Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
なぜトークンは足りなくなるのか? 〜LLMとうまく連携するためにエンジニア がやるべきデータ...
Search
Kashira
May 20, 2026
Technology
48
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
なぜトークンは足りなくなるのか? 〜LLMとうまく連携するためにエンジニア がやるべきデータ整備の話〜
技育CAMPアカデミア(2026/05/14(木) 18:00〜18:45) での発表資料です。
Kashira
May 20, 2026
More Decks by Kashira
See All by Kashira
LLM-Readyなデータ基盤を高速に構築するためのアジャイルデータモデリングの実例
kashira
0
480
【PIXIV DEV MEETUP 2024】AirflowのKubernetes移行 ~ Kubernetesで運用するのは思ったより難しくない ~
kashira
0
1.9k
【PIXIV MEETUP 2023】ピクシブのデータインフラと組織構造
kashira
1
6k
Other Decks in Technology
See All in Technology
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
220
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
310
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
150
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
2
150
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
1
520
product engineering with qa
nealle
0
150
AI Driven AI Governance
pict3
0
210
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.3k
Zoom2Youtube.Claude
kawaguti
PRO
2
460
Featured
See All Featured
Everyday Curiosity
cassininazir
0
250
Build your cross-platform service in a week with App Engine
jlugia
234
18k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Navigating Weather and Climate Data
