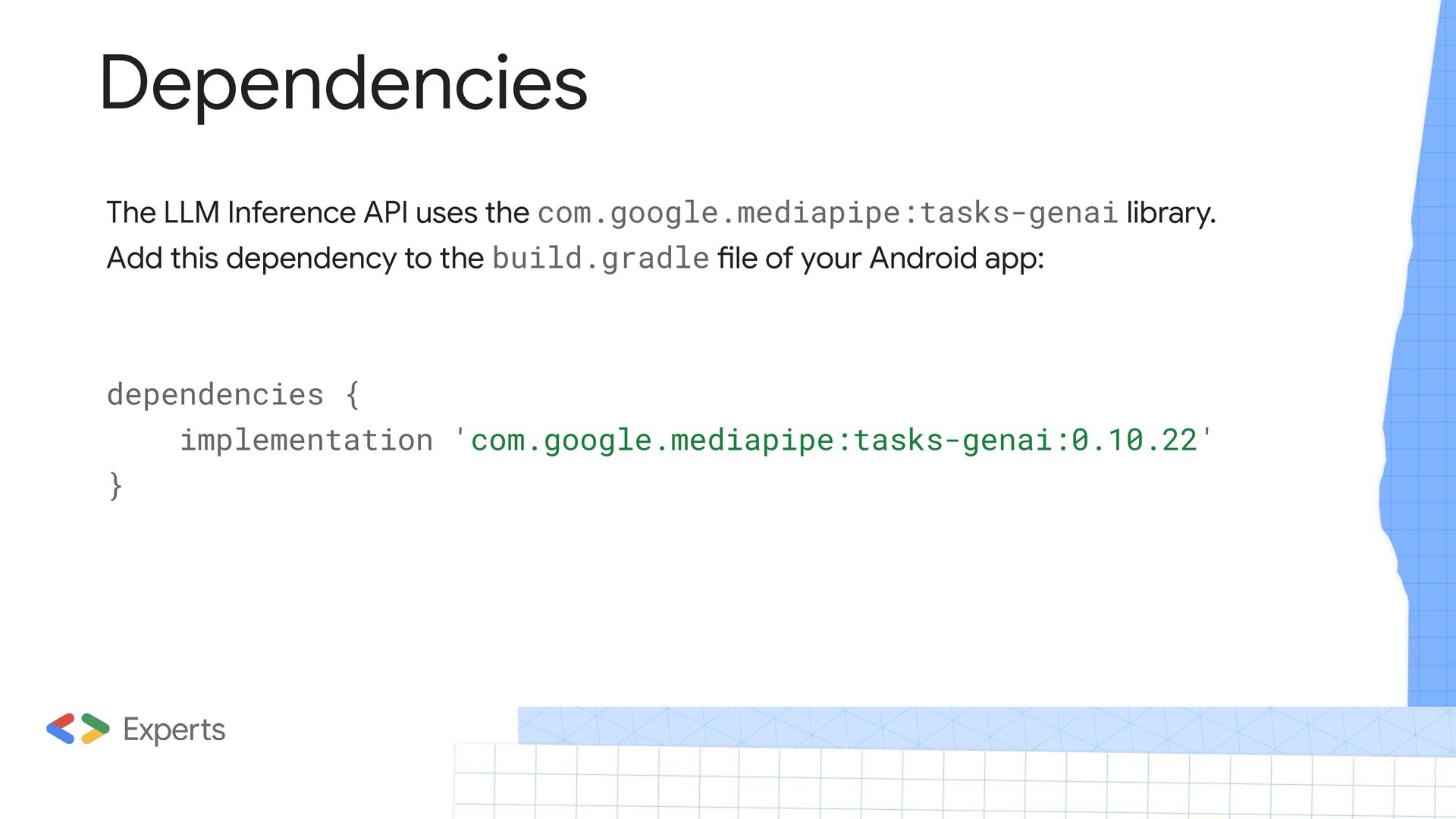
run large language models (LLMs) completely on-device for Android applications, which you can use to perform a wide range of tasks, such as generating text, retrieving information in natural language form, and summarizing documents. The API provides built-in support for multiple text-to-text large language models, so you can apply the latest on-device generative AI models to your Android apps.
