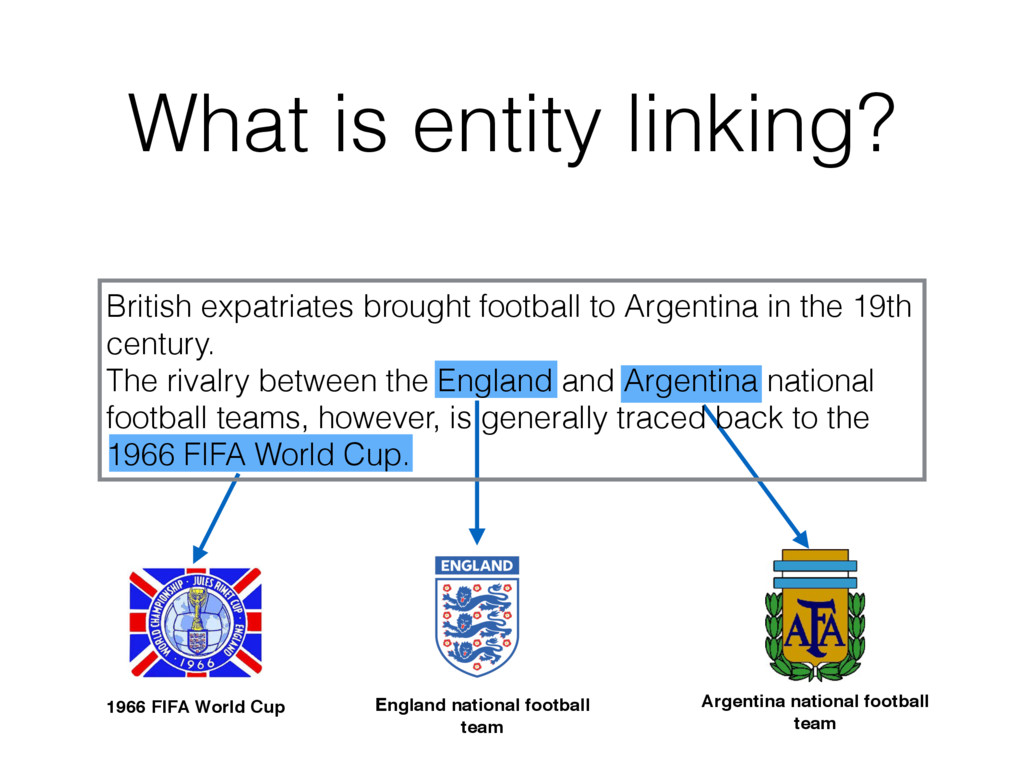
football team What is entity linking? British expatriates brought football to Argentina in the 19th century. The rivalry between the England and Argentina national football teams, however, is generally traced back to the 1966 FIFA World Cup.
Text: any piece of text • documents (news, blog