Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scaling Laws for NL Models
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Keio Computer Society
November 10, 2021
62
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scaling Laws for NL Models
Keio Computer Society
November 10, 2021
More Decks by Keio Computer Society
See All by Keio Computer Society
20211208.pdf
kcs
0
22
自然言語処理~Primer
kcs
0
110
Residual Network.pdf
kcs
0
160
Graph Neural Network
kcs
0
35
Kaggle上位者解法紹介.pdf
kcs
0
50
音声合成の精度比較.pdf
kcs
0
190
ブロックチェーンによる自律AIのための遺伝的アルゴリズムの検討
kcs
0
40
Featured
See All Featured
Faster Mobile Websites
deanohume
310
32k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Six Lessons from altMBA
skipperchong
29
4.3k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Exploring anti-patterns in Rails
aemeredith
3
430
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
Git: the NoSQL Database
bkeepers
PRO
432
67k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Are puppies a ranking factor?
jonoalderson
1
3.7k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Thoughts on Productivity
jonyablonski
76
5.2k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Transcript
Scaling Laws for Neural Language Models KCS 音楽班3年 4LDK https://arxiv.org/abs/2001.08361
instruction ・大多数の推論タスクは言語で効率的に表現され、評価される ・世界中のテキストを教師なし学習のための豊富なデータとして使える ・深層学習は最近、言語モデリングにおいて急速な進歩を遂げており、最先端 のモデルは、辻褄の合った複数段落のテキストサンプルの構築など、多くの特 定のタスク(SuperGLUE)において人間レベルの性能に近づいてきている
調べた項目 言語モデルにおいて損失が以下のそれぞれにどれくらい依存するかを調べた 1. モデルのアーキテクチャ 2. ニューラルモデルのサイズ 3. 計算量 4. 学習に利用できるデータ
5. 文章の長さ
表記 L : クロスエントロピーの損失 N:embedding以外のパラメータ数 B:バッチサイズ S:ステップ数 C:embedding以外の計算量=6NBS D:データセットのサイズ(tokenの数) αX:べき乗則にでてくる定数 Bcrit:最適なバッチサイズ。時間と計算効率によって決まる。 Cmin:ある損失値に到達するための最小のCの推定値。Bcritよりもはるかに小さいバッチサイ
ズで学習した場合に使用される計算量 Smin:ある損失値に到達するために必要な最小のSの推定値。Bcritよりも遥かに大きいバッチ サイズで学習した場合に使用されるステップ数
使用したデータセットやモデル データセット:WebText2 (テストでその他いくつかのデータセットを利用) Tokenizer:byte-pair encoding 損失関数:クロスエントロピー 平均1024トークン以上ある文章を使った。 基本的にはTransformer Decoderを使ったが、比較のためにLSTMや Universal
Transformer(R-Transformer)でも学習した
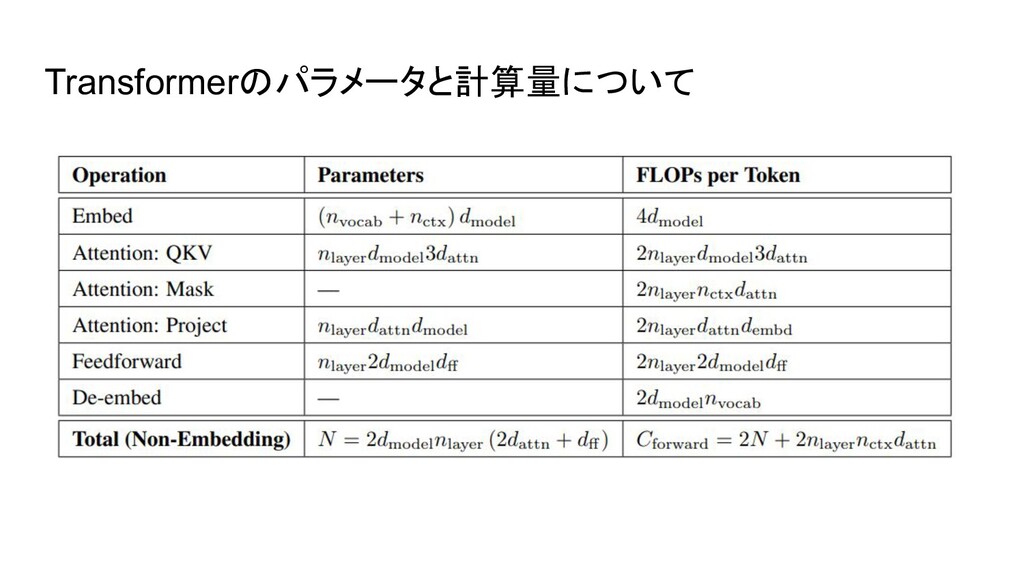
Transformerのパラメータと計算量について 表記 n_layer:レイヤー数 d_model:Embeddingの次元 d_ff:Feed Forward層の次元 d_attn:attentionの出力次元 n_heads:attentionのhead数 n_ctx:一度に入力する文章のトークン数。基本的1024