rabernat
0
280
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
How to build a perfect <img>
jonoalderson
1
5.8k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Transcript
なぜトークンは足りなくなるのか? LLMとうまく連携するためにエンジニア がやるべきデータ整備の話 2026/05/14 pixiv Inc. 新田大樹(kashira)
2 自己紹介 新田 大樹 (@kashira) ピクシブ株式会社 Platform Div, Data Unit
テックリード X: @kashira202111 BigQuery を中心とした全社データインフラの開発・運用を統括。 現在は LLM を活用したデータ分析エージェントの開発をリードし、社内の データ民主化を推進しています。
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 3
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 4
会社紹介 5 特徴 1. 複数プロダクト 2. 少数精鋭で運営 3. プロダクト毎で技術選定
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 6
Q. LLMを使っていますか? • 現状: ◦ 学生の皆さんも使っている人はいるはず ◦ 「自分のコードをLLMに書かせる」のはすごく便利 ◦ 爆速でプロトタイプが作れる
◦ Googleでは 新規コードの75%はLLMで作られている ▪ Cloud Next ‘26: Momentum and innovation at Google scale 7
学生からの不安 • 「LLMが全部コードを書いてくれるなら...」 • 「数年後、僕らエンジニアの仕事ってなくなるんですか?」 8
個人的には無くならないと思っている • エンジニアに求められるスキルは変化するが、無くならない • 言われた通りにプログラムするスキルの需要は低くなるが、 それだけがエンジニアの仕事ではない 9
企業が直面しているLLMでの壁 • コード作成以外のプロセスがボトルネックになっている • ビジネスメンバーの利用ハードルが高い • (new) コストが高い, トークンが足りない ◦
LLMを使った分だけ、リターンがちゃんと出るのか? 10
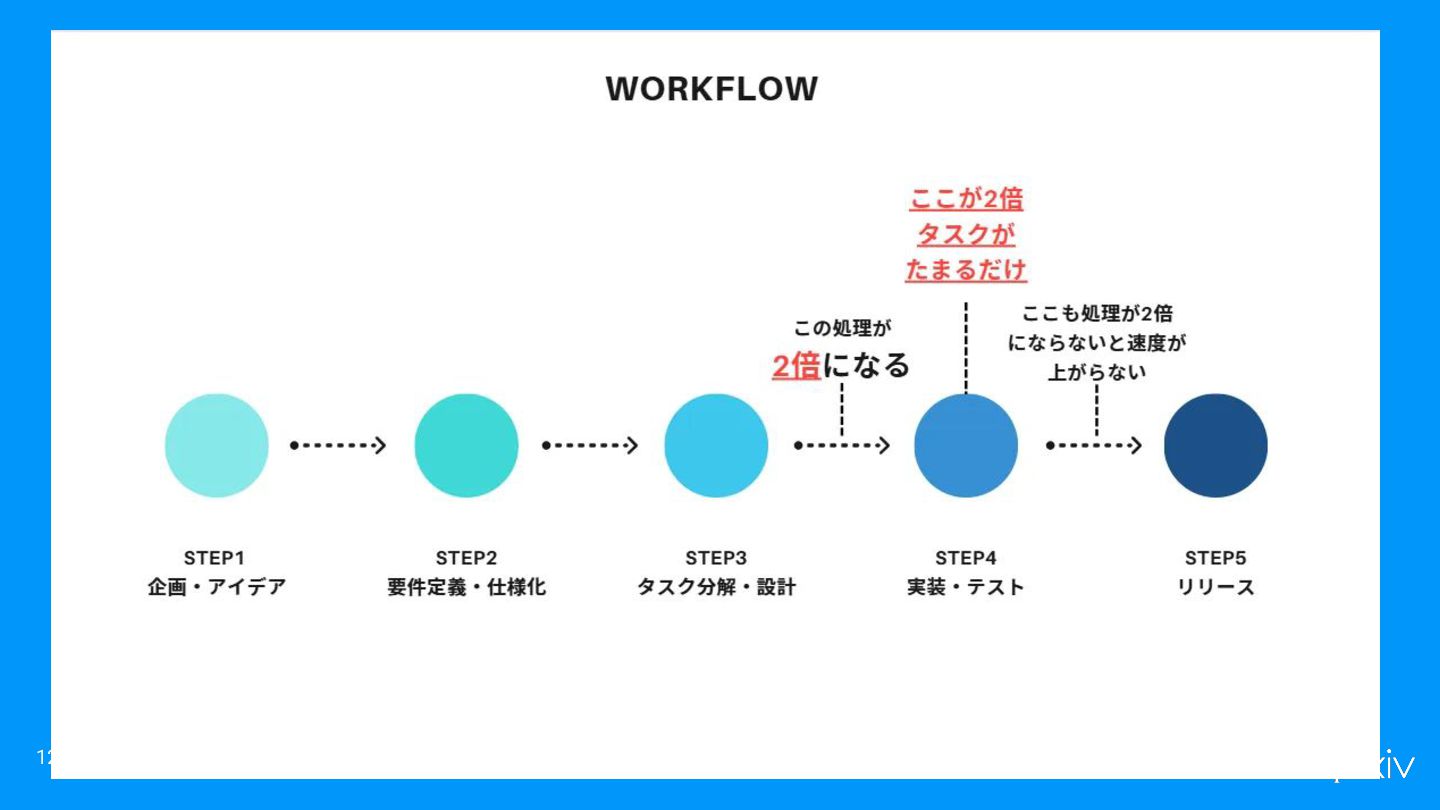
コード作成はビジネスの一部に過ぎない • LLMによってコード作成は早くなりましたが、これは開発の一部に過ぎません • コード作成だけを早くしても開発全体のスピードは速くならない • 自動化する部分を増やして、一連の流れ(Value Stream)の全体を 最適化するのが重要 11
