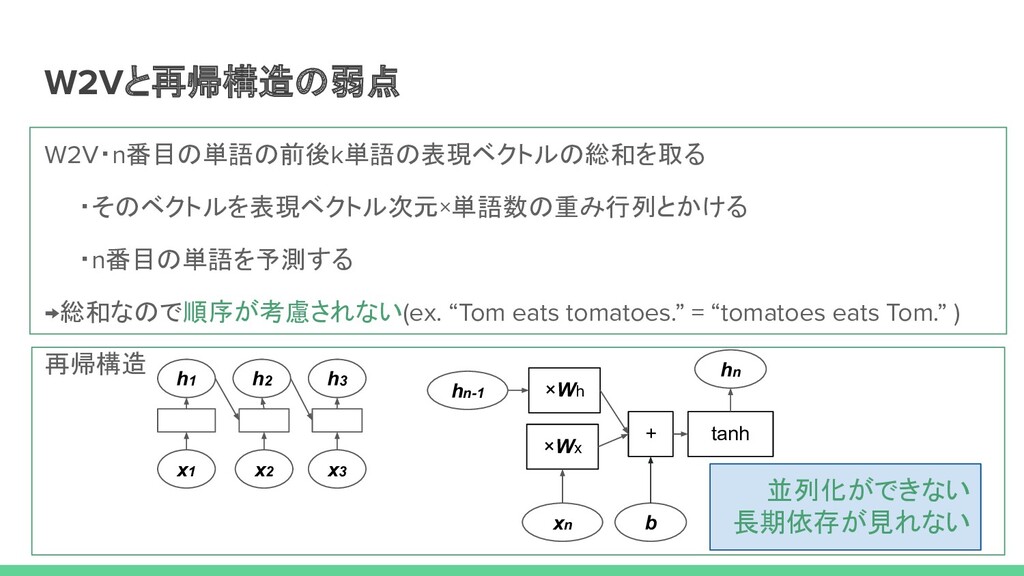
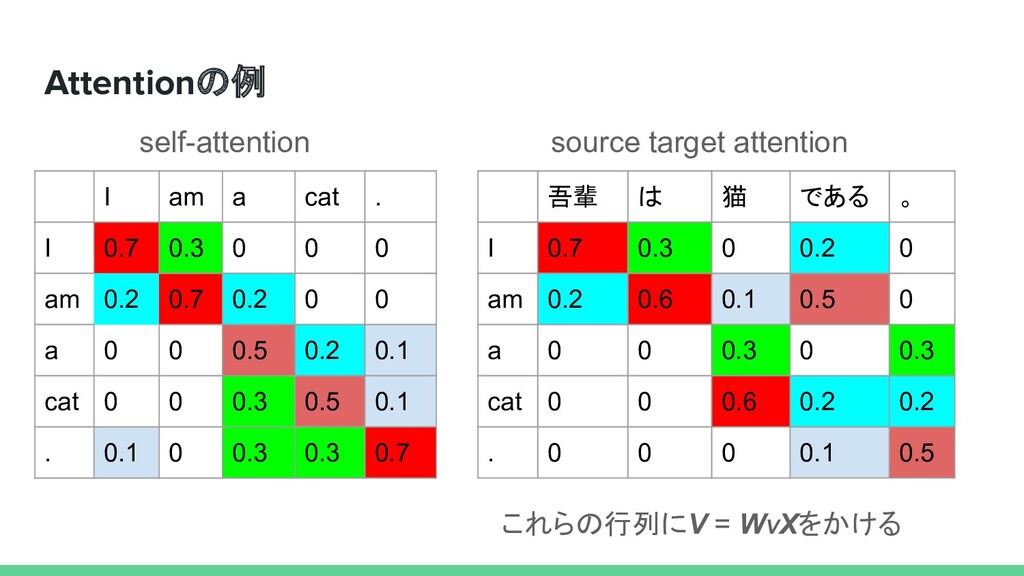
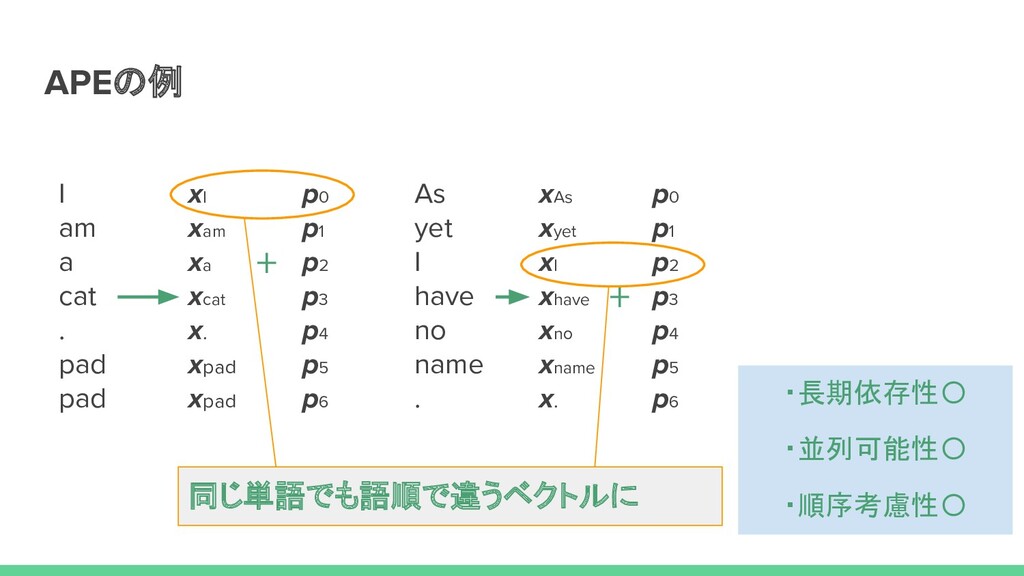
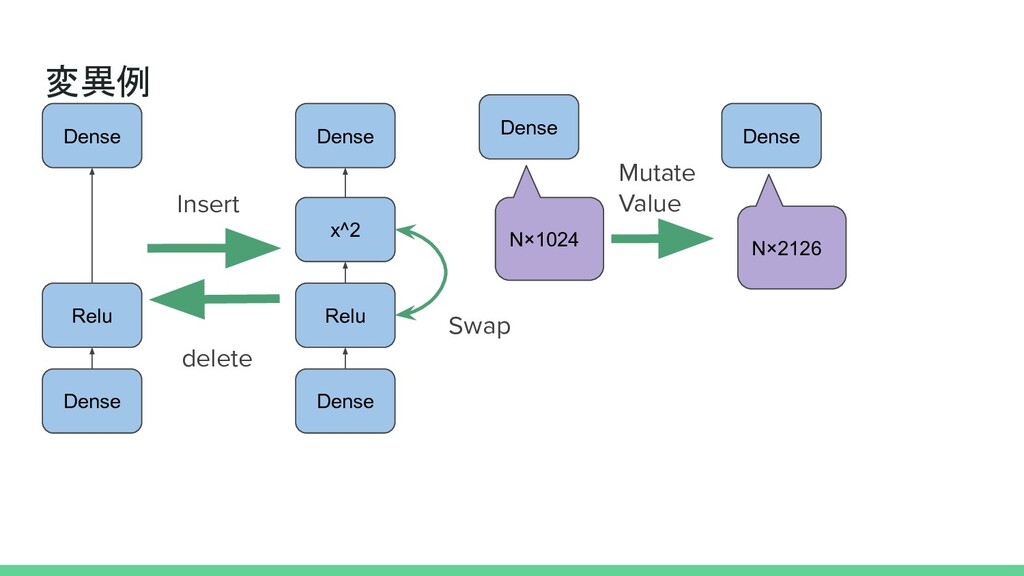
xa xcat x. xpad xpad + As yet I have no name . xAs xyet xI xhave xno xname x. p0 p1 p2 p3 p4 p5 p6 + 同じ単語でも語順で違うベクトルに p0 p1 p2 p3 p4 p5 p6 ・長期依存性〇 ・並列可能性〇 ・順序考慮性〇