post, etc.) • tweets • queries • …. • Entities: typically taken from a knowledge graph • Wikipedia • DBpedia • Freebase • …
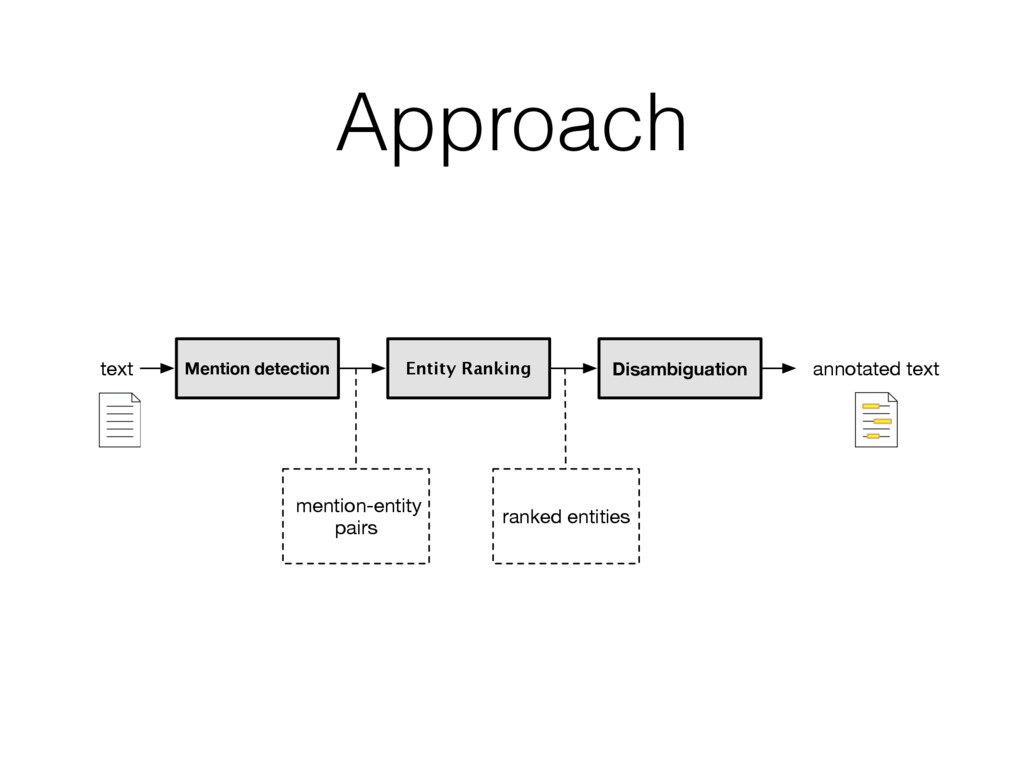
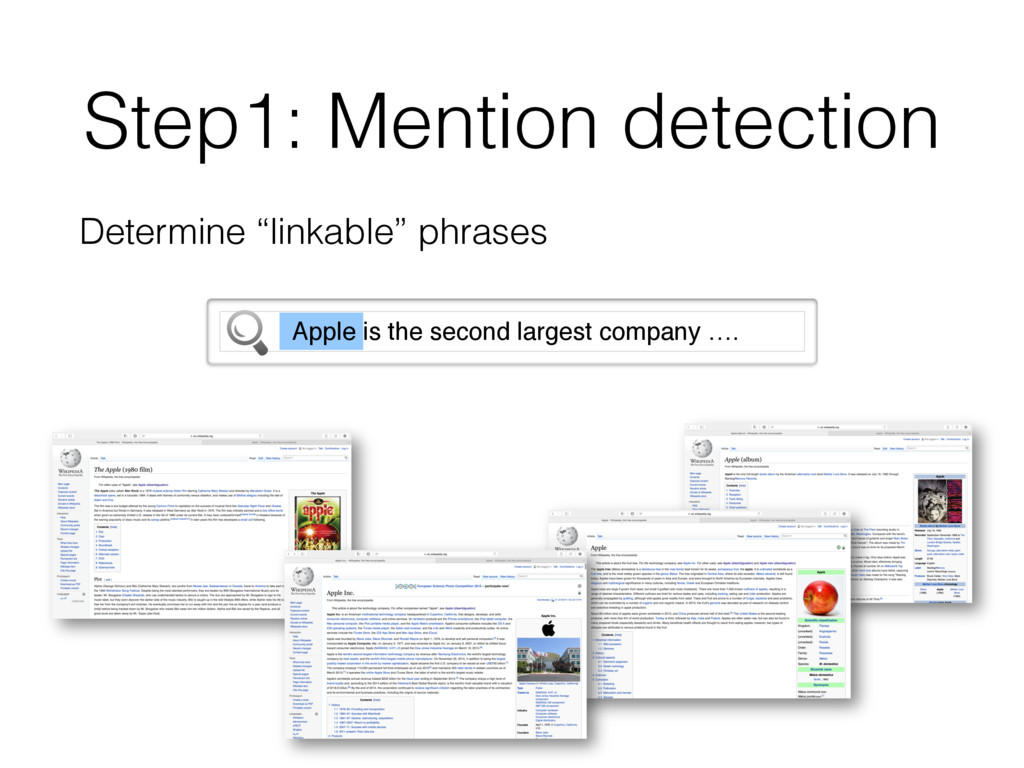
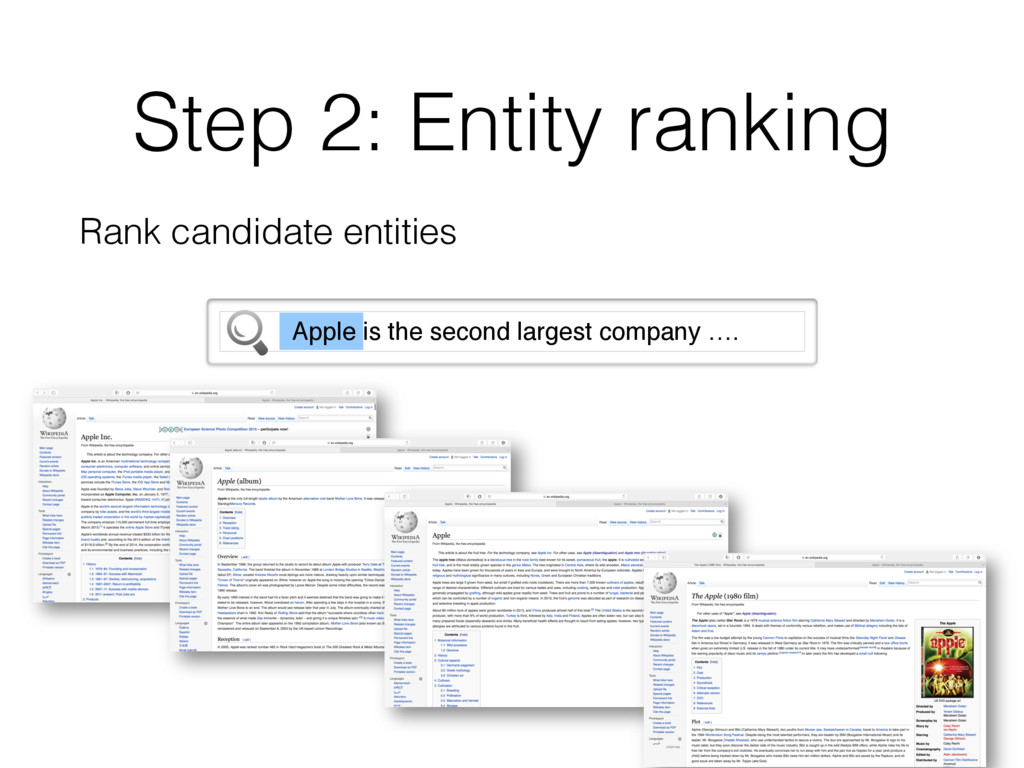
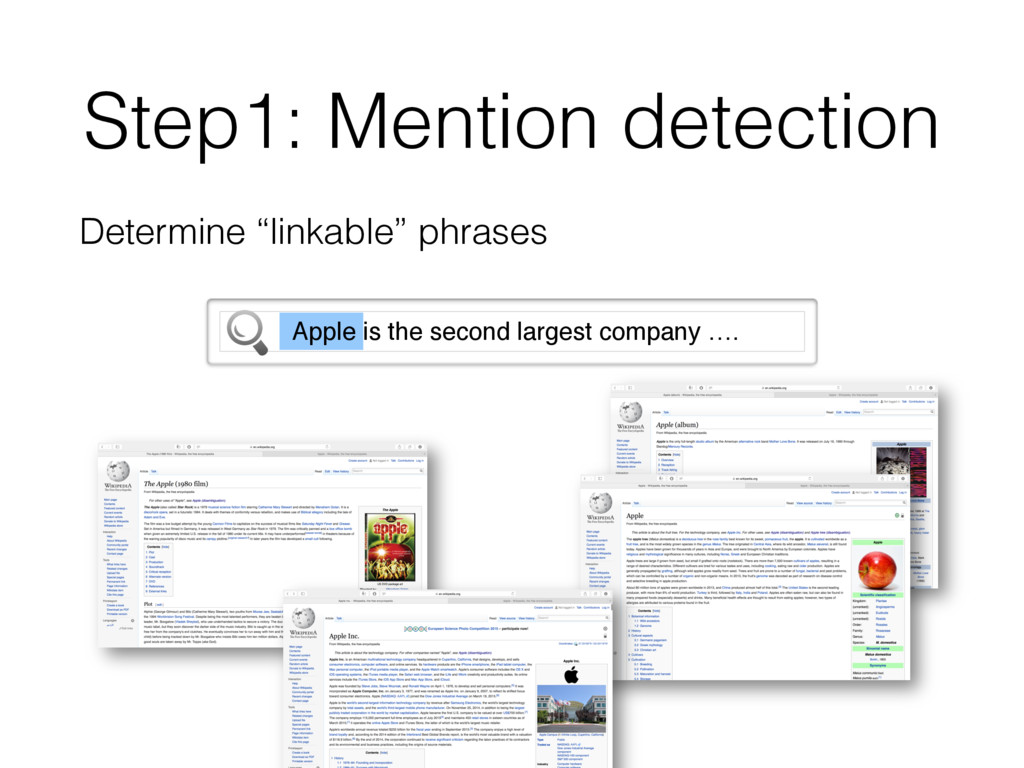
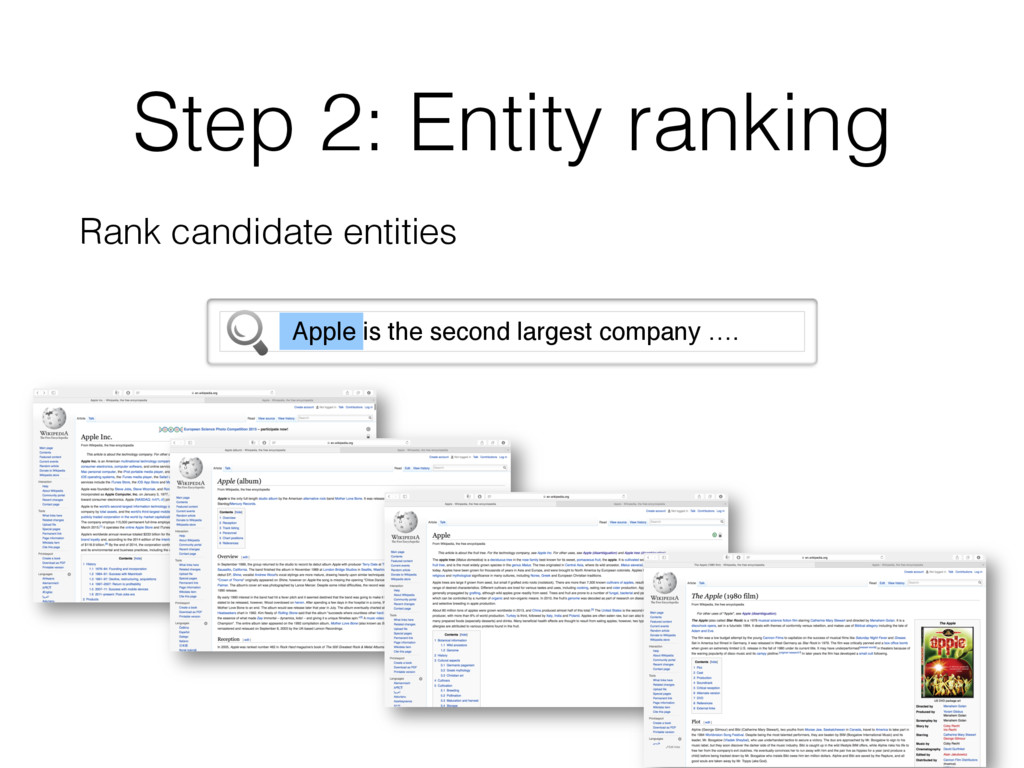
