Community Builder for 3 years • Explore ML Facilitator with Crowdsource by Google for 2 years • Google Dev Library Author Profile Interests Experience • Research in TinyML, TTS & LLM
amounts of labeled data, these networks can identify patterns, classify objects, and make predictions. Deep learning has transformed countless industries such as computer vision, natural language processing, and speech recognition, surpassing the performance of traditional machine learning algorithms in many formerly difficult tasks.
is an open-source deep learning framework developed by the Google Brain team. It offers a vast array of tools, libraries, and resources to create and implement machine learning and deep learning models.
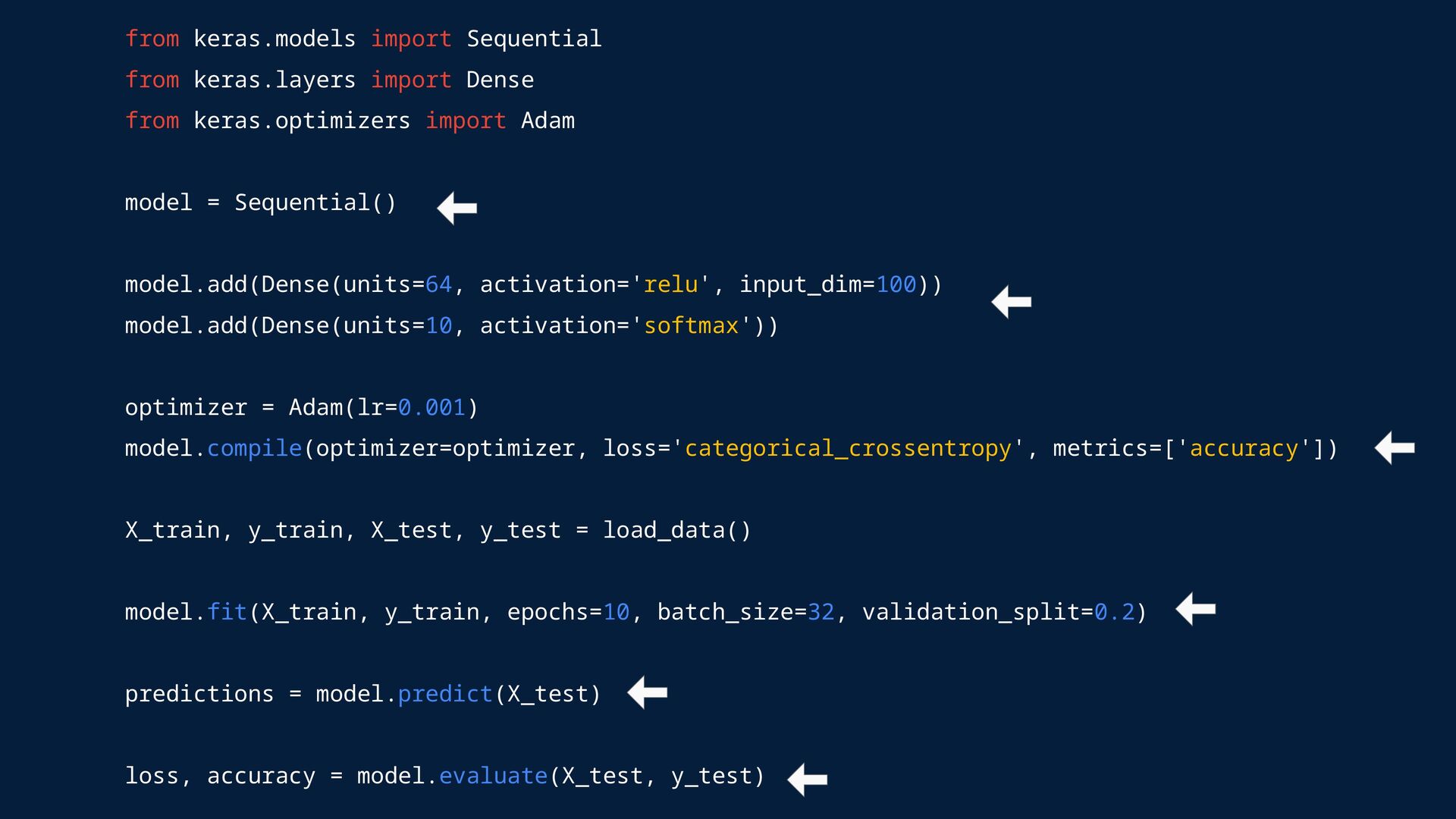
Learning? Keras is the high-level API for TensorFlow (Keras 3 supports JAX and PyTorch). It provides an approachable, highly-productive interface for solving machine learning (ML) problems, with a focus on modern deep learning. Keras covers every step of the machine learning workflow, from data processing to hyperparameter tuning to deployment. Every TensorFlow user should use the Keras APIs by default. Whether you're an engineer, a researcher, or an ML practitioner, you should start with Keras.
