Share
TensorFlow User Group (TFUG) のMeetup#3の発表スライドです。数千万人ユーザー規模のアドネットワークAkaNeの広告配信の最適化モデルを、ニューラルネットで構築した事例を紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
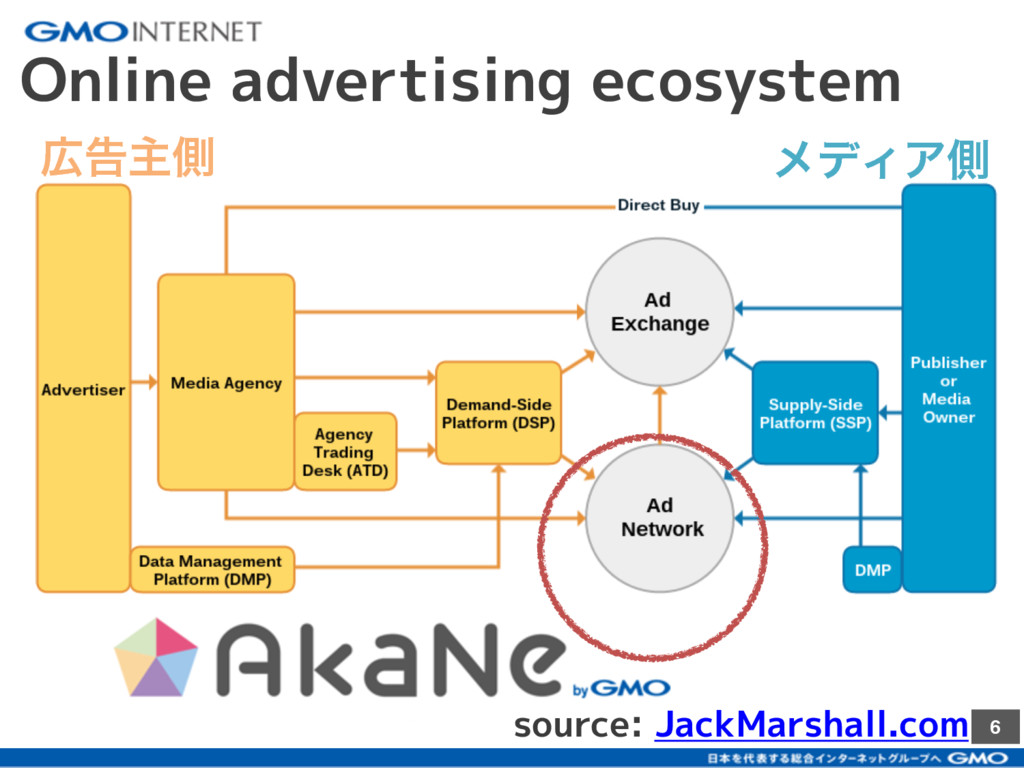{kind=link}
{kind=link}