全てを自動化するのではない。任せない部分を作るのも大事な決定。
12
ビジネスメンバーのLLM利用ハードルが高い • Claude CodeやCursorを触るのに抵抗がある人が多い • セットアップがエンジニア特有で難しい • 雑に使うのはセキュリティ的に危ない • コスパが悪い
13 もちろん出来る人もいるし、増えているが多くがそうではない。
トークンが足りない • 基礎的なLLMの知識を知らずに使っていると、トークンの消費が激しい • 例えば ◦ どのタイミングでトークンが消費されるのか? ◦ Context Windowの概念や特性
14 Github Copilotが従量課金になったりと、 今後トークン最適化が重要なテーマになると考えている。
これら全て、 環境整備(データ整備)の問題 15
LLMのための環境整備のスキルは 需要が高まっている 16
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 17 あくまで一例なので、他にも活躍できる場所はいっぱいあるよ。 従来のエンジニアリングでも不要になるとは思わないけど、 今回は扱わない。
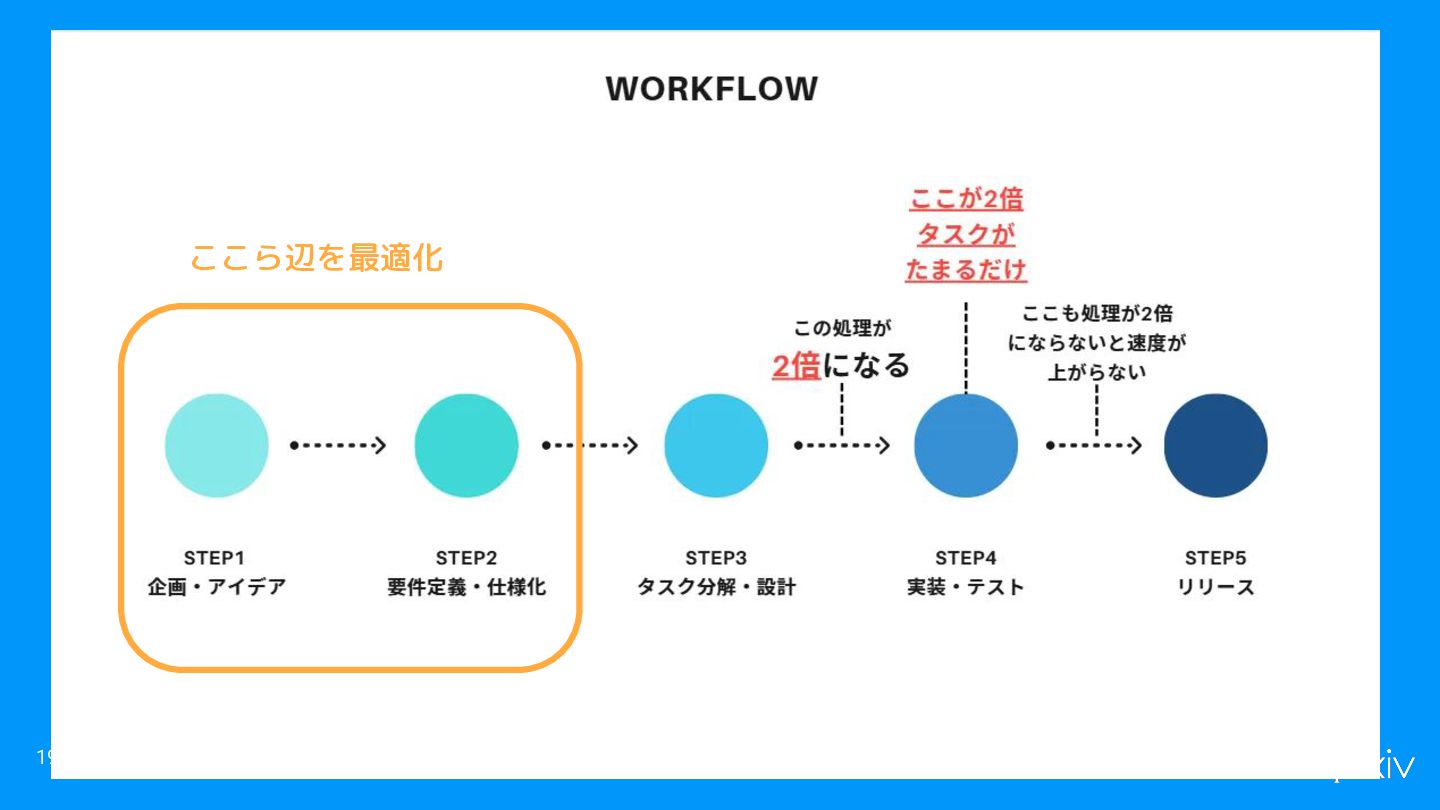
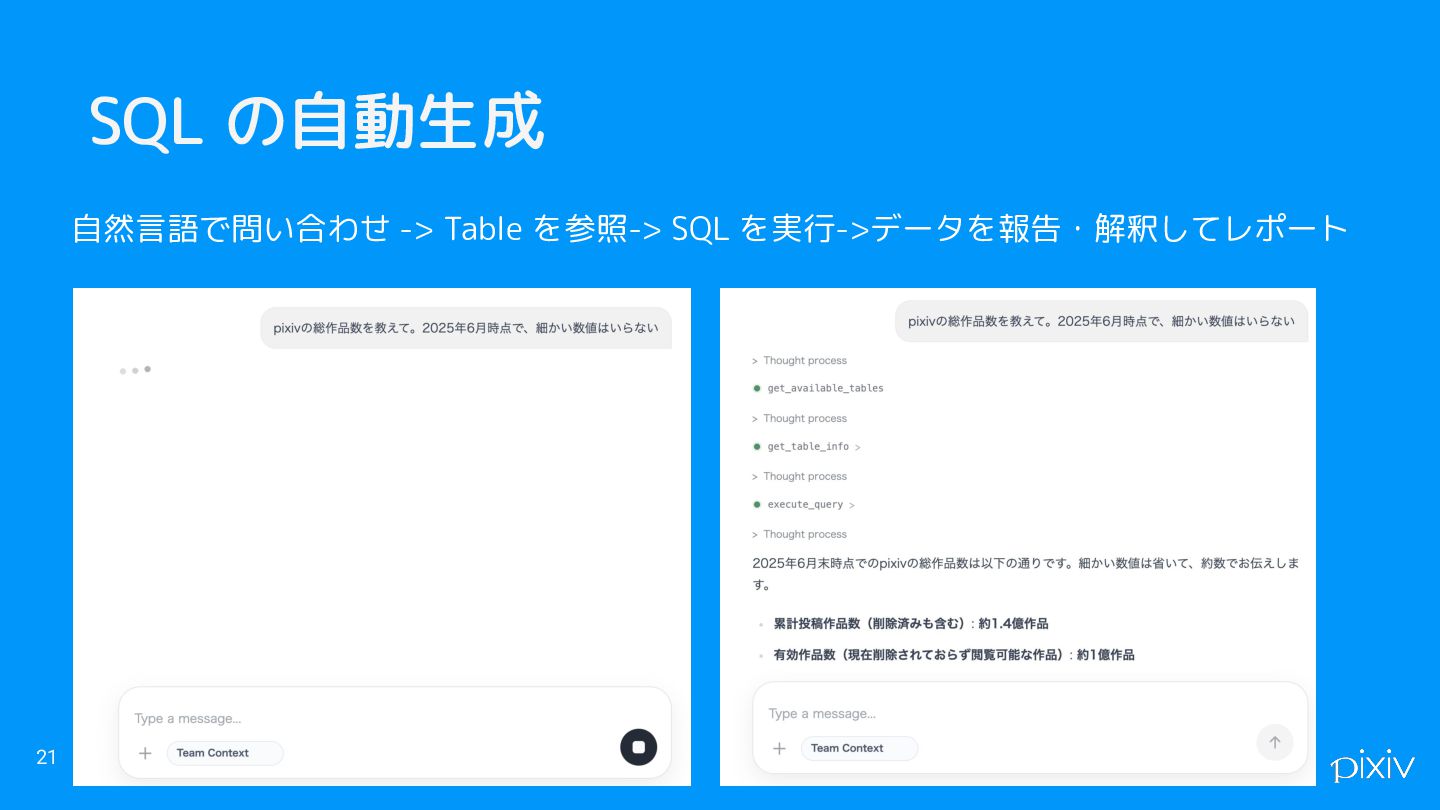
内製のデータエージェント、kaiについて 18 • ピクシブ株式会社、内製のデータエージェントです • 分析用のデータベース、BigQueryにSQLを自動で実行して、 インサイトを自動で引き出します ◦ 先週リリースした機能の利用度を教えて ◦
登録者数の性別比は? • Before ◦ SQLをかける人だけが、数値を調べられた ◦ 大体数値を見るのに、エンジニアの手を借りつつ2-3日かかっていた • After ◦ 30分-1時間で気になる数値を誰でもサクッと調べられる
19 ここら辺を最適化
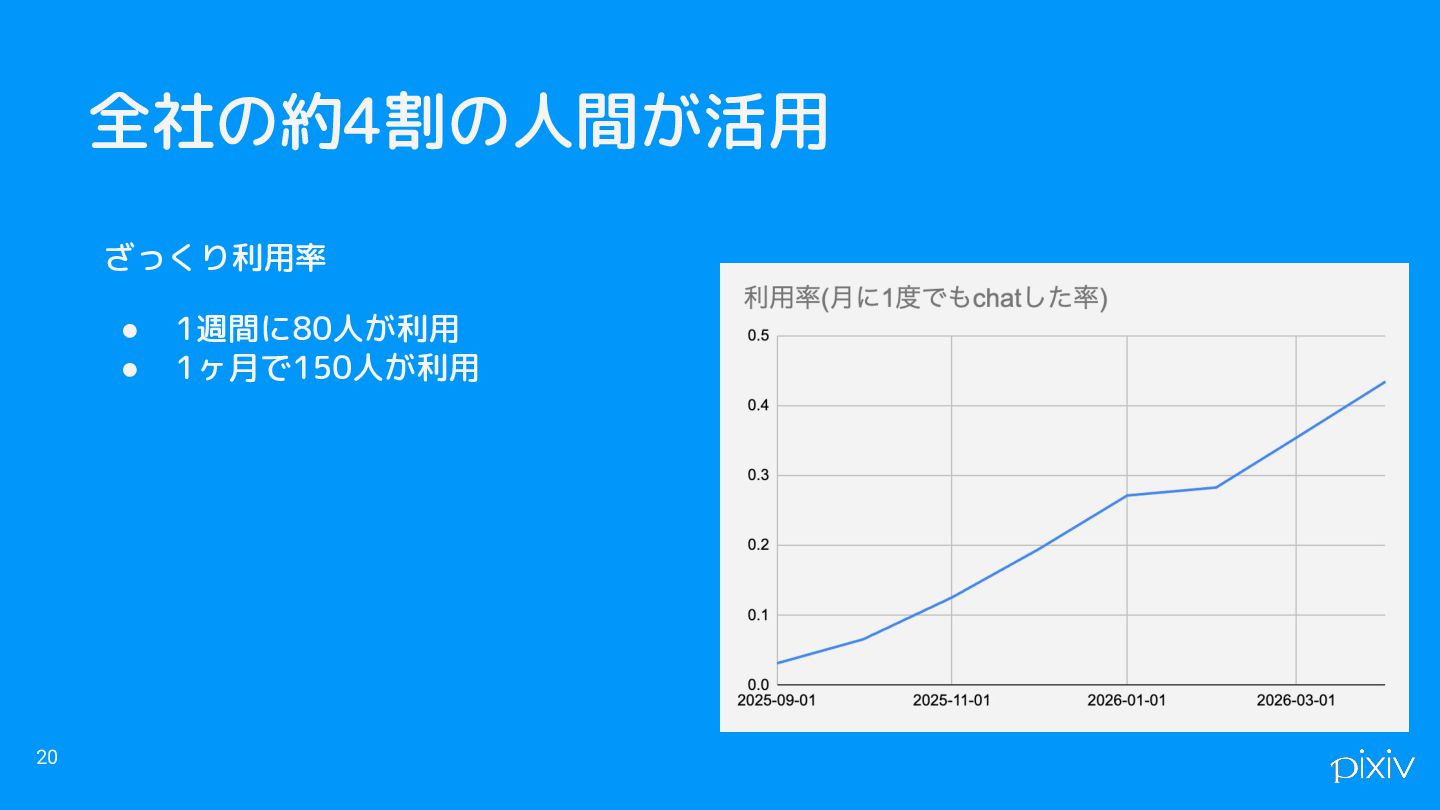
全社の約4割の人間が活用 ざっくり利用率 • 1週間に80人が利用 • 1ヶ月で150人が利用 20
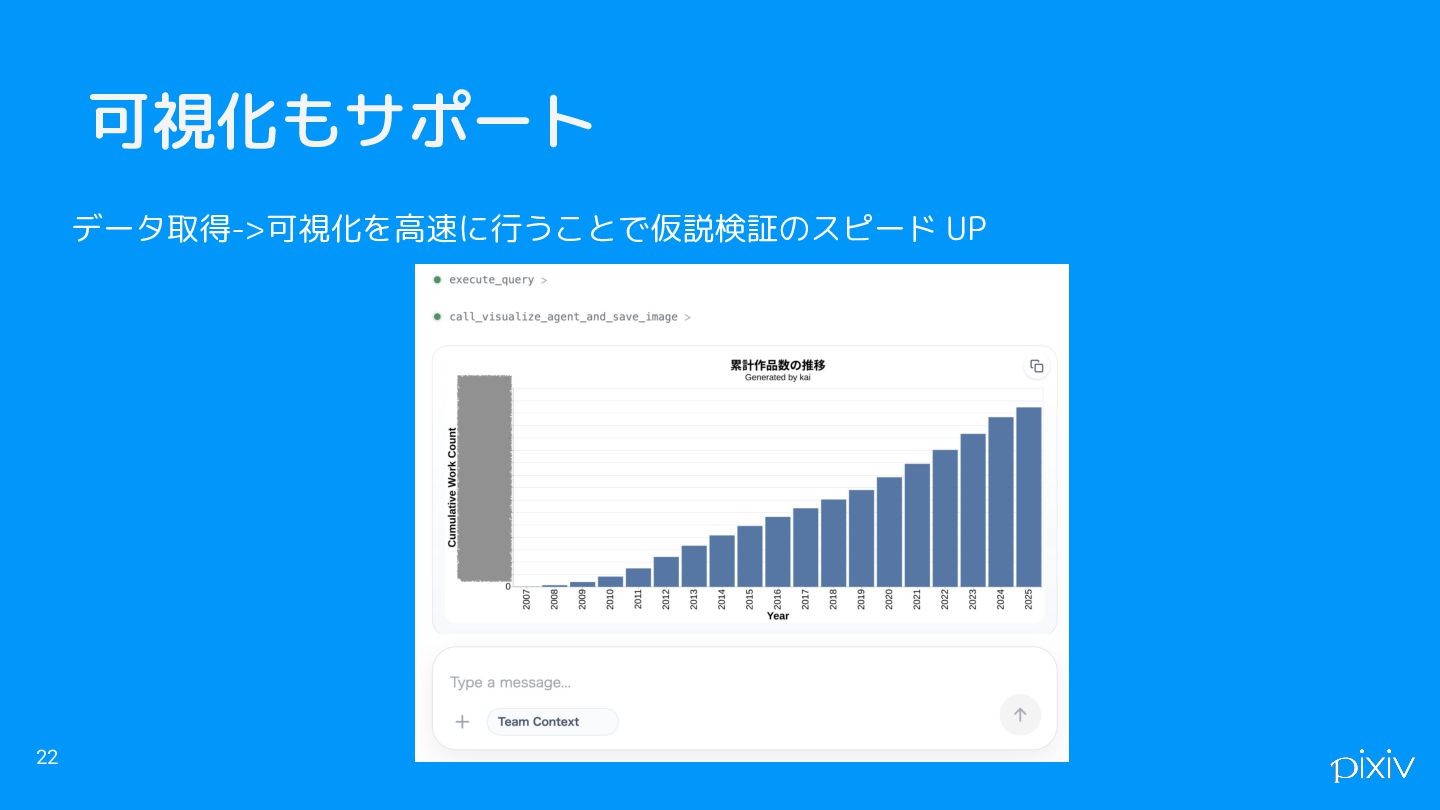
SQL の自動生成 21 自然言語で問い合わせ -> Table を参照-> SQL を実行->データを報告・解釈してレポート
可視化もサポート 22 データ取得->可視化を高速に行うことで仮説検証のスピード UP
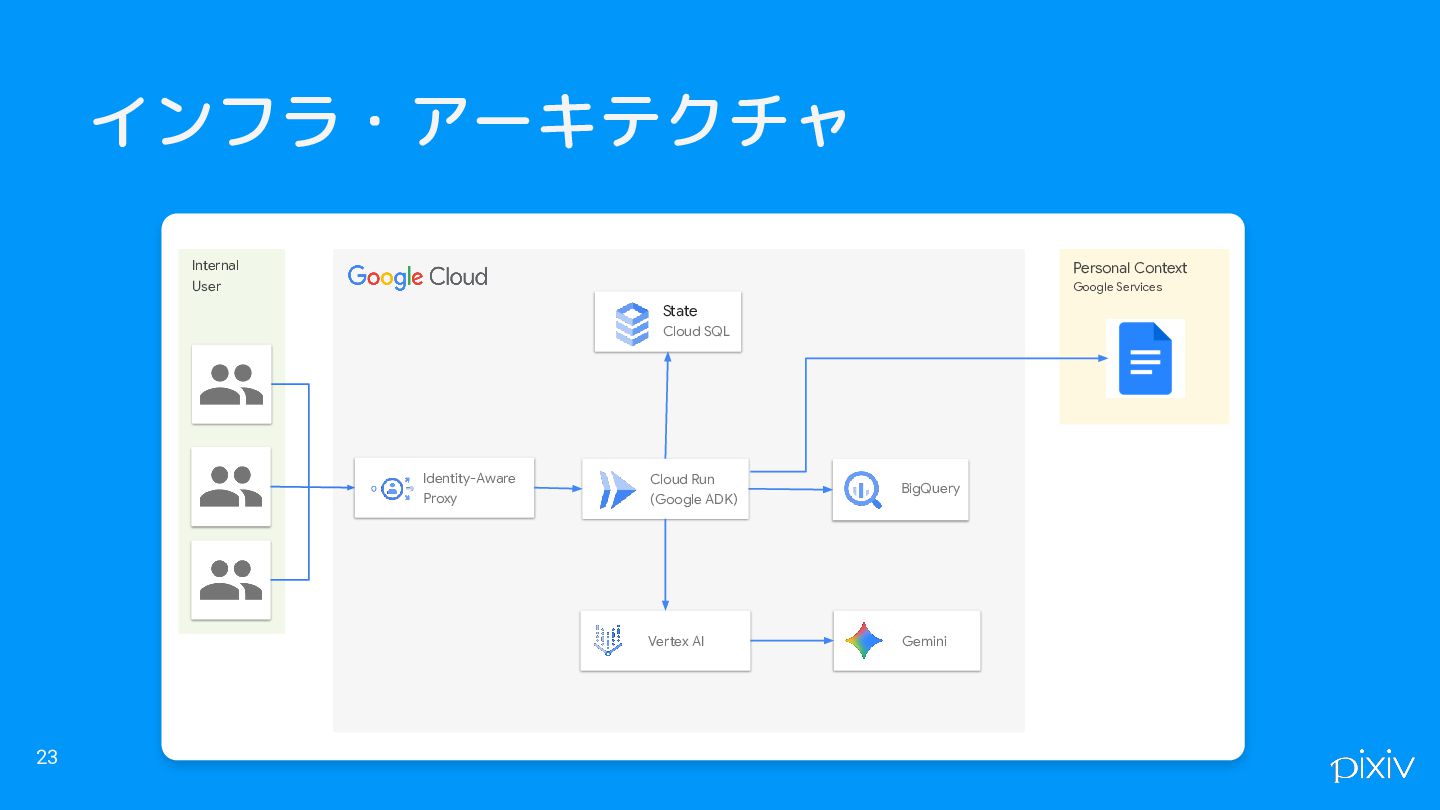
インフラ・アーキテクチャ 23 Internal User Personal Context Google Services Identity-Aware Proxy
