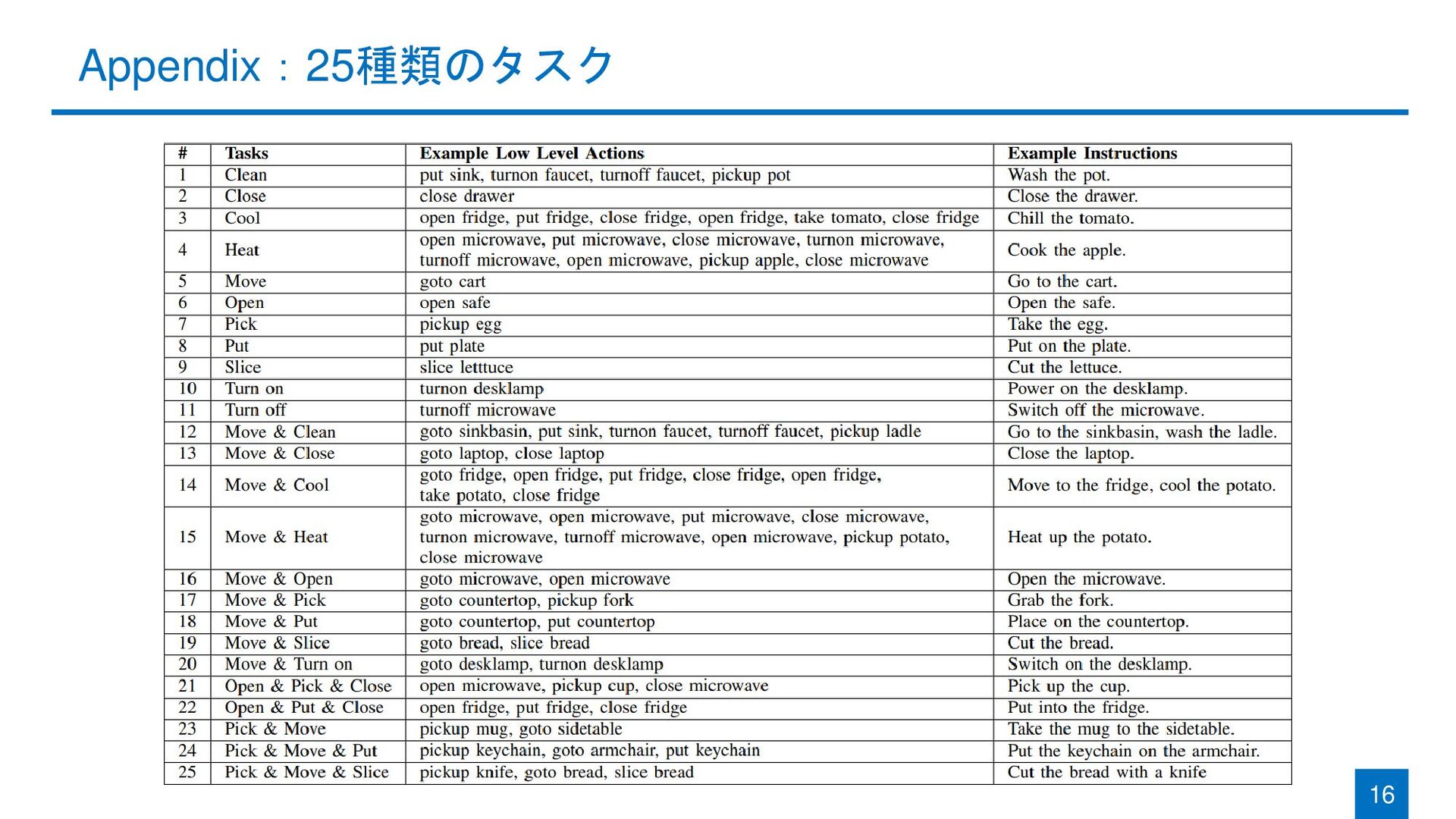
in the sink” + “turn on the faucet” + “turn off the faucet” 方針2:分割したサブゴールをマージして新たなタスクを作成 ◼ 指示文:主要なサブゴールのみを説明するように作成 ◼ 例)”go to the fridge” + “open the fridge” -> Move & Open 6 新たなタスク例
does [object] look like?” 3) Direction: “which direction should I turn to?” ◼ Oracle answer:対応する応答テンプレート 1) Location: “The [object] is to your [direction] in/on the [container].” 2) Appearance: “The [object] is [color] and made of [material].” 3) Direction: “You should turn [direction] / You don’t need to move.” Oracle answer:シーンのメタデータを用いたテンプレート応答自動生成 8 パーサで抽出した指示文中の名詞 シミュレータから取得
{kind=link}
{kind=link}
![背景:自然言語指示による家事タスク実行 ◼ ALFRED [Shridhar+, CVPR20] ◼ 物体操作を含むVision-and-Language Navigationタスクの標準ベンチマーク ◼ 抽象度の異なる指示文が存在](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼ 前提:3種類の質問テンプレート 1) Location: “where is [object]?” 2) Appearance: “what](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![② Performer:Episodic Transformer [Pashevich+, ICCV21] ◼ transformerを用いて,画像・言語・行動に関する過去の系列をエンコード ◼ 訓練集合において考えられるすべての質問とoracle answerで事前学習](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_10.jpg){kind=link}
![実験設定:DialFREDベンチマーク ◼ シミュレータ:AI2-THOR [Kolve+, 17] ◼ 1000ステップ超過または10回以上の行動失敗で終了 ◼ 評価指標 ①](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}