Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal Club]MultiMAE: Multi-modal Multi-task ...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
October 31, 2022
Technology
450
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal Club]MultiMAE: Multi-modal Multi-task Masked Autoencoders (ECCV22)
Semantic Machine Intelligence Lab., Keio Univ.
PRO
October 31, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.9k
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
140
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
220
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
450
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
390
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
Featured
See All Featured
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Marketing to machines
jonoalderson
1
5.6k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
420
Music & Morning Musume
bryan
47
7.3k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Google's AI Overviews - The New Search
badams
0
1.1k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
HDC tutorial
michielstock
2
750
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Transcript
MultiMAE: Multi-modal Multi-task Masked Autoencoders 慶應義塾大学 杉浦孔明研究室 飯岡 雄偉 Roman
Bachmann, David Mizrahi, Andrei Atanov, Amir Zamir, Institute of Technology Lausanne (EPFL) Bachmann, R., Mizrahi, D., Atanov, A., & Zamir, A. (2022). MultiMAE: Multi-modal Multi-task Masked Autoencoders. In ECCV.
概要:MultiMAE 2 • 様々なタスクに遷移しやすい事前学習モデル • 複数モダリティにおける画像を入力 – RGB, Depth, Semantic
Segmentation • 各モダリティごとに出力 – それぞれ疑似的にGTを作成 – タスクごとに損失を算出 https://multimae.epfl.ch/
研究背景:扱いやすい画像特徴量の事前学習モデル • BERT[Jacob+, NAACL19] – 文をマスクして,予測 – 言語特徴量の事前学習モデルとしてbreak through •