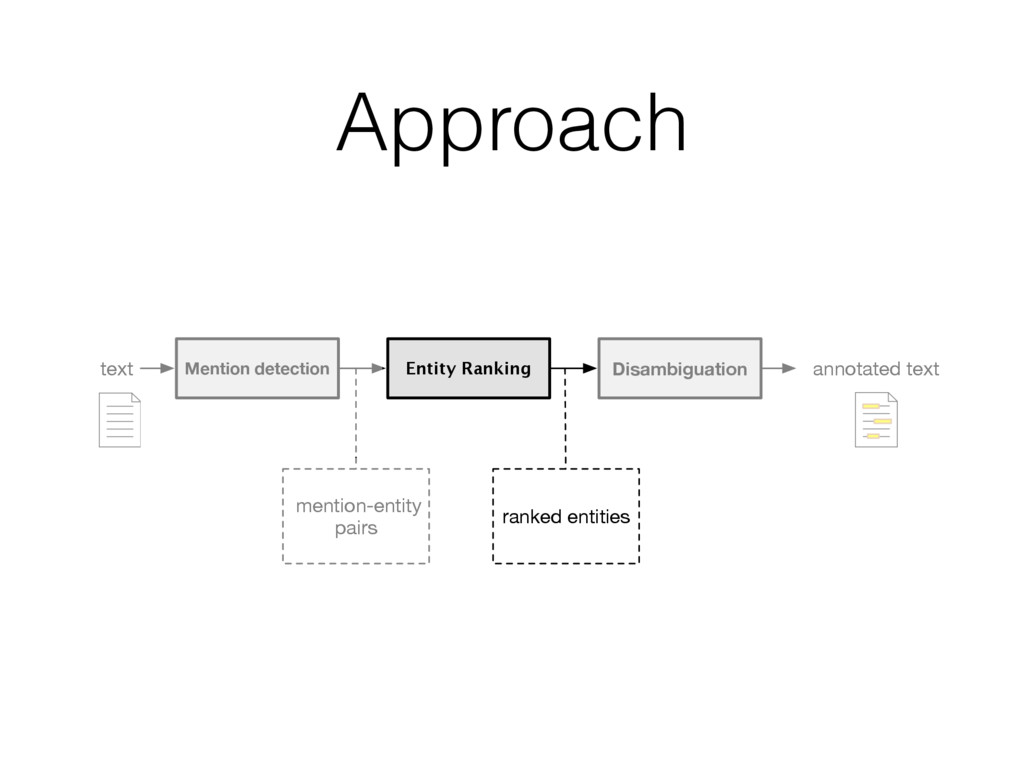
entity that should be linked • Find entity name variants • E.g. “jlo” is name variant of [Jennifer Lopez] • Filter out inappropriate ones • E.g. “new york” matches >2k different entities; all are not interesting Detecting all “linkable phrases” (mentions) of the text, with their corresponding entities.