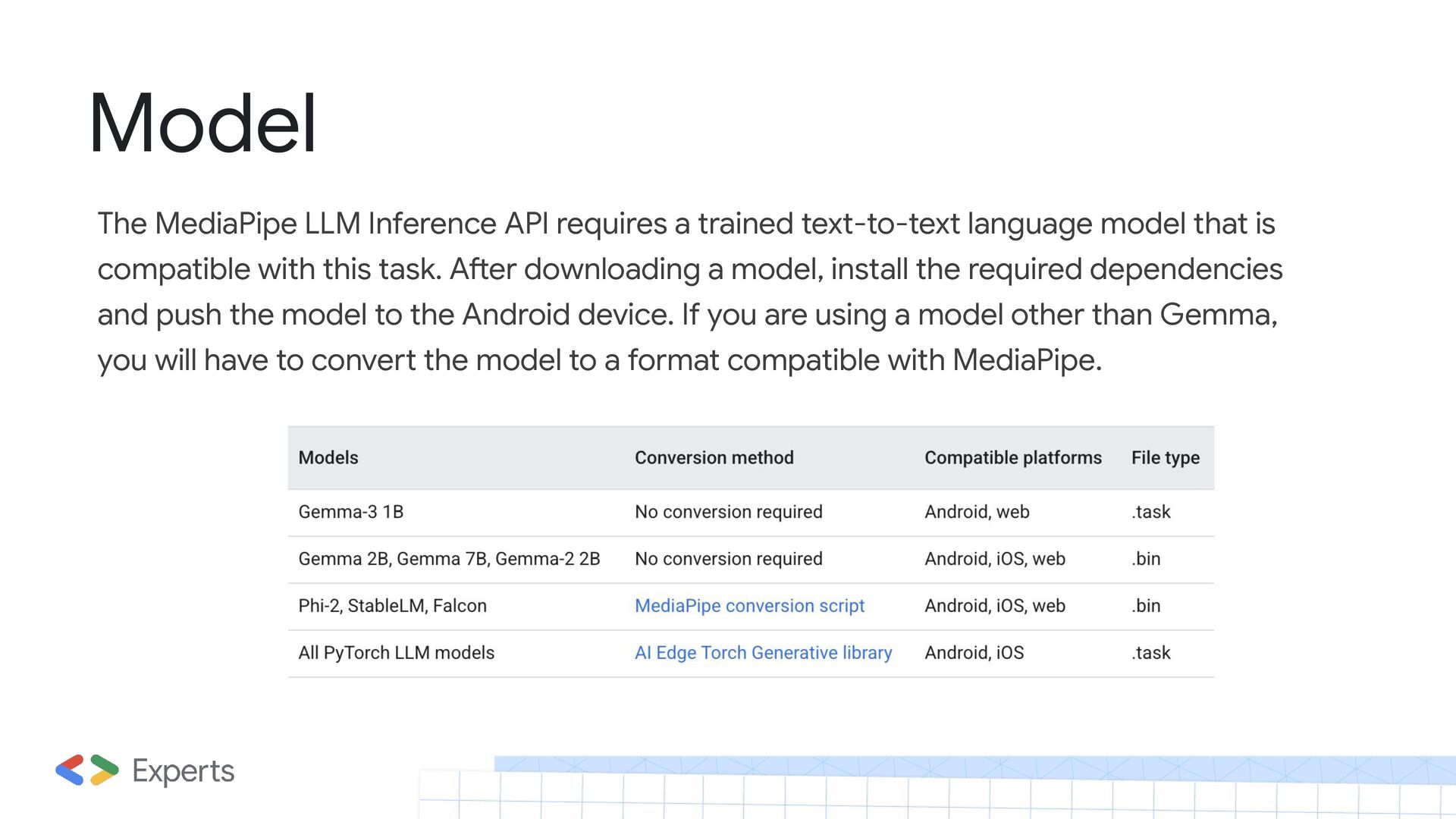
of Gemma: Gemma-3 1B, Gemma-2 2B, Gemma 2B, and Gemma 7B. Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. It also supports the following external models: Phi-2, Falcon-RW-1B and StableLM-3B, and recently, DeepSeek R-1. In addition to the supported models, users can use Google's AI Edge Torch to export PyTorch models into multi-signature LiteRT (tflite) models, which are bundled with tokenizer parameters to create Task Bundles that are compatible with the LLM Inference API.