Masked Autoencoders(MAE)[He +, CVPR22] – 画像をマスクして,予測 – RGBの画像のみで学習 -> 実際,Depth等が取れる状況は多いはず • MultiMAE – RGB, Depth, Semantic Segmentationにおける画像で学習 – より多様なタスクへの効率的な転移を目指す 3
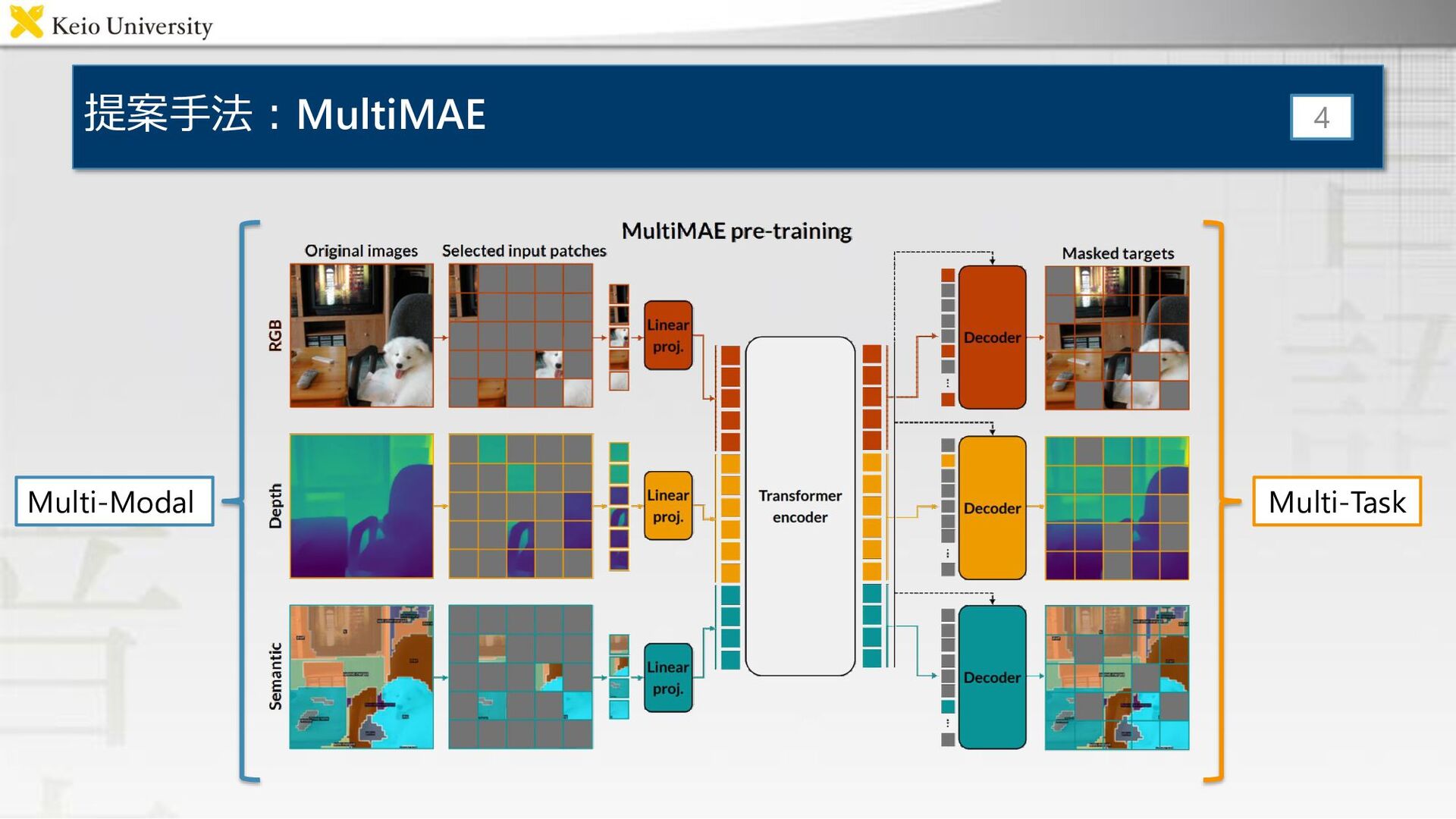
提案手法:MultiMAE 4 Multi-Modal Multi-Task
構造①:RGB画像から各モダリティの疑似画像を作成 • Depth – Omnidata[Ainaz+, ICCV21] で学習した DPT-Hybrid[Rene, ICCV21] で予測
• Semantic Segmentation – COCO[Tsung, ECCV14] で学習した Mask2Former[Bowen, CVPR22] で予測 5
構造②:全特徴量を一つのEncoderに入力 • 各画像を16×16のパッチに分割 • マスクするパッチを選択 – ディリクレ分布によって,各モダリ ティから獲得するパッチ数を決定 – 一様分布によって,各画像からパッチ