Cloud Run (Google ADK) Vertex AI BigQuery Gemini State Cloud SQL
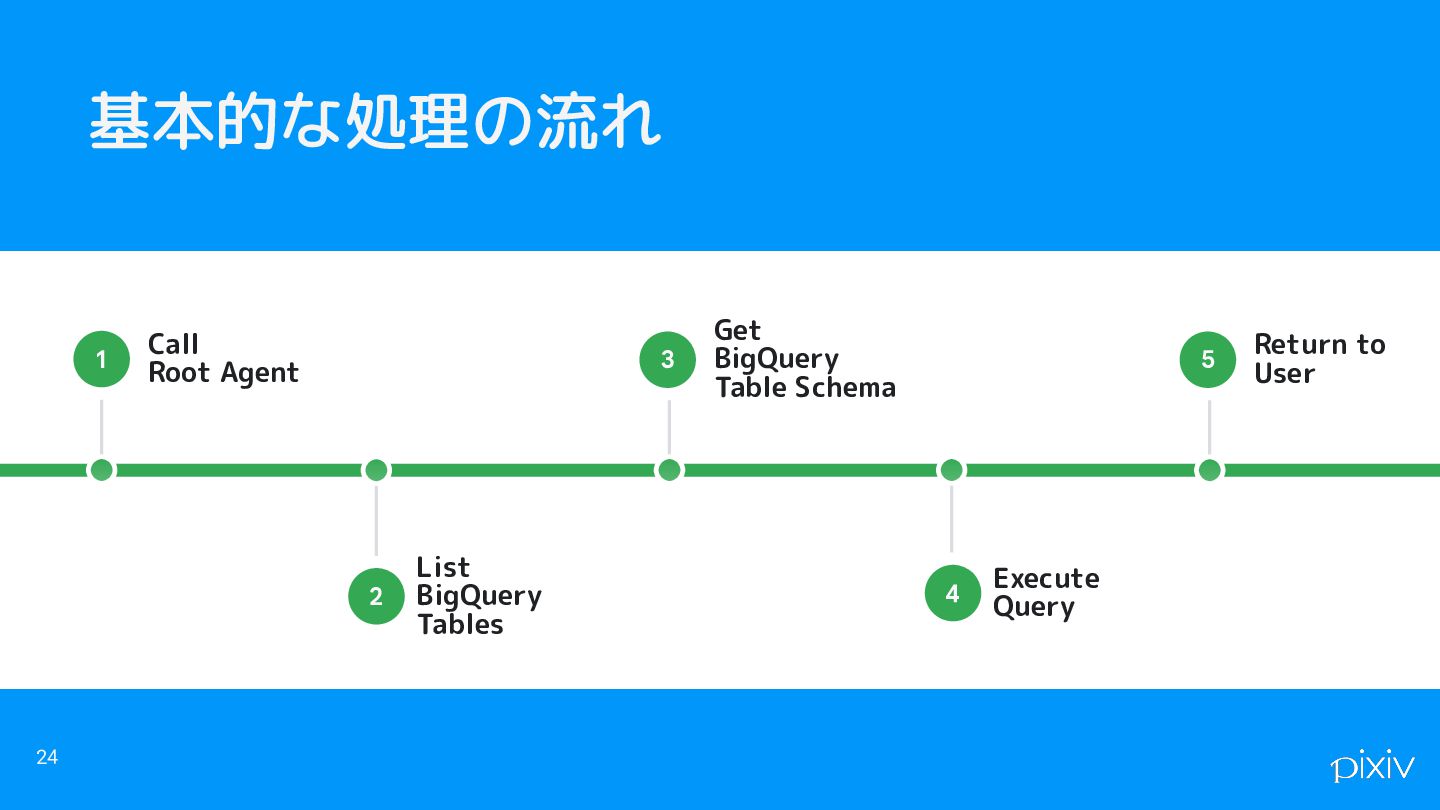
基本的な処理の流れ 24 List BigQuery Tables 2 Call Root Agent 1
Get BigQuery Table Schema 3 Execute Query 4 Return to User 5
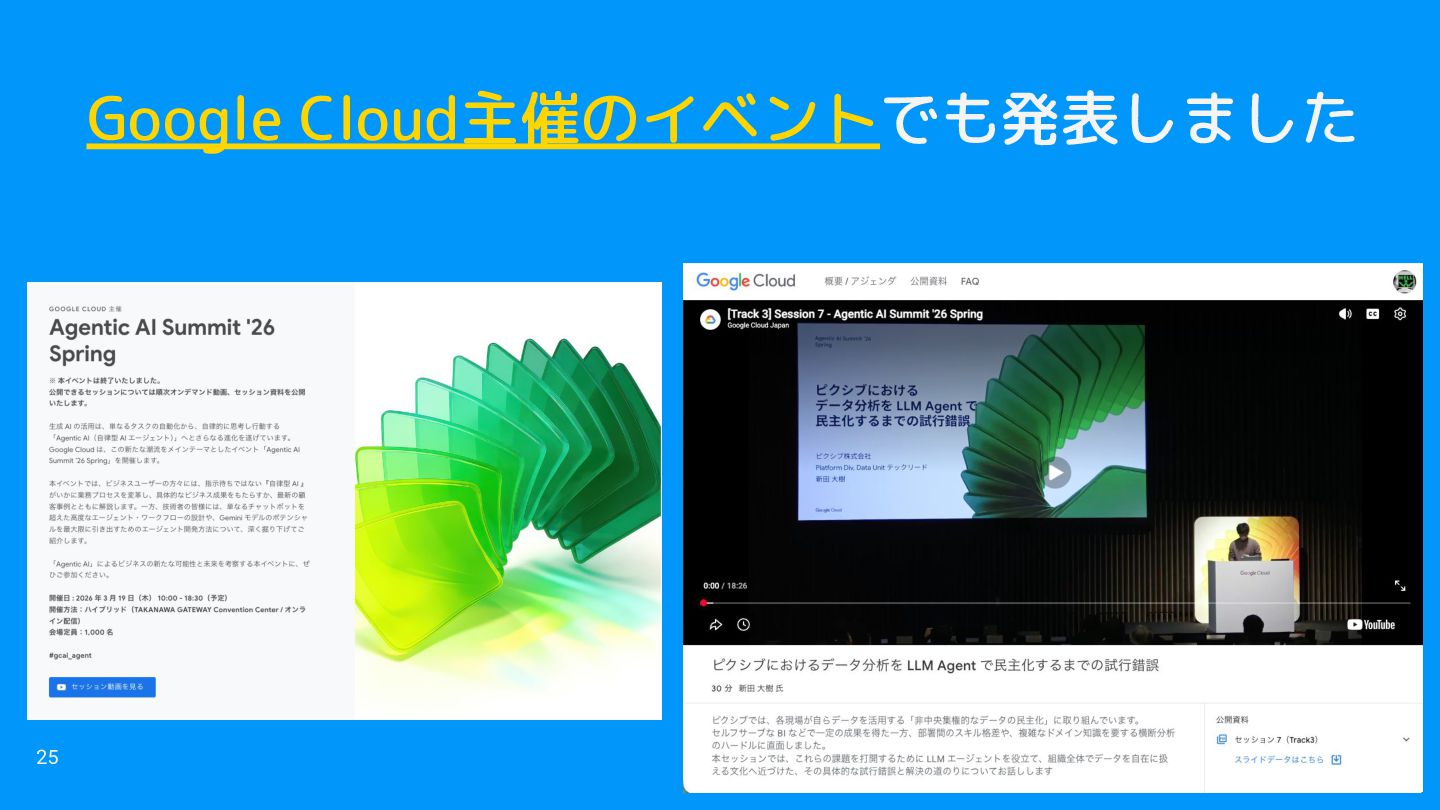
Google Cloud主催のイベントでも発表しました 25
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 26
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 27
まずは、基礎概念の紹介 28
LLMは過去のテキストを元に次の単語を予 測する 29 引用: 3Blue1BrownJapan, LLMの仕組み(簡単 バージョン), https://youtu.be/y 7NQiNER6r4?si=T9 uvQj0P5r2IQBWH&t
=172
学習していないことは知らない PROMPT # 自社の売上データ(未学習データ) 昨日のA商品の売上は50万円、 B商品の売上は120万円でした。 # 質問 合計売上と、どちらが売れたか教え て。
LLM ANSWER 承知いたしました。 合計売上は170万円です。 B商品(120万円)の方がA商 品(50万円)よりも売れてい ます。 データがPublicでなくても Context として与えれば推論可能です。
Agentとは 31 • LLMが学習したデータだけでは解けない問題は多い ◦ 例えば、ピクシブ株式会社が保有する独自データを使った分析など • 独自データを毎回プロンプトに入れるのは無理 • これを解決するのが、Agent
system • 自律的にツールを使って、外部データを入力する、Actionを起こすことで依頼を 達成する
Agentとは 32 # Agentの超ざっくりコード is_running = True history = []
# Contextを積み上げるための履歴 while is_running: # 1. 環境や過去の履歴から情報を取得 (RAGやMemory) context = get_context_and_data(history) # 2. Contextに基づき、次に取るべき行動を決定 (LLM Call) action = llm.decide_next_step(context) # 3. 行動: 決定された行動 (Tool) を実行 tool_output = execute_action(action) # 4. 履歴を更新し、次のループへ history.append(tool_output) # 終了条件の確認 if action == "RETURN_FINAL_ANSWER" or max_iterations_reached(): is_running = False
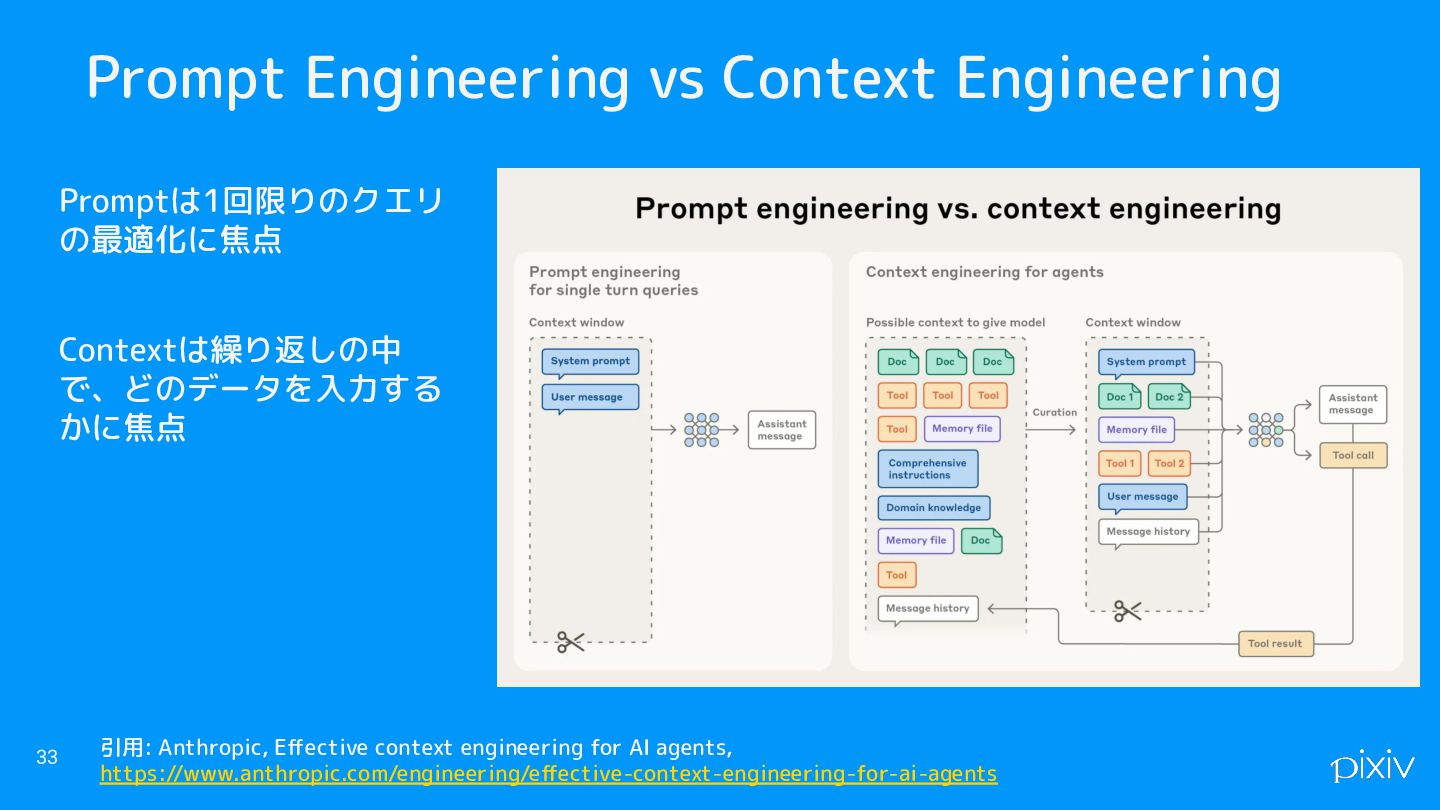