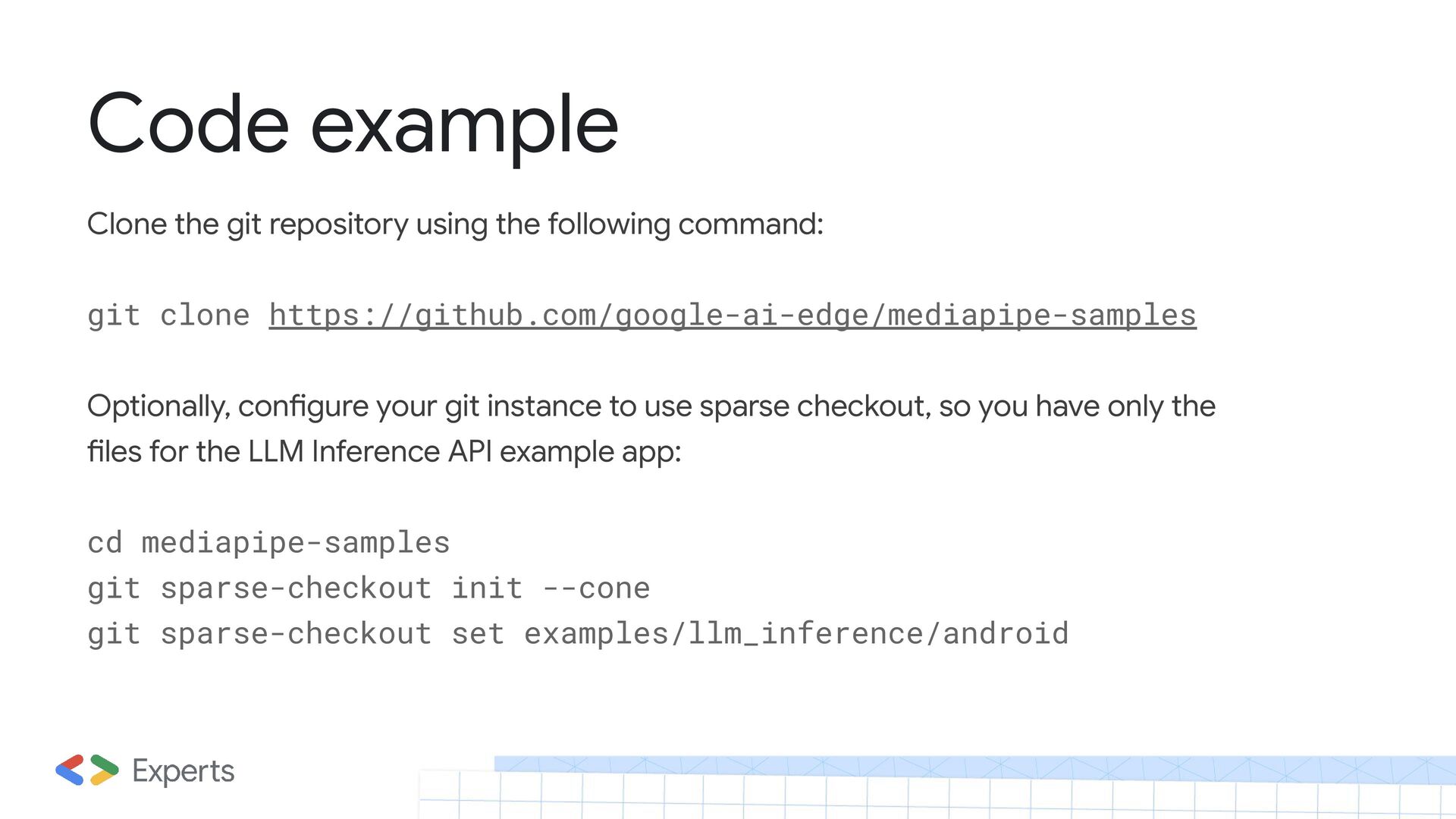
git clone https://github.com/google-ai-edge/mediapipe-samples Optionally, configure your git instance to use sparse checkout, so you have only the files for the LLM Inference API example app: cd mediapipe-samples git sparse-checkout init --cone git sparse-checkout set examples/llm_inference/android
language model that is compatible with this task. After downloading a model, install the required dependencies and push the model to the Android device. If you are using a model other than Gemma, you will have to convert the model to a format compatible with MediaPipe.
