Facilitator with Crowdsource by Google • Consultant at The Innovation Village • Google Dev Library Contributor Profile Wesley Kambale Interests Experience • Research in TinyML, TTS and LLM
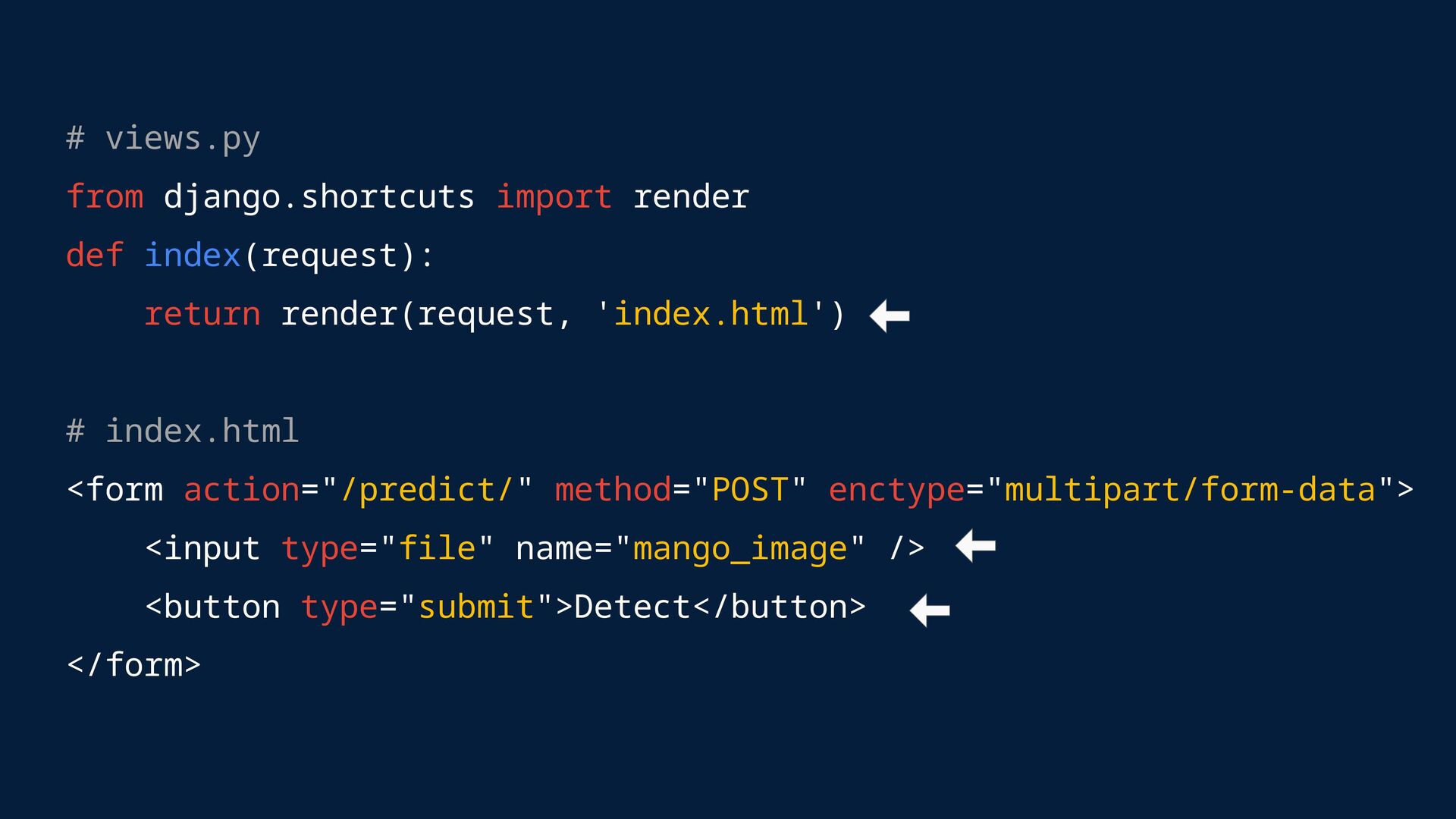
Model serving is how machine learning models are deployed to make predictions in production. • We’ll use Django for the app framework and FastAPI for serving the model via APIs. Goal: Build an app that detects mango damage using a TensorFlow model with Django and FastAPI.
