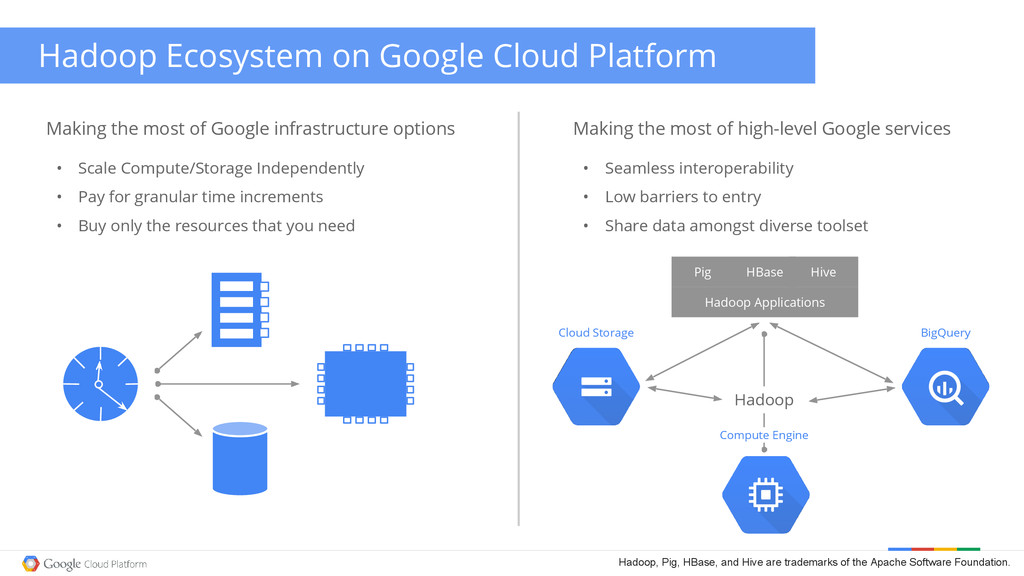
most of Google infrastructure options Cloud Storage Compute Engine Hive Hadoop Hadoop Ecosystem on Google Cloud Platform • Scale Compute/Storage Independently • Pay for granular time increments • Buy only the resources that you need • Seamless interoperability • Low barriers to entry • Share data amongst diverse toolset BigQuery Pig Hadoop Applications Hadoop, Pig, HBase, and Hive are trademarks of the Apache Software Foundation.
• Task coordination and execution Hadoop and the Big Data Ecosystem A Framework • De-facto standards around key primitives • Big Data beyond Hadoop/MapReduce Open Standardization
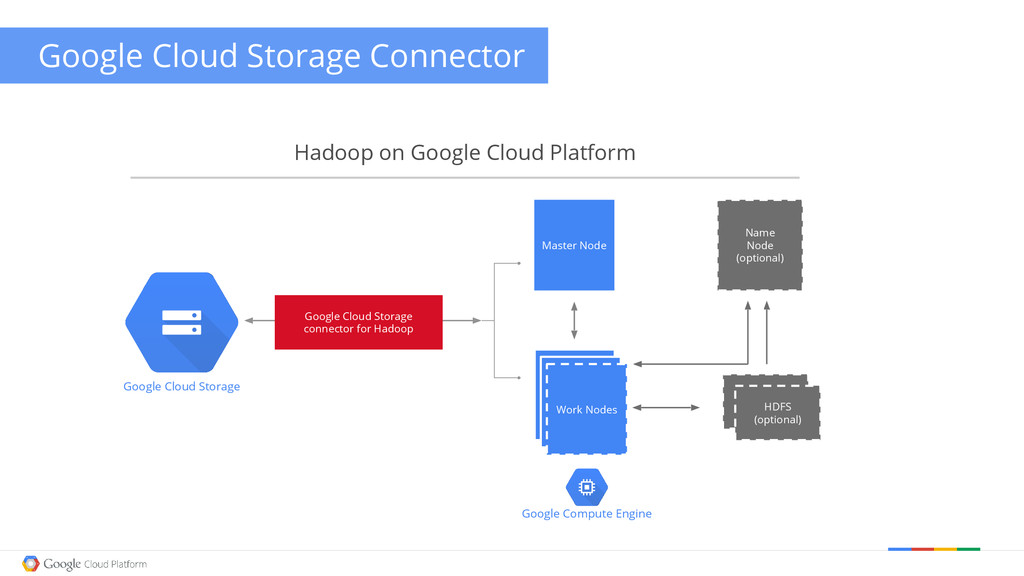
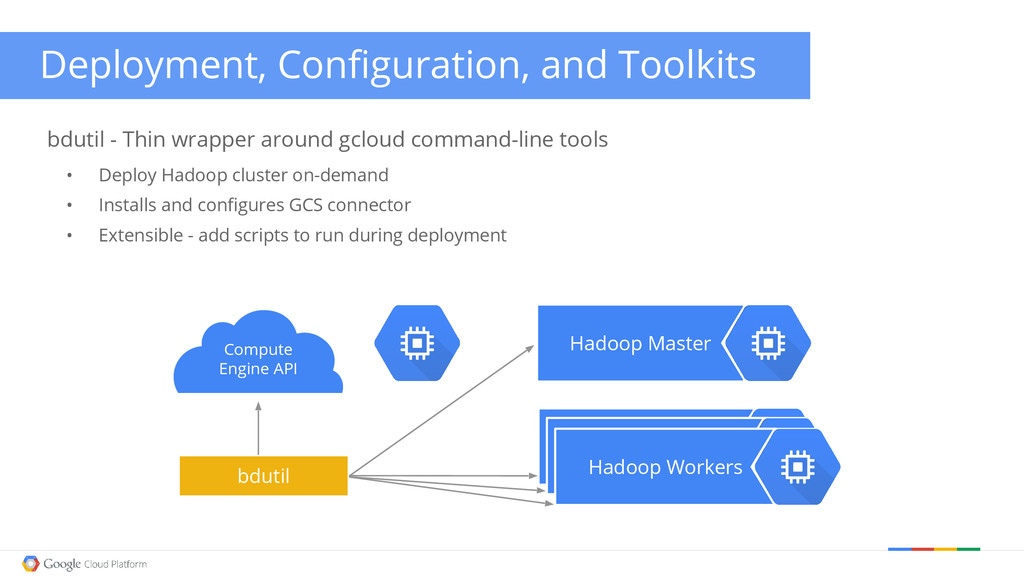