evaluation methods: tf.keras.Model.fit: Trains the model for a fixed number of epochs. tf.keras.Model.predict: Generates output predictions for the input samples. tf.keras.Model.evaluate: Returns the loss and metrics values for the model; configured via the tf.keras.Model.compile method.
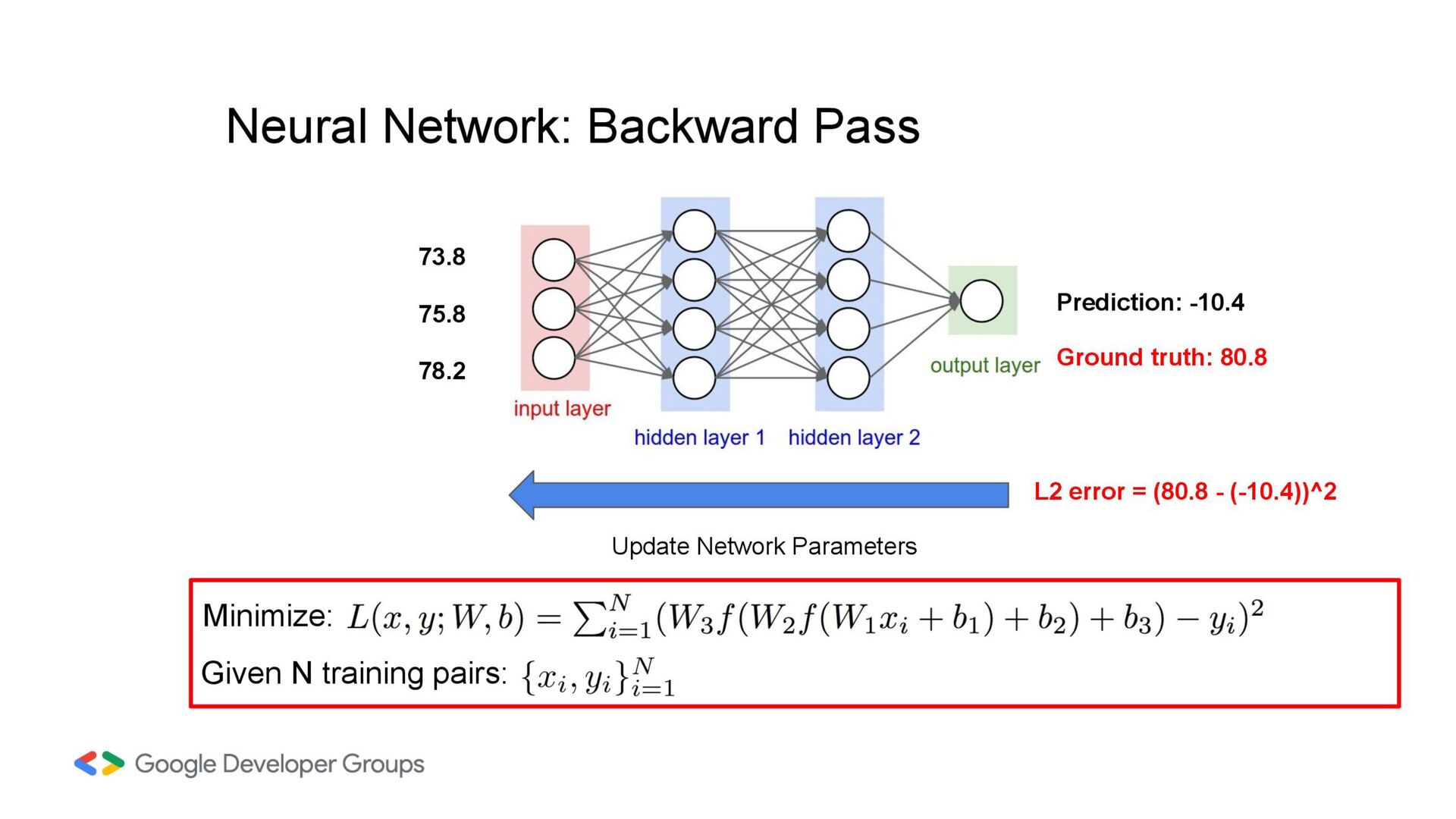
the human brain's interconnected neurons, utilized in machine learning to process and learn from data, making them capable of complex pattern recognition and