Django: A high-level Python web framework. FastAPI: A fast web framework to serve APIs, especially for machine learning models. TensorFlow: Our deep learning framework for building and serving the model. Uvicorn: ASGI server to run FastAPI apps. Lightweight, fast for async requests.
Lightweight, fast for async requests. Pillow: Image processing (resize, format conversion). Handles JPEG, PNG. Numpy: Used for preprocessing images. Python-Multipart: Handles file uploads in FastAPI.
for asynchronous programming. It’s built on ASGI. This allows for high concurrency, serving of requests. Django is synchronous. Built on WSGI. Isn't as efficient for real-time for high-throughput tasks without extra tooling like Django Channels for async support. FastAPI is better suited for serving machine learning models, especially with frameworks like TensorFlow or PyTorch, due to its ability to handle large data and fast response times.
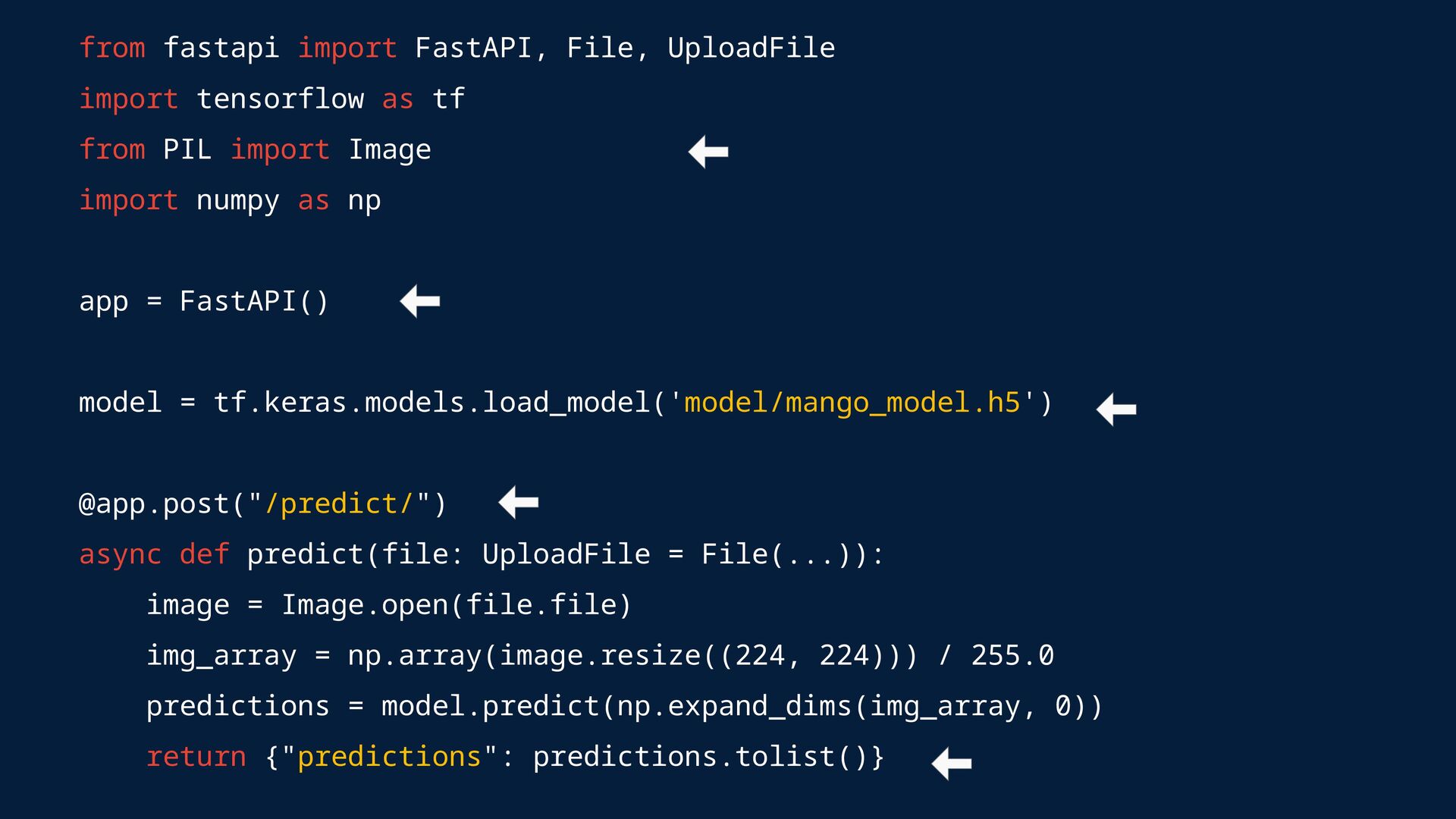
up FastAPI to load the model and serve the predictions via an endpoint. FastAPI handles asynchronous requests well, making it ideal for serving models.