Cloud Storage Connector Google Cloud Storage connector for Hadoop Hadoop on Google Cloud Platform Master Node Work Nodes HDFS (optional) Name Node (optional) Google Cloud Storage
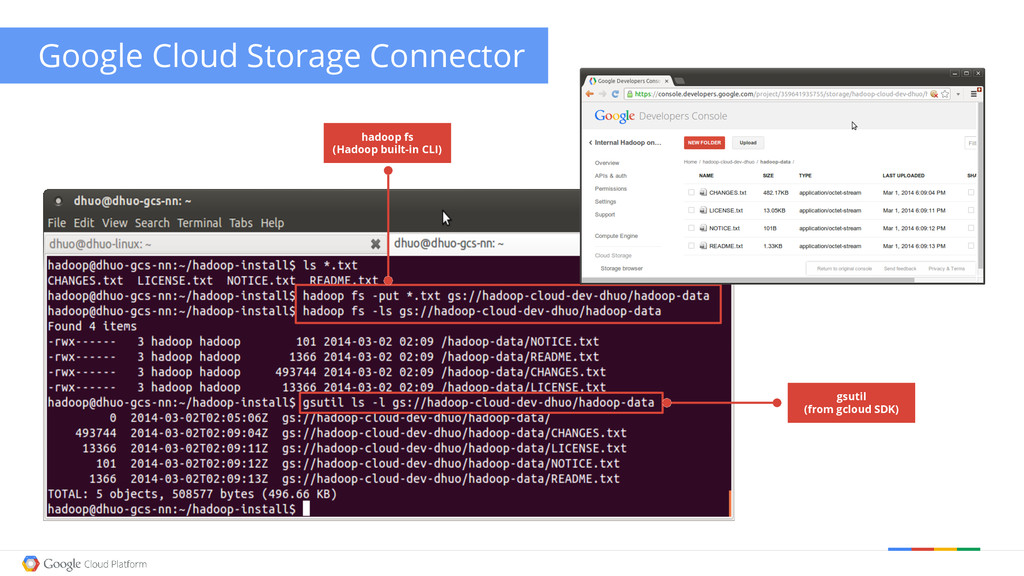
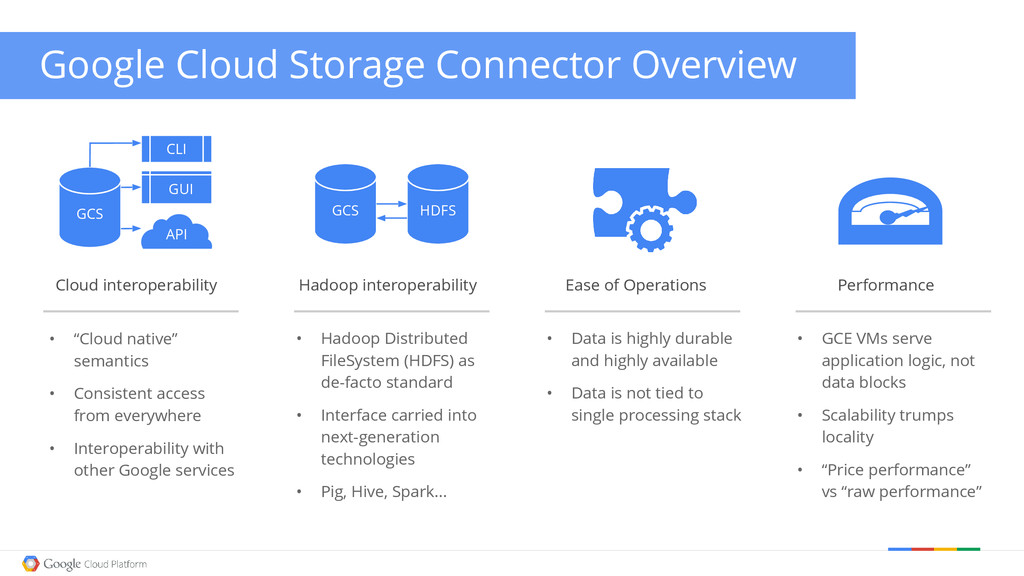
Storage Connector Overview • “Cloud native” semantics • Consistent access from everywhere • Interoperability with other Google services • Hadoop Distributed FileSystem (HDFS) as de-facto standard • Interface carried into next-generation technologies • Pig, Hive, Spark... • Data is highly durable and highly available • Data is not tied to single processing stack • GCE VMs serve application logic, not data blocks • Scalability trumps locality • “Price performance” vs “raw performance” GCS HDFS GCS GUI CLI API
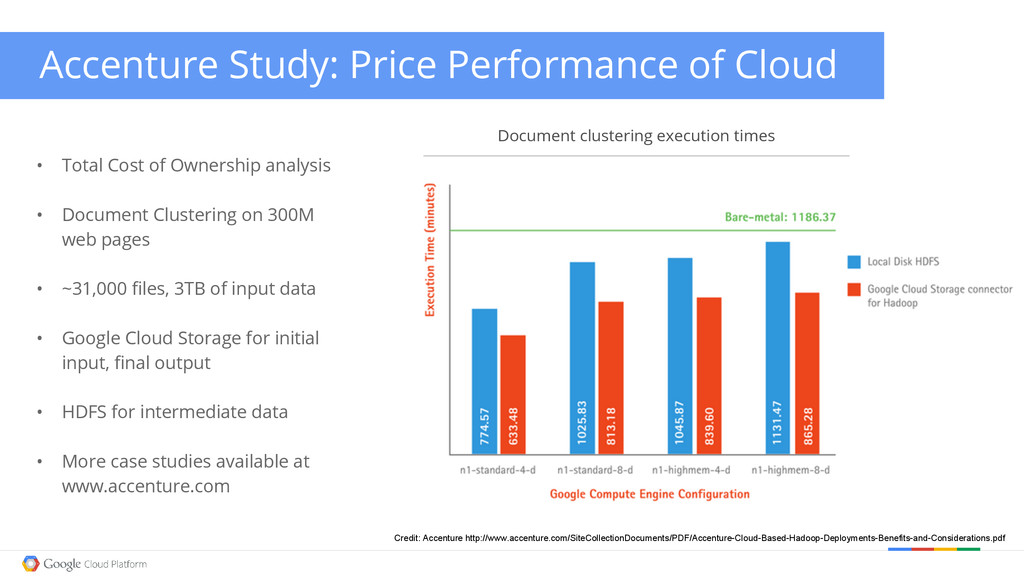