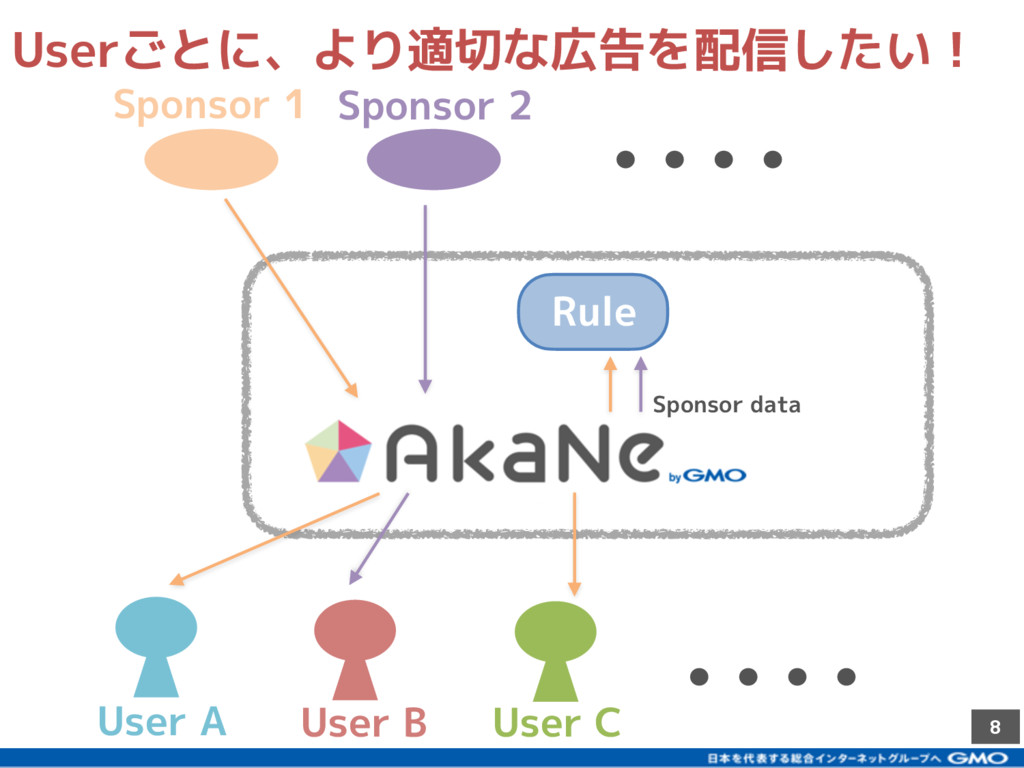{kind=link}
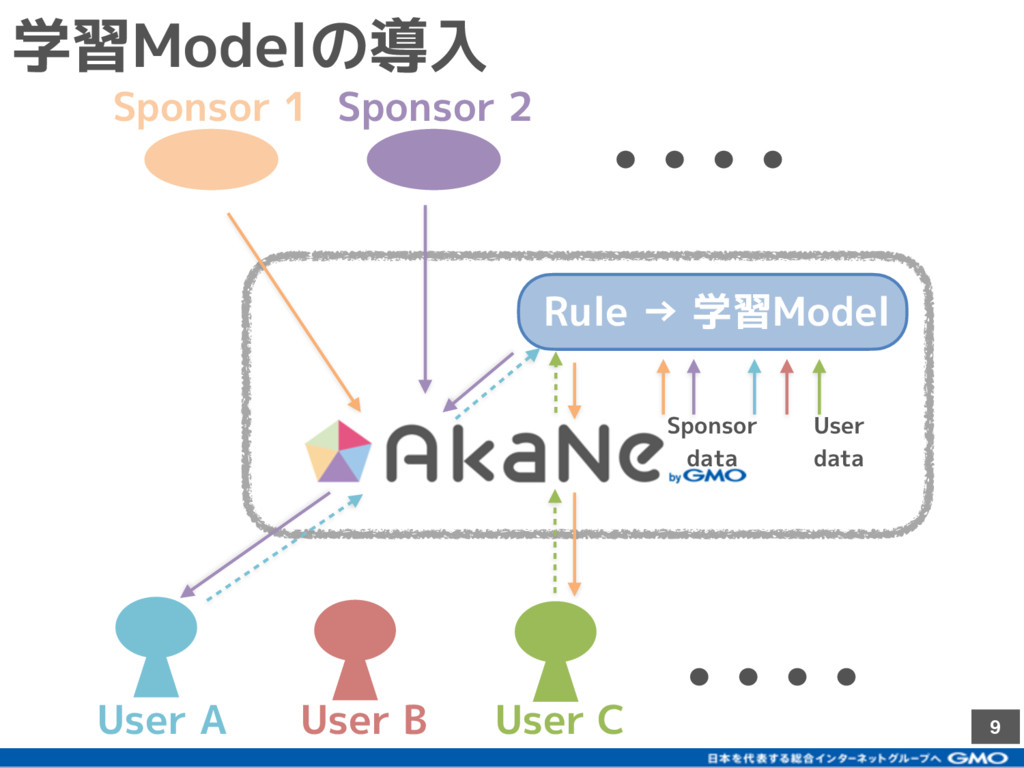{kind=link}