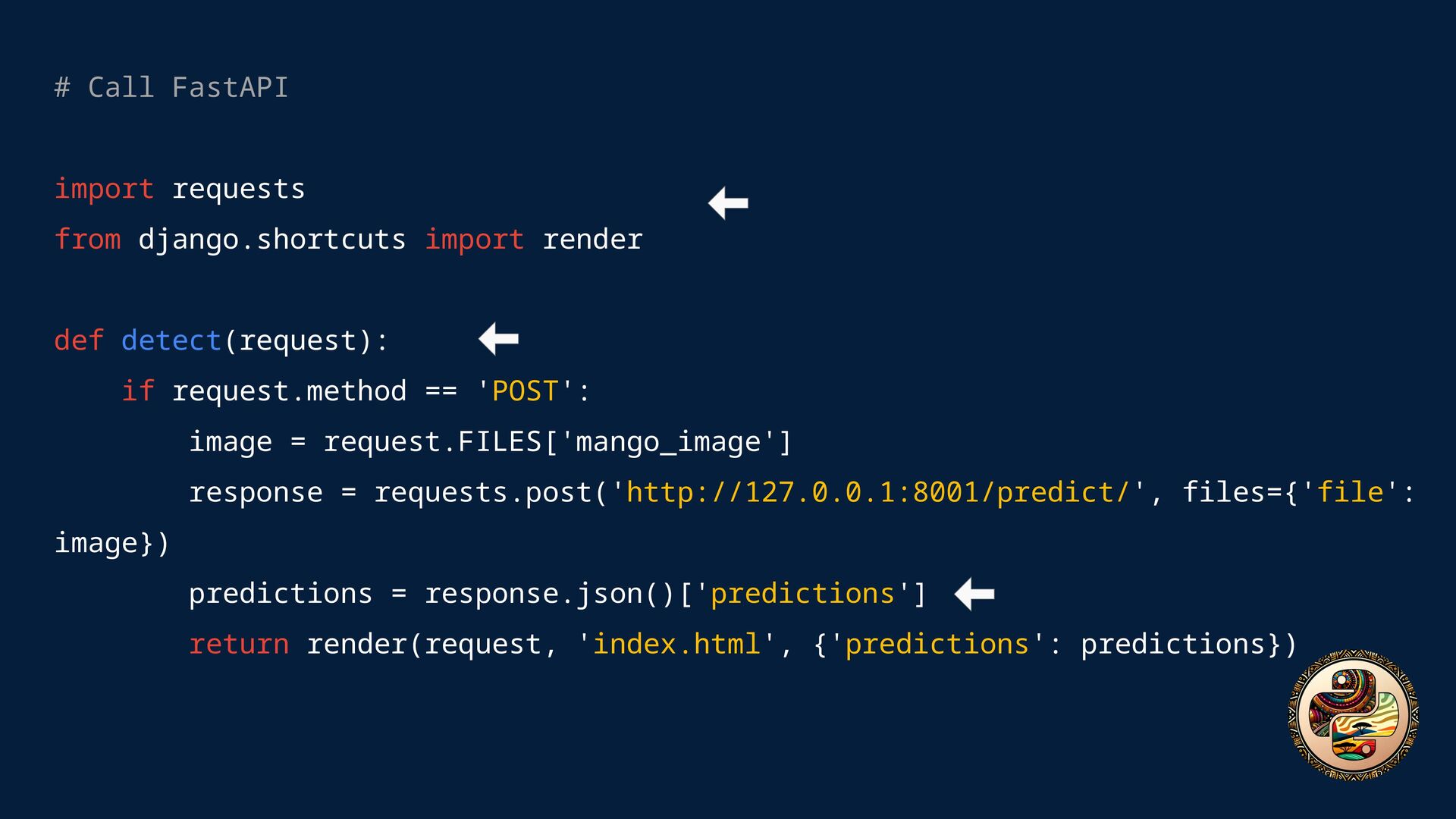
Django? Django handles the web interface, while FastAPI serves the model. Use Uvicorn to run the FastAPI server and route requests from Django. # Bash uvicorn fastapi_app.api:app --reload --port 8001
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}