を選択 • それぞれの特徴量をconcatして入力 – Visible tokens(=マスクされていない) のみ利用 6
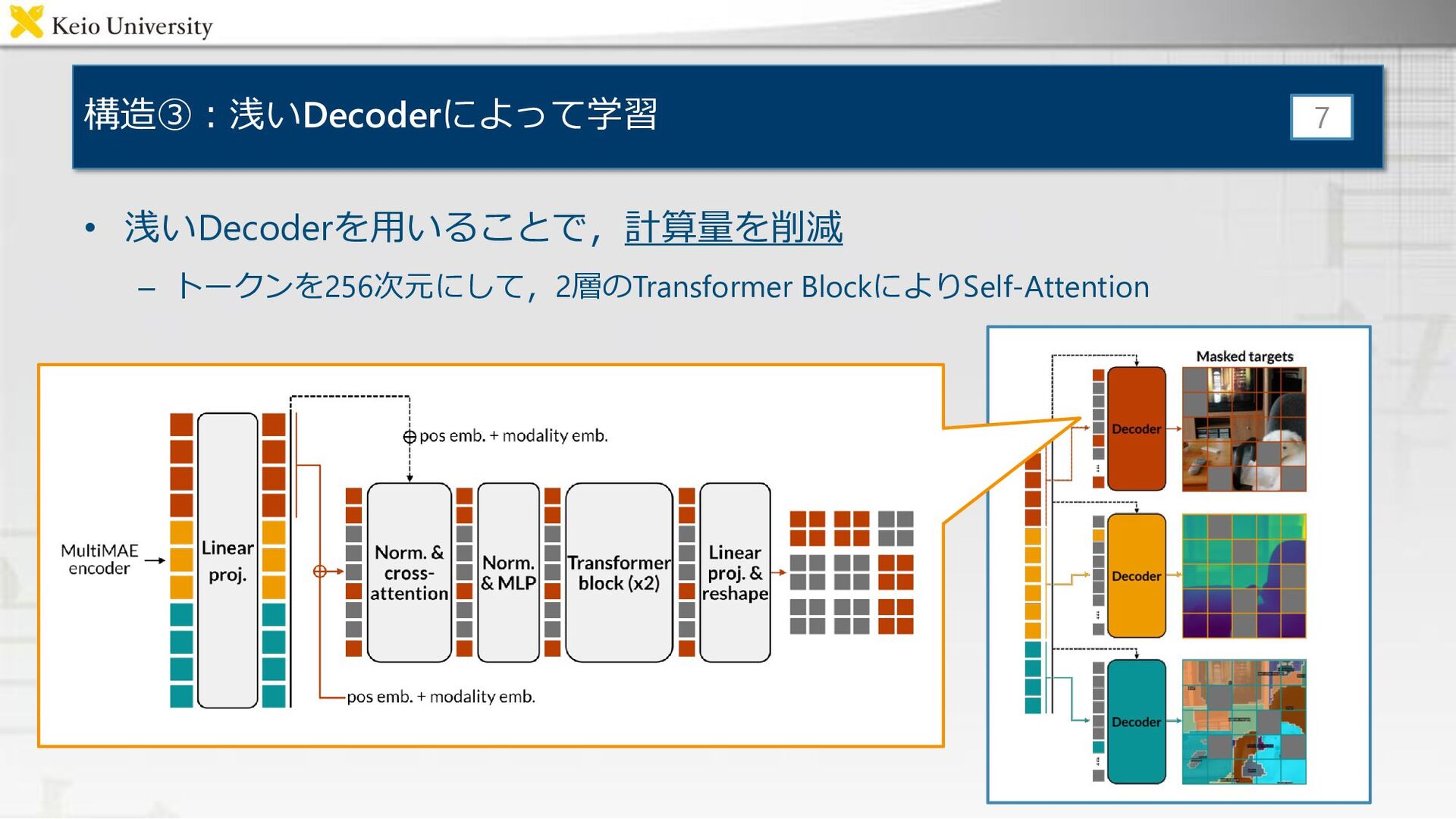
構造③:浅いDecoderによって学習 • 浅いDecoderを用いることで,計算量を削減 – トークンを256次元にして,2層のTransformer BlockによりSelf-Attention 7
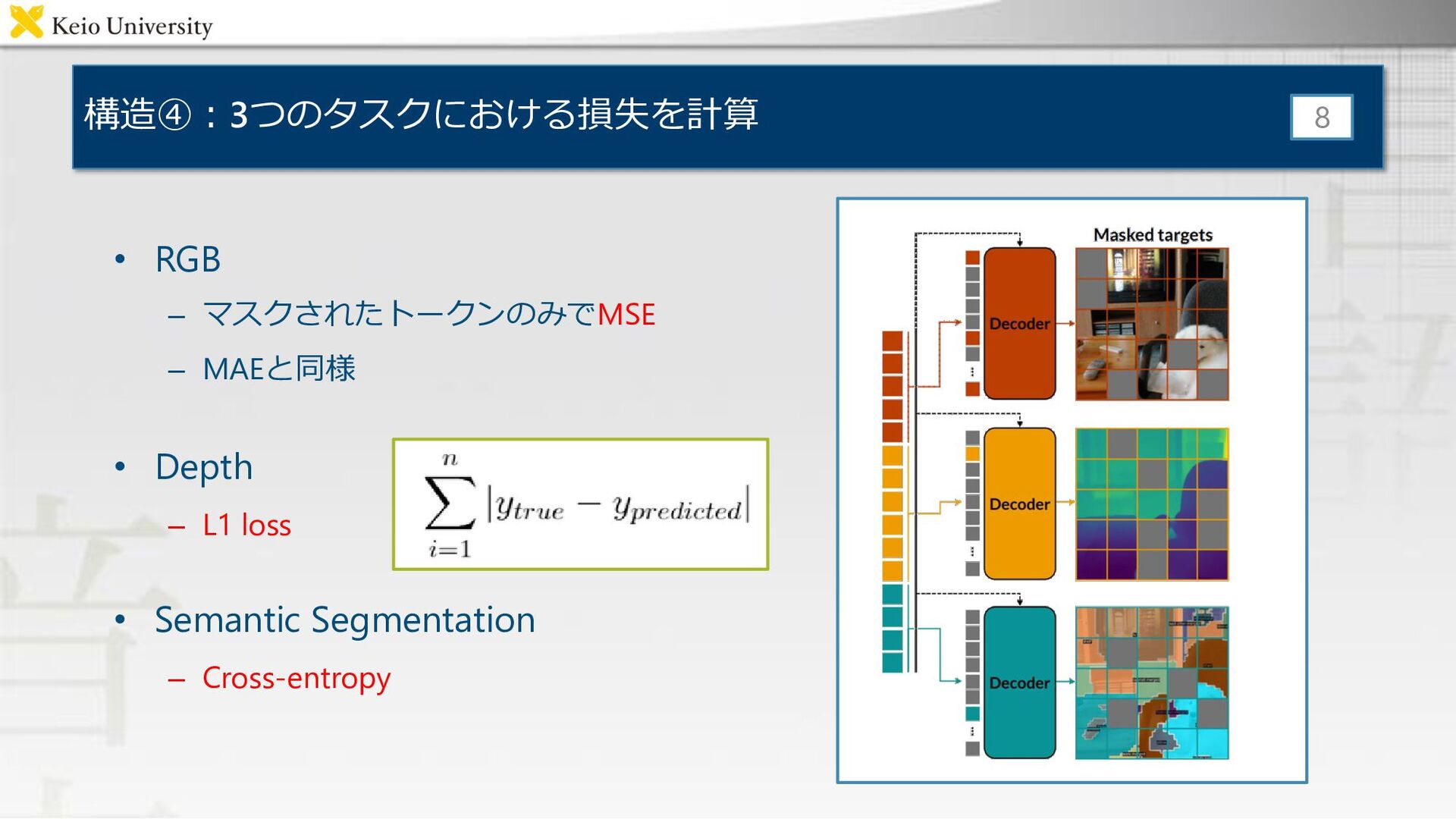
構造④:3つのタスクにおける損失を計算 • RGB – マスクされたトークンのみでMSE – MAEと同様 • Depth –
L1 loss • Semantic Segmentation – Cross-entropy 8
実験設定:3つの下流タスクで評価 1. Classification • Top-1 accuracyで評価 2. Semantic Segmentation •
mIoUで評価 3. Dense Regression Tasks • NYUv2データセットにおける𝛿1 で評価 • Depth値がthreshouldを下回るピクセル の割合(%) 9 今回は1.25 Fine-tuning用データセット – ImageNet-1K [Jia+, CVPR09] – ADE20K [Bolei+, CVPR17] – Hypersim [Mike+, ICCV21] – NYUv2 [Nathan+, ECCV12] – Taskonomy [Amir+, CVPR18] 事前学習 データセット:1.28M ImageNet GPU:8 A100 GPUs 学習時間:6.0 min / epoch
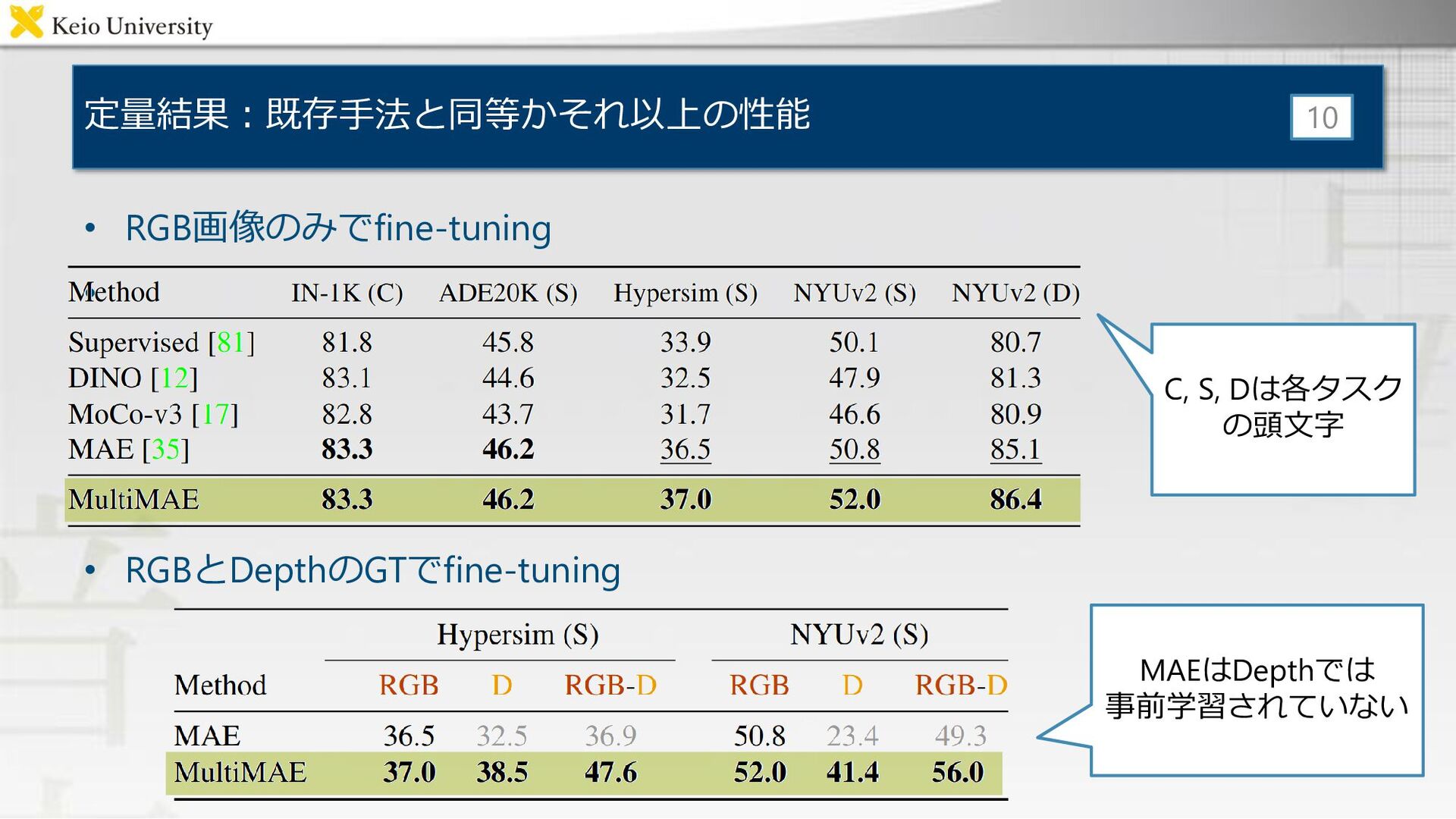
定量結果:既存手法と同等かそれ以上の性能 • RGB画像のみでfine-tuning • • RGBとDepthのGTでfine-tuning 10 C, S, Dは各タスク
の頭文字 MAEはDepthでは 事前学習されていない
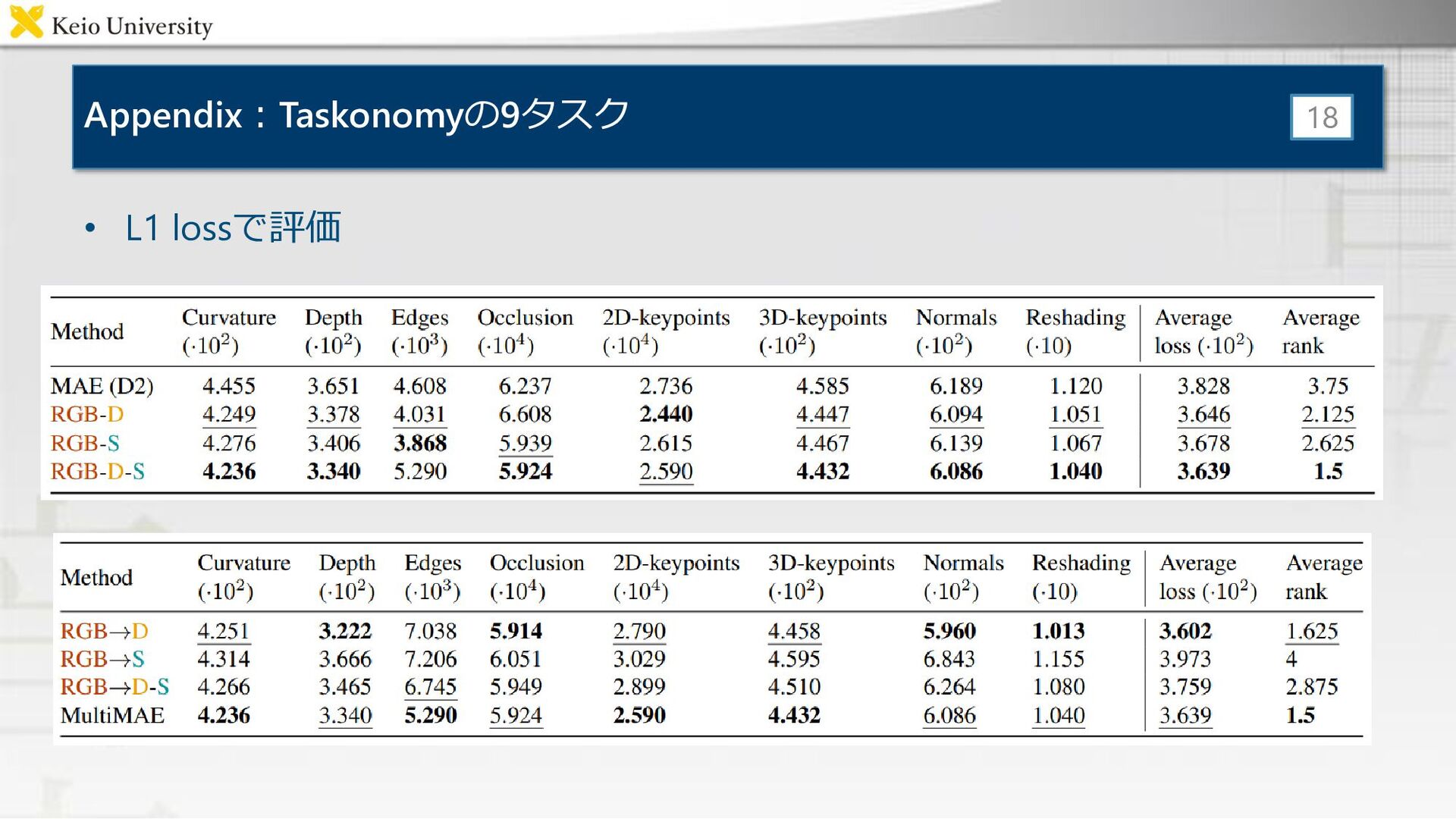
定量結果:既存手法と同等かそれ以上の性能 • 疑似ラベルの使用により性能上昇 • Taskonomy [Amir+, CVPR18] – 転移学習のしやすさを調べる –
評価は9タスクにおける評価のランキング 平均 11
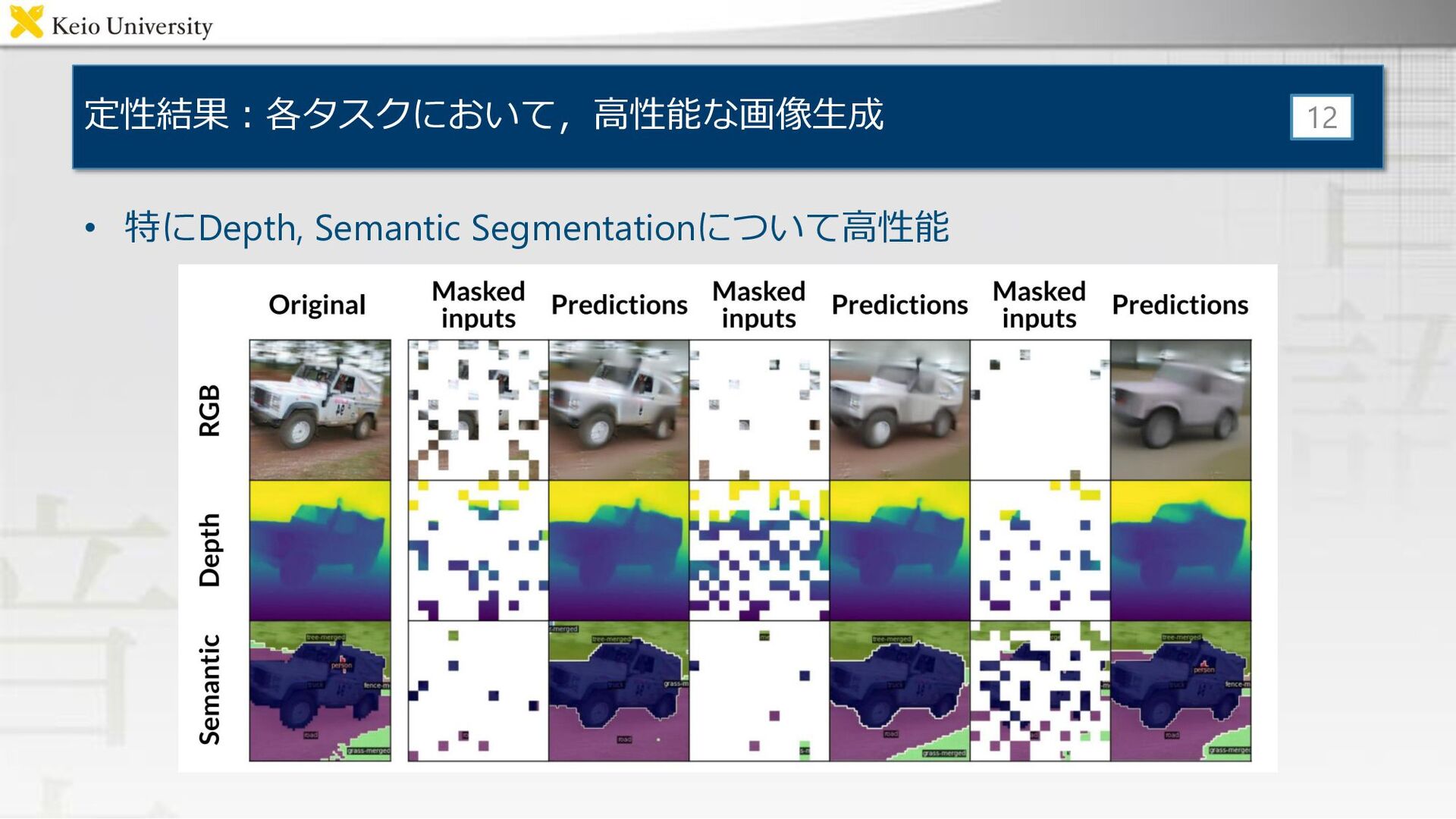
定性結果:各タスクにおいて,高性能な画像生成 • 特にDepth, Semantic Segmentationについて高性能 12
