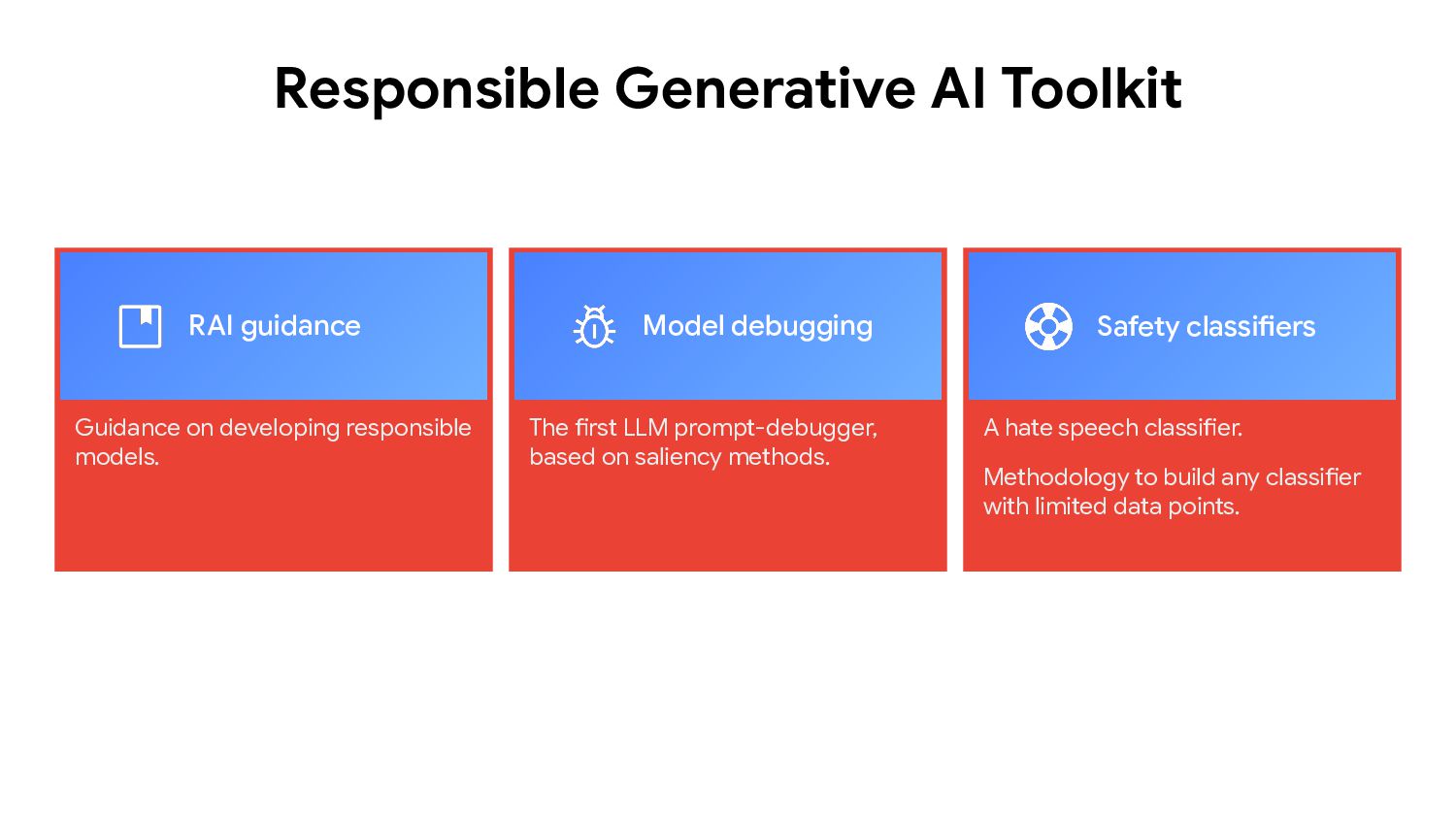
During this talk, we will explore the ethical and technical aspects of building AI systems responsibly using generative models.
Key insights will include bias mitigation, model transparency, and regulatory compliance. Attendees will learn how to create fair, interpretable, and accountable AI systems, with insights drawn from real-world case studies.
This talk emphasizes the importance of human oversight and aligning AI outputs with societal values.
Key Takeaways:
- Ethical frameworks for responsible AI
- Bias reduction in generative models
- Model transparency and interpretability
- Compliance with AI regulations
- Human-in-the-loop system design
- Real-world responsible AI use cases
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}