• contains a mapping from entity name variants to entities 2. Find all document n-grams (substrings) against the dictionary • The length of n-gram is typically between 6 and 8 3. Filter out undesired entities
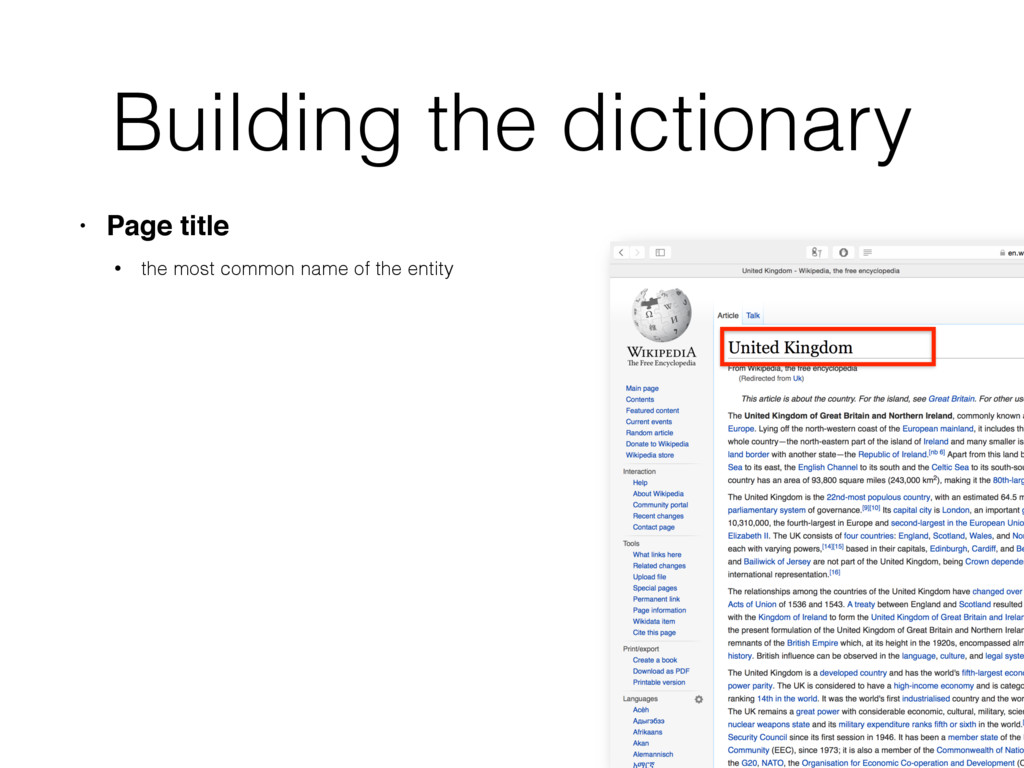
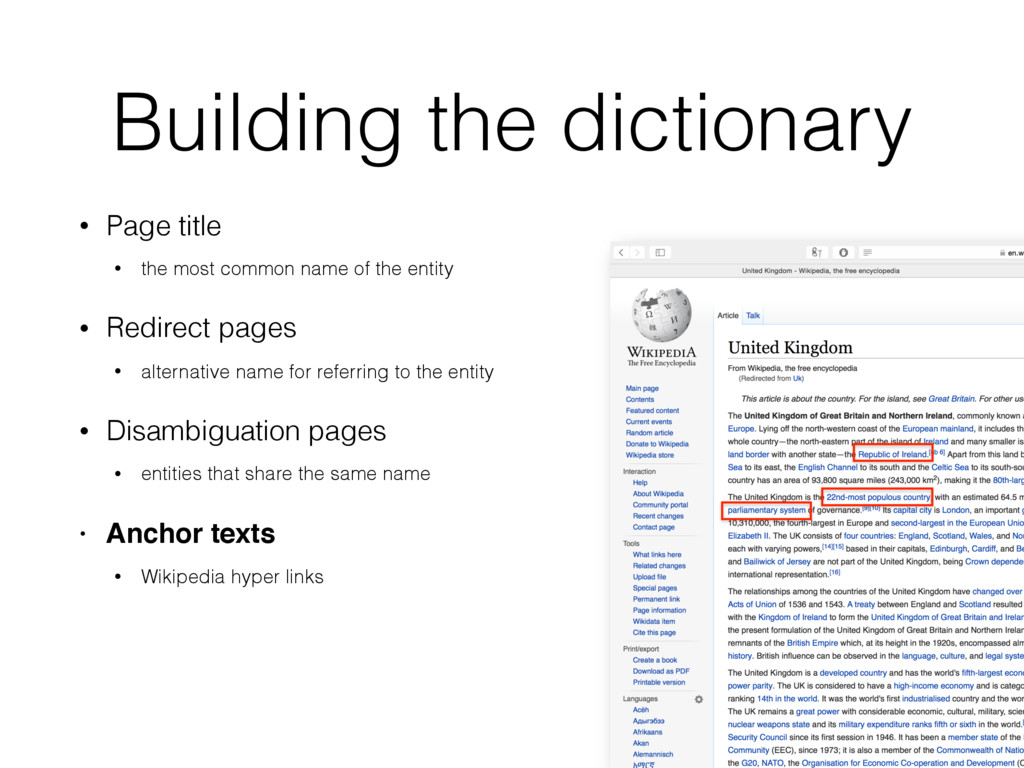
name of the entity • Redirect pages • alternative name for referring to the entity • Disambiguation pages • entities that share the same name • Anchor texts • Wikipedia hyper links • Bold texts from the first paragraph • denotes other name variants of the entity
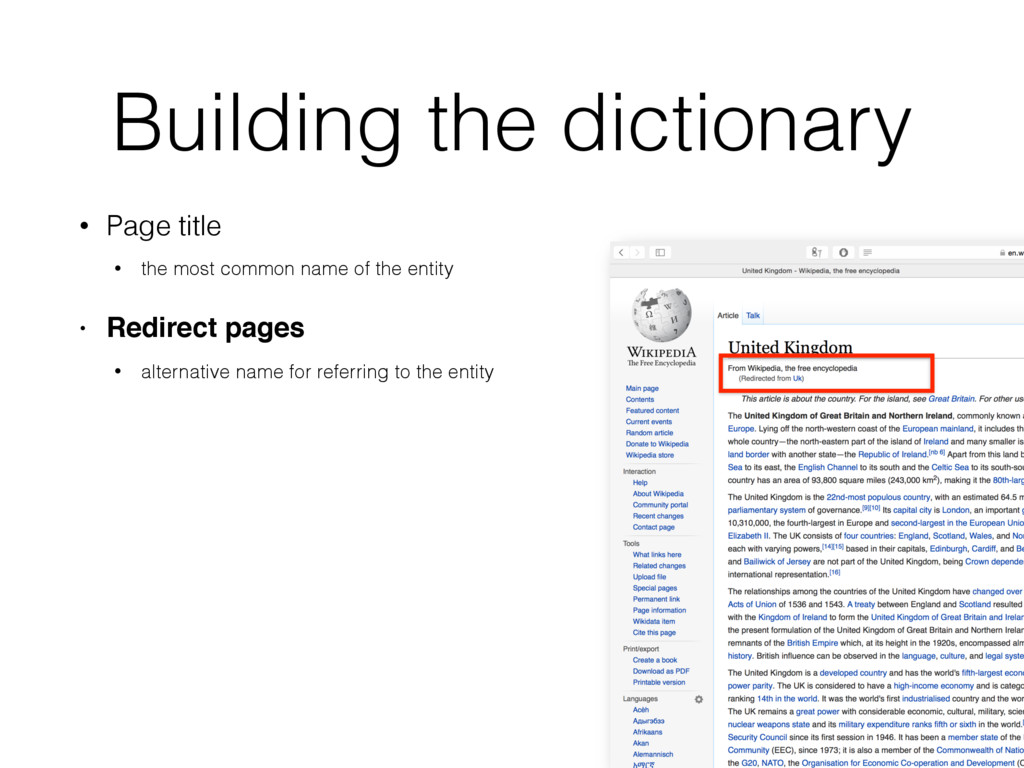
name of the entity • Redirect pages • alternative name for referring to the entity • Disambiguation pages • entities that share the same name • Anchor texts • Wikipedia hyper links • Bold texts from the first paragraph • denotes other name variants of the entity
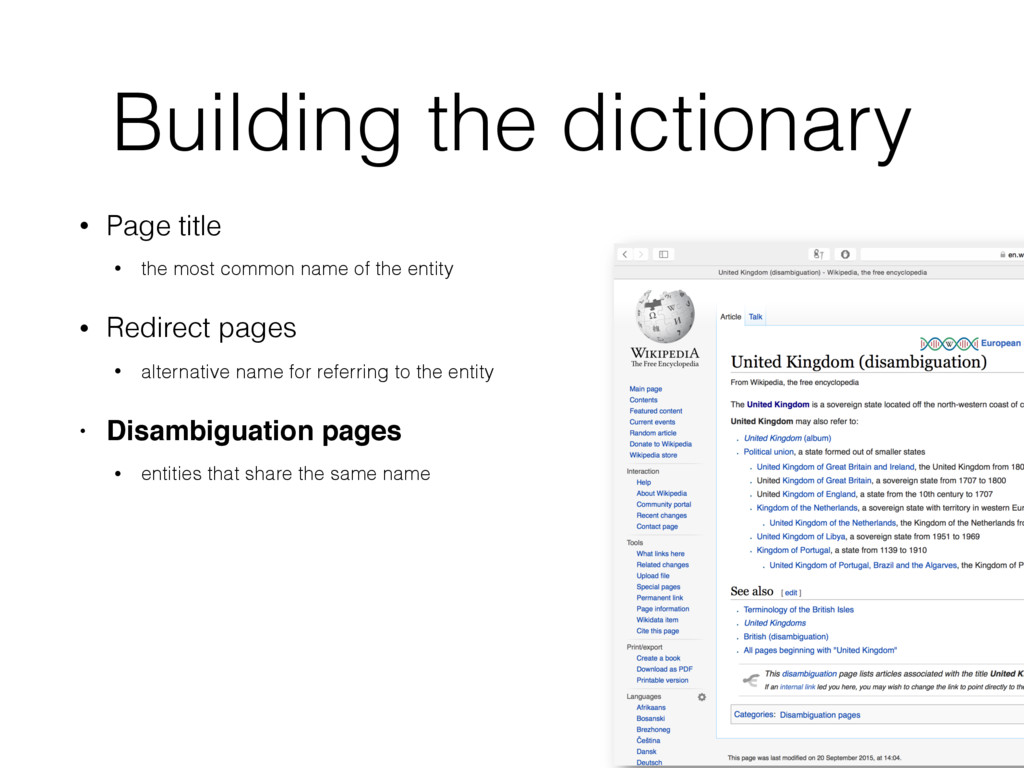
name of the entity • Redirect pages • alternative name for referring to the entity • Disambiguation pages • entities that share the same name • Anchor texts • Wikipedia hyper links • Bold texts from the first paragraph • denotes other name variants of the entity
name of the entity • Redirect pages • alternative name for referring to the entity • Disambiguation pages • entities that share the same name • Anchor texts • Wikipedia hyper links • Bold texts from the first paragraph • denotes other name variants of the entity