Prompt Engineering vs Context Engineering 33 Promptは1回限りのクエリ の最適化に焦点 Contextは繰り返しの中 で、どのデータを入力する
かに焦点 引用: Anthropic, Effective context engineering for AI agents, https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
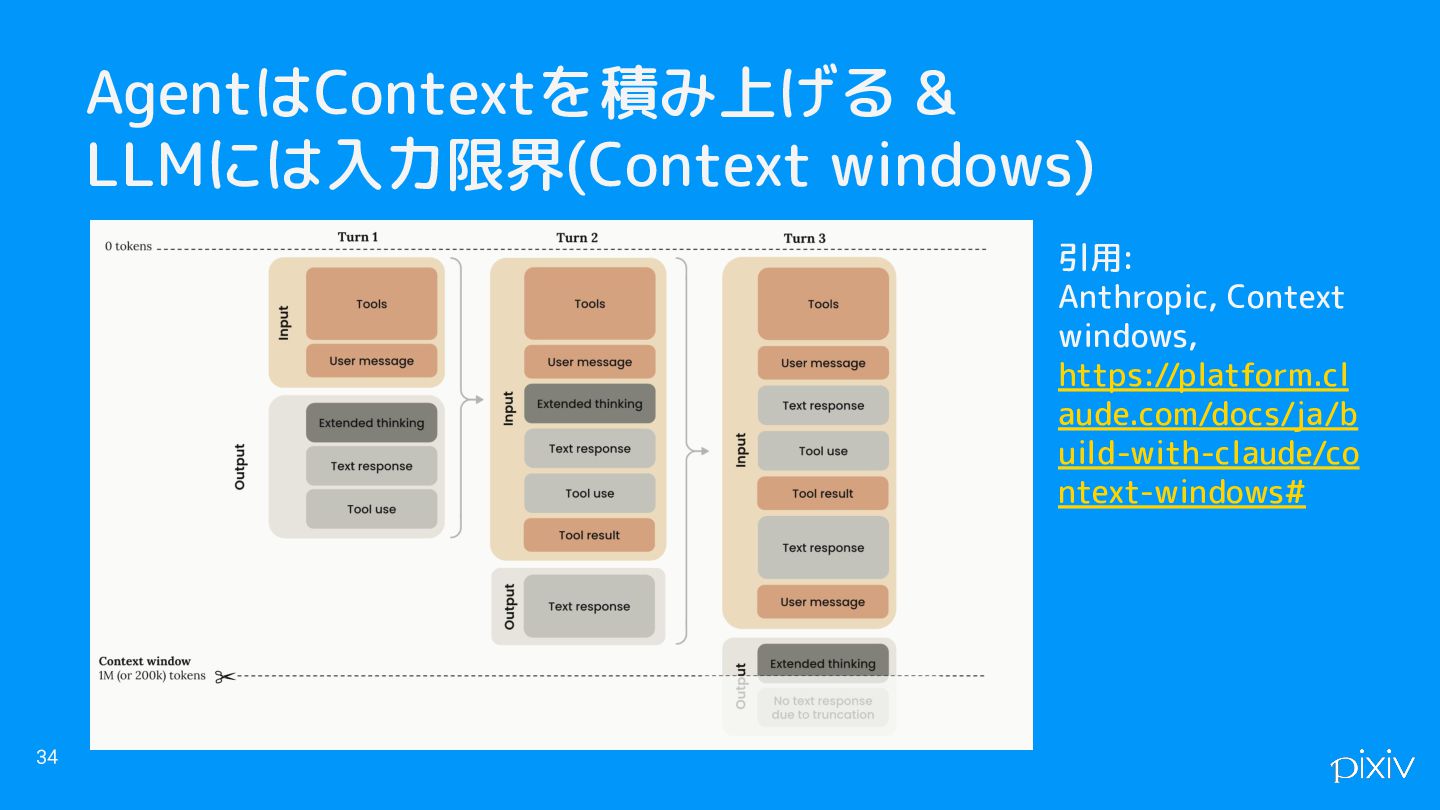
AgentはContextを積み上げる & LLMには入力限界(Context windows)がある 34 引用: Anthropic, Context windows, https://platform.cl
aude.com/docs/ja/b uild-with-claude/co ntext-windows#
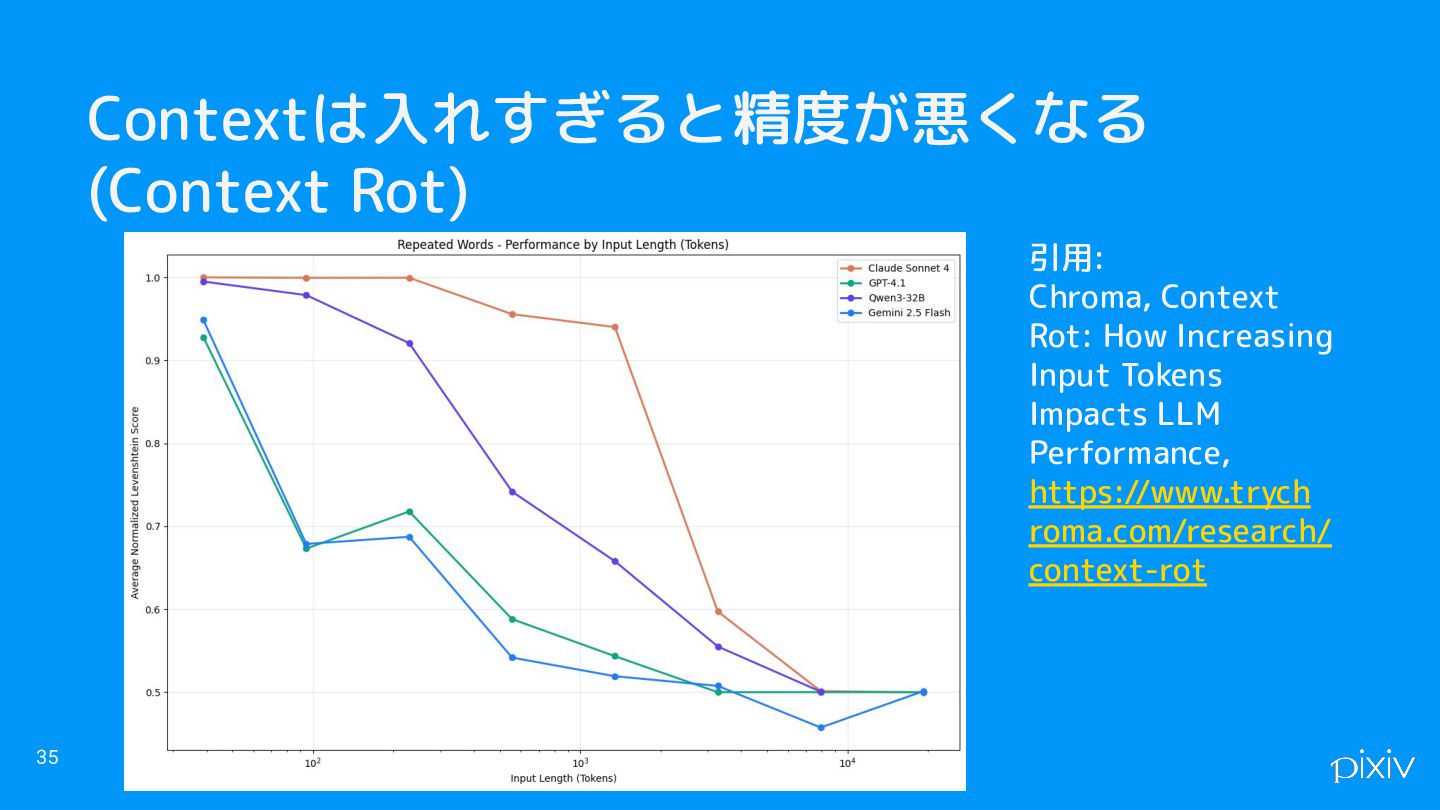
Contextは入れすぎると精度が悪くなる (Context Rot) 35 引用: Chroma, Context Rot: How Increasing
Input Tokens Impacts LLM Performance, https://www.trych roma.com/research/ context-rot
Agent作成の要は Context Engineering 36
Context Engineeringとは、 LLMに渡すデータを制御する エンジニアリング 37
Context Engineeringは どんなことをしているのか? 具体例を見ていこう 38
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 i. Case1: 精度の壁 ii. Case2: データ整備の壁 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 39
kaiの背景 40 背景: 社内のDBにデータは集まっているが、SQLを書かないと分析できないケースが多い。 そのため、PdMやマーケは数値をあまり見ることが出来ず、施策を行う合意形成が遅 く、また一部では勘で仕事を進めている。 目指す解決策: Agentを使って、SQLを自動で作って分析できる仕組みを作ろう。
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 i. Case1: 精度の壁 ii. Case2: データ整備の壁 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 41