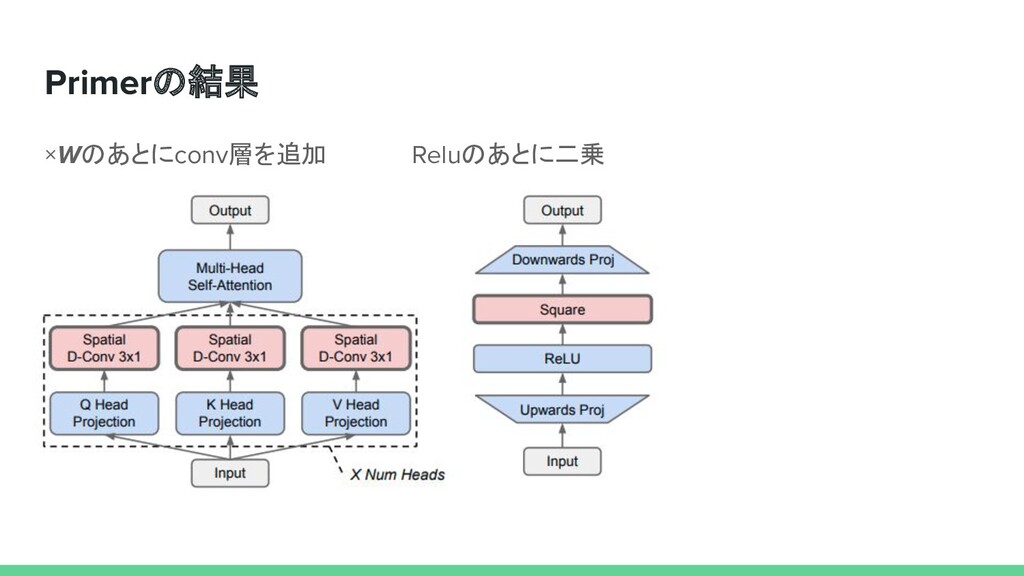
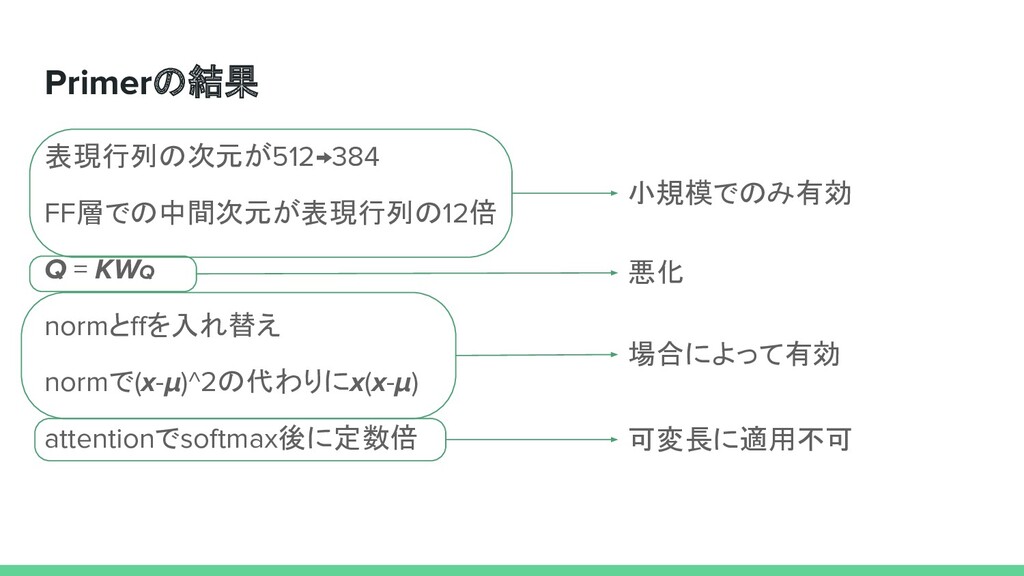
Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin Attention Is All You Need In Neural Information Processing Systems, (NIPS),2017 David R. So, Wojciech Manke, Hanxiao Liu, Zihang Dai, Noam Shazeer, Quoc V. Le Primer: Searching for Efficient Transformers for Language Modeling In Neural Information Processing Systems, (NeurIPS),2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Encoderモデルの学習 INPUT OUTPUT I am a cat . [PAD] model](https://files.speakerdeck.com/presentations/420c3a204dec4bcc8545507449bceb4c/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}