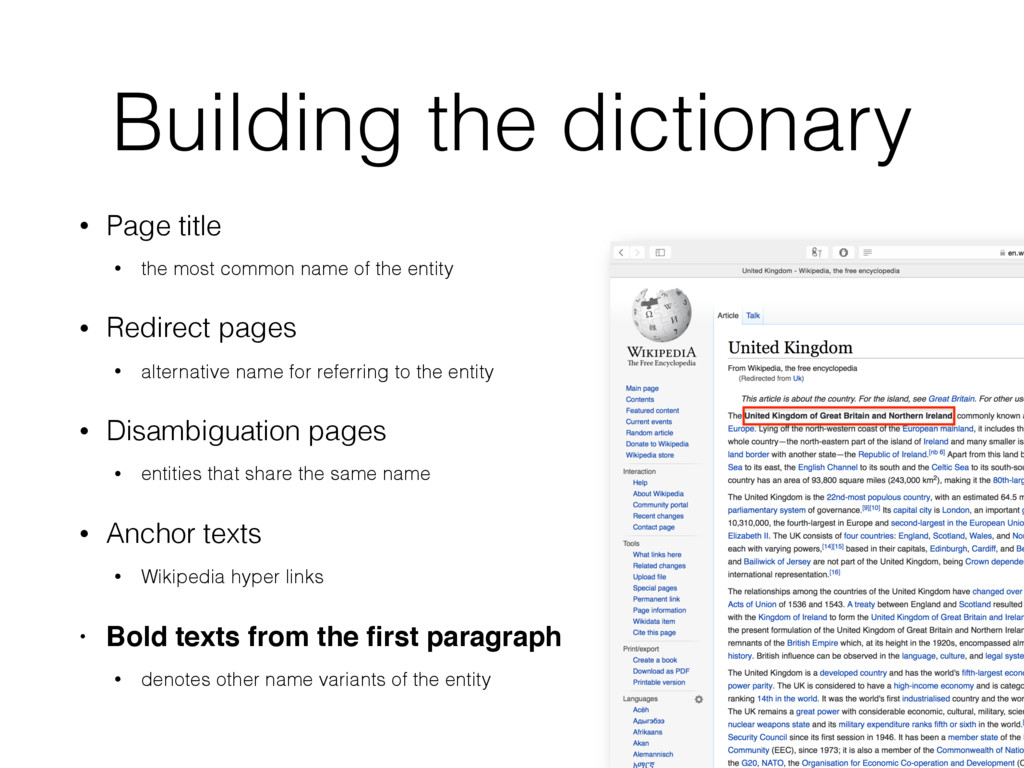
name of the entity • Redirect pages • alternative name for referring to the entity • Disambiguation pages • entities that share the same name • Anchor texts • Wikipedia hyper links • Bold texts from the first paragraph • denotes other name variants of the entity
• A mention can be associated to too many entities • esp. the very commons names (e.g. ‘new york’, ‘us’) • Some mentions are unlikely to be linked any entity • ‘the’ -> [The The] • ‘b’ -> [B (I Am Kloot album)]
• Probability of the entity measured in terms of incoming links • Page views • Probability of the entity measured in terms of traffic volume Neither the text nor other mentions in the document are taken into account
of text (sentence, paragraph) around the mention • Entire document • Similarity function • Cosine similarity Compare the surrounding context of a mention with the textual representation of the entity
at most a few topics • Entities mentioned in a document should be topically related to each other • Relatedness can be captured between two entities Captures coherence between entity linking decisions in the text
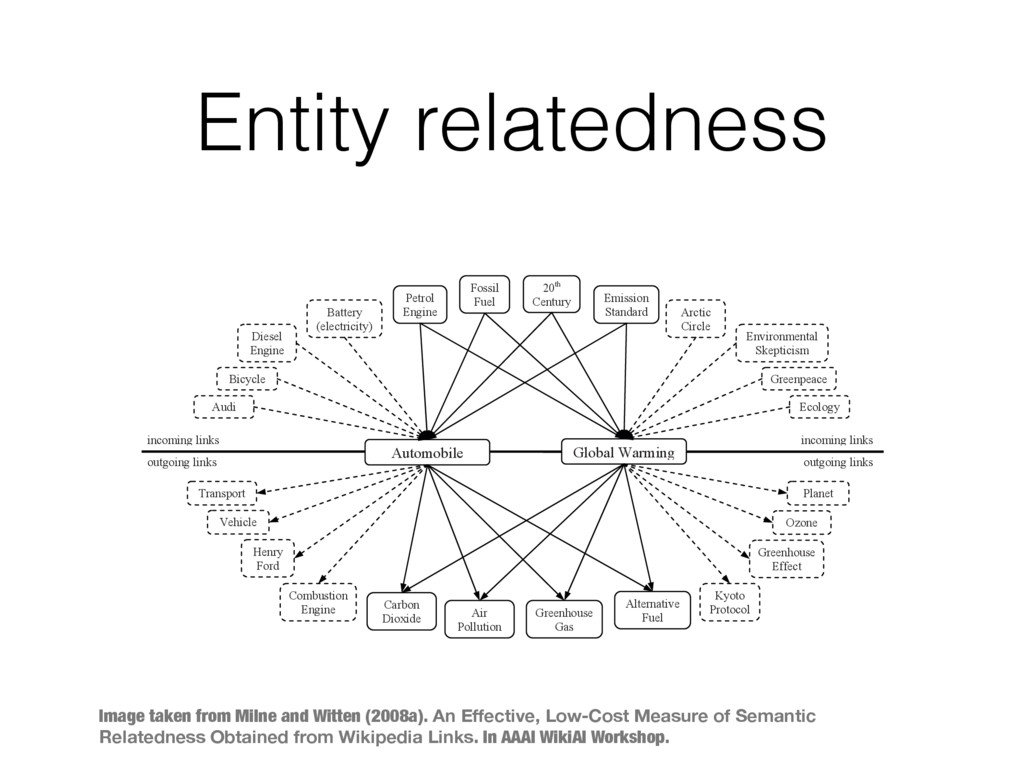