Total Cost of Ownership analysis • Document Clustering on 300M web pages • ~31,000 files, 3TB of input data • Google Cloud Storage for initial input, final output • HDFS for intermediate data • More case studies available at www.accenture.com Document clustering execution times
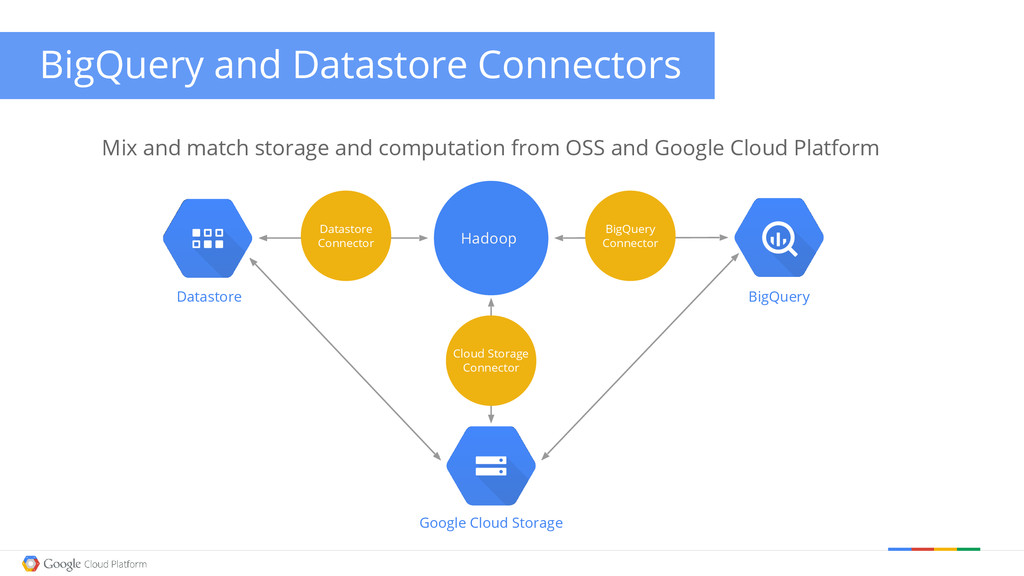
pieces of Open Source software • Shark: Hive on Spark • Hive: SQL on Hadoop • Spark: Next-Generation Data Processing on Hadoop data sources Pluggable into Google Cloud Platform • Inherits GCS Connector support • “External Tables” for seamless data portability • Hive metadata in Google CloudSQL for lifetime beyond cluster • Multi-tenancy via multiple personal Hive clusters
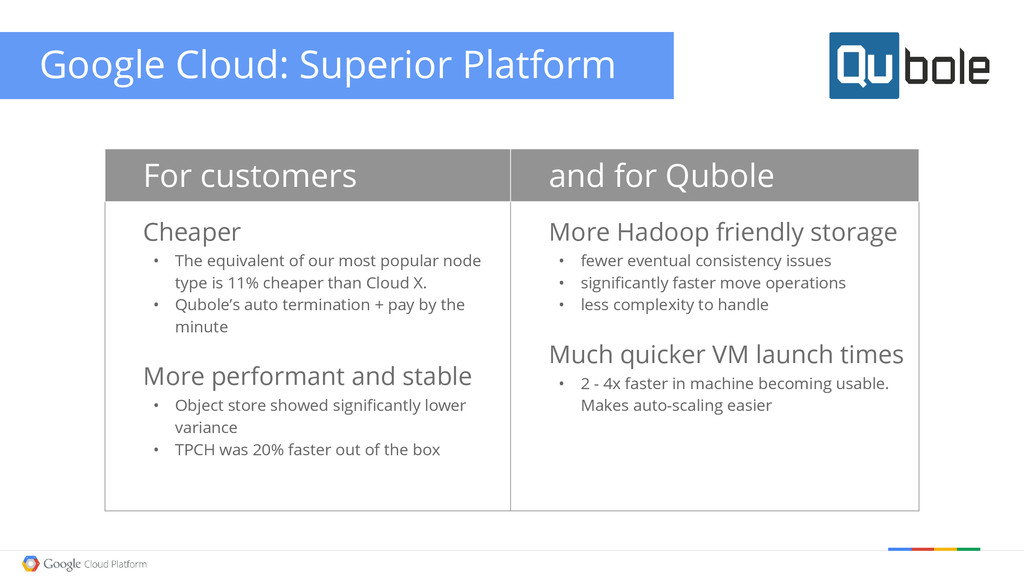
• The equivalent of our most popular node type is 11% cheaper than Cloud X. • Qubole’s auto termination + pay by the minute More performant and stable • Object store showed significantly lower variance • TPCH was 20% faster out of the box More Hadoop friendly storage • fewer eventual consistency issues • significantly faster move operations • less complexity to handle Much quicker VM launch times • 2 - 4x faster in machine becoming usable. Makes auto-scaling easier
on April 7th. Qubole integrates with GCS Qubole integrates with BigQuery Replace HDFS - Use as long term store and ephemeral Hadoop clusters Export to BQ - Allow processed data to be served up from a low latency query engine Extract from BQ - For joins during ETL processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}