decision-making. Neural network layers can have a state (i.e have weights) or be stateless.
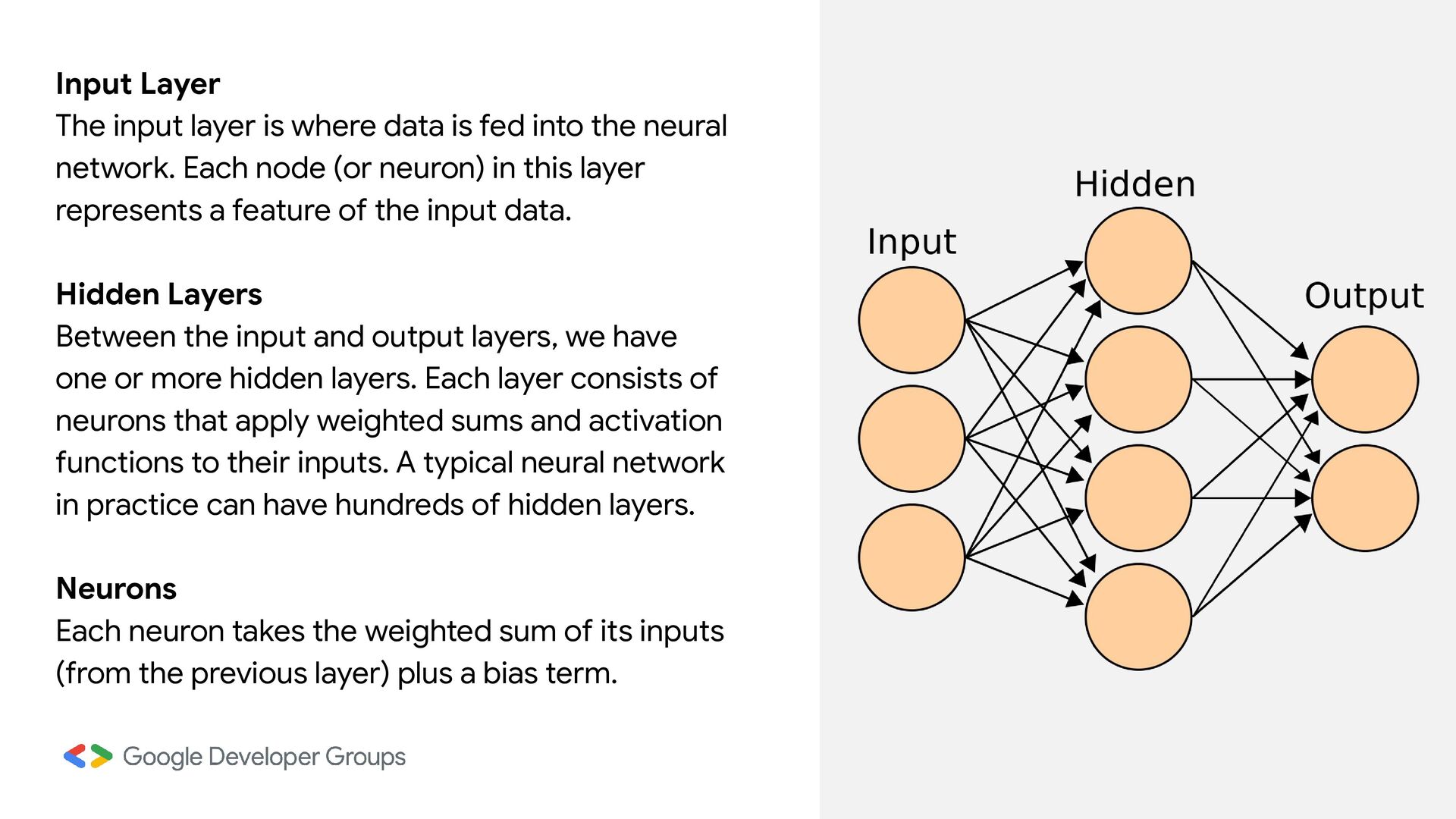
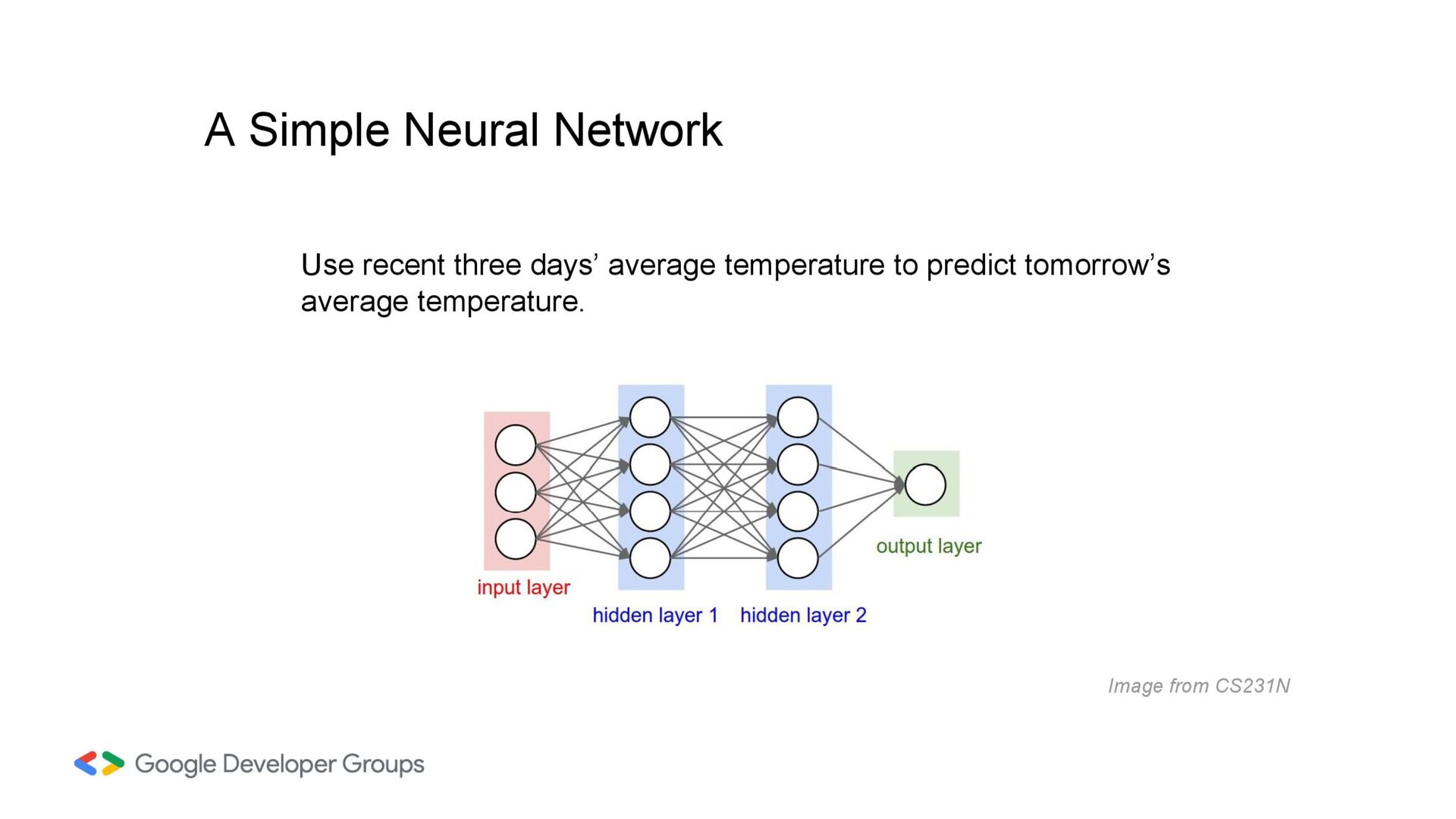
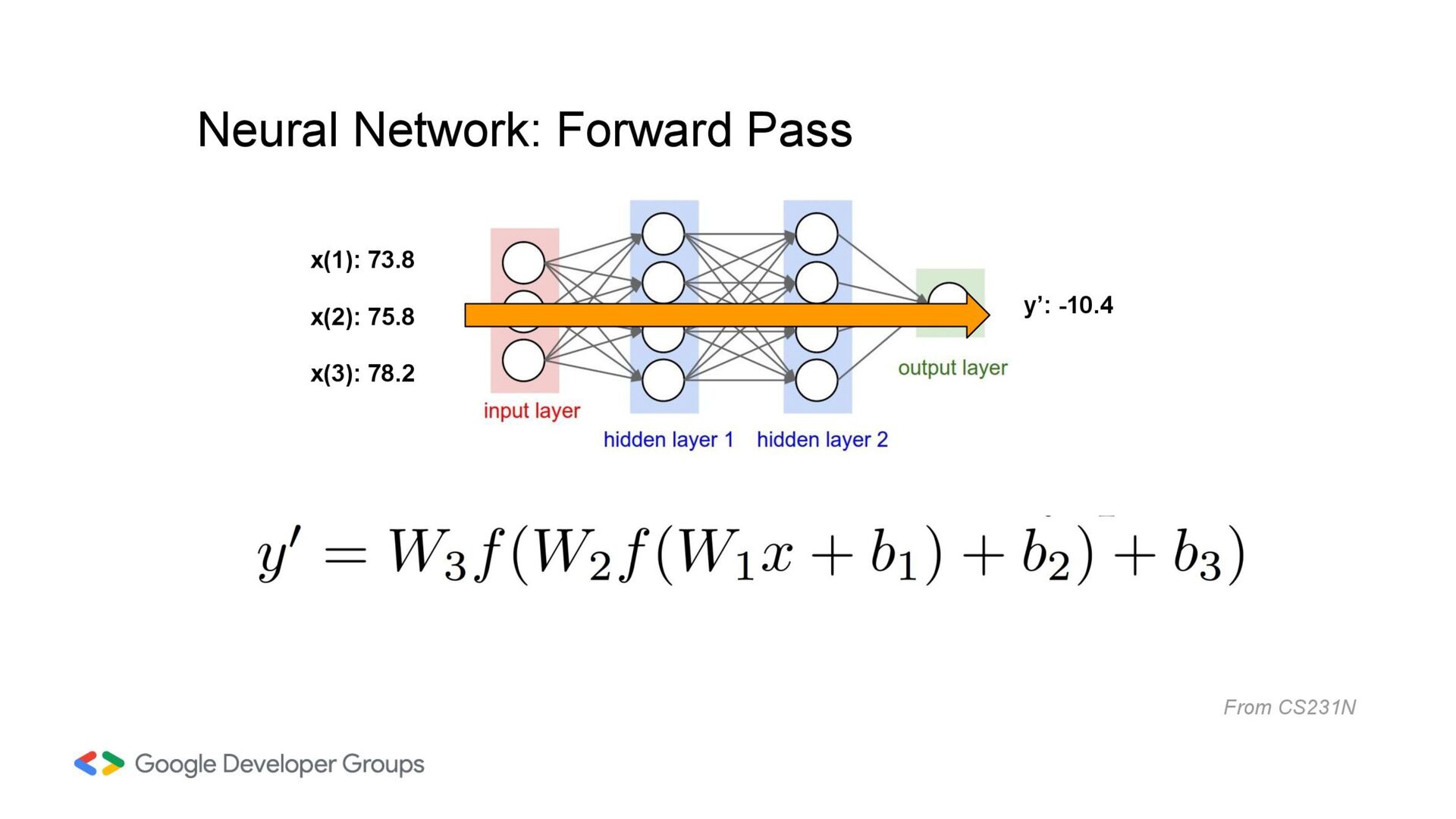
into the neural network. Each node (or neuron) in this layer represents a feature of the input data. Hidden Layers Between the input and output layers, we have one or more hidden layers. Each layer consists of neurons that apply weighted sums and activation functions to their