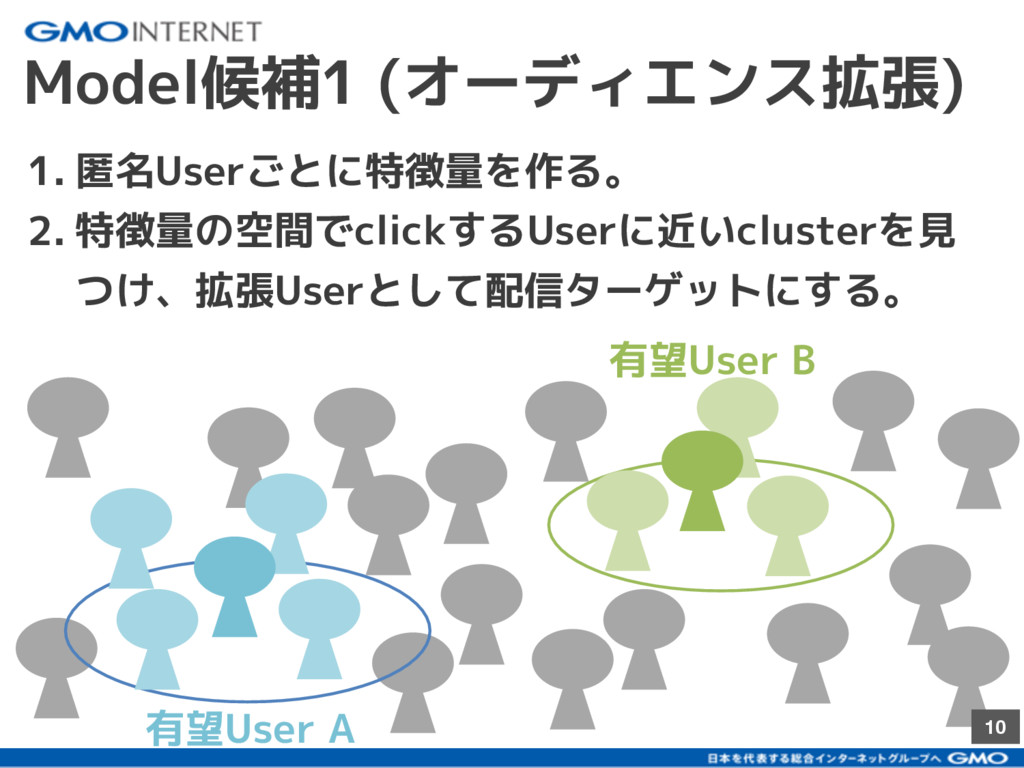{kind=link}
{kind=link}
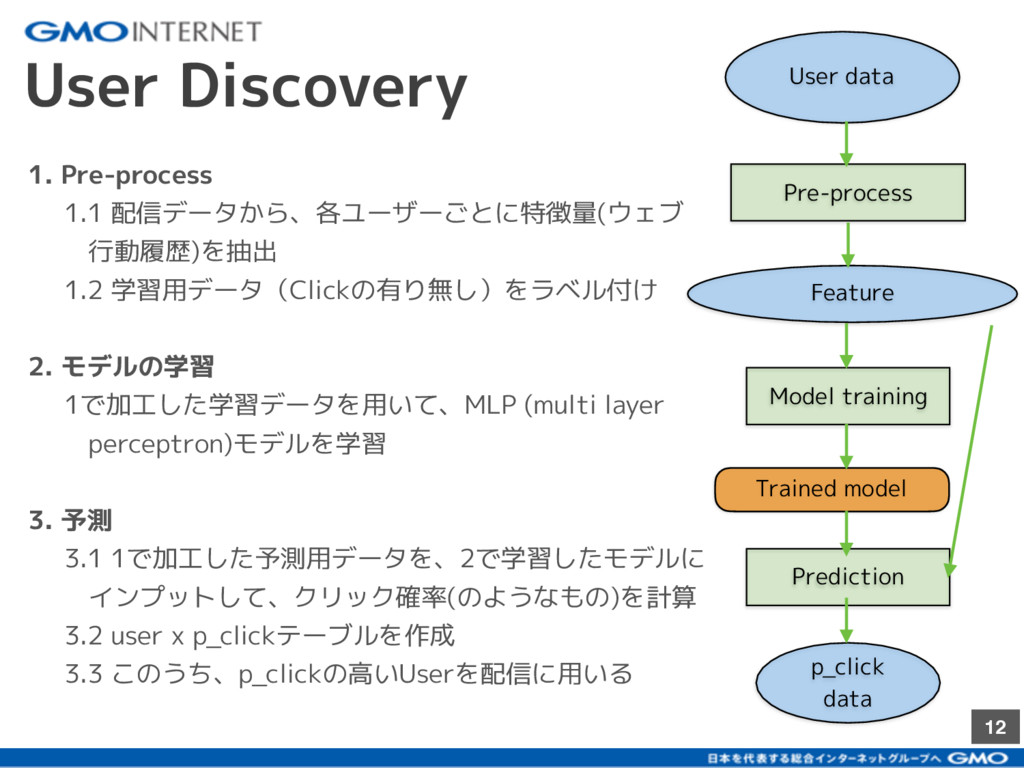{kind=link}