category structure. While the results are similar in terms of accuracy to thesaurus based techniques, the collaborative nature of Wikipedia offers a much larger—and constantly evolving—vocabulary. Gabrilovich and Markovitch (2007) achieve extremely accurate results with ESA, a technique that is somewhat reminiscent of the vector space model widely used in information retrieval. Instead of comparing vectors of term weights to evaluate the similarity between queries and documents, they compare weighted vectors of the Wikipedia articles related to each term. The name of the approach—Explicit Semantic Analysis—stems from the way these vectors are comprised of manually defined because Wikipedia’s extensive textual content can largely be ignored, and more accurate, because it is more closely tied to the manually defined semantics of the resource. Wikipedia’s extensive network of cross-references, portals, categories and info-boxes provide a huge amount of explicitly defined semantics. Despite the name, Explicit Semantic Analysis takes advantage of only one property: the way in which Wikipedia’s text is segmented into individual topics. It’s central component—the weight between a term and an article—is automatically derived rather than explicitly specified. In contrast, the central component of our approach is the link: a manually-defined connection between two manually disambiguated concepts. Wikipedia provides millions of these connections, as Global Warming Automobile Petrol Engine Fossil Fuel 20th Century Emission Standard Bicycle Diesel Engine Carbon Dioxide Air Pollution Greenhouse Gas Alternative Fuel Transport Vehicle Henry Ford Combustion Engine Kyoto Protocol Ozone Greenhouse Effect Planet Audi Battery (electricity) Arctic Circle Environmental Skepticism Greenpeace Ecology incoming links outgoing links Figure 1: Obtaining a semantic relatedness measure between Automobile and Global Warming from Wikipedia links. incoming links outgoing links 26 Image taken from Milne and Witten (2008a). An Effective, Low-Cost Measure of Semantic Relatedness Obtained from Wikipedia Links. In AAAI WikiAI Workshop.
that contains all mention nodes and exactly one mention-entity edge for each mention • Greedy algorithm iteratively removes edges • The graph with the highest density is kept as the solution
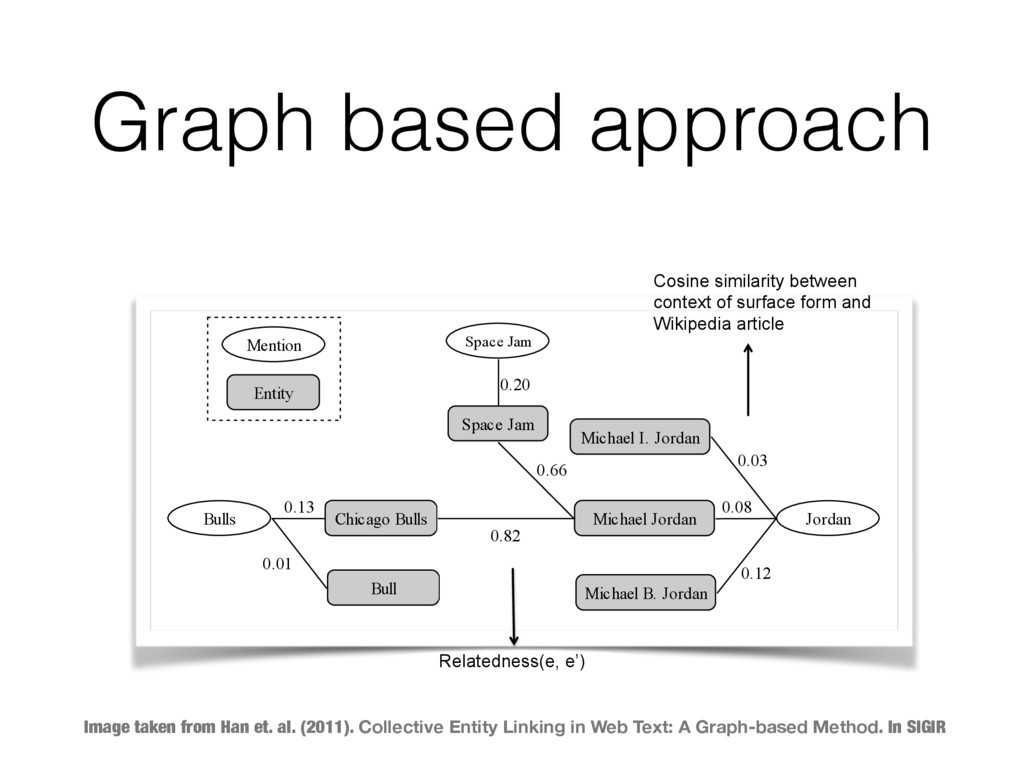
G=(V, E), where the node set V contains all name mentions in a document and all the possible referent entities of these name mentions, with each node representing a name mention or an entity; each edge