Transformerのパラメータと計算量について あ でNが計算できる。バイアスを除いている / Embeddingパラメータは入れないほうが綺 麗なスケーリング則になったので除いている。 で順伝播の計算量が求まるが、2項目はd_modelがn_ctxより十分大きい場合無視でき るため、第1項のみを使う。また、逆伝播では順伝播の2倍計算するので合計して1バッ チ1ステップあたりの計算量は6Nになる
Transformerのパラメータと計算量について
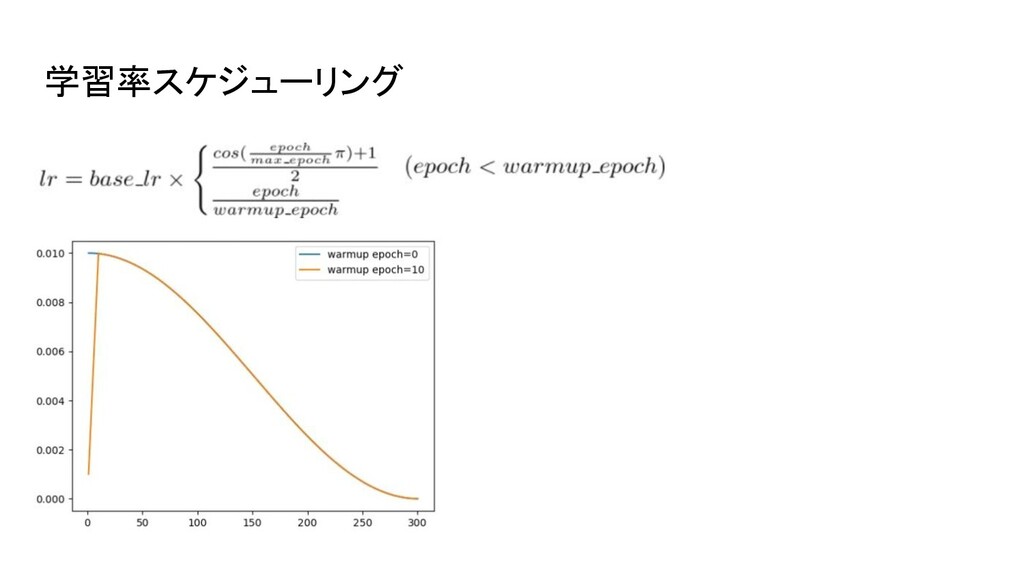
訓練方法 基本的に、adam, batchサイズ512, ステップ数2.5*10^5 メモリの制約で最大のモデルはAdafactor laearning late/学習率スケジューリングは様々な値を使った。 収束したあとの損失はスケジューリングとはほとんど依存していない 基本的に、3000epochまで線形で増加→そこからコサイン減衰
学習率スケジューリング
データセット WebText2を使っている。 newspaper3kでRedditの中でkarmaが3以上の投稿を収集した。 合計で20.3M個の文章、96GBのテキスト、1.62*10^10単語(wcにより定義?) OpenAIの作ったTokenizer”Language Models are Unsupervised Multitask Learners”で2.29*10^10トークンになった。
このうち6.6 * 10^8トークンをテストに使用して、Books Corpus、Common Crawl, 英語 版Wikipedia, 著作権フリーのネット上の本もテストに利用した。
abstruct ・損失は, 1.モデルのサイズ 2. データセットのサイズ 3. 計算量 に応じてべき乗則的に変化し,その傾向は7桁以上に及ぶものもある. ・ネットワークの幅や深さなど、その他のアーキテクチャの詳細は、広い範囲で最小限の 影響しかない
abstruct 1.過学習のモデル/データセットサイズへの依存性 2.学習速度のモデルサイズへの依存性 これら2つは単純な方程式で表される. この方程式より限られた計算資源の最適な割り当てを決定することができる。 →大きなモデルはサンプル効率が非常に高い 最適な計算効率を得るためには、比較的「少量のデータ」で非常に「大きなモデル」を学 習し、「収束のかなり手前」で停止する必要がある。
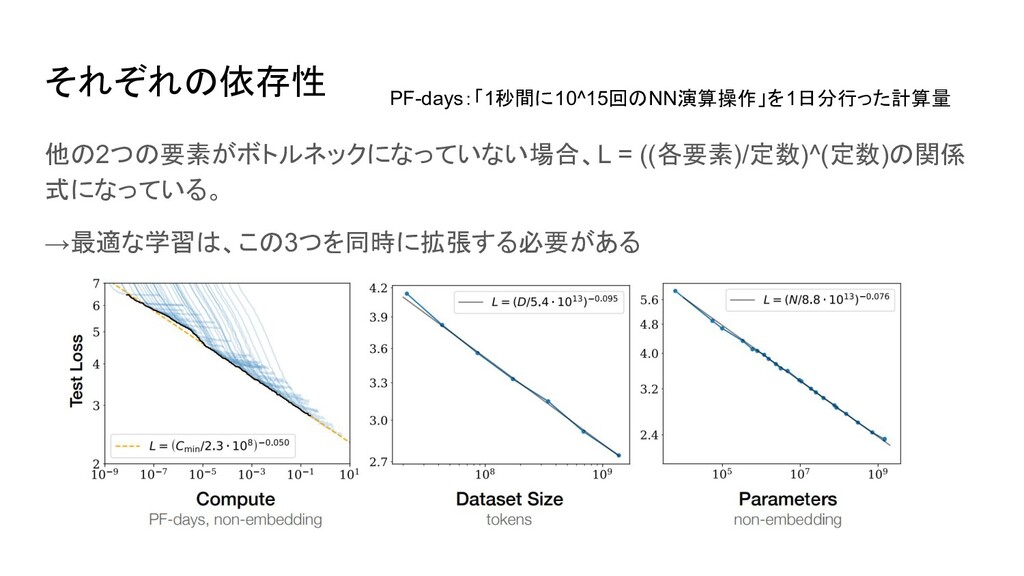
