerdeck.com/presentations/064512ddd3034a42badc5e63ba30d25d/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
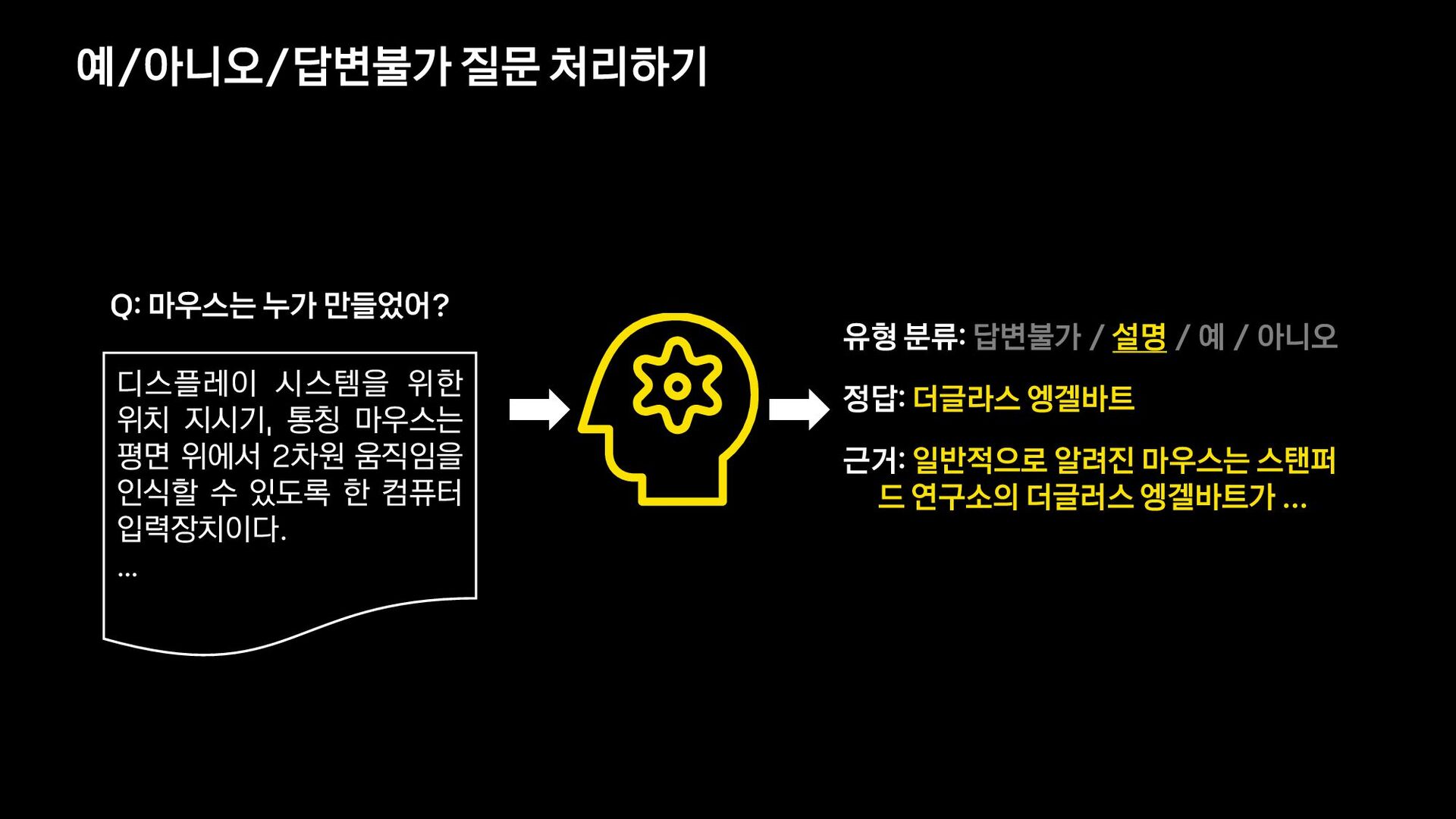{kind=link}
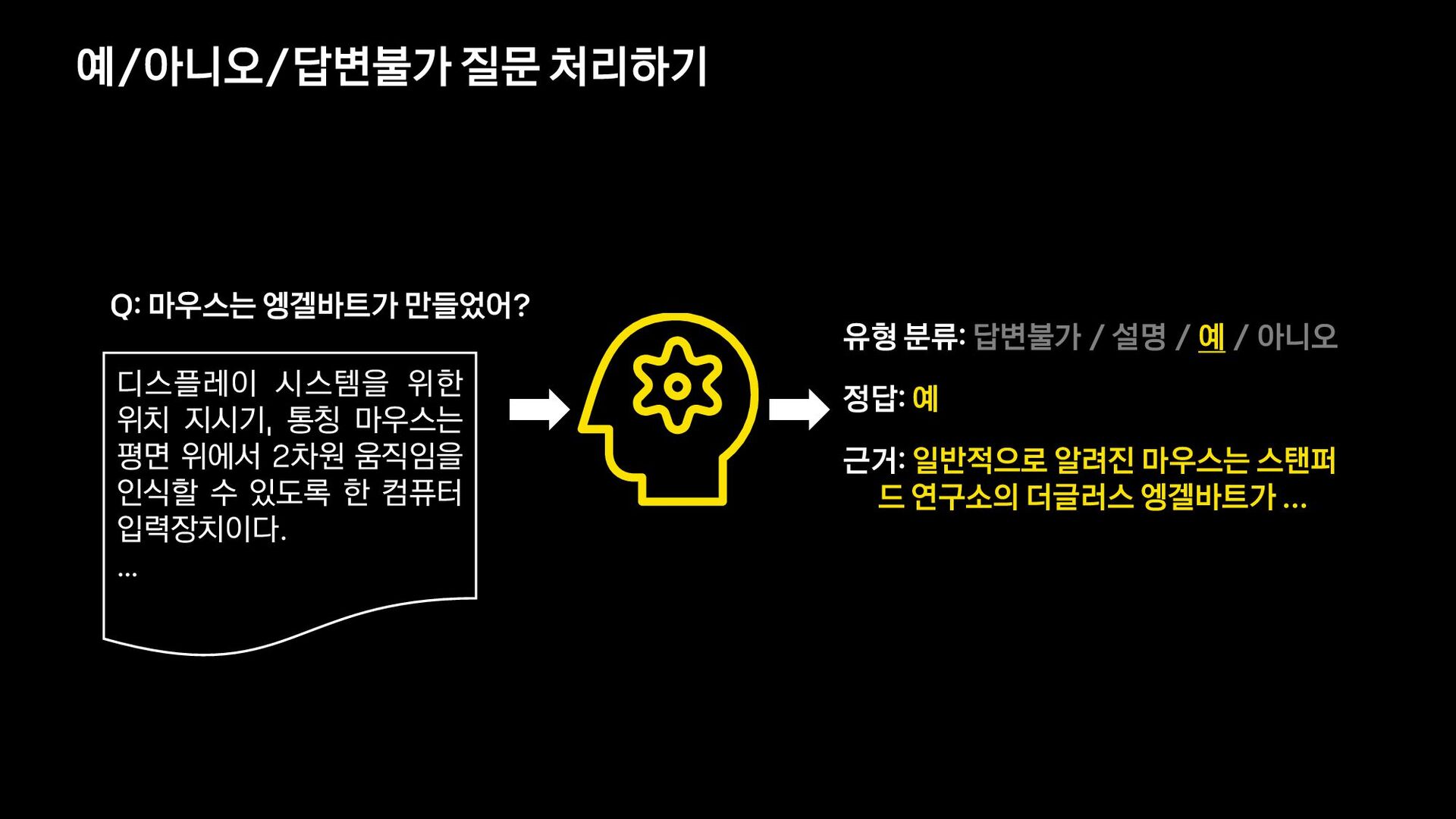{kind=link}