定性結果:単一モーダル画像による入力 13
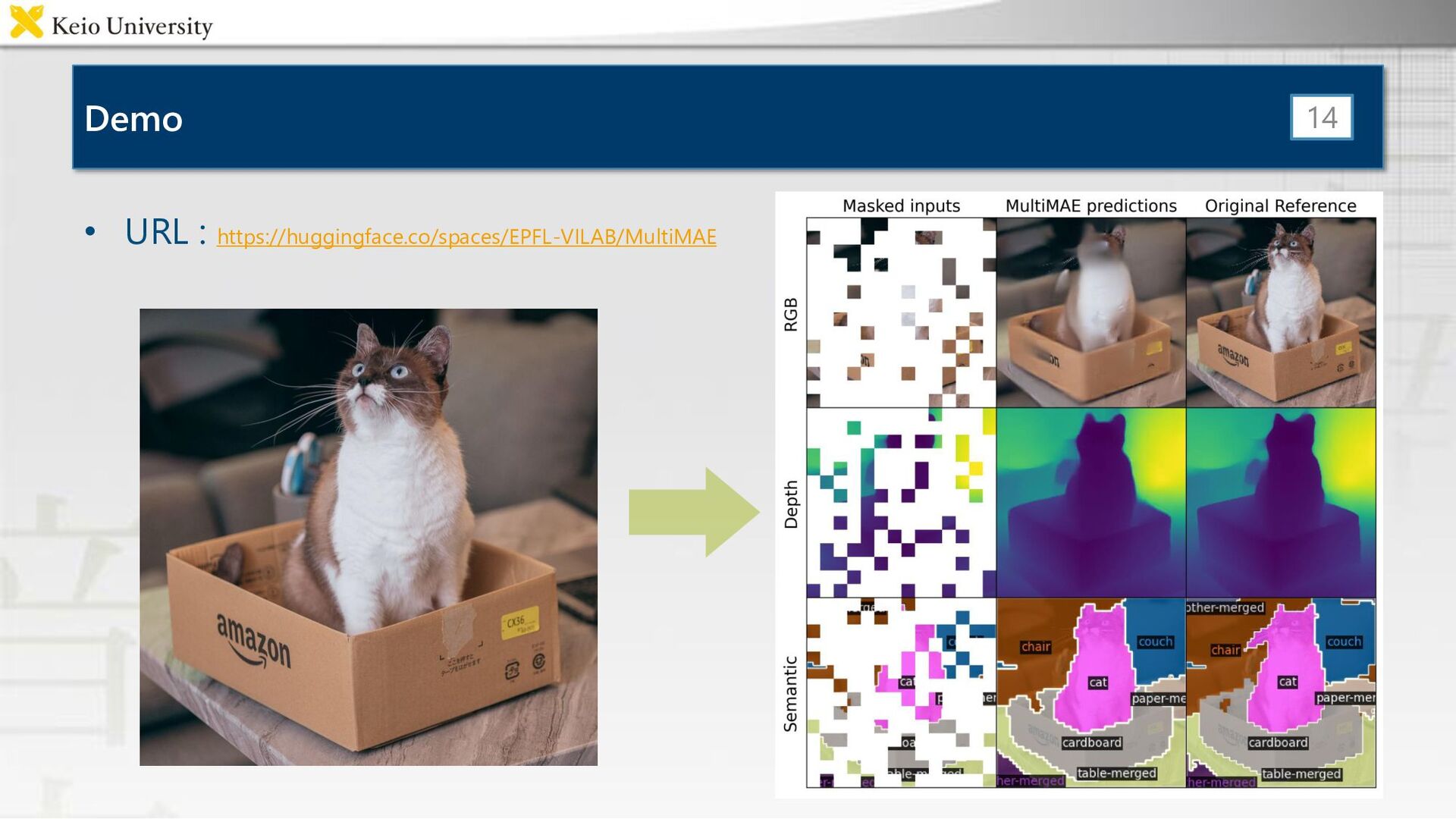
Demo • URL : https://huggingface.co/spaces/EPFL-VILAB/MultiMAE 14
まとめ: • 背景 – 扱いやすく,様々なタスクに応用できる画像の事前学習モデルを目指す • 提案手法:MultiMAE – Multi-modalな画像を入力し,Multi-taskに学習 –
データセットを疑似的に作成 • 結論 – 各タスクにおいて,MAEと同等,もしくは上回る評価 15
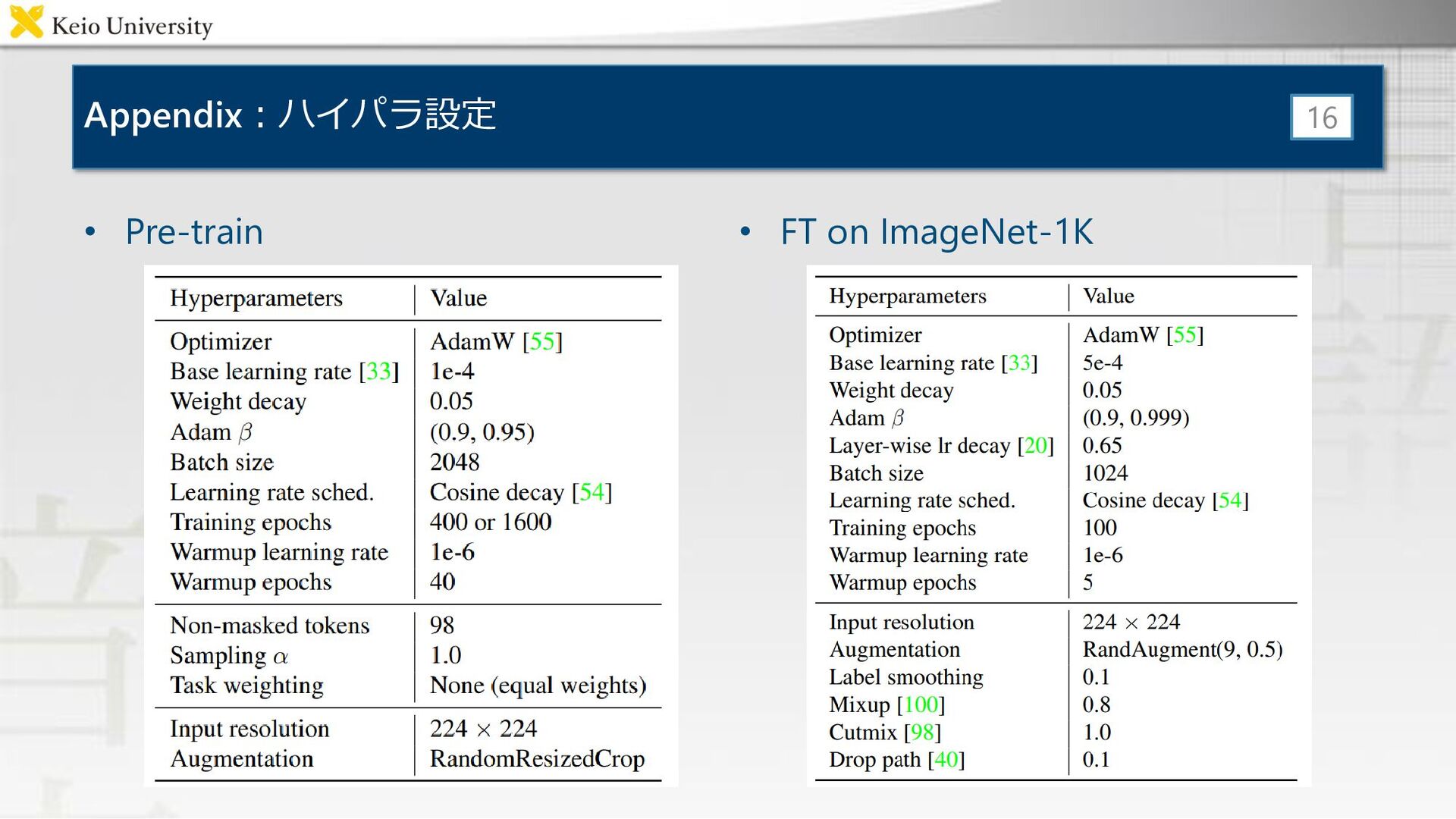
Appendix:ハイパラ設定 • Pre-train 16 • FT on ImageNet-1K
Appendix:ディリクレ分布 17
Appendix:Taskonomyの9タスク • L1 lossで評価 18
{kind=link}
{kind=link}
![研究背景:扱いやすい画像特徴量の事前学習モデル • BERT[Jacob+, NAACL19] – 文をマスクして,予測 – 言語特徴量の事前学習モデルとしてbreak through •](https://files.speakerdeck.com/presentations/fa89f1c53d124c85b4917360c5cef63a/slide_2.jpg){kind=link}
{kind=link}
![構造①:RGB画像から各モダリティの疑似画像を作成 • Depth – Omnidata[Ainaz+, ICCV21] で学習した DPT-Hybrid[Rene, ICCV21] で予測](https://files.speakerdeck.com/presentations/fa89f1c53d124c85b4917360c5cef63a/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量結果:既存手法と同等かそれ以上の性能 • 疑似ラベルの使用により性能上昇 • Taskonomy [Amir+, CVPR18] – 転移学習のしやすさを調べる –](https://files.speakerdeck.com/presentations/fa89f1c53d124c85b4917360c5cef63a/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}