それぞれの依存性 他の2つの要素がボトルネックになっていない場合、L = ((各要素)/定数)^(定数)の関係 式になっている。 →最適な学習は、この3つを同時に拡張する必要がある PF-days:「1秒間に10^15回のNN演算操作」を1日分行った計算量
諸発見 ・性能はスケールへの依存が強く、モデルの形状への依存は弱い ・N, D, Cがボトルネックになっていない限り、損失はそれぞれとべき乗関係にあり、その 傾向は6桁以上に及ぶ。 ・↑は実験範囲では逸脱していないが、損失がゼロになる前に平坦になるはず ・過学習を避けるにはモデルサイズを8倍にするたびにデータを5倍にすればいい ・学習曲線はべき乗則に従うため、初期の部分が分かれば長時間トレーニングした場合 の結果が予測できる
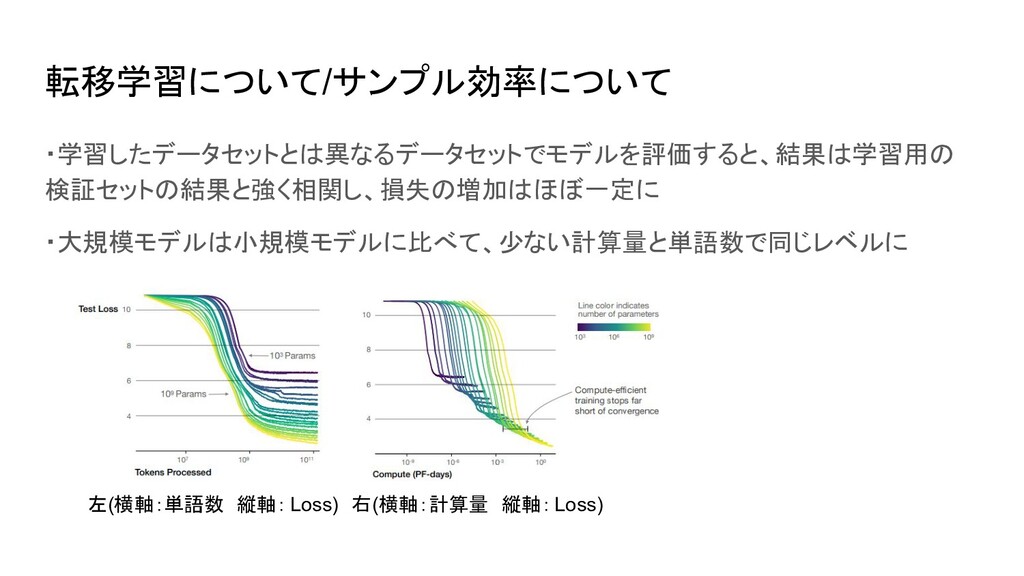
転移学習について/サンプル効率について ・学習したデータセットとは異なるデータセットでモデルを評価すると、結果は学習用の 検証セットの結果と強く相関し、損失の増加はほぼ一定に ・大規模モデルは小規模モデルに比べて、少ない計算量と単語数で同じレベルに 左(横軸:単語数 縦軸: Loss) 右(横軸:計算量 縦軸: Loss)
収束までの学習について ・収束まで学習させることは非効率になる 決まった計算資源C:モデルサイズN、利用可能なデータDが無制限 →「非常に大きなモデル」で、「収束のかなり手前」で停止すると最適 小さなモデルを使って収束させるよりもサンプル効率が高い 訓練時の計算量に対して必要なデータ量はD≒C^0.27とゆっくり増加していく
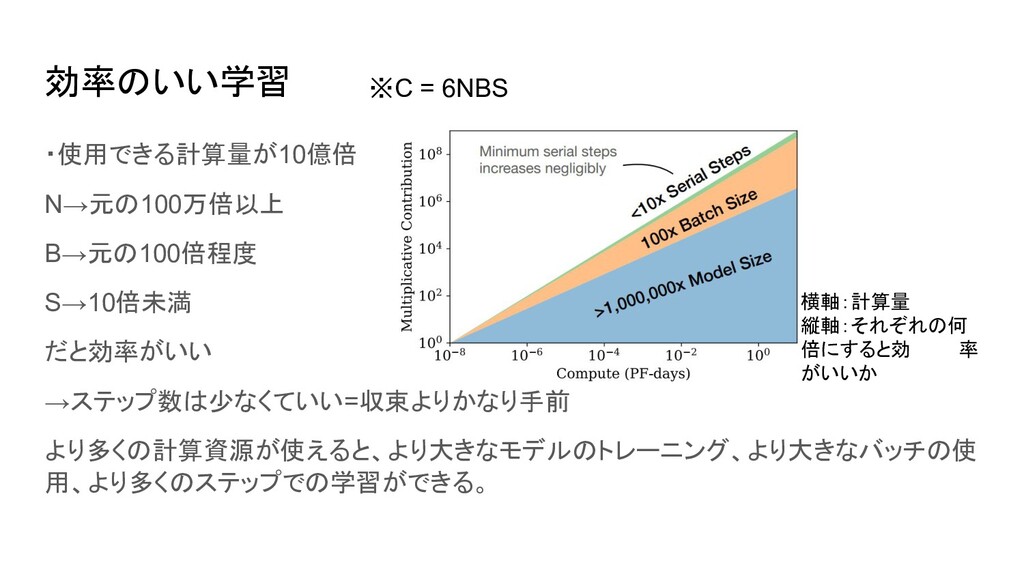
効率のいい学習 ・使用できる計算量が10億倍 N→元の100万倍以上 B→元の100倍程度 S→10倍未満 だと効率がいい →ステップ数は少なくていい=収束よりかなり手前 より多くの計算資源が使えると、より大きなモデルのトレーニング、より大きなバッチの使 用、より多くのステップでの学習ができる。 横軸:計算量
縦軸:それぞれの何 倍にすると効 率 がいいか ※C = 6NBS
理想的なバッチサイズ 理想的なバッチサイズは、ほとんど損失だけに依存するべき乗で求まり、引き続き gradient noise scaleを測定することで決定することができる。 gradient noise scale→”An empirical model
of large-batch training”で詳しく解説され ている?