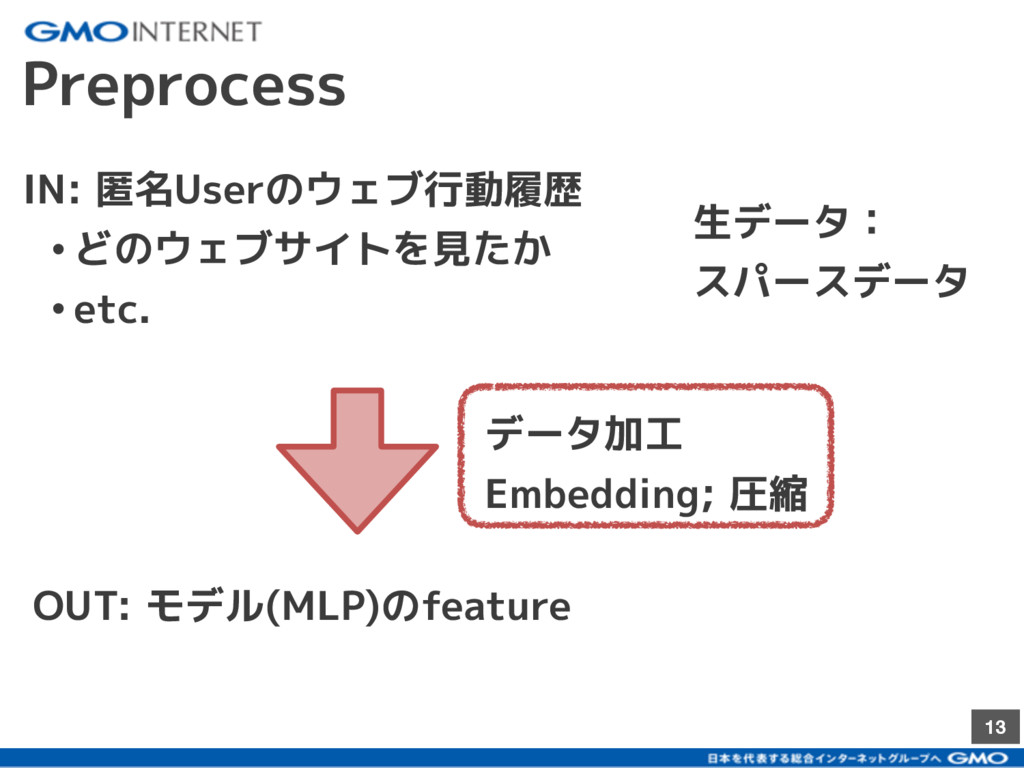{kind=link}
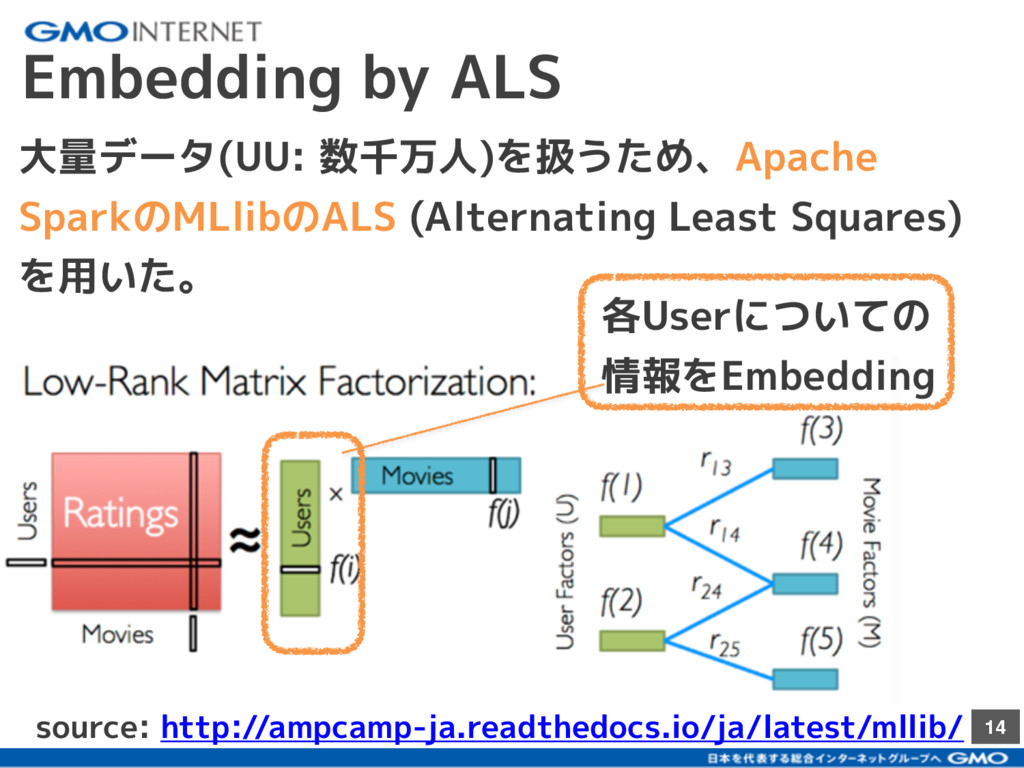{kind=link}
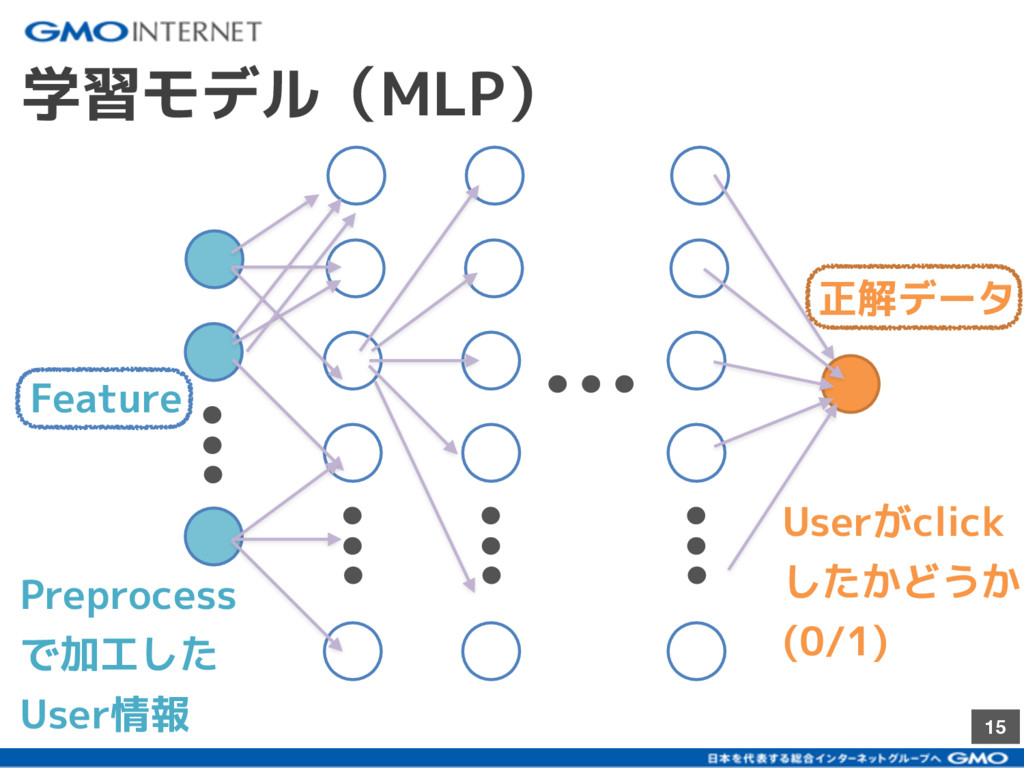