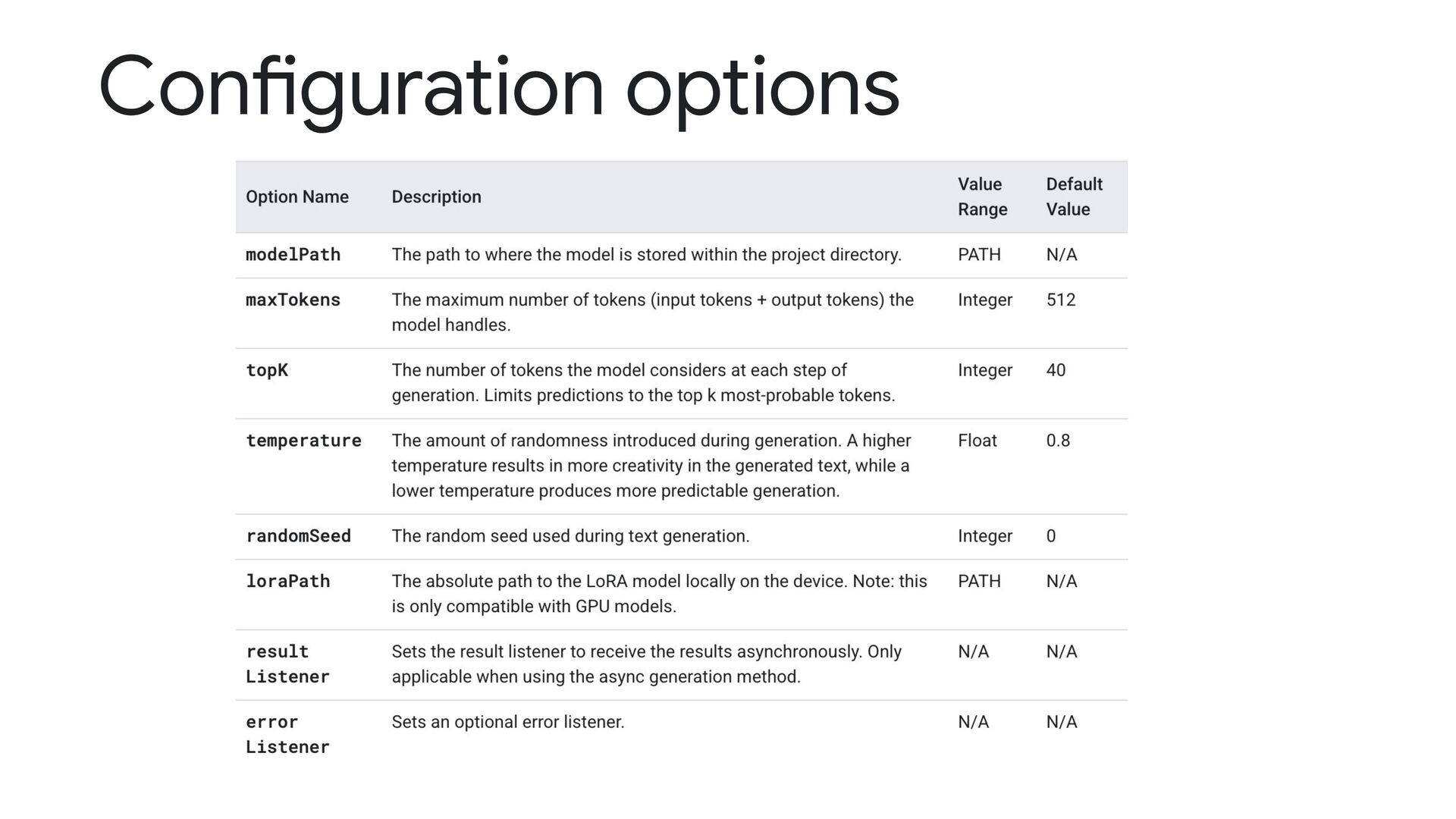
createFromOptions() function to set up the task. The createFromOptions() function accepts values for the configuration options. val options = LlmInferenceOptions.builder() .setModelPath("/data/local/.../") .setMaxTokens(1000) .setTopK(40) .setTemperature(0.8) .setRandomSeed(101) .build() llmInference = LlmInference.createFromOptions(context, options)
the input text provided in the previous section (inputPrompt). This produces a single generated response. val result = llmInference.generateResponse(inputPrompt) logger.atInfo().log("result: $result") Run the task
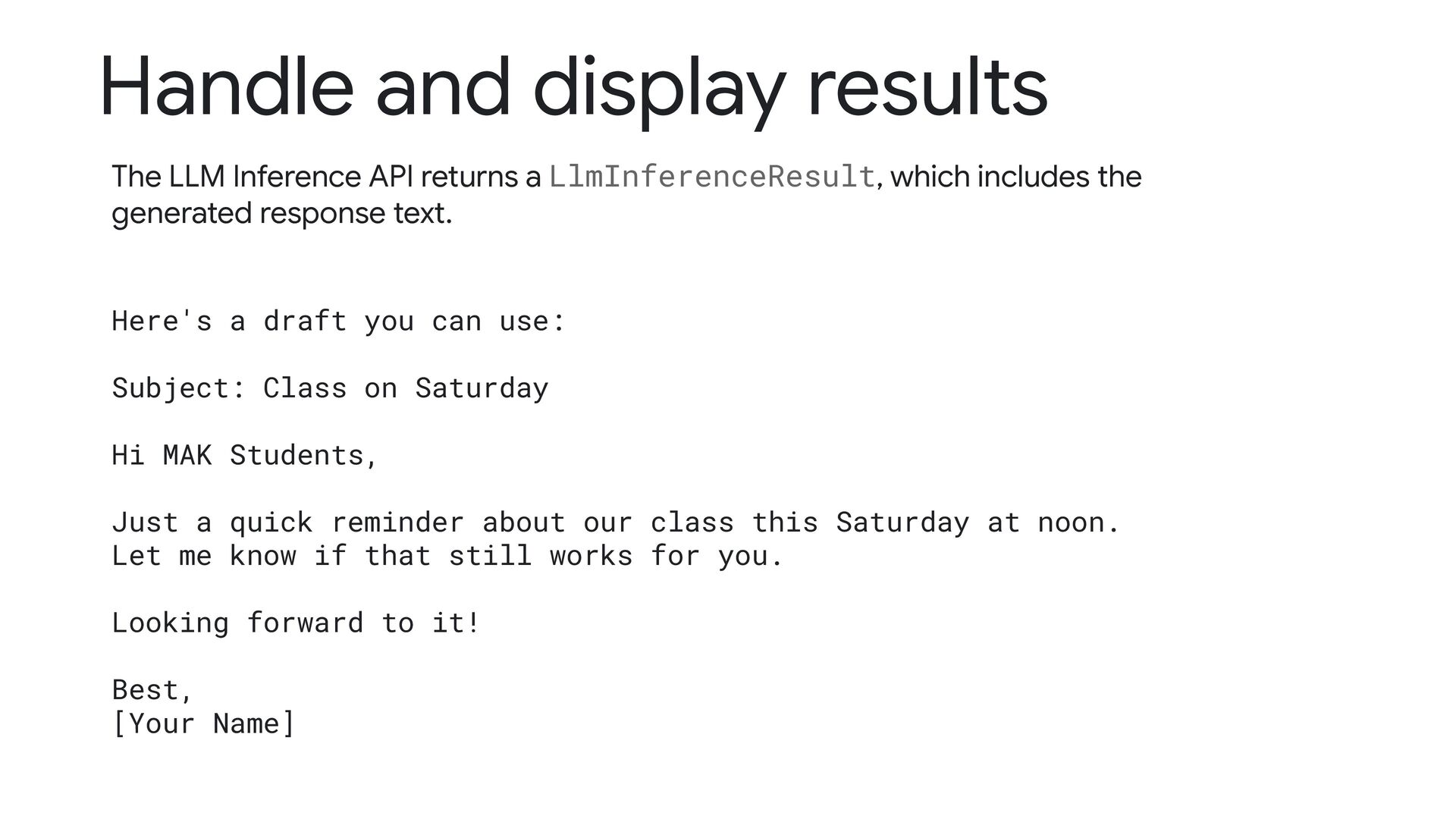
LlmInferenceResult, which includes the generated response text. Here's a draft you can use: Subject: Class on Saturday Hi MAK Students, Just a quick reminder about our class this Saturday at noon. Let me know if that still works for you. Looking forward to it! Best, [Your Name]
to support Low-Rank Adaptation (LoRA) for large language models. Utilizing fine-tuned LoRA models, developers can customize the behavior of LLMs through a cost-effective training process. LoRA support of the LLM Inference API works for all Gemma variants and Phi-2 models for the GPU backend, with LoRA weights applicable to attention layers only. This initial implementation serves as an experimental API for future developments with plans to support more models and various types of layers in the coming updates.