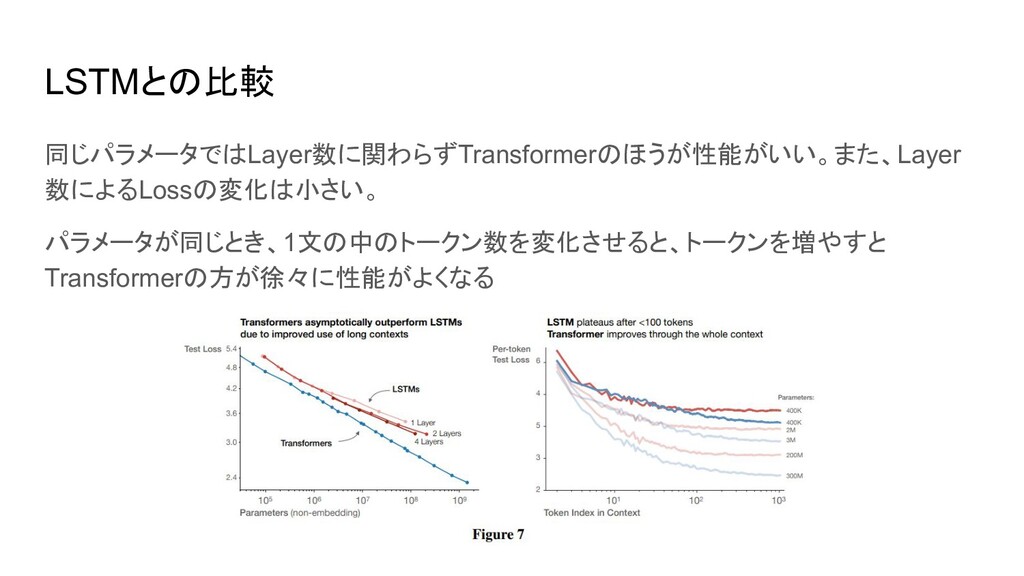
LSTMとの比較 同じパラメータではLayer数に関わらずTransformerのほうが性能がいい。また、Layer 数によるLossの変化は小さい。 パラメータが同じとき、1文の中のトークン数を変化させると、トークンを増やすと Transformerの方が徐々に性能がよくなる
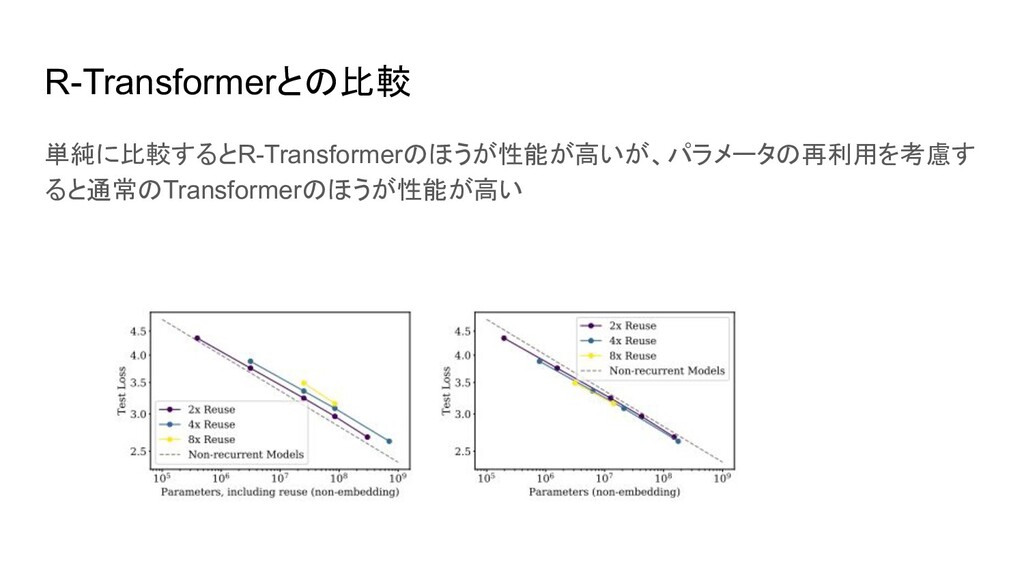
R-Transformerとの比較 単純に比較するとR-Transformerのほうが性能が高いが、パラメータの再利用を考慮す ると通常のTransformerのほうが性能が高い
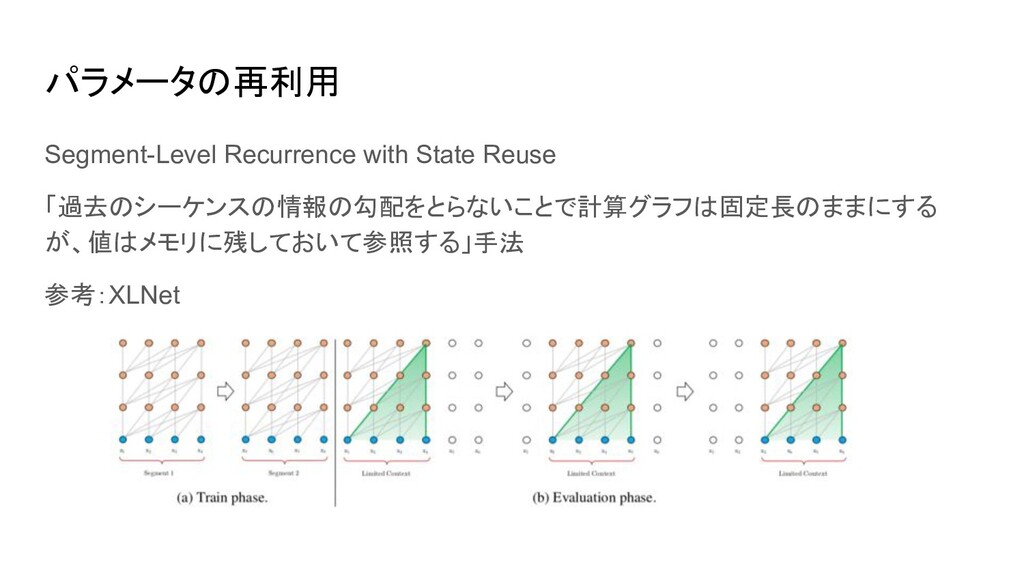
パラメータの再利用 Segment-Level Recurrence with State Reuse 「過去のシーケンスの情報の勾配をとらないことで計算グラフは固定長のままにする が、値はメモリに残しておいて参照する」手法 参考:XLNet
まとめ モデルサイズ、データ、計算量を適切にスケールアップすることで言語モデルの性能が スムーズかつ目に見えて向上することがわかる より大きな言語モデルは、現在のモデルよりも性能が向上し、サンプル効率も良くなると 期待できる モデルの選択はパラメータ数などのべき乗則が成り立つ値よりも損失への影響が低い。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}