Cloud TPUs by Zak Stone (Google I/O '18 video) Training Performance: A user’s guide to converge faster by Brennan Saeta (TensorFlow Dev Summit 2018 video) In-Datacenter Performance Analysis of a Tensor Processing Unit by Norm Jouppi et al. (paper) An in-depth look at Google’s first Tensor Processing Unit by Kaz Sato, Cliff Young and David Patterson (blog post) The future of computing by John Hennessy (Google I/O '18 video)
Architecture: A Quantitative Approach, 6/e. 2018 End of the Line? 2X / 20 yrs (3%/yr) RISC 2X / 1.5 yrs (52%/yr) CISC 2X / 3.5 yrs (22%/yr) End of Dennard Scaling ⇒ Multicore 2X / 3.5 yrs (23%/yr) Am- dahl’s Law ⇒ 2X / 6 yrs (12%/yr) End of Growth of Single Program Speed?
256K ops / cycle Up to 256M ops / instruction Operations per cycle CPU a few CPU (vector extension) tens GPU tens of thousands TPU hundreds of thousands, up to 256K
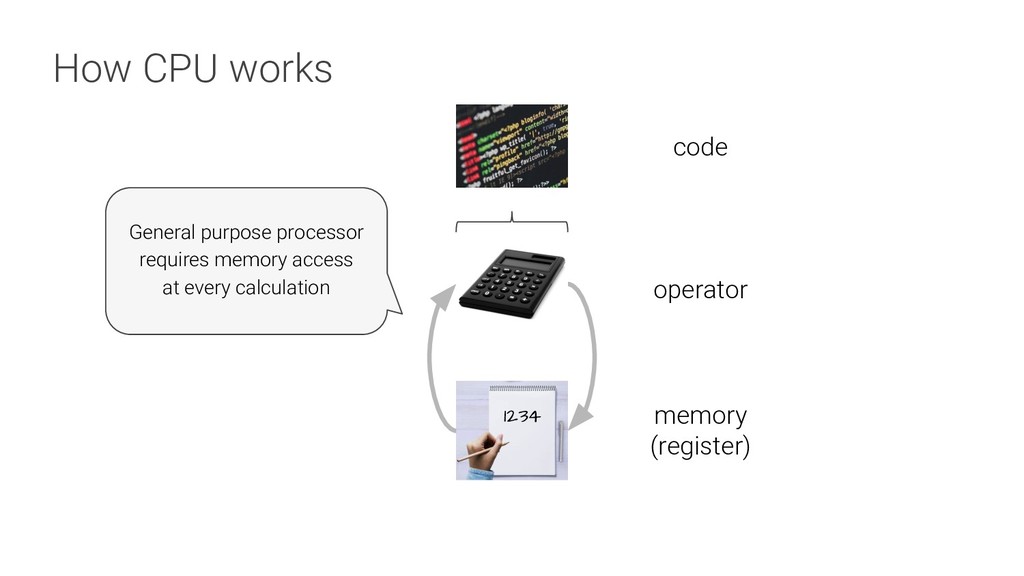
Read data from memory Read_Weights Read weights from memory MatrixMultiply/ Convolve Multiply or Convolve, Accumulate the results Activate Apply activation functions Write_Host_Memory Write result to memory
only 2% Removing all complexities: caching, branch prediction, OOO, multi-processing/threading, context switching etc Guaranteed latency: 7ms with high thruput
M M M M M M M M M M M M M M M M M M S E E E E E E E E Exponent: 8 bits Mantissa (Significand): 23 bits fp32: Single-precision IEEE Floating Point Format Range: ~1e−38 to ~3e38 S E E E E E M M M M M M M M M M Exponent: 5 bits Mantissa (Significand): 10 bits fp16: Half-precision IEEE Floating Point Format Range: ~5.96e−8 to 65504 Less bandwidth, Larger model, but shorter range
M M M M M M M M M M M M M S E E E E E E E E Exponent: 8 bits Mantissa (Significand): 23 bits fp32: Single-precision IEEE Floating Point Format Range: ~1e−38 to ~3e38 S E E E E E M M M M M M M M M M Exponent: 5 bits Mantissa (Significand): 10 bits fp16: Half-precision IEEE Floating Point Format Range: ~5.96e−8 to 65504 bfloat16: Brain Floating Point Format S E E E E E E E E Exponent: 8 bits Mantissa (Significand): 7 bits M M M M M M M Range: ~1e−38 to ~3e38 Supported by TPU Same range as fp32 Floating Point Formats in TPU
allowed us to focus on building our models without being distracted by the need to manage the complexity of cluster communication patterns. “ Alfred Spector, CTO, Two Sigma Anantha Kancherla, Head of Software, Self-Driving Level 5, Lyft Since working with Google Cloud TPUs, we’ve been extremely impressed with their speed—what could normally take days can now take hours.
Shards w’ = w - n Δ w w Δw Model Replicas Data Shards Δw Δw High speed interconnect PS with gRPC on TCP/IP by software on CPU → PS becomes the bottleneck, tedious distributed cluster mgmt All Reduce with 2-D toroidal mesh network by Google's HPC hardware → as easy as using a single node as scalable as supercomputers
Update Variable s Gradient s Loss Model Gradient s Loss Model Parameter Server Model Replicas Data Shards w’ = w - n Δ w w Δw Multi GPUs Distributed TensorFlow TPU
tons of matrix operations Large model with large batch size Can run with TPU supported ops Don't use Cloud TPU when: Sparse, small, high-precision, or many branches Can't run with TPU supported ops Eg. large CNN such as ResNet
you count Cloud TPUs? 1 Cloud TPU has 4 TPU processors and 8 cores. Total 64GB HBM and 180 TFLOPS. Can you use Cloud TPU for inference? Batch inference works on Cloud TPU. Online inference does not. TensorFlow Serving and ML Engine prediction does not work on Cloud TPU. Is Cloud TPU faster than GPU? Google hasn't published any comparison, but RiseML has a blog post comparing with NVIDIA V100. Any other way of using TPU than TPUEstimator? No. We strongly recommend to start with the reference models and then customise TPUEstimator. Does Colaboratory or Cloud Datalab support TPU? Stay tuned. Does Cloud ML Engine support TPU? Yes. Training with Cloud TPU is supported as beta.
analyze your ENTIRE TensorFlow pipeline including data ingestion and ETL to CPU, GPU, and TPU utilization and graph/operator optimization...These profiling tools are exactly what we've always from Spark-based ETL pipelines, but we've never seen them on the market - not at this level of system detail and optimization." https://www.meetup.com/Advanced-Spark-and-TensorFlow-Meetup/events/23 3979387/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[ https://dawn.cs.stanford.edu/benchmark/ ]](https://files.speakerdeck.com/presentations/8648f1d4e2ec4e53aa2e1b28c98eb215/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}