{kind=link}
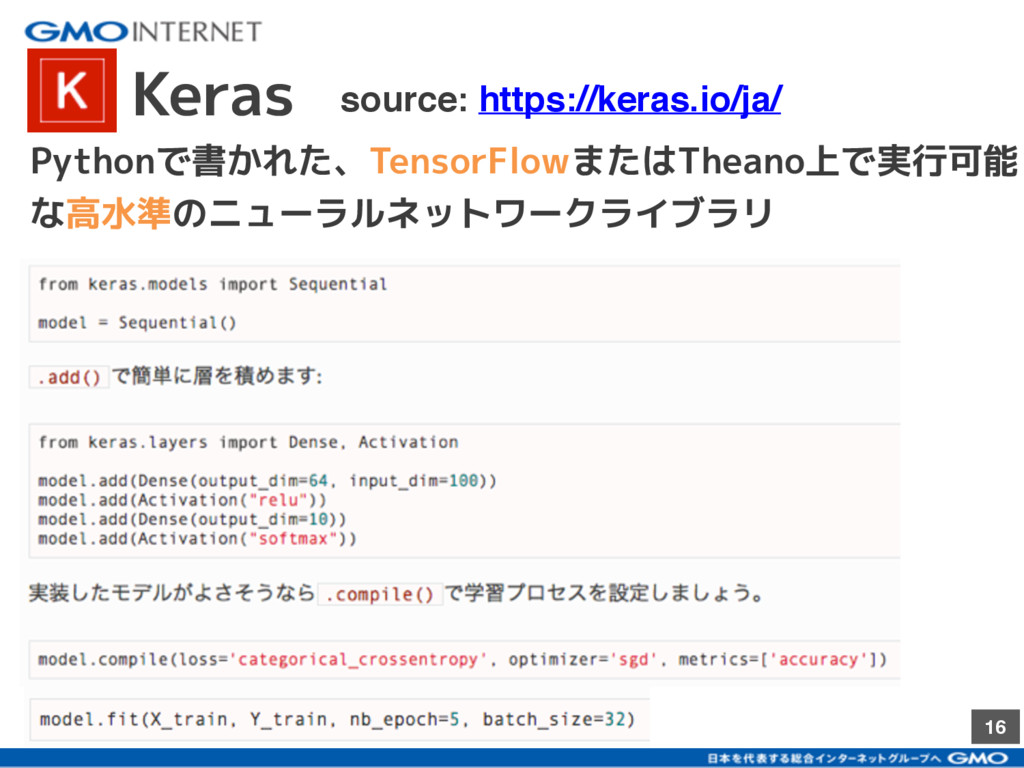{kind=link}
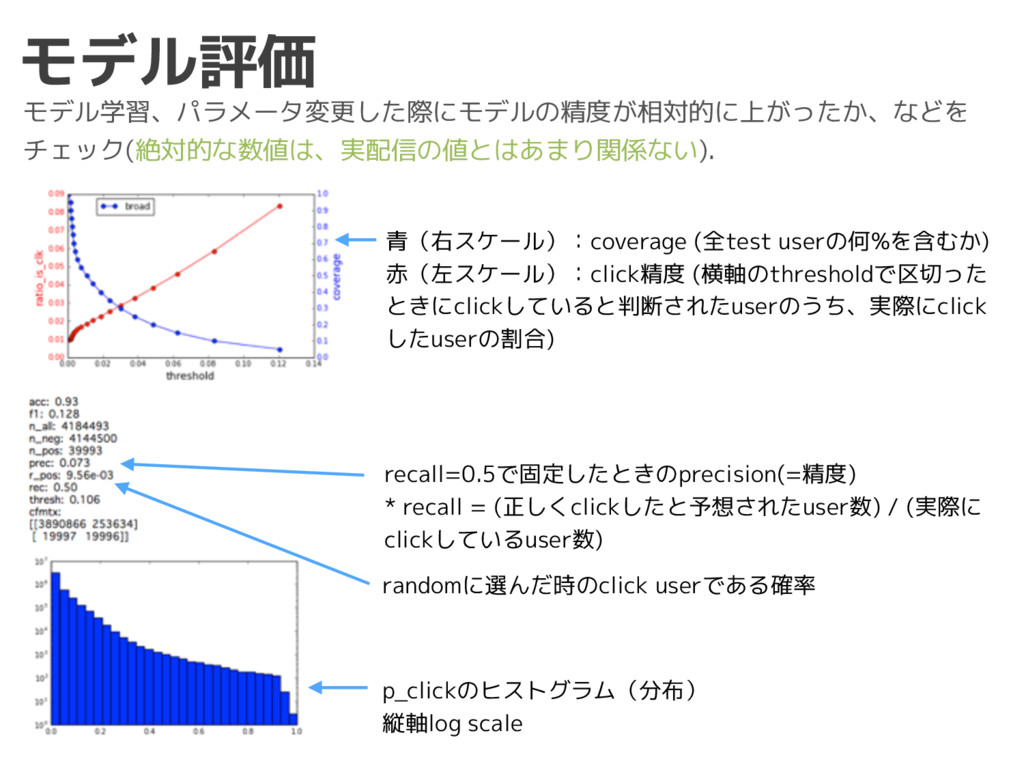