初期の実装 まずは、既存の業務フローの通りの指示をLLMにやらせようとしました。 1. 普段使われているダッシュボード(Looker Explore)を特定する 2. ダッシュボードで使われているクエリを参照する 3. そのデータからクエリを作成する 4.
実行する 5. 結果を返す 42
上手くいきませんでした 43
当初のLLMの出力: user_idごとにイラスト・漫画の合計作品数を教えて 44 LLMの出力結果 期待している回答
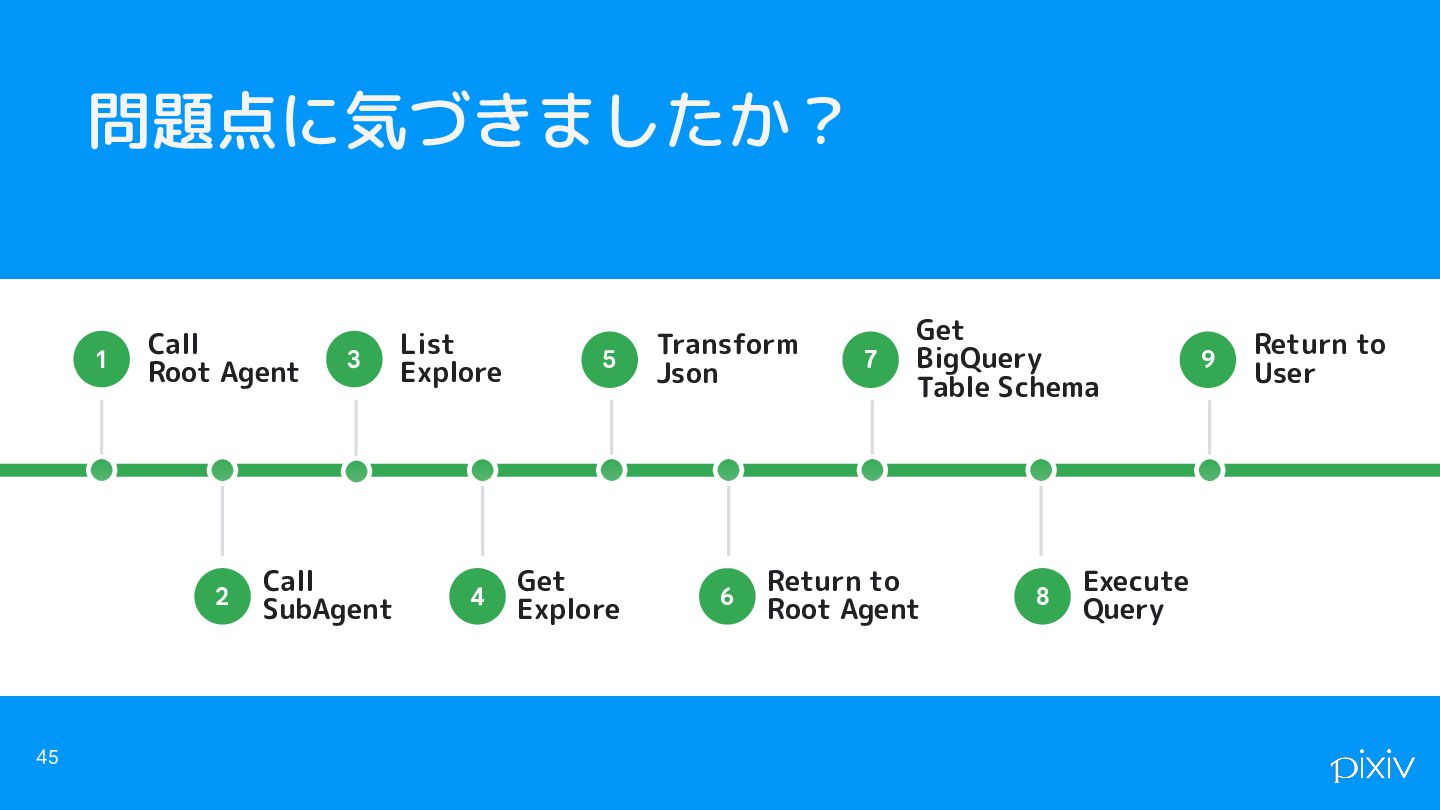
問題点に気づきましたか? 45 Call SubAgent 2 Call Root Agent 1 List
Explore 3 Get Explore 4 Transform Json 5 Return to Root Agent 6 Get BigQuery Table Schema 7 Execute Query 8 Return to User 9
問題点 • ダッシュボードが500個以上あり、整備されていない汚いデータになっている ◦ ので、間違ったダッシュボードを引っ張ってきて値がズレることが多い • 要求するステップ数が多い ◦ Toolの呼び出し、実行結果などのイベントがトークンの無駄な 消費に繋がっている
◦ コンテキストエンジニアリングとは多少ズレるけど、LLMは確率動作なので 何回も実行すればそれだけ間違いの確率は増えていく 46
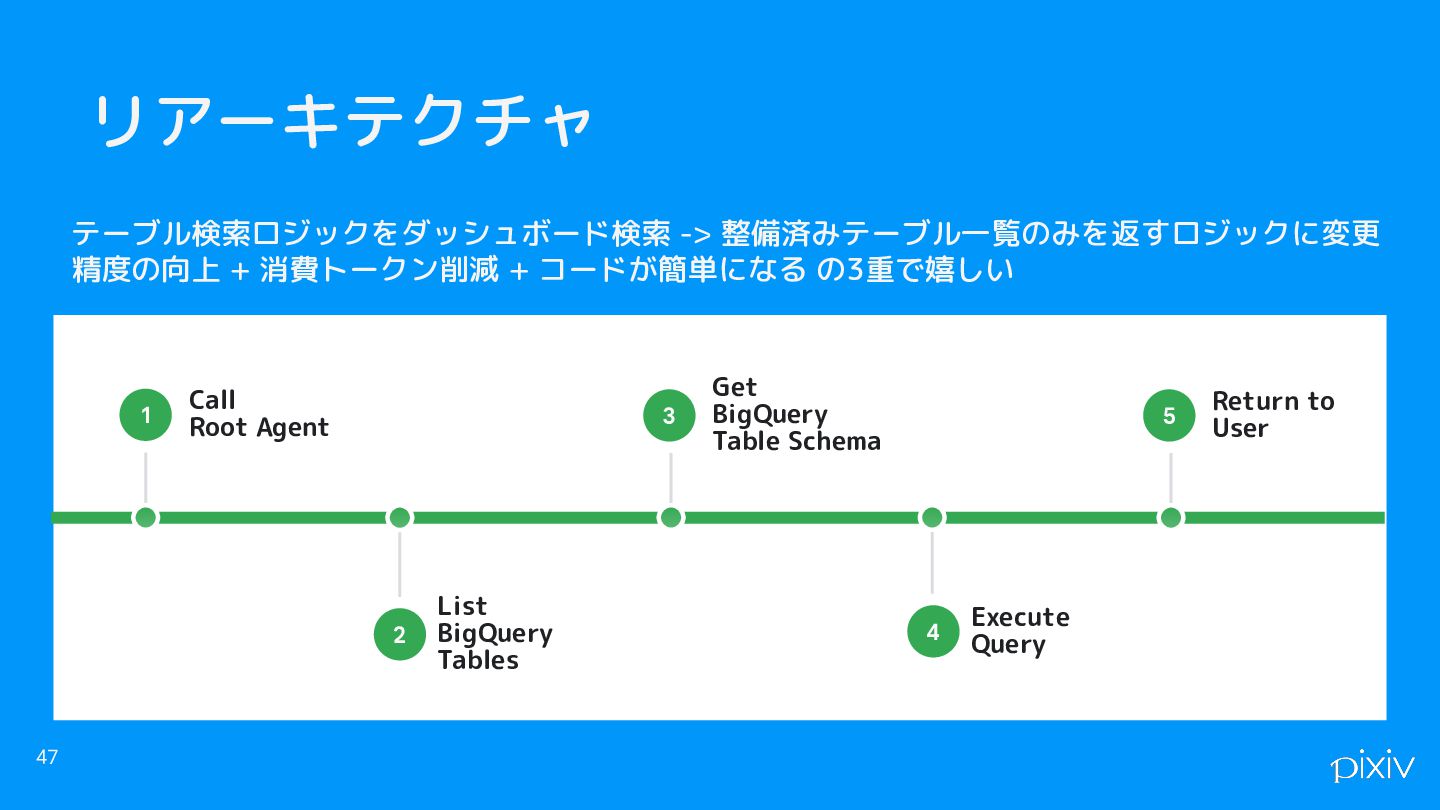
リアーキテクチャ 47 List BigQuery Tables 2 Call Root Agent 1
Get BigQuery Table Schema 3 Execute Query 4 Return to User 5 テーブル検索ロジックをダッシュボード検索 -> 整備済みテーブル一覧のみを返すロジックに変更 精度の向上 + 消費トークン削減 + コードが簡単になる の3重で嬉しい
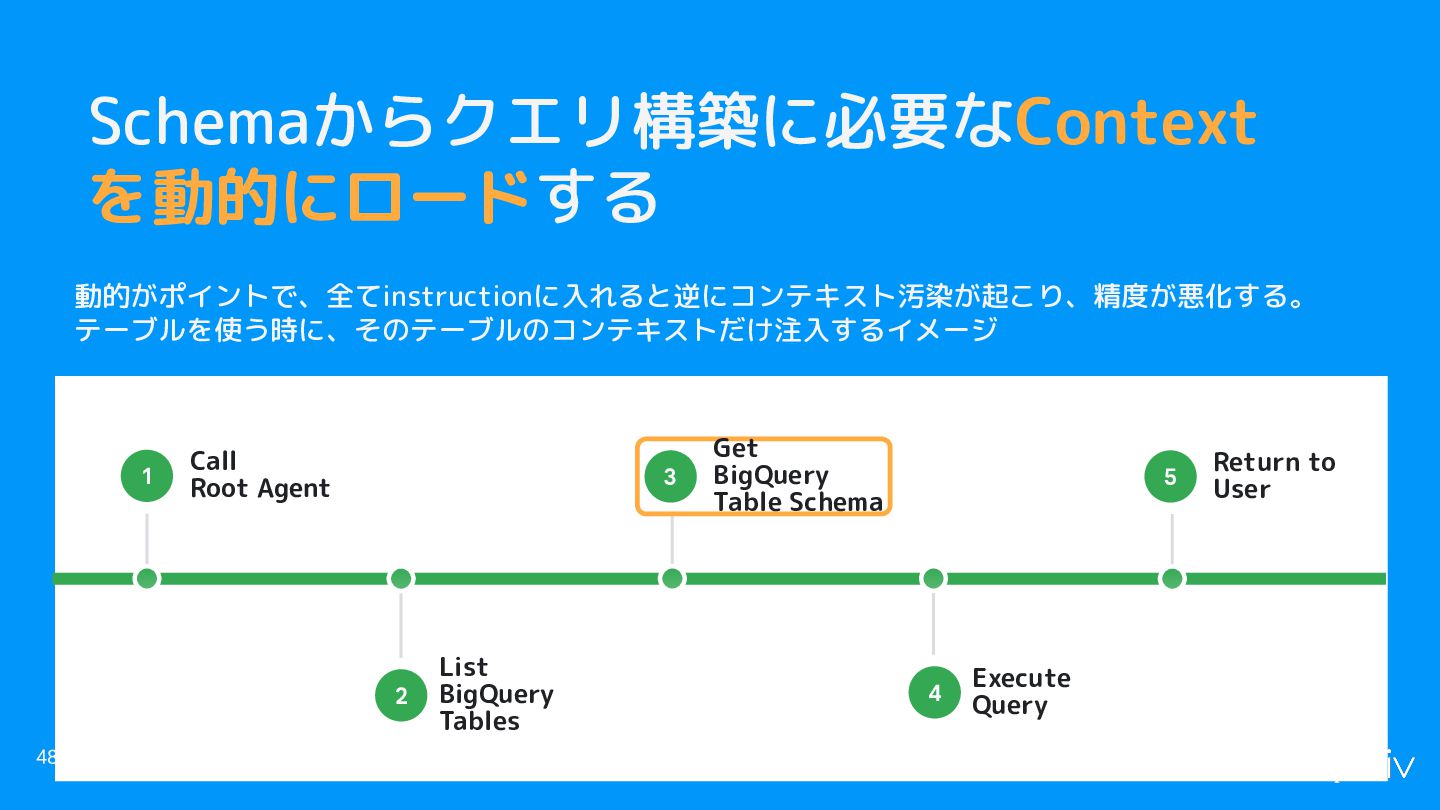
Schemaからクエリ構築に必要なContext を動的にロードする 48 List BigQuery Tables 2 Call Root Agent
1 Get BigQuery Table Schema 3 Execute Query 4 Return to User 5 動的がポイントで、全てinstructionに入れると逆にコンテキスト汚染が起こり、精度が悪化する。 テーブルを使う時に、そのテーブルのコンテキストだけ注入するイメージ
メタデータ整備 49 - name: work_type description: | Definition: 作品の種類区分。 Example