{kind=link}
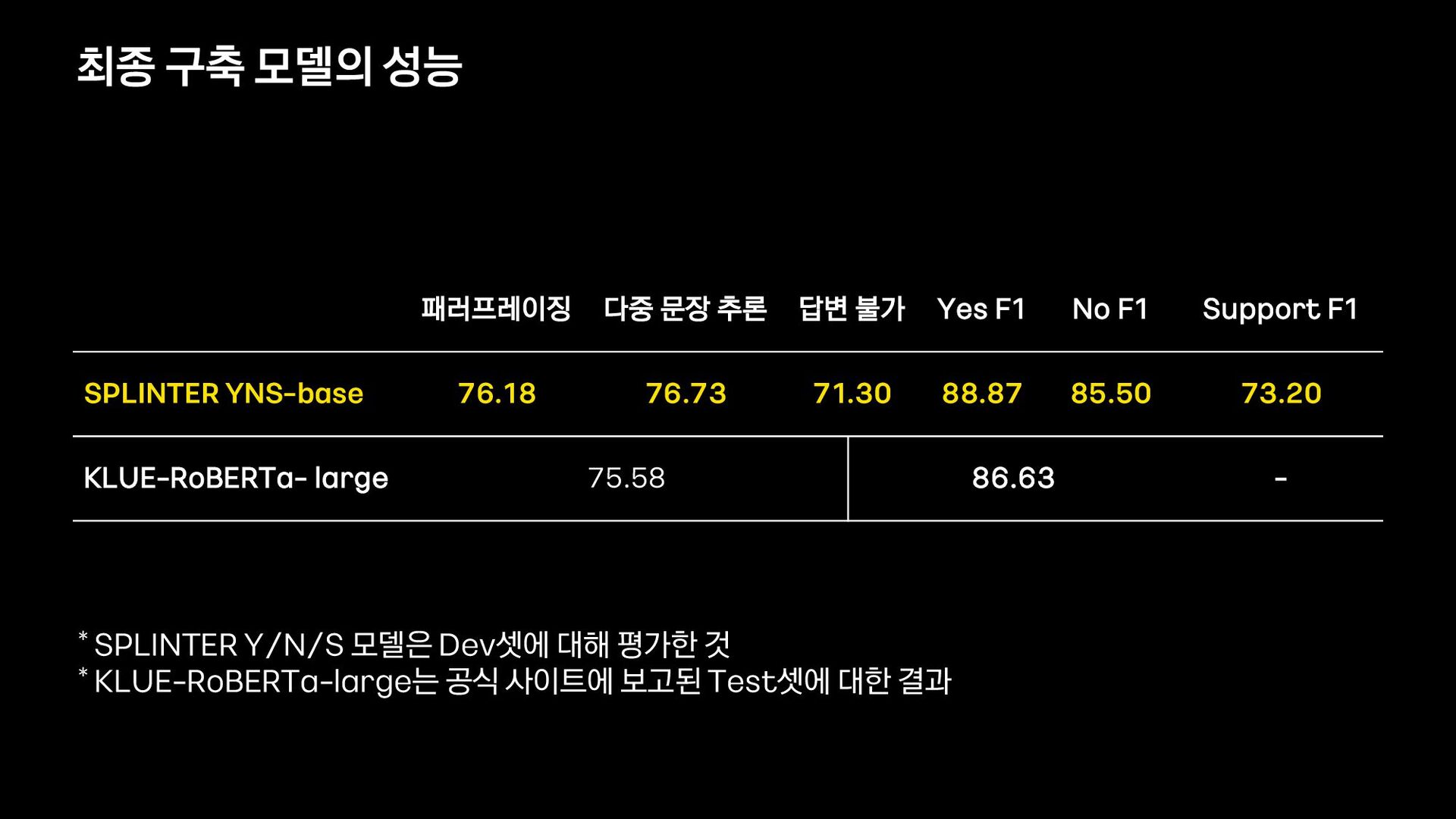{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