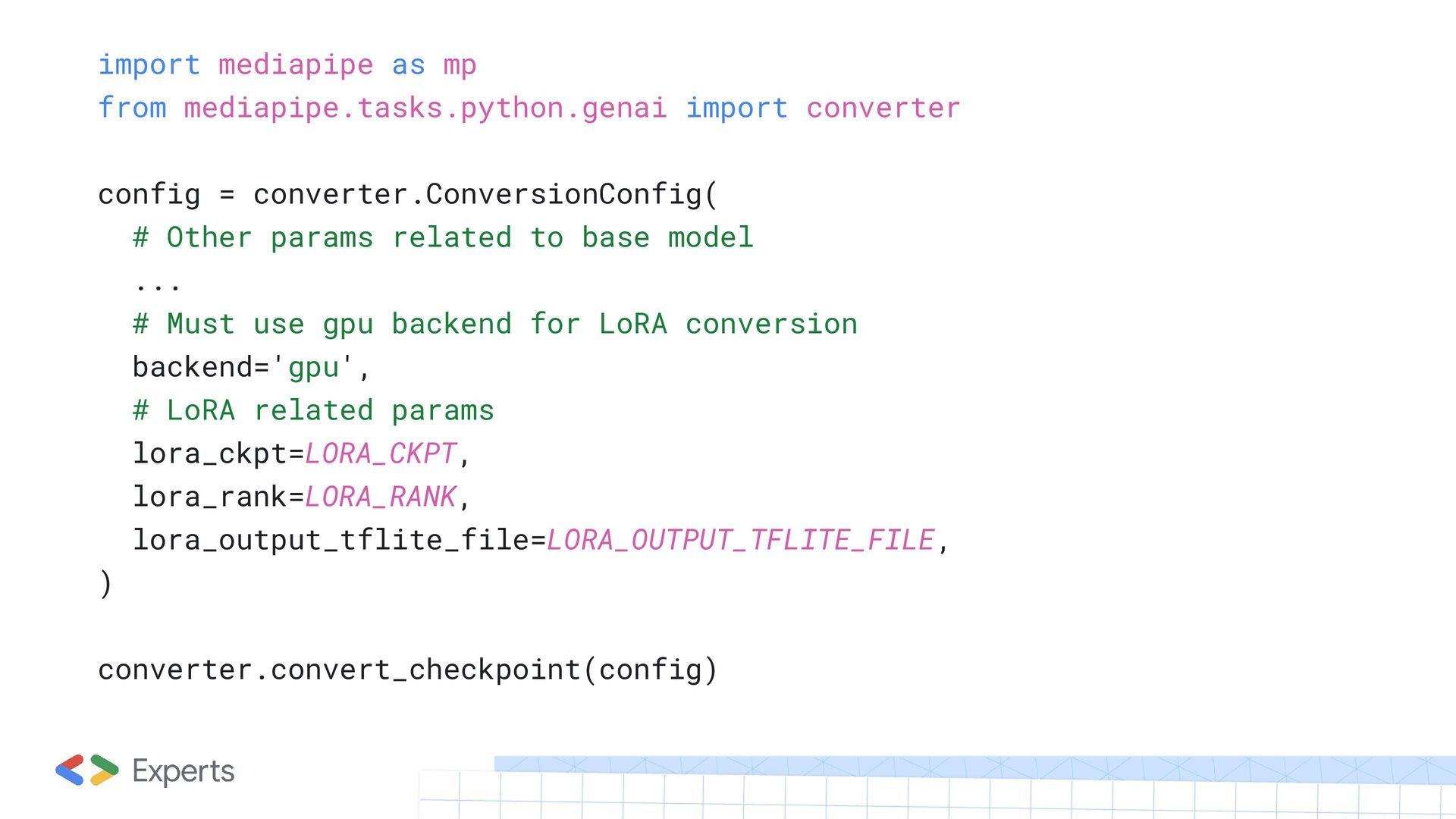
saving the model, you obtain an adapter_model.safetensors file containing the fine-tuned LoRA model weights. The safetensors file is the LoRA checkpoint used in the model conversion. As the next step, you need convert the model weights into a TensorFlow Lite Flatbuffer using the MediaPipe Python Package. The ConversionConfig should specify the base model options as well as additional LoRA options. The API only supports LoRA inference with GPU, the backend must be set to 'gpu'.
converter.ConversionConfig( # Other params related to base model ... # Must use gpu backend for LoRA conversion backend='gpu', # LoRA related params lora_ckpt=LORA_CKPT, lora_rank=LORA_RANK, lora_output_tflite_file=LORA_OUTPUT_TFLITE_FILE, ) converter.convert_checkpoint(config)
to support LoRA model inference. Android supports static LoRA during initialization. To load a LoRA model, users specify the LoRA model path as well as the base LLM. val options = LlmInferenceOptions.builder() ... .setRandomSeed(101) .setLoraPath('<path to LoRA model>') .build() llmInference = LlmInference.createFromOptions(context, options) LoRA model inference
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}