{kind=link}
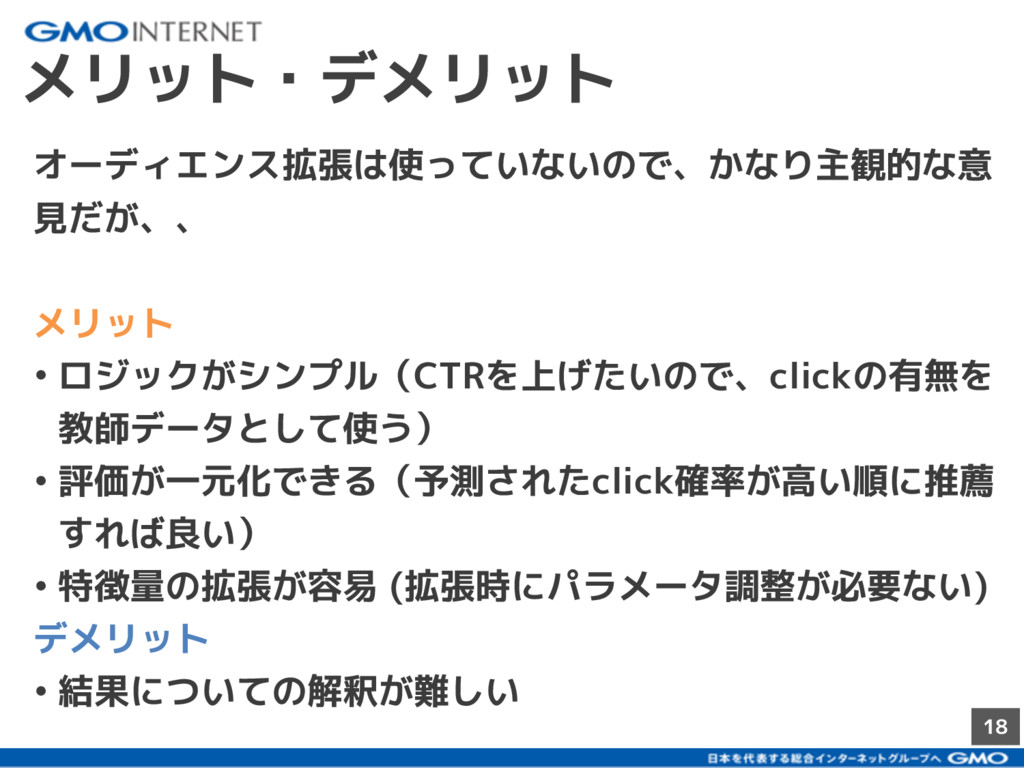{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}