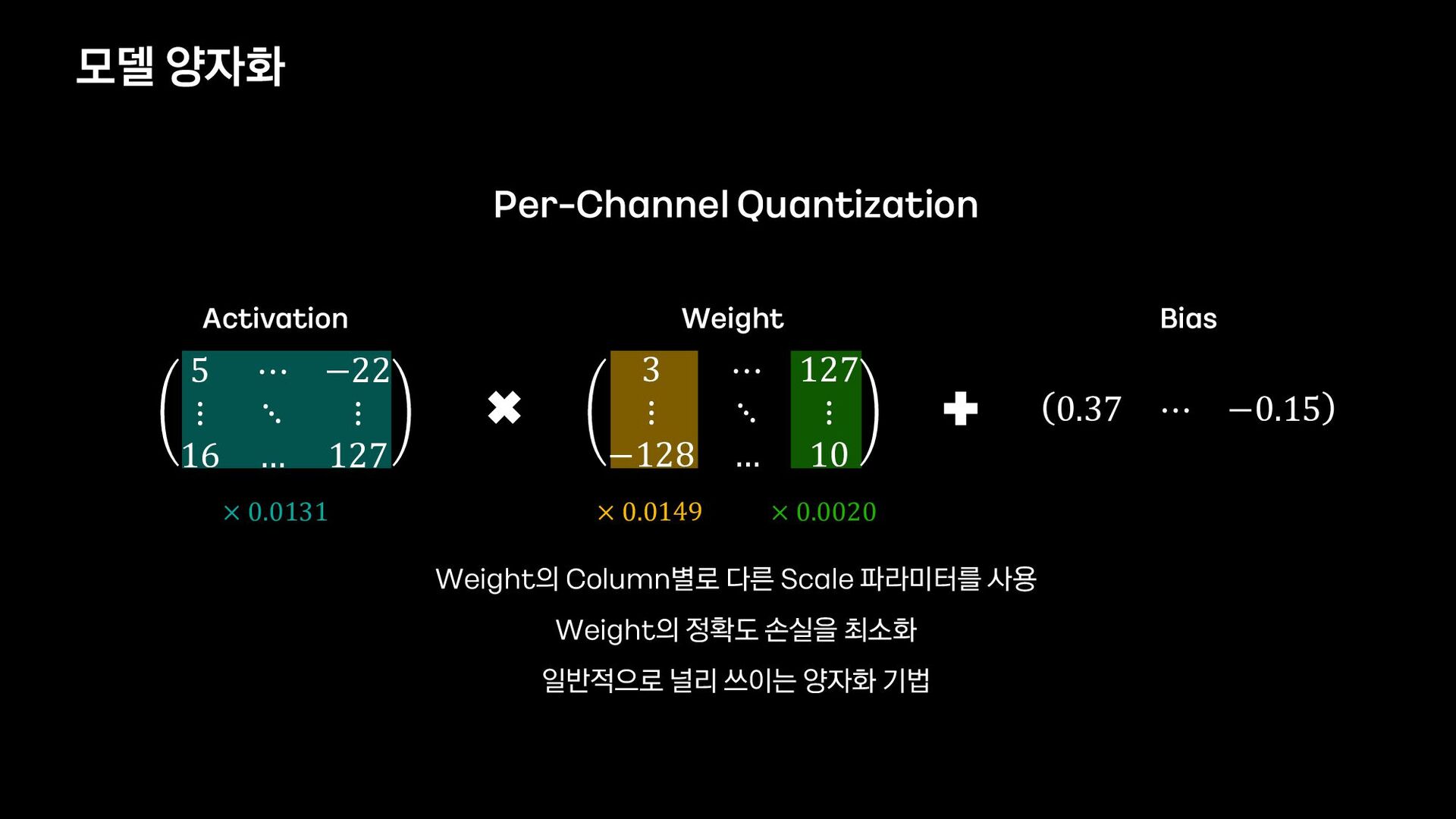{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}