inputs. A typical neural network in practice can have hundreds of hidden layers. Neurons Each neuron takes the weighted sum of its inputs (from the previous layer) plus a bias term.
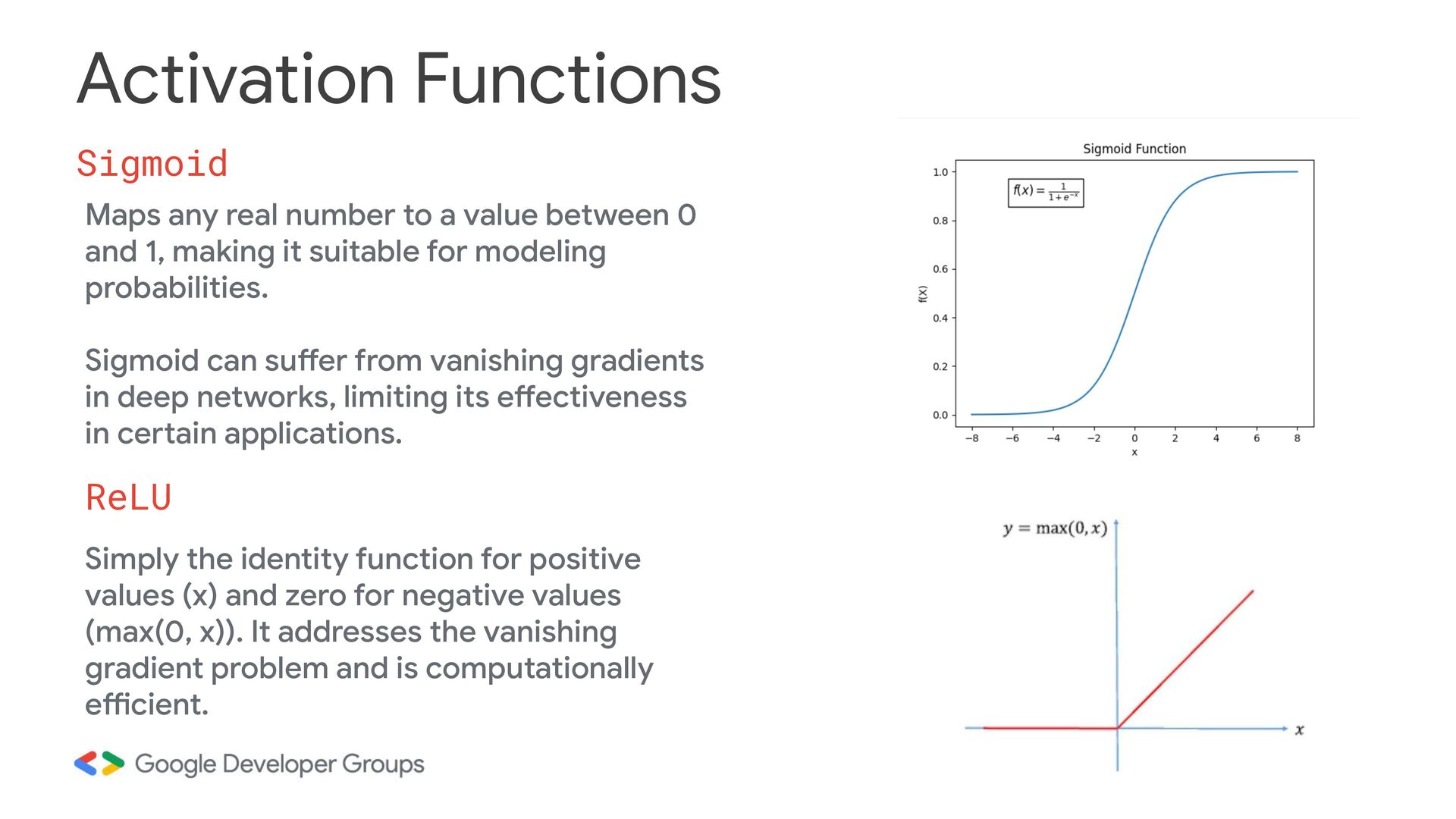
between 0 and 1, making it suitable for modeling probabilities. Sigmoid can suffer from vanishing gradients in deep networks, limiting its effectiveness in certain applications. ReLU Simply the identity function for positive values (x) and zero for negative values (max(0, x)). It addresses the vanishing gradient problem and is computationally efficient.
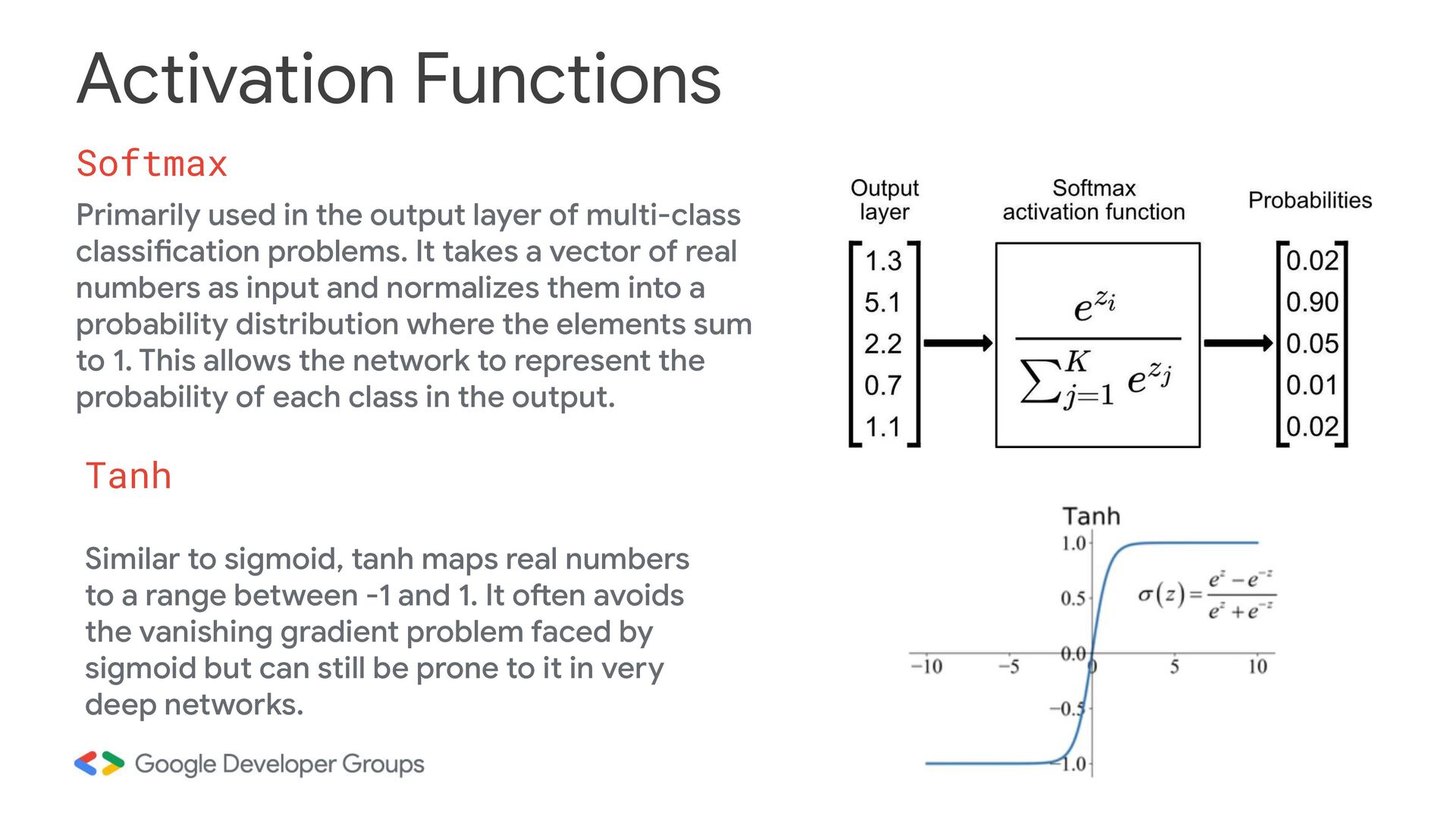
multi-class classification problems. It takes a vector of real numbers as input and normalizes them into a probability distribution where the elements sum to 1. This allows the network to represent the probability of each class in the output. Tanh Similar to sigmoid, tanh maps real numbers to a range between -1 and 1. It often avoids the vanishing gradient problem faced by sigmoid but can still be prone to it in very deep networks.
difference between the predicted and actual values. Mean Absolute Error (MAE): The average of the absolute differences between the predicted and actual values. It is less sensitive to outliers compared to MSE. Classification Binary Cross-Entropy Loss (Log Loss): It measures the difference between the predicted probability of the positive class and the actual binary label (0 or 1). Categorical Cross-Entropy Loss: This is an extension of binary cross-entropy for multi-class classification problems (more than two classes). It calculates the average cross-entropy loss across all classes
optimizer that iteratively updates the model parameters based on the gradient of the loss function with respect to each parameter. It takes a small learning rate step in the direction of the negative gradient, aiming to minimize the loss. RMSprop (Root Mean Square Prop) Adaptively adjusts the learning rate for each parameter based on its historical squared gradients. This helps to address the issue of diminishing learning rates in SGD for parameters with frequently changing gradients. Adam (Adaptive Moment Estimation) Combines the benefits of momentum and RMSprop, incorporating both exponentially decaying averages of past gradients and squared gradients. It is widely used due to its efficiency and effectiveness in various deep learning tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}