Data: - "illustration": イラスト - "manga": マンガ - "ugoira": うごイラ - "novel": 小説 Transformation Rule: ソースの作品種別コードを標準名称に変換 tests: - not_null - accepted_values: values: ['illustration', 'manga', 'ugoira', 'novel'] テーブルスキーマを見れば クエリが書けるようにする • Filteringの値の候補 • 日本語とのマッピング • NULL定義
改善後のLLMの出力: user_idごとにイラスト・漫画の合計作品数を教えて 50 期待している回答 LLMの出力結果 データ整備すれば基礎的なクエリは、ほぼ完璧に出せる
LLM Readyなパイプラインを作ることで 精度・コストで良い結果に 51
LLM Readyなデータがあれば、精度は上がる => データ整備が非常に重要 52
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 i. Case1: 精度の壁 ii. Case2: データ整備の壁 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 53
新たな問題点 データ整備が追いつかない 54
データ整備がボトルネック 55 整備済みのテーブル一覧を返す = 精度を出すにはテーブル整備が必要になる。 それ以外のテーブルを使いたケースが多く、業務適応が部分的になっていた。 例: • OK: BOOTHのBOOST機能込みの売り上げが見たい
from 経営陣 • NG: BOOTHの配送手数料、手数料を分解した売り上げが見たい from 現場 • NG: Comicの売り上げが見たい from 現場
Team Contextを導入した Notionにページを作って、 それをLLMに事前に読み込ませる。 これにより、Team単位で関心のあるテーブ ルのピックアップやドメイン知識を覚えさ せることが出来るようになり、利用率や満 足度の向上に繋がった。 56
Team Contextの仕組み 57 INSTRUCTIONS
Team Contextの仕組み 58 INSTRUCTIONS # 指示 tool1を使って... # Team Context
{...} Markdownで注入
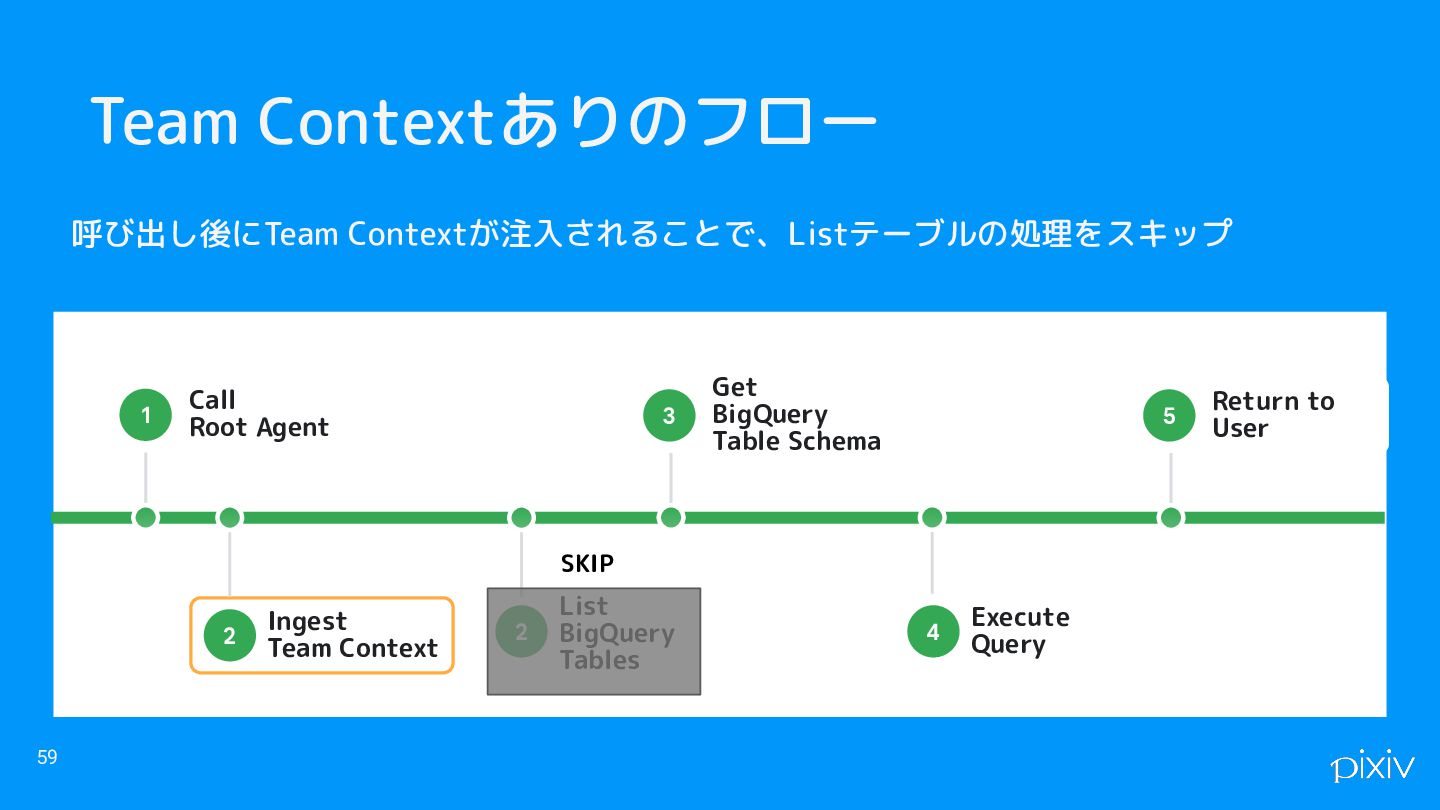
Team Contextありのフロー 59 Ingest Team Context 2 Call Root Agent
1 Get BigQuery Table Schema 3 Execute Query 4 Return to User 5 呼び出し後にTeam Contextが注入されることで、Listテーブルの処理をスキップ List BigQuery Tables 2 SKIP