between a name mention and an entity represents a Compatible relation between them; each edge between two entities represents a Semantic-Related relation between them. For illustration, Figure 2 shows the Referent Graph representation of the EL problem in Example 1. Space Jam Chicago Bulls Bull Michael Jordan Michael I. Jordan Michael B. Jordan Space Jam Bulls Jordan Mention Entity 0.66 0.82 0.13 0.01 0.20 0.12 0.03 0.08 Figure 2. The Referent Graph of Example 1 By representing both the local mention-to-entity compatibility and the global entity relation as edges, two types of dependencies are captured in Referent Graph: M o m 2) C c i W e t 3) N t C r p R t 4. C In this which mentio repres Compa Cosine similarity between context of surface form and Wikipedia article Relatedness(e, e’) Image taken from Han et. al. (2011). Collective Entity Linking in Web Text: A Graph-based Method. In SIGIR
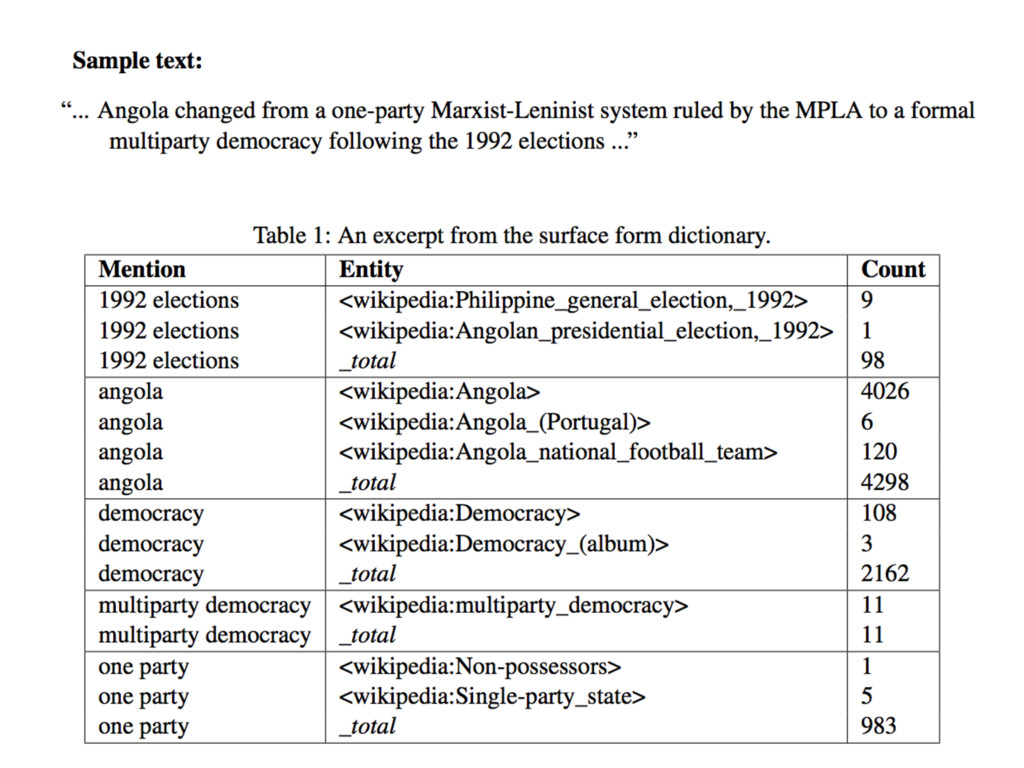
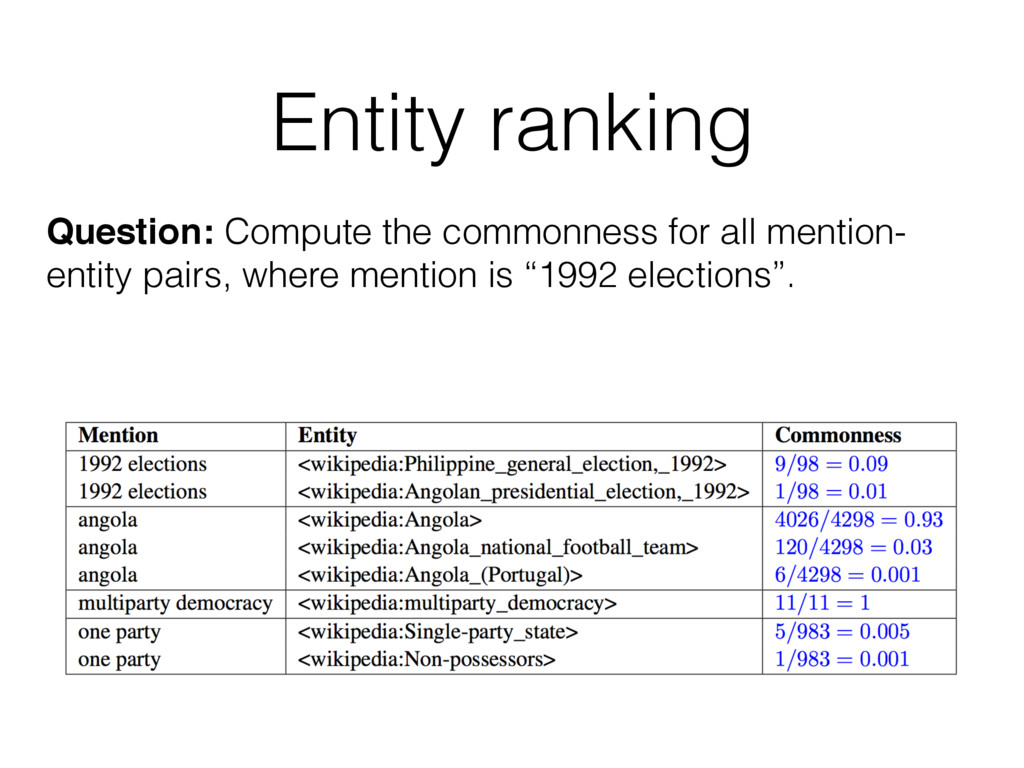
of the mention detection step for the given sample text? All mention-entity pairs of Table 1 are considered, except the ones related to the mention “democracy“. We ignore this mention, because the longer mention “multiparty democracy“ is considered. Answer:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}