チーム・個人・組織単位で コンテキストを最適化することで、 コストも精度的も良い結果に 60
他にContext Engineeringで扱う概念 • MCP vs Tool • Memory • Cache
• Skills • Event Compaction • RAG (Vector, Graph) vs Documents • Sub Agent 61 ただ単に使うのと、 裏側の仕組みを理解して使うのには天と地の差がある。
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 62
FDE (Forward Deployed Engineer) GTM Engineer (Go-To-Market) 63 こんなJobもあるんだくらいで見ていただけると 大事なのは、名前が付くくらい求められているJobということ
アジェンダ 1. 会社紹介 2. 企業のLLM活用の現状 3. 事例紹介 4. 技術的な深掘り a.
LLM周りの基礎概念の紹介 b. Context Engineeringの実例 5. 新しいJobの誕生 6. まとめ・なぜトークンは足りなくなるのか? 64
なぜトークンは足りなくなるのか? 65 コンテキストの運用を真面目に取り組んでいないことが多い • 同じセッションを使い回していませんか? ◦ コンテキストの汚染が発生しているので、より無駄なトークンを消費します • 読み込むデータが綺麗ですか?linkだらけになってませんか? •
MCPを大量につないで、LLMを混乱させていませんか? データが分散していませんか? • Agents.md や Claude.md が細かすぎませんか?逆に荒すぎませんか? • モデル選択を適切に行っていますか?Sub Agentでコンテキスト区切ってますか? 色々工夫をした上で、トークンが足りないのであれば、 あとはROIの問題なので課金するしかない
まとめ 66 • LLMの進化でエンジニアの仕事は無くならない ◦ 求められるスキルの変化はある • AgentやLLMの挙動を理解することは、コスパのよい開発スキルを持つこと ◦ Agentの挙動を何となく知っておけば生産性で他の人に差を付けられる
• LLMは開発だけではなく、ビジネスプロセスも最適化できる • ビジネスの最適化はブルーオーシャンなので、 Agentを作って勉強するのもおすすめです
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Agentとは 32 # Agentの超ざっくりコード is_running = True history = []](https://files.speakerdeck.com/presentations/3a8d3d05624d4c0aae28e145cfe18c90/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}